
消費金融場景下的使用者購買預測--簡單總結
消費金融場景下的使用者購買預測-簡單回顧
成績很一般,希望能抱個大腿一起學習!!!,哈哈!!!,簡單回顧一下,有利於下次進步!!!投入時間大概20天!!!
這個比賽 本人 A榜:53名,B榜:48名,這是我參加的第2個比賽,還有很多地方不足,希望能向大佬學習!!!github掛載baseline程式碼!!!
1. 任務
利用招商銀行客戶的個人屬性、信用卡消費資料,以及部分客戶在掌上生活APP上的一個月的操作行為日誌,設計合理的特徵工程與模型演算法方案,預測客戶在未來一週內(4月1日-7日),是否會購買掌上生活APP上的優惠券(包括飯票、影票等)。考慮到客戶隱私,客戶的個人屬性資料與信用卡消費資料,採用脫敏並標準化處理為V1,V2,…,V30數值型屬性。客戶在APP上的行為日誌,一些欄位也進行了相應加密。
評價指標: AUC
2. 資料介紹
- 個人屬性與信用卡消費資料(agg檔案):包含80000名信用卡客戶的個人屬性與信用卡消費資料,其中包含列舉型特徵和數值型特徵,均已轉為數值並進行了脫敏和標準化處理。(無缺失)
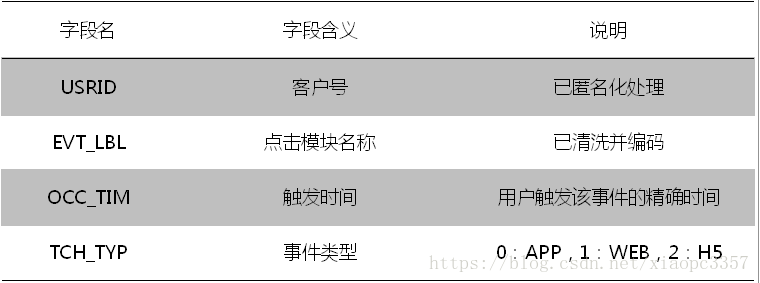
- app操作行為日誌(log檔案):上述信用卡客戶中,部分已繫結掌上生活app的客戶,在近一個月時間視窗內的所有點選行為日誌。其中,點選模組名稱均為數字編碼(形如231-145-18),代表了點選模組的三個級別(如飯票-代金券-門店詳情)(有缺失,缺失一半以上)
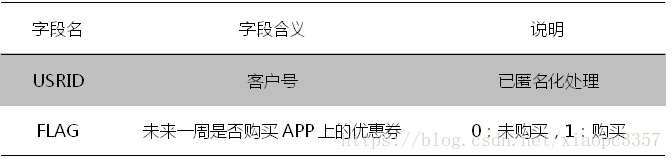
- 標籤資料:包括客戶號及標籤。其中,標籤資料為使用者是否會在未來一週,購買掌上生活app上的優惠券。

3. 解題分析
官方給出訓練集資料和測試集資料,訓練集給出80000使用者在3月份的資料,以此預測測試集20000使用者(使用者ID與訓練集不重複)是否在4月1日-7日是否購買優惠券。
賽題分為A榜和B榜,分別採用測試集的50%作為評測。
訓練集:
80000名信用卡使用者的個人屬性和信用卡消費,以及部分使用者的APP操作行為日誌資料,其中一半以上使用者APP操作行為日誌資料缺失,並且正負樣本嚴重不平衡,80000樣本中只有3000多正樣本。
測試集:
包括20000名與訓練集不同使用者的個人屬性與信用卡消費,以及部分使用者的APP操作行為日誌資料,其中一半以上使用者APP操作行為日誌資料缺失,標籤未知。
本題本質上就是利用大部分使用者的歷史資料預測另外少部分使用者未來的購買意向,因此需關注個人屬性與消費資料以及APP操作行為於購買的關係。
由於個人屬性與消費資料進行了脫敏和標準化操作,我們難以挖掘出每一個特徵所表徵的意義是什麼,因此重點對APP操作行為日誌進行挖掘,對個人屬性和消費記錄資料只做簡單處理。
處理資料時,由於訓練集和測試集使用者ID不重複,將訓練集和測試集放在一起進行特徵提取,更加有利於整體的特徵提取。
3.1 特徵工程(baseline,共273列特徵)
3.1.1 log資料探勘
由於log資料均以時間為關聯,故而挖掘重心偏重於時間特徵;
a. 統計每個使用者一個月內的的總點選次數,1列(目的:分析點選總數與是否購買關聯);
b. 統計每個使用者在歷史一個月中每天的點選次數,31列(目的:分析某一天的點選量是否與購買關聯)
c. 點選模組分為三個級別(如飯票-代金券-門店詳情),第一級唯一數值個數為21個,將其one-hot化,再單列累加(目的:分析使用者對購買物件的偏好),第二級為178列,將其one-hot化,再單列累加(目的:分析使用者對購買什麼券的偏好),至於第三級,由於列數過多,不進行統計。
d. 將瀏覽型別one-hot,共兩種瀏覽方式,APP和H5共2列,再單列統計
e. 統計每個使用者每次點選間隔(秒為單位) 最小值-最大值-均值-標準差,4列
