
深度學習入門基礎講義
工作確定以後,閒暇時間做了如下一個PPT講義,用於向實驗室新生介紹深度學習。他們大部分在本科期間學習通訊相關專業課程,基本沒有接觸過影象處理和機器學習。
對於一個研究生而言,自學應當是一個最基本也是最重要的能力。自學不僅是獨立學習,更是主動學習。因此,該講義的目的主要是使其對深度學習有一個初步的認識,並順便了解一些常見的概念。 而真正走進深度學習,還需要各自的努力。
該講義儘量用一些淺顯的話語來介紹。囿於水平,一些講解可能存在模糊甚至錯誤的情況,歡迎大家提出寶貴的意見。此外,希望補充某些內容,也可以留言或者私信。
PPT中有些圖來自於網路,如果有侵權可以聯絡刪除。
講義整體包含三部分:
- 相關基礎
- 深度卷積神經網路
- 深度學習應用示例
一、相關基礎
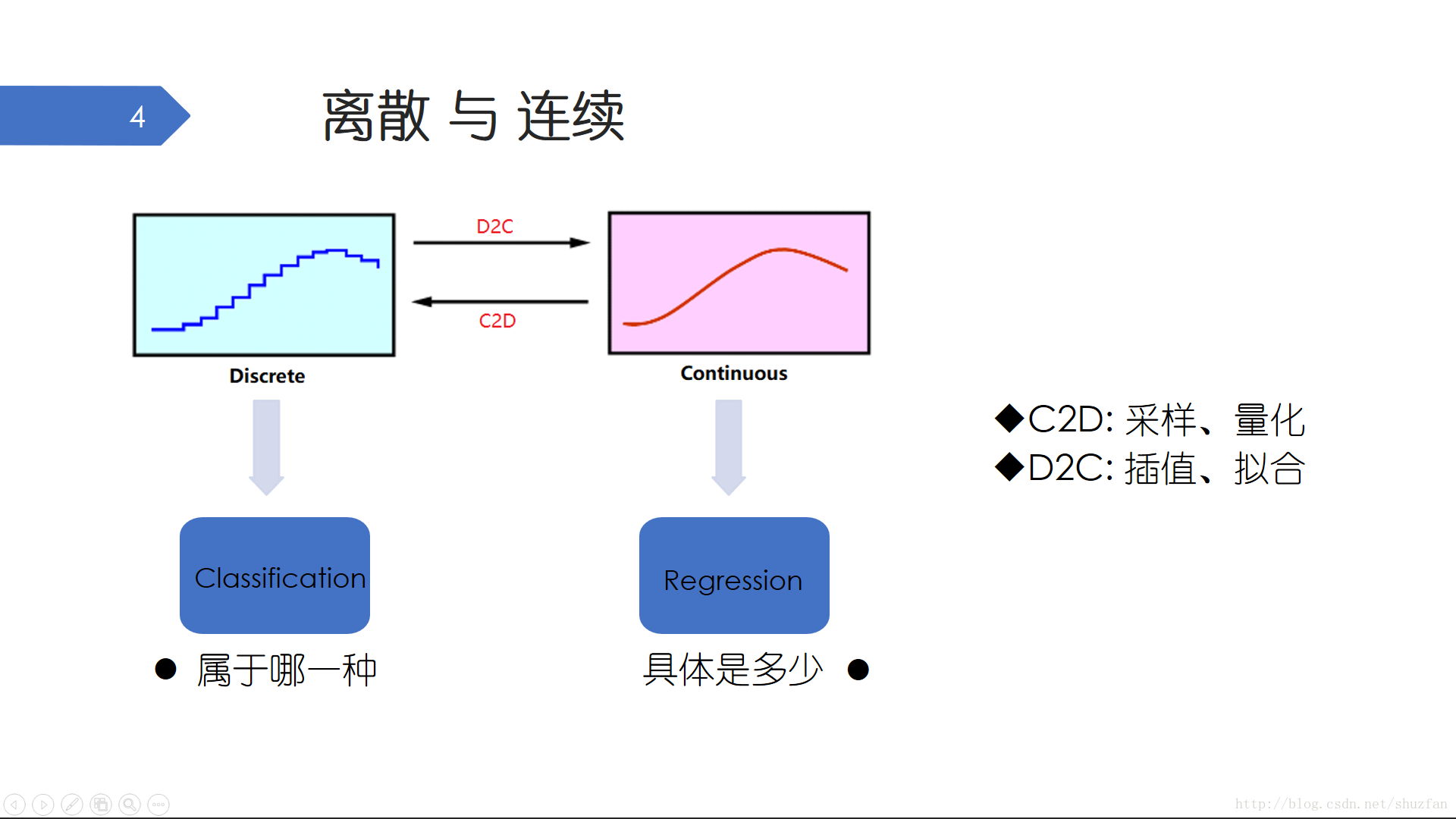
關於世界是離散還是連續的目前還沒有定論,但多數人傾向於 “世界是連續的,認知是離散的”。 對於通訊系統或者訊號處理專業的同學而言,離散和連續是一對熟悉而又重要的概念,它們可以相互轉化。我們通常採用 取樣量化 的方式將連續訊號轉化為離散訊號,比如音效卡裝置的採集原理(稍好點的音效卡都可以調節取樣頻率以及位深度等引數)。離散訊號轉化為連續訊號通常採用 插值擬合 的方式來進行逼近,比如等高線地圖的繪製、遊戲地圖的渲染。
