
動態ip代理:反網絡爬蟲之設置User-Agent的常規方法
爬蟲過程中的反爬措施非常重要,其中設置隨機 User-Agent 是一項重要的反爬措施。常規情況,比較方便的方法是利用 fake_useragent包,這個包內置大量的 UA 可以隨機替換,這比自己去搜集羅列要方便很多,下面來看一下如何操作。
1.首先,安裝好fake_useragent包,一行代碼搞定:
2.可以測試一下
3.這裏,使用了 ua.random 方法,可以隨機生成各種瀏覽器的 UA,見下圖: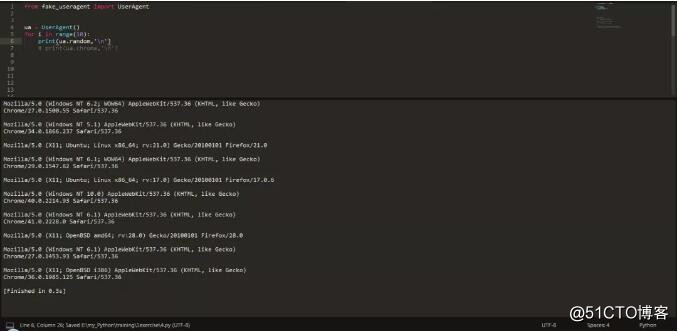
4.如果只想要某一個瀏覽器的,比如 Chrome ,那可以改成 ua.chrome,再次生成隨機 UA 查看一下: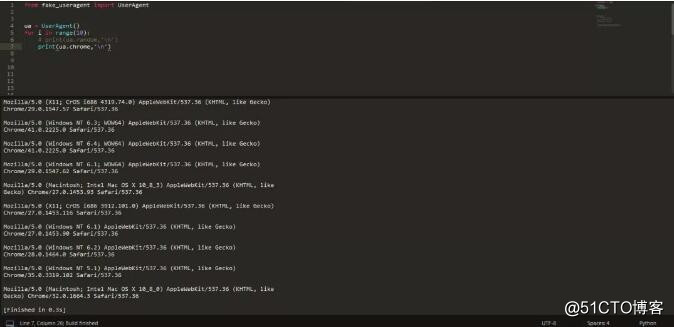
重要提示
反爬除了以上措施,還有一個很重要的就是識別一些代理ip的使用
不過如果是使用諸如太陽換ip軟件一類的專業工具,高匿性質強,那就很難識別了。
動態ip代理:反網絡爬蟲之設置User-Agent的常規方法
相關推薦
動態ip代理:反網絡爬蟲之設置User-Agent的常規方法
大量 cto sha mark 瀏覽器 想要 爬蟲 http rom 動態ip代理:反網絡爬蟲之設置User-Agent的常規方法 爬蟲過程中的反爬措施非常重要,其中設置隨機 User-Agent 是一項重要的反爬措施。常規情況,比較方便的方法是利用 fake_userag
動態ip代理:反網路爬蟲之設定User-Agent的常規方法
動態ip代理:反網路爬蟲之設定User-Agent的常規方法 爬蟲過程中的反爬措施非常重要,其中設定隨機 User-Agent 是一項重要的反爬措施。常規情況,比較方便的方法是利用 fake_useragent包,這個包內建大量的 UA 可以隨機替換,這比自己去搜集羅列要方便很多,下面來看一下如何操作。
網絡爬蟲之網頁排重:語義指紋
網絡爬蟲 網頁排重 引言:網絡爬蟲讓我們高效地從網頁獲取到信息,但網頁的重復率很高,網頁需要按內容做文檔排重,而判斷文檔的內容重復有很多種方法,語義指紋是其中比較高效的方法。本文選自《網絡爬蟲全解析——技術、原理與實踐》。 現代社會,有效信息對人來說就像氧氣一樣不可或缺。互聯網讓有效信息的收集工作變
python學習第八十五天:網絡爬蟲之數據解析方式
數據解析 模式 end 解析 多次 pre 綜合練習 直接 list Python網絡爬蟲之數據解析方式 正則解析 單字符: . : 除換行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一個字符 \d :數字
Python 入門網絡爬蟲之精華版
網站 爬蟲 處理 通過 精華 免費 proxy params 華爾街 Python 入門網絡爬蟲之精華版 轉載 寧哥的小站,總結的不錯 Python學習網絡爬蟲主要分3個大的版塊:抓取,分析,存儲 另外,比較常用的爬蟲框架Scrapy,這裏最後也詳細介紹一
2017.07.26 Python網絡爬蟲之Scrapy爬蟲框架
返回 scripts http ref select 文本 lang bsp str 1.windows下安裝scrapy:cmd命令行下:cd到python的scripts目錄,然後運行pip install 命令 然後pycharmIDE下就有了Scrapy:
2017.07.28 Python網絡爬蟲之爬蟲實戰 今日影視2 獲取JS加載的數據
常見 實戰 交互 影視 獲取 框架 並且 htm 處理 1.動態網頁指幾種可能: 1)需要用戶交互,如常見的登錄操作; 2)網頁通過js / AJAX動態生成,如一個html裏有<div id="test"></div>,通過JS生成<divi
2017.08.04 Python網絡爬蟲之Scrapy爬蟲實戰二 天氣預報
font size 項目 執行 weather html time art show 1.項目準備:網站地址:http://quanzhou.tianqi.com/ 2.創建編輯Scrapy爬蟲: scrapy startproject weather scrapy
2017.08.04 Python網絡爬蟲之Scrapy爬蟲實戰二 天氣預報的數據存儲問題
