
基於訊息的分散式架構設計
分散式設計與開發中有些疑難問題必須藉助一些演算法才能解決,比如分散式環境一致性問題,感覺以下分散式演算法是必須瞭解的(隨著學習深入有待新增):
- Paxos演算法
- 一致性Hash演算法
Paxos演算法
1)問題描述
分散式中有這麼一個疑難問題,客戶端向一個分散式叢集的服務端發出一系列更新資料的訊息,由於分散式叢集中的各個服務端節點是互為同步資料的,所以執行完客戶端這系列訊息指令後各服務端節點的資料應該是一致的,但由於網路或其他原因,各個服務端節點接收到訊息的序列可能不一致,最後導致各節點的資料不一致。舉一個例項來說明這個問題,下面是客戶端與服務端的結構圖:
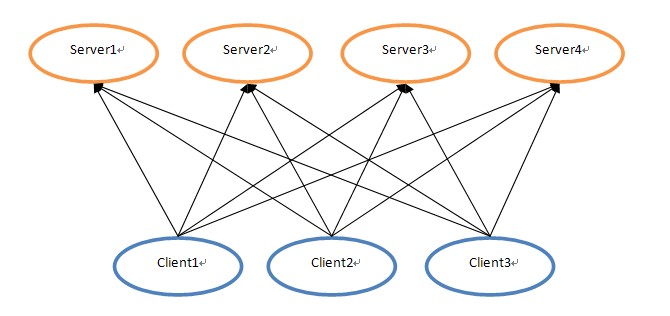
當client1、client2、client3分別發出訊息指令A、B、C時,Server1~4由於網路問題,接收到的訊息序列就可能各不相同,這樣就可能由於訊息序列的不同導致Server1~4上的資料不一致。對於這麼一個問題,在分散式環境中很難通過像單機裡處理同步問題那麼簡單,而Paxos演算法就是一種處理類似於以上資料不一致問題的方案。
2)演算法本身
演算法本身我就不進行完整的描述和推導,網上有大量的資料做了這個事情,但我學習以後感覺萊斯利·蘭伯特(Leslie Lamport,paxos演算法的奠基人,此人現在在微軟研究院)的Paxos Made Simple 是學習paxos最好的文件,它並沒有像大多數演算法文件那樣搞一堆公式和數學符號在那裡嚇唬人,而是用人類語言讓你搞清楚Paxos要解決什麼問題,是如何解決的。這裡也藉機抨擊一下那些學院派的研究者,要想讓別人認可你的成果,首先要學會怎樣讓大多數人樂於閱讀你的成果,而這個描述Paxos演算法的文件就是我們學習的榜樣。
言歸正傳,透過Paxos演算法的各個步驟和約束,其實它就是一個分散式的選舉演算法,其目的就是要在一堆訊息中通過選舉,使得訊息的接收者或者執行者能達成一致,按照一致的訊息順序來執行。其實,以最簡單的想法來看,為了達到大夥執行相同序列的指令,完全可以通過序列來做,比如在分散式環境前加上一個FIFO佇列來接收所有指令,然後所有服務節點按照佇列裡的順序來執行。這個方法當然可以解決一致性問題,但它不符合分散式特性,如果這個佇列down掉或是不堪重負這麼辦?而Paxos的高明之處就在於允許各個client互不影響地向服務端發指令,大夥按照選舉的方式達成一致,這種方式具有分散式特性,容錯性更好。
說到這個選舉演算法本身,可以聯想一下現實社會中的選舉,一般說來都是得票者最多者獲勝,而Paxos演算法是序列號更高者獲勝,並且當嘗試提交指令者被拒絕時(說明它的指令所佔有的序列號不是最高),它會重新以一個更好的序列參與再次選舉,通過各個提交者不斷參與選舉的方式,達到選出大夥公認的一個序列的目的。也正是因為有這個不斷參與選舉的過程,所以Paxos規定了三種角色(proposer,acceptor,和 learner)和兩個階段(accept和learn),三種角色的具體職責和兩個階段的具體過程就見Paxos Made Simple ,另外一個國內的哥們寫了個不錯的PPT ,還通過動畫描述了paxos執行的過程。不過還是那句話不要一開始就陷入演算法的細節中,一定要多想想設計這些遊戲規則的初衷是什麼。
Paxos演算法的最大優點在於它的限制比較少,它允許各個角色在各個階段的失敗和重複執行,這也是分散式環境下常有的事情,只要大夥按照規矩辦事即可,演算法的本身保障了在錯誤發生時仍然得到一致的結果。
3)演算法的實現
Paxos的實現有很多版本,最有名的就是google chubby ,不過看不了原始碼。開源的實現可見libpaxos 。另外,ZooKeeper 也基於paxos解決資料一致性問題,也可以看看它是如果實現paxos的。
4)適用場景
弄清楚paxos的來龍去脈後,會發現它的適用場景非常多,Tim有篇blog《Paxos在大型系統中常見的應用場景》專門談這個問題。我所見到的專案裡,naming service是運用Paxos最廣的領域,具體應用可參考ZooKeeper
一致性Hash演算法
1)問題描述
分散式常常用Hash演算法來分佈資料,當資料節點不變化時是非常好的,但當資料節點有增加或減少時,由於需要調整Hash演算法裡的模,導致所有資料得重新按照新的模分佈到各個節點中去。如果資料量龐大,這樣的工作常常是很難完成的。一致性Hash演算法是基於Hash演算法的優化,通過一些對映規則解決以上問題
2)演算法本身
對於一致性Hash演算法本身我也不做完整的闡述,有篇blog《一致性hash演算法 - consistent hashing》 描述這個演算法非常到位,我就不重複造輪子了。
實際上,在其他設計和開發領域我們也可以借鑑一致性Hash的思路,當一個對映或規則導致有難以維護的問題時,可以考慮更一步抽象這些對映或規則,通過規則的變化使得最終資料的不變。一致性hash實際就是把以前點對映改為區段對映,使得資料節點變更後其他資料節點變動儘可能小。這個思路在作業系統對於儲存問題上體現很多,比如作業系統為了更優化地利用儲存空間,區分了段、頁等不同緯度,加了很多對映規則,目的就是要通過靈活的規則避免物理變動的代價
3)演算法實現
一致性Hash演算法本身比較簡單,不過可以根據實際情況有很多改進的版本,其目的無非是兩點:
- 節點變動後其他節點受影響儘可能小
- 節點變動後資料重新分配儘可能均衡
實現這個演算法就技術本身來說沒多少難度和工作量,需要做的是建立起你所設計的對映關係,無需藉助什麼框架或工具,sourceforge上倒是有個專案libconhash ,可以參考一下
以上兩個演算法在我看來就算從不涉及演算法的開發人員也需要了解的,演算法其實就是一個策略,而在分散式環境常常需要我們設計一個策略來解決很多無法通過單純的技術搞定的難題,學習這些演算法可以提供我們一些思路。