對於機器學習而言,幾乎所有的任務都可以歸類為 離散的分類 任務和 連續的迴歸 任務。當我們面對一個機器學習問題時,可能需要以離散和連續的角度從巨集觀上認識該問題,並注意離散和連續的轉化。
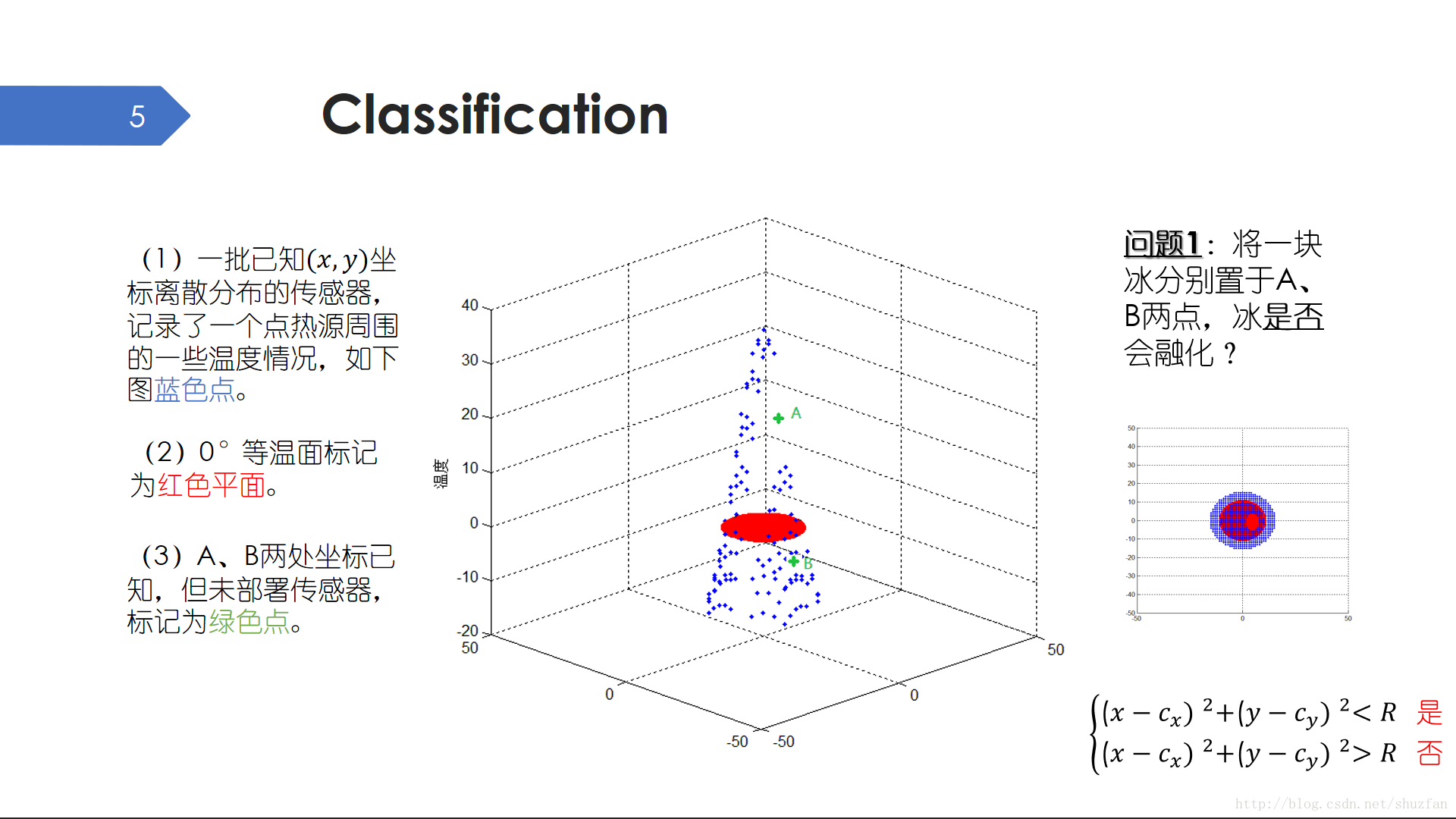
分類是一個典型的離散問題。如上面的三維空間點圖,每一個藍色點都是點熱源附近的一個溫度感測器。可惜的是,由於感測器部署位置以及損壞的原因,在綠色點A和B我們沒有測得有效的溫度資料。現在的問題是,如果我們將一塊冰分別置於A和B兩點,冰是否
會融化?
“是或者不是”,這是一個典型的二分類問題。解決這個問題很簡單,我們甚至根本不用具體知道A和B兩點的溫度。我們只需要設定一個距離閾值,然後計算A、B兩點距點熱源的距離是否大於該閾值就可以了。
