
我們都不是神的孩子
阿新 • • 發佈:2019-01-10
聚類分析(Cluster Analysis)
一、聚類分析與判別分析
• 判別分析:已知分類情況,將未知個體歸入正確類別
• 聚類分析:分類情況未知,對資料結構進行分類
二、Q型和R型 聚類
Q型是對樣本進行分類處理,其作用在於:
1.能利用多個變數對樣本進行分類
2.分類結果直觀,聚類譜系圖能明確、清楚地表達其數值分類結果
3.所得結果比傳統的定性分類方法更細緻、全面、合理
R型是對變數進行分類處理,其作用在於:
1.可以瞭解變數間及變數組合間的親疏關係
2.可以根據變數的聚類結果及它們之間的關係,選擇主要變數進行迴歸分析或Q型聚類分析
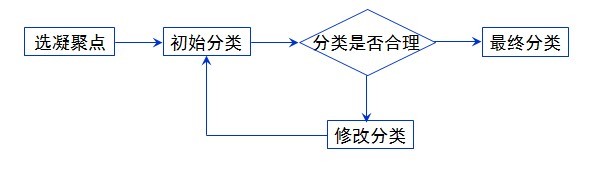
三、聚類過程
1.資料預處理(標準化)
2.構造關係矩陣(親疏關係的描述)
3.聚類(根據不同方法進行分類)
4.確定最佳分類(類別數)
3.1標準化: 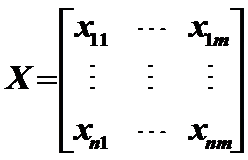
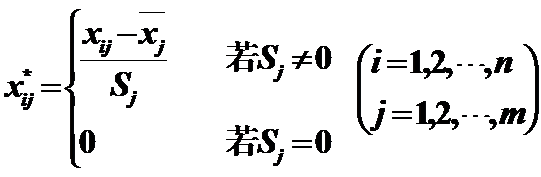 作用:變換後的資料均值為0,標準差為1,消去了量綱的影響;當抽樣樣本改變時,它仍能保持相對穩定性。
2)Range –1 to 1:極差標準化變換
作用:變換後的資料均值為0,標準差為1,消去了量綱的影響;當抽樣樣本改變時,它仍能保持相對穩定性。
2)Range –1 to 1:極差標準化變換
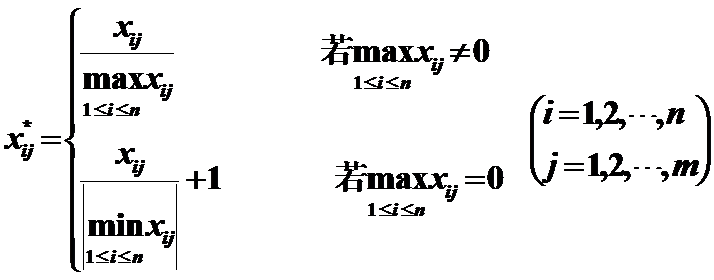
 作用:變換後的資料最小為0,最大為1,其餘在區間[0,1]內,極差為1,無量綱。
5)Mean of 1
作用:變換後的資料最小為0,最大為1,其餘在區間[0,1]內,極差為1,無量綱。
5)Mean of 1
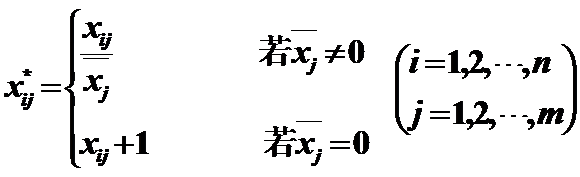 作用:變換後的資料均值為1。
6)Standard deviation of 1
作用:變換後的資料均值為1。
6)Standard deviation of 1
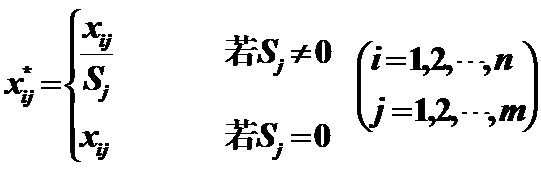 作用:變換後的資料標準差為1。
3.2構造關係矩陣
3.2.1描述變數或樣本的親疏程度的數量指標有兩種:
Ø相似係數——性質越接近的樣品,相似係數越接近於1或-1;彼此無關的樣品相似係數則接近於0,聚類時相似的樣品聚為一類
Ø距離——將每一個樣品看作m維空間的一個點,在這m維空間中定義距離,距離較近的點歸為一類。
3.2.2距離定義方式:
l)歐氏(Euclidean)距離
作用:變換後的資料標準差為1。
3.2構造關係矩陣
3.2.1描述變數或樣本的親疏程度的數量指標有兩種:
Ø相似係數——性質越接近的樣品,相似係數越接近於1或-1;彼此無關的樣品相似係數則接近於0,聚類時相似的樣品聚為一類
Ø距離——將每一個樣品看作m維空間的一個點,在這m維空間中定義距離,距離較近的點歸為一類。
3.2.2距離定義方式:
l)歐氏(Euclidean)距離

