
情感分析資源大全(語料、詞典、詞嵌入、程式碼)
該部落格收集情感分析領域中一些語料、詞典等。
如果引用到下列語料、詞典等資料,出於尊重作者的學術成果,在文章中還請引用相關的文獻。
1 語料庫
1.1 譚鬆波-酒店評論語料-UTF-8,10000條
現在網上大部分譚鬆波老師的評論語料資源的編碼方式都是gb2312,本資源除了原始編碼格式,還具有UTF-8編碼格式。 本資源還包含將所有語料分成pos.txt和neg.txt兩個檔案,每個檔案中的一行代表原始資料的一個txt檔案,即一篇評論。
下載地址為:譚鬆波-酒店評論語料-UTF-8,10000條
1.2 SemEval-2014 Task 4資料集
SemEval-2014 Task 4資料集主要用於細粒度情感分析,包含Laptop和Restaurant兩個領域,每個領域的資料集都分為訓練資料、驗證資料(從訓練資料分離出來)和測試資料,非常適用於有監督的機器學習演算法或者深度學習演算法,如LSTM等。檔案格式為.xml,其資料統計如下:
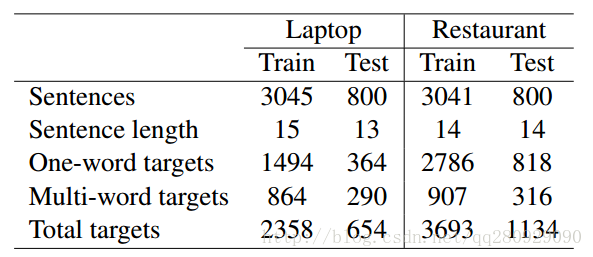
下載地址為: SemEval-2014 Task 4資料集
1.3 Citysearch corpus
該語料庫為餐館評論資料,收集自Citysearch New York網站,可用於細粒度的情感分析任務中,即aspect extraction任務當中。在本資源中,分為原始資料和處理後資料兩部分,其統計如下:
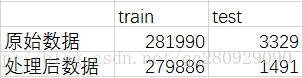
其中,訓練資料不包含標註資訊;測試資料中包含標註資訊,標註類別為預先定義的6個aspect型別,依次為Food、Staff、Ambience、Price、Anecdotes和Miscellaneous,可用於驗證模型的有效性;在處理後資料資料夾中,還包含對應的詞嵌入模型。
下載地址:
1.4 BeerAdvocate
該語料為啤酒評論資料,共150W條評論,可用於細粒度的情感分析任務當中,即aspect extraction任務當中。
由於資源大小的限制,本資源分為原始資料和處理後的資料。在原始資料當中,包含1000條帶標註資訊的評論,共9245條句子,標註類別為Feel、Look、Smell、Taste和Overall五種Aspect類別;在處理後資料當中,包含相應的詞嵌入模型。
原始資料下載地址:BeerAdvocate–Source
處理後資料下載地址:BeerAdvocate–Preprocess
1.5 NLPCC2014評估任務2_基於深度學習的情感分類
該語料共包含中文和英文兩種語言,主要是商品評論,評論篇幅都比較短,可以被應用於篇章級或者句子級的情感分析任務。資料集被分為訓練資料、測試資料、帶標籤的測試資料三個檔案,共有正向和負向兩種極性。
下載地址:NLPCC2014評估任務2_基於深度學習的情感分類
1.6 NLPCC2013評估任務_中文微博觀點要素抽取
該語料主要用於識別微博觀點句中的評價物件和極性。訓練資料由兩個微博主題組成,每個主題各一百條,內含標註及資料說明。
下載地址:NLPCC2013評估任務_中文微博觀點要素抽取
1.7 NLPCC2013評估任務_中文微博情緒識別
該語料主要用於識別出整條微博所表達的情緒,不是簡單的褒貶分類,而是涉及到多個細粒度情緒類別(例如悲傷、憂愁、快樂、興奮等),屬於細粒度的情感分類問題。
下載地址:NLPCC2013評估任務_中文微博情緒識別
1.7 NLPCC2013評估任務_跨領域情感分類
給定已標註傾向性的英文評論資料和英文情感詞典,要求只利用給出的英文情感資源進行中文評論的情感傾向分類。該任務注重考察多語言環境下情感資源的遷移能力,有助於解決不同語言中情感資源分佈的不均衡問題。
下載地址:NLPCC2013評估任務_跨領域情感分類
1.8 NLPCC2012評估任務_面向中文微博的情感分析
該語料主要用於中文微博中的情感句識別、情感傾向性分析和情感要素抽取。
下載地址:NLPCC2012評估任務_面向中文微博的情感分析
1.9 康奈爾大學影評資料集
該語料由電影評論組成,其中持肯定和否定態度的各1,000 篇;另外還有標註了褒貶極性的句子各5331句,標註了主客觀標籤的句子各5000句。該語料可以被應用於各種粒度的情感分析,如詞語、句子和篇章級情感分析研究中。
