
編寫Spark程式並提交到叢集上執行
編寫Spark應用程式
使用SCALA IDE,新建一個SCALA PROJECT,在專案下新建一個lib的資料夾,把spark的JAR包放進去,並且build path裡新增一下JAR包引用,然後新增一個SCALA類SparkRowCount,這個Spark應用程式的功能是計算資料的總行數,程式碼如下
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
object SparkRowCount {
def main(args: Array[String]) {
if (args.length < 1 整個專案的結構如下圖:

匯出JAR
右擊專案名稱,選擇export,再選擇JAR File,然後next>,如下圖:
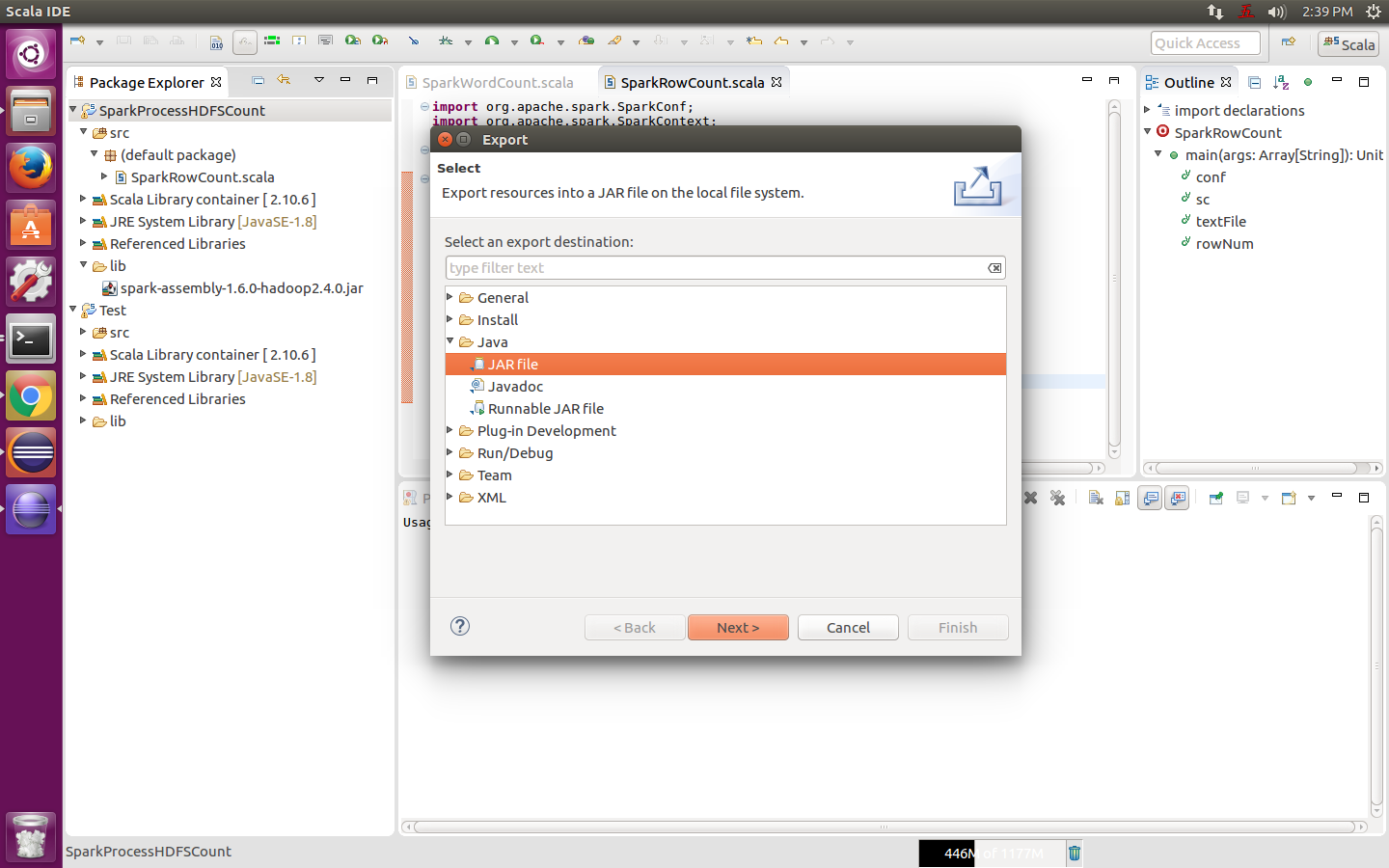
做個簡單的配置,然後一路next,最後finish,如下圖:
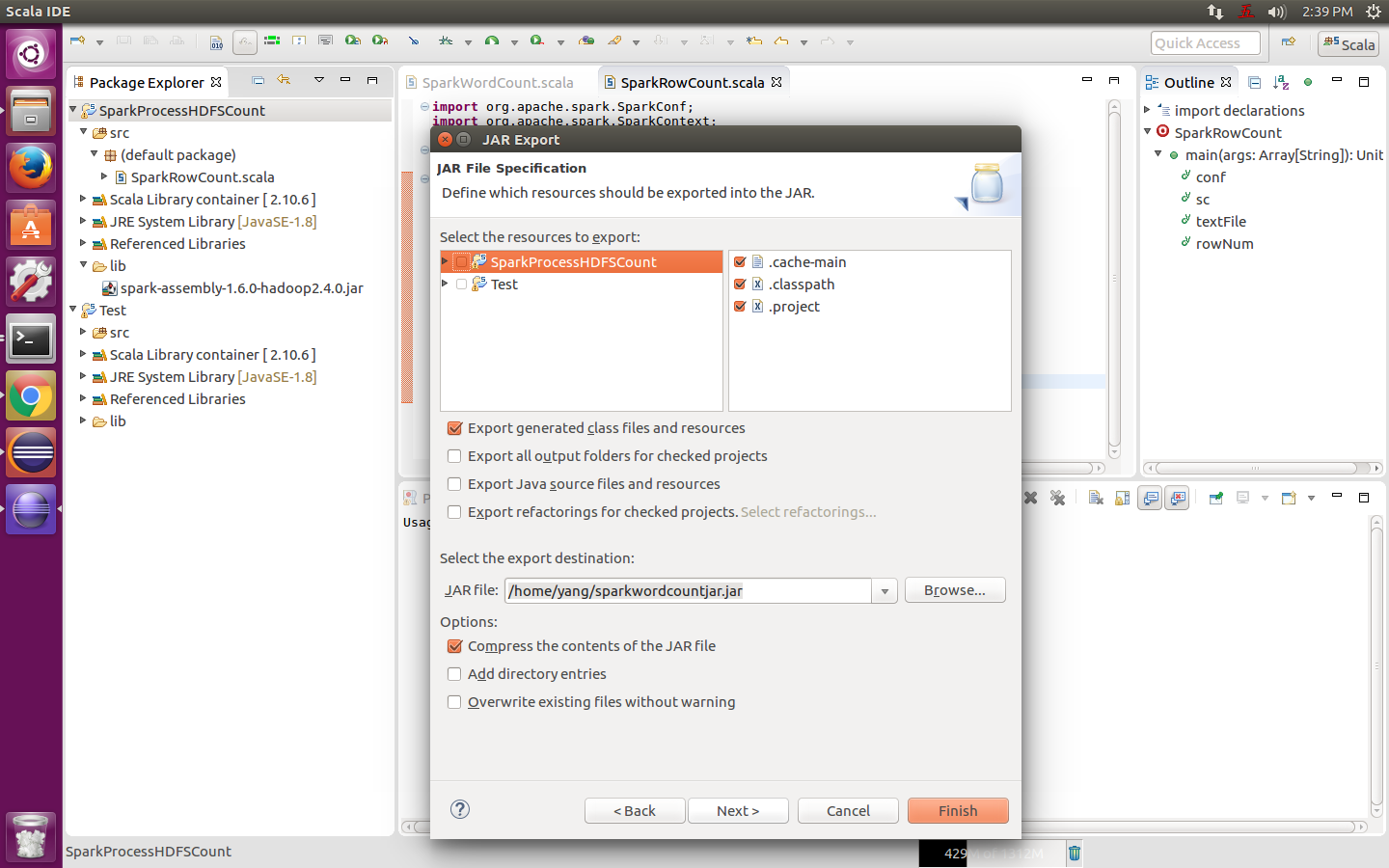
把JAR上傳到HDFS上
hadoop@master:~$ hadoop-2.4.0/bin/hadoop fs -put sparkrowcount.jar /jar/其中,/jar/是HDFS上的根目錄下的jar資料夾。
上傳測試資料集
對於測試資料集,可以隨便找個檔案上傳就好,因為只是統計檔案裡的行數,所以,不限檔案內容。
提交作業到Spark叢集
前提:hadoop spark都以開啟
hadoop@master ./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]選項說明:
–class: 應用程式的入口 (例如SparkRowCount)
–master: 叢集的master的URL (例如 spark://master:7077,master是我的叢集中master的主機名)
–deploy-mode: driver的部署方式,cluster或client,預設為client (default: client) †
–conf: 指定Spark的配置,格式為 “key=value”,要有引號.