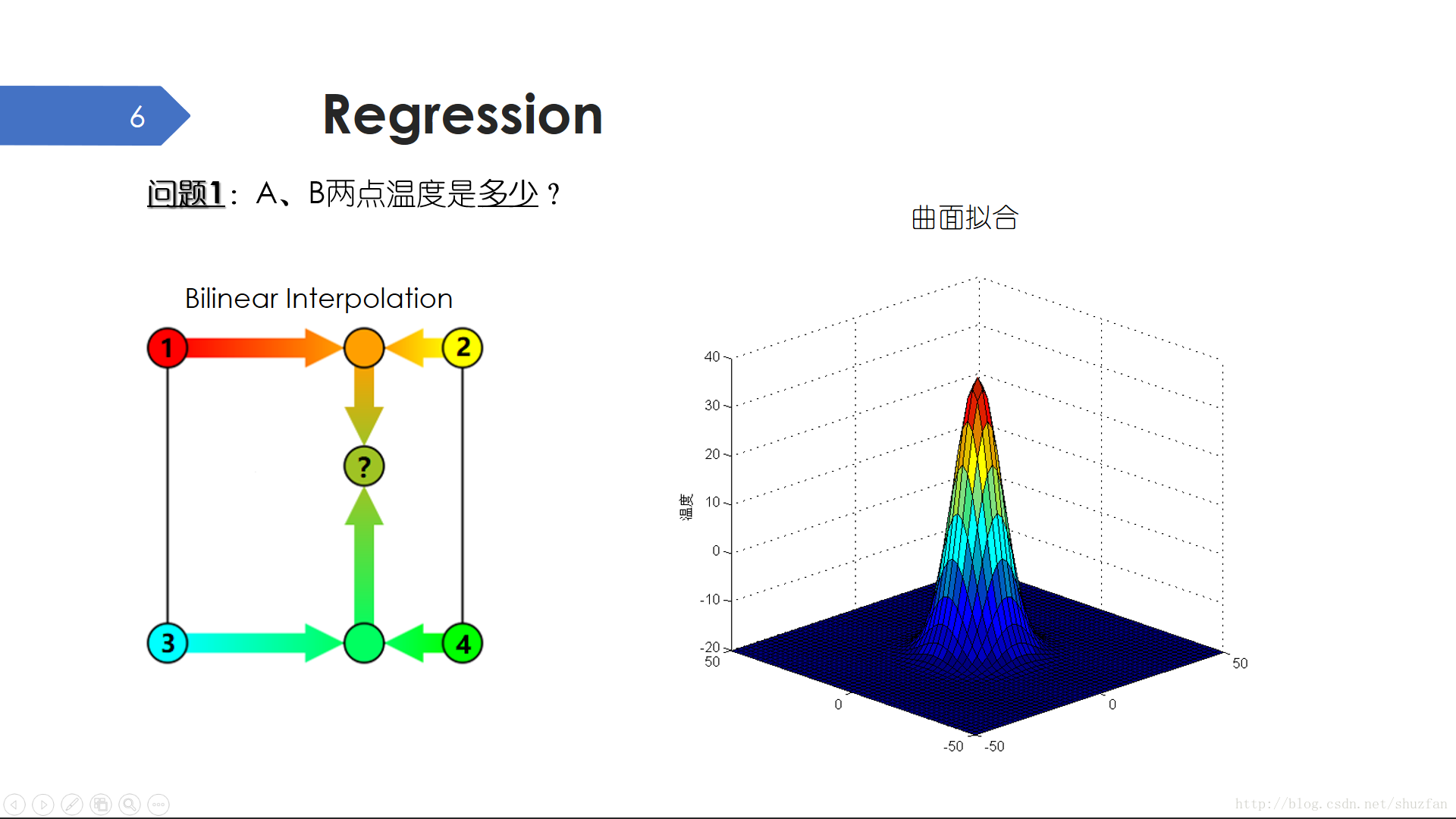
迴歸是一個典型的離散到連續的問題。還是上面的圖,如果我們想要知道A、B兩點的具體溫度該怎麼辦?
一個常見的方法是 “插值”,比如左圖所示的 “雙線性插值”
插值僅僅利用了未知點附近的資訊,沒有考慮全域性的分佈。事實上,感測器所測量的溫度恰好符合如右圖所示的高斯曲面。於是,如果我們找到了這樣一個可以儘可能描述溫度資料分佈的曲面方程,那麼A、B兩點的溫度直接就可以知道了。
通過上面的例子,我們除了要認識到“離散”和“連續”之間的區別,也要學會思考二者之間的聯絡。畢竟,如果知道了具體的溫度,也就直接解決了那塊冰會不會融化的問題。