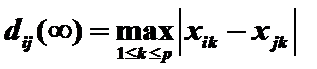 3)明氏(Minkowski)距離
3)明氏(Minkowski)距離
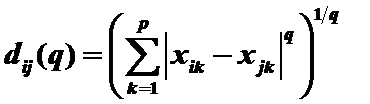 4)夾角餘弦
4)夾角餘弦
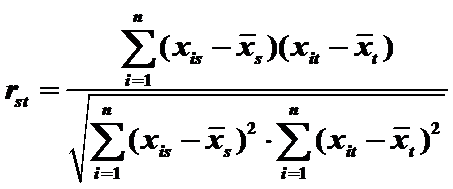 用途:計算兩個向量在原點處的夾角餘弦。當兩夾角為0o時,取值為1,說明極相似;當夾角為90o時,取值為0,說明兩者不相關。
取值範圍:0~1
5)Pearson相關係數
用途:計算兩個向量在原點處的夾角餘弦。當兩夾角為0o時,取值為1,說明極相似;當夾角為90o時,取值為0,說明兩者不相關。
取值範圍:0~1
5)Pearson相關係數
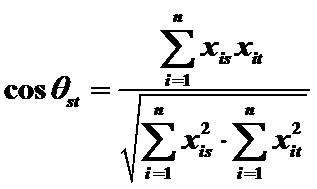 6)Block:絕對值距離(一階Minkowski度量)
6)Block:絕對值距離(一階Minkowski度量)
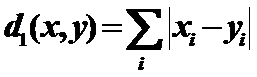 3. 選擇聚類方法
1)系統聚類法(又稱譜系聚類,實際應用中使用最多)。
2) 調優法(如動態聚類法)
3)模糊聚類、圖論聚類、聚類預報等。
3.1系統聚類法
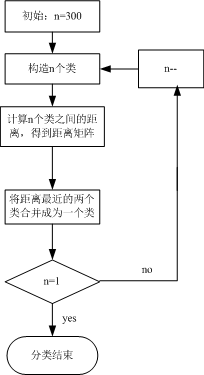
3.1.1系統聚類法的基本思想:令n個樣品自成一類,計算出相似性測度,此時類間距離與樣品間距離是等價的,把測度最小的兩個類合併;然後按照某種聚類方法計算類間的距離,再按最小距離準則並類;這樣每次減少一類,持續下去直到所有樣品都歸為一類為止。聚類過程可做成聚類譜系圖(Hierarchical diagram)。
3.1.2步驟:
s1.構造n個類,每個類包含且只包含一個樣品。
s2.計算n個樣品兩兩間的距離,構成距離矩陣,記作D0。
s3.合併距離最近的兩類為一新類。
s4.計算新類與當前各類的距離。若類的個數等於1,轉到步驟(5),否則回到步驟(3)。
s5.畫聚類圖。
s6.決定類的個數,及各類包含的樣品數,並對類作出解釋。
3. 選擇聚類方法
1)系統聚類法(又稱譜系聚類,實際應用中使用最多)。
2) 調優法(如動態聚類法)
3)模糊聚類、圖論聚類、聚類預報等。
3.1系統聚類法
3.1.1系統聚類法的基本思想:令n個樣品自成一類,計算出相似性測度,此時類間距離與樣品間距離是等價的,把測度最小的兩個類合併;然後按照某種聚類方法計算類間的距離,再按最小距離準則並類;這樣每次減少一類,持續下去直到所有樣品都歸為一類為止。聚類過程可做成聚類譜系圖(Hierarchical diagram)。
3.1.2步驟:
s1.構造n個類,每個類包含且只包含一個樣品。
s2.計算n個樣品兩兩間的距離,構成距離矩陣,記作D0。
s3.合併距離最近的兩類為一新類。
s4.計算新類與當前各類的距離。若類的個數等於1,轉到步驟(5),否則回到步驟(3)。
s5.畫聚類圖。
s6.決定類的個數,及各類包含的樣品數,並對類作出解釋。
 3.1.3 方法:
l最短距離法(single linkage)
l最長距離法(complete linkage)