application-jar: 應用程式JAR的路徑,URL必須是在叢集中全域性可見的,例如,hdfs://或file://,例如我的是hdfs://master:9000/jar/sparkrowcount.jar.
application-arguments: 應用程式傳到主函式的引數
hadoop@master:~$ spark-1.6.0-bin-hadoop2.4/bin/spark-submit \
> --class SparkRowCount \
> --master spark://master:7077 \
> --deploy-mode cluster \
> hdfs://master:9000/jar/sparkrowcount.jar \
> hdfs://master:9000/test/data/knowledgeGraph/knowledgeGraph-100M.json
檢視進度和結果
可以通過spark的web頁面進行檢視,地址為:
http://master:8080/
在Completed Drivers裡,找到最上面這個,這個是最新執行的,然後點選進去:
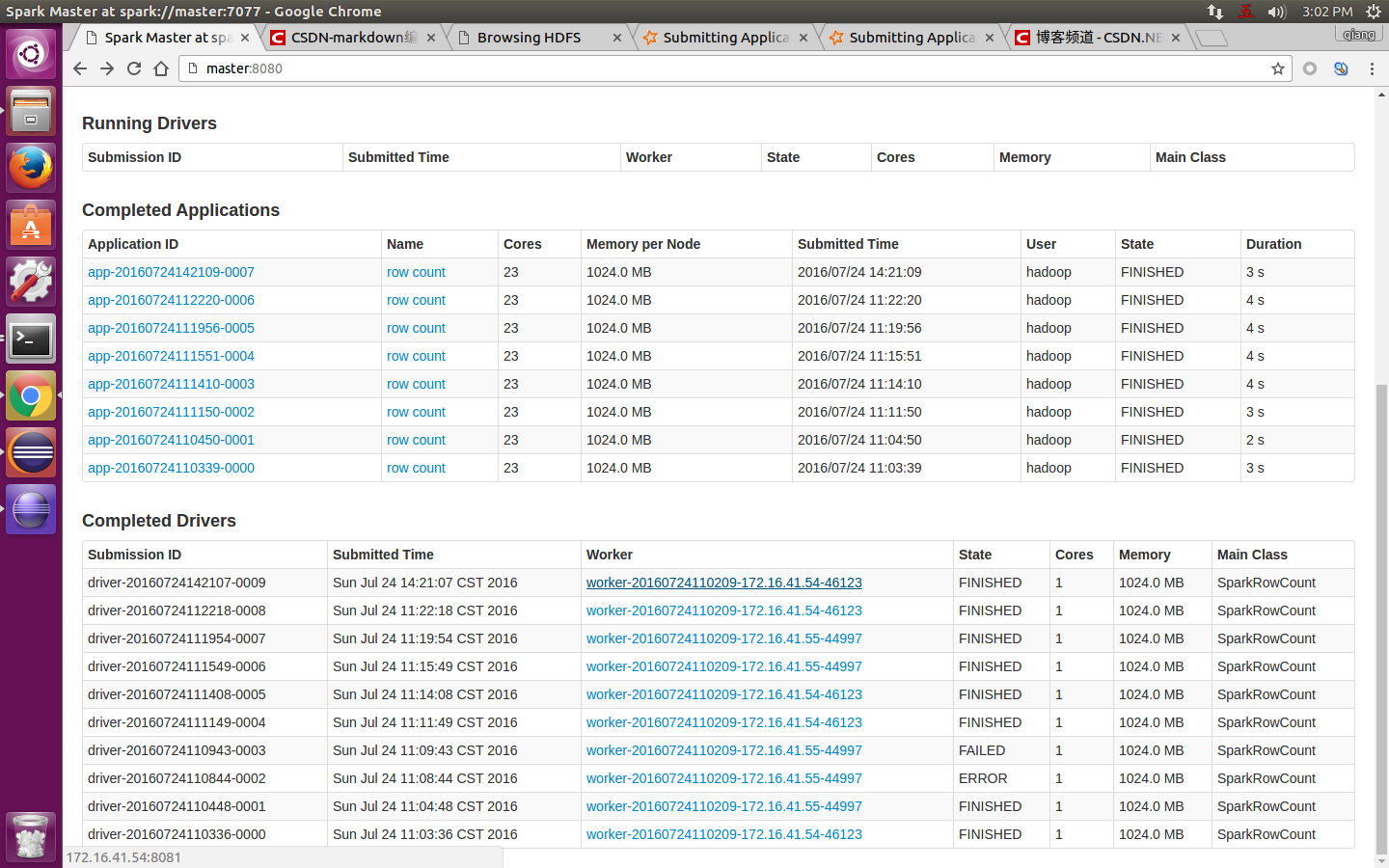
把頁面拉到最下面,找到Finished Drivers,點選檢視最上面這個的logs的stdout:
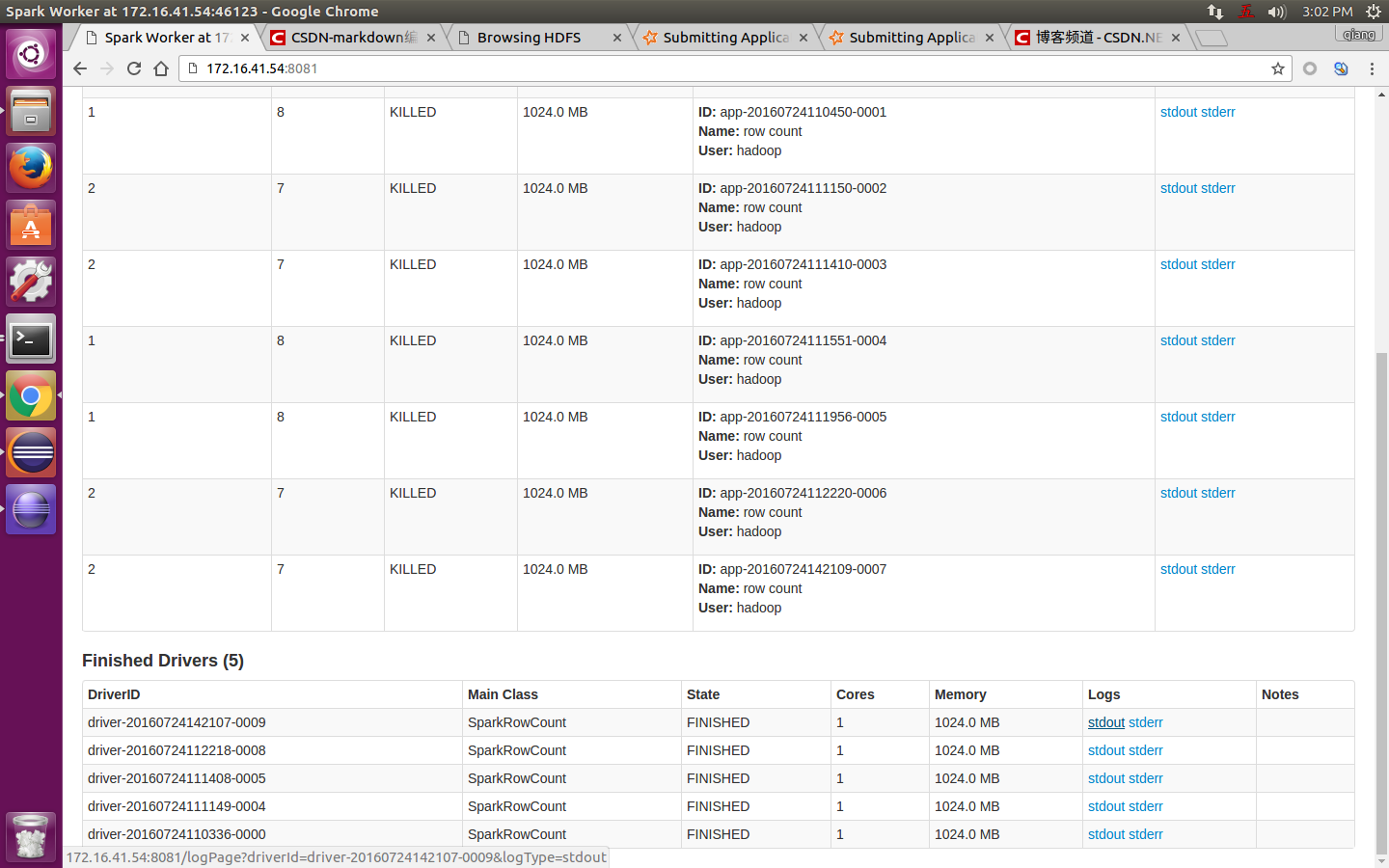
然後,就可以看到程式的輸出結果,如下圖:
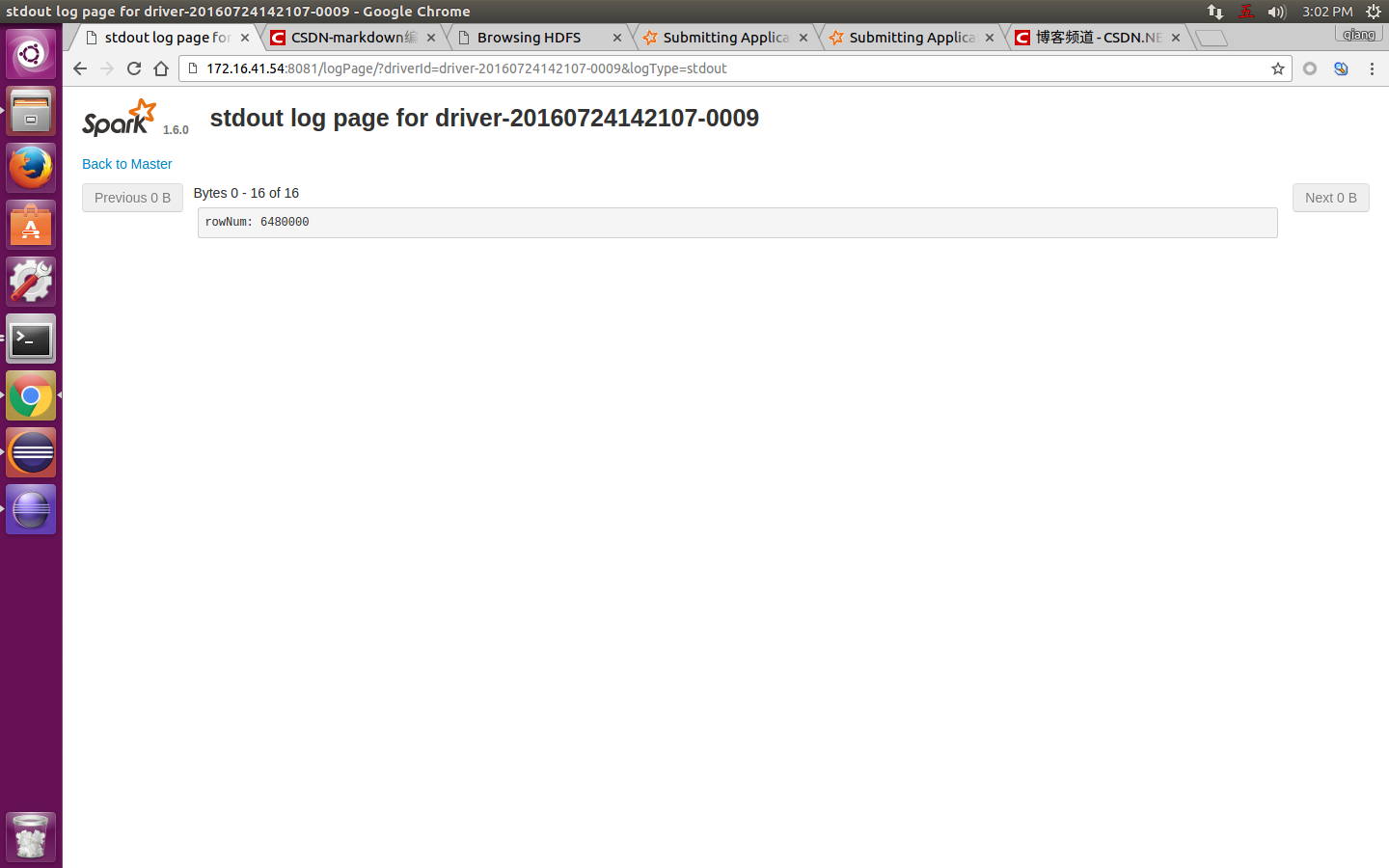
其中,rowNum: 6480000就是程式的輸出結果。