sql語句 city amd64 ces img href asp encoding primary 1.數據存儲到JSon:程序閱讀一般都是使用更方便的Json或者cvs等待格式,繼續講解Scrapy爬蟲的保存方式,也就是繼續對pipelines.py文件動手腳 (1)創
網絡爬蟲之MongoDB數據庫的使用
大量 保留 有序 .com pan 缺點 sch 格式 引號 一.簡潔 MongoDB是一款強大、靈活、且易於擴展的通用型數據庫 1、易用性 MongoDB是一個面向文檔(document-oriented)的數據庫,而不是關系型數據庫。 不采用關系型主要是為了獲得更
網絡爬蟲之JSOUP
element urn con rac 名稱 value fix attribute amp JSOUP中文文檔:http://www.open-open.com/jsoup/推薦博客:http://www.cnblogs.com/jycboy/p/jsoupdoc.ht
皇冠體育二代信用盤帶手機版網絡爬蟲之scrapy框架詳解
ML gin spi 通過 file 解決問題 有時 ide bee 網絡爬蟲之scrapy框架詳解twisted介紹 皇冠體育二代信用盤帶手機版 QQ2952777280Twisted是用Python實現的基於事件驅動的網絡引擎框架,scrapy正是依賴於twisted,
Python網絡爬蟲之三種數據解析方式
循環 oob bs4 none @class clas sel 執行 替換 一.正則解析 單字符: . : 除換行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一個字符 \d :數字 [0-9]
Python網絡爬蟲之圖片懶加載技術、selenium和PhantomJS
min input 函數實現 odin 形式 nsh 分享圖片 nts www. 本文概要: 圖片懶加載 selenium phantomJs 谷歌無頭瀏覽器 一、圖片懶加載 什麽是圖片懶加載? 案例分析:抓取站長素材http://sc.china
網絡爬蟲之requests模塊
use fcc manage 關鍵字 person .json size 詳情 param 一 . requests模塊的學習 什麽是requests模塊 ? requests模塊是python中原生的基於網絡請求的模塊,其主要作用是用來模擬瀏覽器發起請求
python網絡爬蟲之requests模塊
基於 req 模塊 模擬 網絡爬蟲 用法 bsp 流程 發送 什麽是requests模塊: requests模塊是python中原生的基於網路請求的模塊,其主要作用是用來模擬瀏覽器發送請求,功能強大,用法簡潔高效,在爬蟲的領域占半壁江山 如何使用requests模塊
Python網絡爬蟲之Scrapy框架(CrawlSpider)
setting ref 網頁 del tle python網絡 yield 介紹 import 目錄 Python網絡爬蟲之Scrapy框架(CrawlSpider) CrawlSpider使用
linux涉及的常見網絡接口設置和特殊路由問題匯總
linux 網絡 路由 在我的工作中,經常會遇到服務器和其他服務器,交換機對接,目前主要有這樣幾個場景,將相關配置和註意點總結,以便後來查看參考。一個網卡接口有多個IP地址一個網卡接口分多個VLAN多個網卡接口聚合成一個鏈路多個網卡對應多個路由表 linux中有0~255共256張路由表。其中0
Win10登陸界面卡住,進去後無法打開網絡相關的設置,谷歌瀏覽器無法上網
解決方法 耐心 方法 網絡相關 上網 打開 eset 題解 問題 今天Win10抽風,進入登錄頁面輸入用戶名和密碼之後,大約過了10分鐘才進入桌面。重啟後仍然如此。 經過調查,問題主要出在網絡相關模塊上,網絡無法正常初始化,導致登錄一直卡在網絡初始化上。 解決方法
python爬蟲之scrapy中user agent淺談(兩種方法)
user agent簡述 User Agent中文名為使用者代理,簡稱 UA,它是一個特殊字串頭,使得伺服器能夠識別客戶使用的作業系統及版本、CPU 型別、瀏覽器及版本、瀏覽器渲染引擎、瀏覽器語言、瀏覽器外掛等。 開始(測試不同型別user agent返回值) 手機use