l中間距離法(median method)
l可變距離法(flexible median)
l重心法(centroid)
l類平均法(average)
l可變類平均法(flexible average)
lWard最小方差法(Ward’s minimum variance)
a)Between-groups linkage 組間平均距離連線法
方法簡述:合併兩類的結果使所有的兩兩項對之間的平均距離最小。(項對的兩成員分屬不同類)
b)Within-groups linkage 組內平均連線法
方法簡述:兩類合併為一類後,合併後的類中所有項之間的平均距離最小
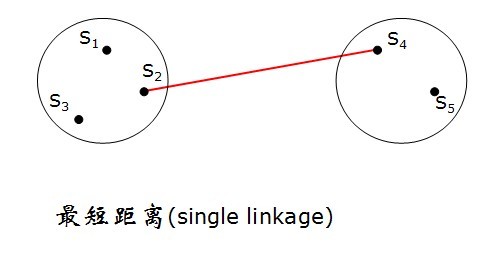
c)Nearest neighbor 最近鄰法(最短距離法)
方法簡述:首先合併最近或最相似的兩項
特點:樣品有連結聚合的趨勢,這是其缺點,不適合一般資料的分類處理,除去特殊資料外,不提倡用這種方法。
d)Furthest neighbor 最遠鄰法(最長距離法)
方法簡述:用兩類之間最遠點的距離代表兩類之間的距離,也稱之為完全連線法
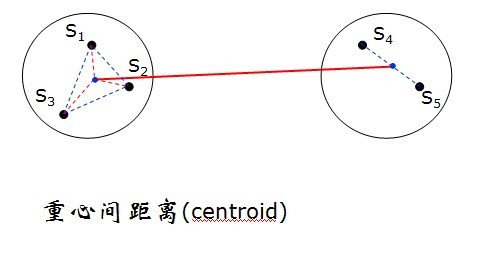
e)Centroid clustering 重心聚類法
方法簡述:兩類間的距離定義為兩類重心之間的距離,對樣品分類而言,每一類中心就是屬於該類樣品的均值
特點:該距離隨聚類地進行不斷縮小。該法的譜系樹狀圖很難跟蹤,且符號改變頻繁,計算較煩。
f)Ward’s method 離差平方和法
方法簡述:基於方差分析思想,如果分類合理,則同類樣品間離差平方和應當較小,類與類間離差平方和應當較大
特點:實際應用中分類效果較好,應用較廣;要求樣品間的距離必須是歐氏距離。
3.1.3 方法:
l最短距離法(single linkage)
l最長距離法(complete linkage)
l中間距離法(median method)
l可變距離法(flexible median)
l重心法(centroid)
l類平均法(average)
l可變類平均法(flexible average)
lWard最小方差法(Ward’s minimum variance)
a)Between-groups linkage 組間平均距離連線法
方法簡述:合併兩類的結果使所有的兩兩項對之間的平均距離最小。(項對的兩成員分屬不同類)
b)Within-groups linkage 組內平均連線法
方法簡述:兩類合併為一類後,合併後的類中所有項之間的平均距離最小
c)Nearest neighbor 最近鄰法(最短距離法)
方法簡述:首先合併最近或最相似的兩項
特點:樣品有連結聚合的趨勢,這是其缺點,不適合一般資料的分類處理,除去特殊資料外,不提倡用這種方法。
d)Furthest neighbor 最遠鄰法(最長距離法)
方法簡述:用兩類之間最遠點的距離代表兩類之間的距離,也稱之為完全連線法
e)Centroid clustering 重心聚類法
方法簡述:兩類間的距離定義為兩類重心之間的距離,對樣品分類而言,每一類中心就是屬於該類樣品的均值