f. 統計最後7天每個使用者點選累計次數 6列
3.1.2 agg個人屬性和消費資料探勘
a. 首先分析正負樣本每列特徵的最大值和最小值,比較正樣本的負樣本的資料分佈;
b. 統計每列特徵的唯一數值個數統計,以區分是否為連續或離散資料,統計發現,將唯一數值低於30的預設為離散資料,並將其進行離散化和one-hot處理,單獨訓練,效果相比原始特徵提升明顯,但後來訓練發現,這造成過擬合的嫌疑過大,因此將這類特徵待定;
c. 考慮交叉特徵的非線性,首先將agg的每列疑似離散的特徵(唯一數值個數不超過100)按重要性排序,然後採用多項式特徵交叉融合,刪除低標準差特徵後,提取top 10特徵,疊加one-hot,相比one-hot的agg效能有所提升,但後期訓練依舊過擬合驗證,故而將這類特徵待定;
d. 由於以上特徵的過擬合,考慮採用皮爾曼相關性係數進行相關性分析處理完,仍然存在過擬合,接著考慮將其PCA處理,由於PCA後的維數難以確定,故而將所有agg挖掘特徵待定,只將原始30列特徵加入baseline特徵。
3.2 擴增特徵工程(擴增,其中很多會導致過擬合,但本人不知道如何找出與剔除,故而之後的成績一直沒超過baseline,希望路過的大神指點一下!!!)
總要擴增log日誌特徵,擴增agg特徵在baseline特徵中待定;
3.2.1 擴增全域性特徵
a. 有無APP,考慮用於有無APP的影響,統計發現,有APP的使用者購買率遠遠大於無APP操作記錄的使用者,1列
b. 最後7天的點選趨勢(斜率),用最後7天累計次數/相應的天數
c. 一個月中使用者點選次數的平均值-最大值-最小值-標準差 4列
d. 最後10天使用者點選次數的平均值-最大值-最小值-標準差 4列
e. 最後7天使用者點選次數的平均值-最大值-最小值-標準差 4列
f. 最後3天使用者點選次數的平均值-最大值-最小值-標準差 4列
g. 使用者點選間隔平均值-最大值-最小值-標準差(天為單位)4列
h. 使用者最近點選日期 , 1列
i. 使用者最近點選日期+間隔均值/最大值/最小值 3列
j. 星期分析,分別分析週一到周天的平均值-最大值-最小值-標準差 4*7=28列
k. 星期點選比率,使用者周1(2-7)次數/使用者總點選次數, 7列
l. 點選模組第1級的平均值-最大值-最小值-標準差 4列
m. 點選模組第1級每一物件的點選率 21列
n. 點選模組第2級的平均值-最大值-最小值-標準差 4列
o. APP操作點選次數大於等1的使用者標記為1,反之為0 1列
p. H5操作點選次數大於等1的使用者標記為1,反之為0 1列
q. APP和H5操作點選次數都大於等1的使用者標記為1,反之為0 1列
由於以上某些特徵相似度極高,這是不允許的,所以本人通過以下方法進行剔除,不知道是否有效,請路過的大神指點指點!!!!
方法1:(暴力)
a. 對比每列特徵數值,將缺失資料大於60%的特徵去除並去重(耗時);
b. 採用皮爾曼係數分別求每列特徵與標籤的相關性,將特徵進行相關性排序,高分排前,低分排後;
c. 將第一個特徵分別對比之後的每一個特徵,如果發現相似度高於95%則剔除後排特徵;
d. 以此類推,直至迴圈結束。
方法2:(依舊暴力)
a. 先區分agg和log特徵,因為這兩種型別的特徵相似性肯定不高,agg資料完整,而log資料缺失嚴重;
b. 分別對agg和log特徵進行重要性排序;
c. 然後對agg和log特徵分別去重,以及去除重複性很高的特徵,刪除方法與方法1相似。
方法3:採用PCA降維
採用PCA線下評測降分明顯,因此未拿PCA特徵進行線上評測。
4. 模型
4.1 模型1: XGBoost
4.2 模型2: Lightgbm
設定early stop round 提前停止迭代引數,防止過擬合,其他引數採用隨機搜尋尋優。