下載地址:康奈爾大學影評資料集
1.10 MPQA
Janyce Wiebe等人所開發的MPQA(Multiple-Perspective QA)庫:包含535 篇不同視角的新聞評論,它是一個進行了深度標註的語料庫。其中標註者為每個子句手工標註出一些情感資訊,如觀點持有者、評價物件、主觀表示式以及其極性與強度。
下載地址:MPQA
1.11 Twitter Comments
該語料主要來自於Twitter上面的評論資料集,分為訓練資料和測試資料,分別有6248條和692條Twitter。在檔案中,每條推特被分為三行,第一行為評論句子、第二行為評價物件、第三行為情感極性。通常每條句子只包含一個評價物件。在情感極性中,用-1、0、1分別代表負向、中性、正向,三個極性的條數分別在語料中佔25%、50%、25%。該語料來自於以下工作。
Paper:Dong L, Wei F, Tan C, et al. Adaptive Recursive Neural Network for Target-dependent Twitter Sentiment Classification[C]// Meeting of the Association for Computational Linguistics. 2014:49-54.
下載地址:Twitter Comments
2 詞典
2.1 大連理工大學中文情感詞彙本體庫(無輔助情感分類)
中文情感詞彙本體庫是大連理工大學資訊檢索研究室在林鴻飛教授的指導下經過全體教研室成員的努力整理和標註的一箇中文字體資源。該資源從不同角度描述一箇中文詞彙或者短語,包括詞語詞性種類、情感類別、情感強度及極性等資訊。
中文情感詞彙本體的情感分類體系是在國外比較有影響的Ekman的6大類情感分類體系的基礎上構建的。在Ekman的基礎上,詞彙本體加入情感類別“好”對褒義情感進行了更細緻的劃分。最終詞彙本體中的情感共分為7大類21小類。
構造該資源的宗旨是在情感計算領域,為中文文字情感分析和傾向性分析提供一個便捷可靠的輔助手段。中文情感詞彙本體可以用於解決多類別情感分類的問題,同時也可以用於解決一般的傾向性分析的問題。
其資料格式介紹如下:

下載地址為:http://download.csdn.net/download/qq280929090/10215956
由於在某些情感分析文獻當中,需要對情感程度進行歸一化,將隨後新增歸一化版本。
本版本去掉輔助情感分類,主要是由於其對實驗幫助非常小,而且增加了處理的複雜性。
2.2 臺灣大學中文情感極性詞典(NTUSD)
2.3 清華大學李軍中文褒貶義詞典(TSING)
2.4 知網情感詞典(HOWNET)
該詞典主要分為中文和英文兩部分,共包含如下資料:中文正面評價詞語3730個、中文負面評價詞語3116個、中文正面情感詞語836個、中文負面情感詞語1254個;英文正面評價詞語3594個、英文正面評價詞語3563個、英文正面情感詞語769個、英文負面情感詞語1011個。
下載地址:http://download.csdn.net/download/qq280929090/10216044
2.5 知網程度副詞詞典(HOWNET)
2.6 知網主張詞語詞典(HOWNET)
3 預訓練詞嵌入
3.1 Google預訓練詞嵌入
3.2 Glove預訓練詞嵌入
該預訓練詞嵌入根據斯坦福大學提出的Glove模型進行訓練,主要包括如下四個檔案:
1) glove.6B:Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 50d, 100d, 200d, & 300d vectors, 822 MB download)
2) glove.42B.300d:Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download)
3)glove.840B.300d:Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download)
4)glove.twitter.27B:Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 25d, 50d, 100d, & 200d vectors, 1.42 GB download)
下載地址為:Glove預訓練詞嵌入