特點:該距離隨聚類地進行不斷縮小。該法的譜系樹狀圖很難跟蹤,且符號改變頻繁,計算較煩。
f)Ward’s method 離差平方和法
方法簡述:基於方差分析思想,如果分類合理,則同類樣品間離差平方和應當較小,類與類間離差平方和應當較大
特點:實際應用中分類效果較好,應用較廣;要求樣品間的距離必須是歐氏距離。


 3.2快速聚類
3.2.1方法:
3.2快速聚類
3.2.1方法:
 四、譜系分類的確定
分類準則:
A.任何類都必須在臨近各類中是突出的,即各類重心間距離必須極大
B.確定的類中,各類所包含的元素都不要過分地多
C.分類的數目必須符合實用目的
D.若採用幾種不同的聚類方法處理,則在各自的聚類圖中應發現相同的類
學習小結:
聚類的關鍵:
1)用什麼指標(變數)表達要分析的樣品?
2)標準化方法
3)選擇聚類方法
4)用什麼統計量(距離、相似係數)描述樣本間的相似程度?
5)用什麼方法(類間距離等)進行聚類?
6)分成幾類比較合適?
四、譜系分類的確定
分類準則:
A.任何類都必須在臨近各類中是突出的,即各類重心間距離必須極大
B.確定的類中,各類所包含的元素都不要過分地多
C.分類的數目必須符合實用目的
D.若採用幾種不同的聚類方法處理,則在各自的聚類圖中應發現相同的類
學習小結:
聚類的關鍵:
1)用什麼指標(變數)表達要分析的樣品?
2)標準化方法
3)選擇聚類方法
4)用什麼統計量(距離、相似係數)描述樣本間的相似程度?
5)用什麼方法(類間距離等)進行聚類?
6)分成幾類比較合適?
均值表示為3.1.3 常用方法 1)Z Scores:標準化變換,標準差為
,極差為
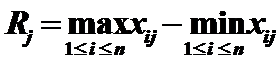
作用:變換後的資料均值為0,標準差為1,消去了量綱的影響;當抽樣樣本改變時,它仍能保持相對穩定性。
2)Range –1 to 1:極差標準化變換
作用:變換後的資料均值為0,極差為1,且|xij*|<1,消去了量綱的影響;在以後的分析計算中可以減少誤差的產生。 3)Maximum magnitude of 1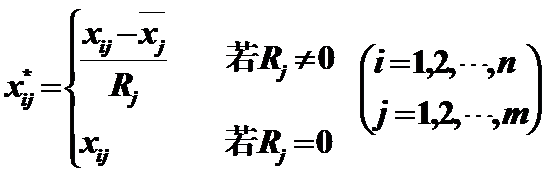
作用:變換後的資料最小為0,最大為1,其餘在區間[0,1]內,極差為1,無量綱。
5)Mean of 1
作用:變換後的資料均值為1。
6)Standard deviation of 1
作用:變換後的資料標準差為1。
3.2構造關係矩陣
3.2.1描述變數或樣本的親疏程度的數量指標有兩種:
Ø相似係數——性質越接近的樣品,相似係數越接近於1或-1;彼此無關的樣品相似係數則接近於0,聚類時相似的樣品聚為一類
Ø距離——將每一個樣品看作m維空間的一個點,在這m維空間中定義距離,距離較近的點歸為一類。
3.2.2距離定義方式:
l)歐氏(Euclidean)距離
4)夾角餘弦
用途:計算兩個向量在原點處的夾角餘弦。當兩夾角為0o時,取值為1,說明極相似;當夾角為90o時,取值為0,說明兩者不相關。
取值範圍:0~1
5)Pearson相關係數
6)Block:絕對值距離(一階Minkowski度量)
3. 選擇聚類方法
1)系統聚類法(又稱譜系聚類,實際應用中使用最多)。
