
用FCN訓練自己的資料集+caffe
FCN模型下載
0. 我的caffe是早就安裝好的。所以不多說,沒安裝的自己百度
1. 我用的是caffe在github上FCN的程式碼和模型,連結是:
我在伺服器上用下面的語句下載這個FCN的工程包“fcn.berkeleyvision.org-master”。由於我只打算用voc-8s的網路,所以後文只針對此網路,別的相似。
git clone https://github.com/shelhamer/fcn.berkeleyvision.org.git模型下載的方法是,點進


自己的資料集
1. 把所有圖片的名字改成從0~N-1,N是你資料集圖片的個數。
我的訓練集是N=440張圖,那麼將原圖(必須是3通道的RGB圖)和label圖(必須得是灰度)的名字都變成0.png~439.png。
我的驗證集是N=94張圖,那麼原圖和label圖都是0.png~93.png
(訓練集和驗證集都是訓練時用的,與測試集不同)
注意:如果你想直接用VOC資料集裡自帶的測試指令碼來分割你的圖片,請把你的圖片類別的RGB值轉成VOC資料集21個類別裡有的顏色。我的資料集的類別是我自己設定的RGB值。所以我自己寫了測試指令碼來還原分割圖的色彩。
2. 把資料放在一個你自己制定的目錄下,並按照原圖和label圖分好。
我的訓練時的原圖在data/train、訓練時的label圖在data/grey;
我的驗證集的原圖在data/val、訓練時的label圖在data/val_grey。
並且生成好訓練集和驗證集的標籤list。如圖,訓練集的是“train.txt”,驗證集的是“segvalid.txt”。

注意:list裡只是數字,沒有“.png”,因為FCN原始碼裡是需要利用這些序號的。
如

訓練
1. 先建立一個資料夾
2. 那麼,solver.prototxt基本不用改,本次訓練是4000次迭代存一個caffemodel,我把最大迭代次數改成了10萬次。
train_net:"train.prototxt"
test_net:"val.prototxt"
test_iter:736
# maketest net, but don't invoke it from the solver itself
test_interval:999999999
display:20
average_loss:20
lr_policy:"fixed"
# lr forunnormalized softmax
base_lr:1e-14
# highmomentum
momentum:0.99
# nogradient accumulation
iter_size:1
max_iter:100000 #最大迭代次數
weight_decay:0.0005
snapshot:4000
snapshot_prefix:"snapshot/"
test_initialization: false3. 需要改的有train.prototxt和val.prototxt。
要改的地方有兩種,先說train.prototxt
(1) data層,我使用的是

我將voc_dir改成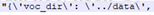
(2) 因為我的資料集的num_output=8,所以我把後面幾層的都改成了8,但是為了使用
至於val.prototxt的改動也是兩種,第二種和上面一樣,說一下data層
我改成了

注意‘spilt’後面是‘segvalid’,也是我驗證集segvalid.txt的名字
4. 然後可以訓練了。
不過得改一下solve.py 中驗證集list的位置:

然後執行
Python2 solve.py
就可以啦。
開始訓練了:但是第一個loss=545113,嚇了一跳

但是驗證的時候,準確率啥的還可以:
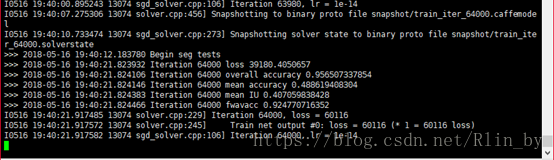
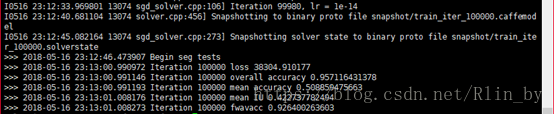
最後訓練10萬次後,我的結果如下:
測試
本文參考https://www.cnblogs.com/k7k8k91/p/7989630.html,可以參考裡面的單張圖的分割,
主要用的是deploy.prototxt和infer.py。記得把deploy.prototxt裡後面層的名字改成和train.prototxt一致的。然後把
裡的caffemodel換成自己的。
p.s. 本人大四,以上都是自己摸索做的,如有不對的地方,還請前輩們指點。