2) 調優法(如動態聚類法)
3)模糊聚類、圖論聚類、聚類預報等。
3.1系統聚類法
3.1.1系統聚類法的基本思想:令n個樣品自成一類,計算出相似性測度,此時類間距離與樣品間距離是等價的,把測度最小的兩個類合併;然後按照某種聚類方法計算類間的距離,再按最小距離準則並類;這樣每次減少一類,持續下去直到所有樣品都歸為一類為止。聚類過程可做成聚類譜系圖(Hierarchical diagram)。
3.1.2步驟:
s1.構造n個類,每個類包含且只包含一個樣品。
s2.計算n個樣品兩兩間的距離,構成距離矩陣,記作D0。
s3.合併距離最近的兩類為一新類。
s4.計算新類與當前各類的距離。若類的個數等於1,轉到步驟(5),否則回到步驟(3)。
s5.畫聚類圖。
s6.決定類的個數,及各類包含的樣品數,並對類作出解釋。
3.1.3 方法:
l最短距離法(single linkage)
l最長距離法(complete linkage)
l中間距離法(median method)
l可變距離法(flexible median)
l重心法(centroid)
l類平均法(average)
l可變類平均法(flexible average)
lWard最小方差法(Ward’s minimum variance)
a)Between-groups linkage 組間平均距離連線法
方法簡述:合併兩類的結果使所有的兩兩項對之間的平均距離最小。(項對的兩成員分屬不同類)
b)Within-groups linkage 組內平均連線法
方法簡述:兩類合併為一類後,合併後的類中所有項之間的平均距離最小
c)Nearest neighbor 最近鄰法(最短距離法)
方法簡述:首先合併最近或最相似的兩項
特點:樣品有連結聚合的趨勢,這是其缺點,不適合一般資料的分類處理,除去特殊資料外,不提倡用這種方法。
d)Furthest neighbor 最遠鄰法(最長距離法)
方法簡述:用兩類之間最遠點的距離代表兩類之間的距離,也稱之為完全連線法
e)Centroid clustering 重心聚類法
方法簡述:兩類間的距離定義為兩類重心之間的距離,對樣品分類而言,每一類中心就是屬於該類樣品的均值
特點:該距離隨聚類地進行不斷縮小。該法的譜系樹狀圖很難跟蹤,且符號改變頻繁,計算較煩。
f)Ward’s method 離差平方和法
方法簡述:基於方差分析思想,如果分類合理,則同類樣品間離差平方和應當較小,類與類間離差平方和應當較大
特點:實際應用中分類效果較好,應用較廣;要求樣品間的距離必須是歐氏距離。
3.2快速聚類
3.2.1方法:
四、譜系分類的確定
分類準則:
A.任何類都必須在臨近各類中是突出的,即各類重心間距離必須極大
B.確定的類中,各類所包含的元素都不要過分地多
C.分類的數目必須符合實用目的
D.若採用幾種不同的聚類方法處理,則在各自的聚類圖中應發現相同的類
學習小結:
聚類的關鍵:
1)用什麼指標(變數)表達要分析的樣品?
2)標準化方法
3)選擇聚類方法
4)用什麼統計量(距離、相似係數)描述樣本間的相似程度?
5)用什麼方法(類間距離等)進行聚類?
6)分成幾類比較合適?