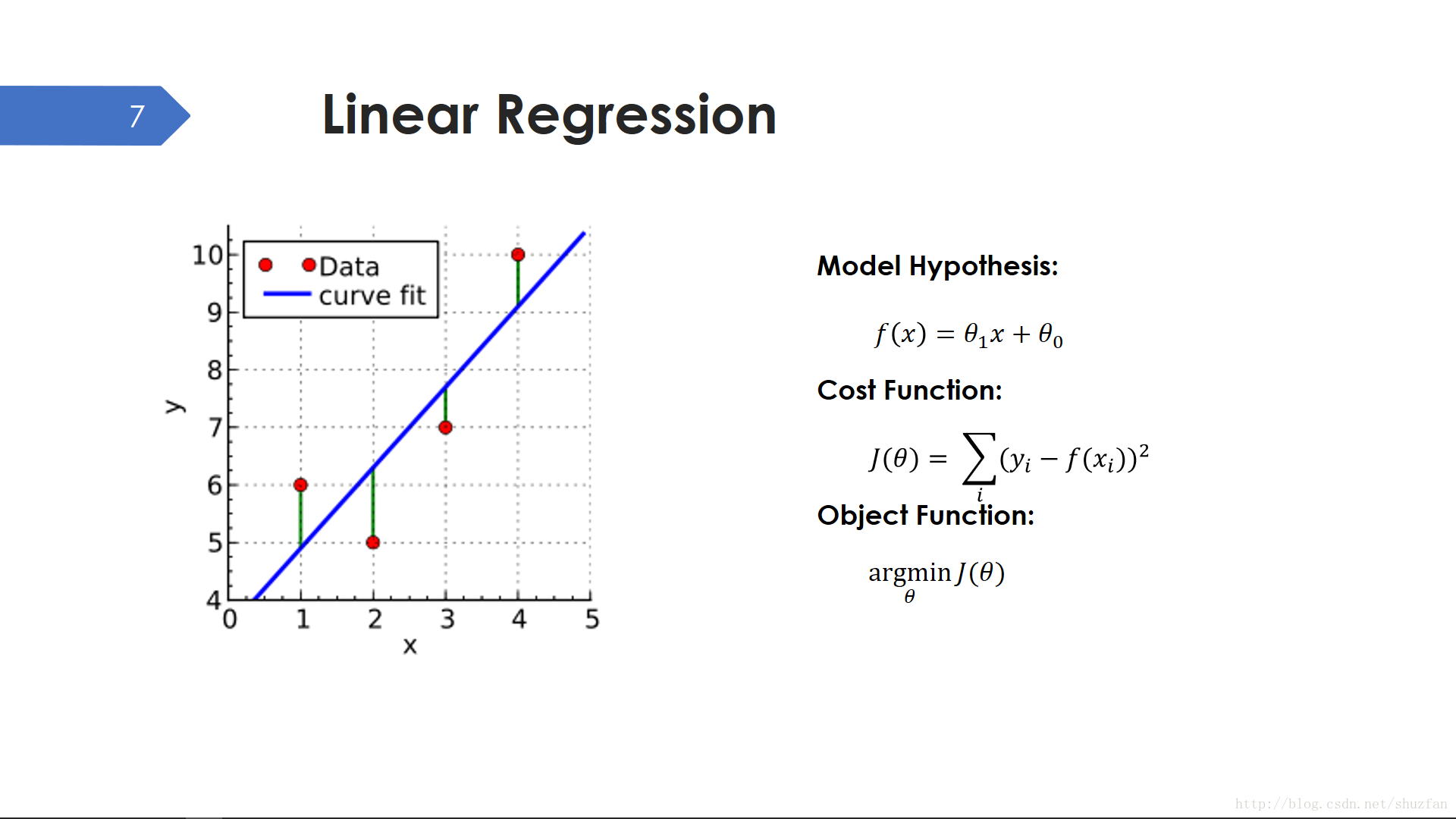
線性迴歸可以說是最簡單的也是我們接觸最早的機器學習方法,因為線性迴歸出現在很多中學數學教材中。線性迴歸的問題很簡單,如上右圖所示,尋找一條最“貼合”的直線。所以我們假設的模型就是一條直線,有2個未知引數(斜率和截距);然後我們繼續定義一個代價函式(有些地方也稱損失函式 loss function),這個代價函式其實就是一個歐氏距離平方和;最後我們的目標函式就是最小化代價。
模型假設 —— 代價函式 —— 目標函式,基本是解決一個機器學習問題所必備的三個要素和步驟。
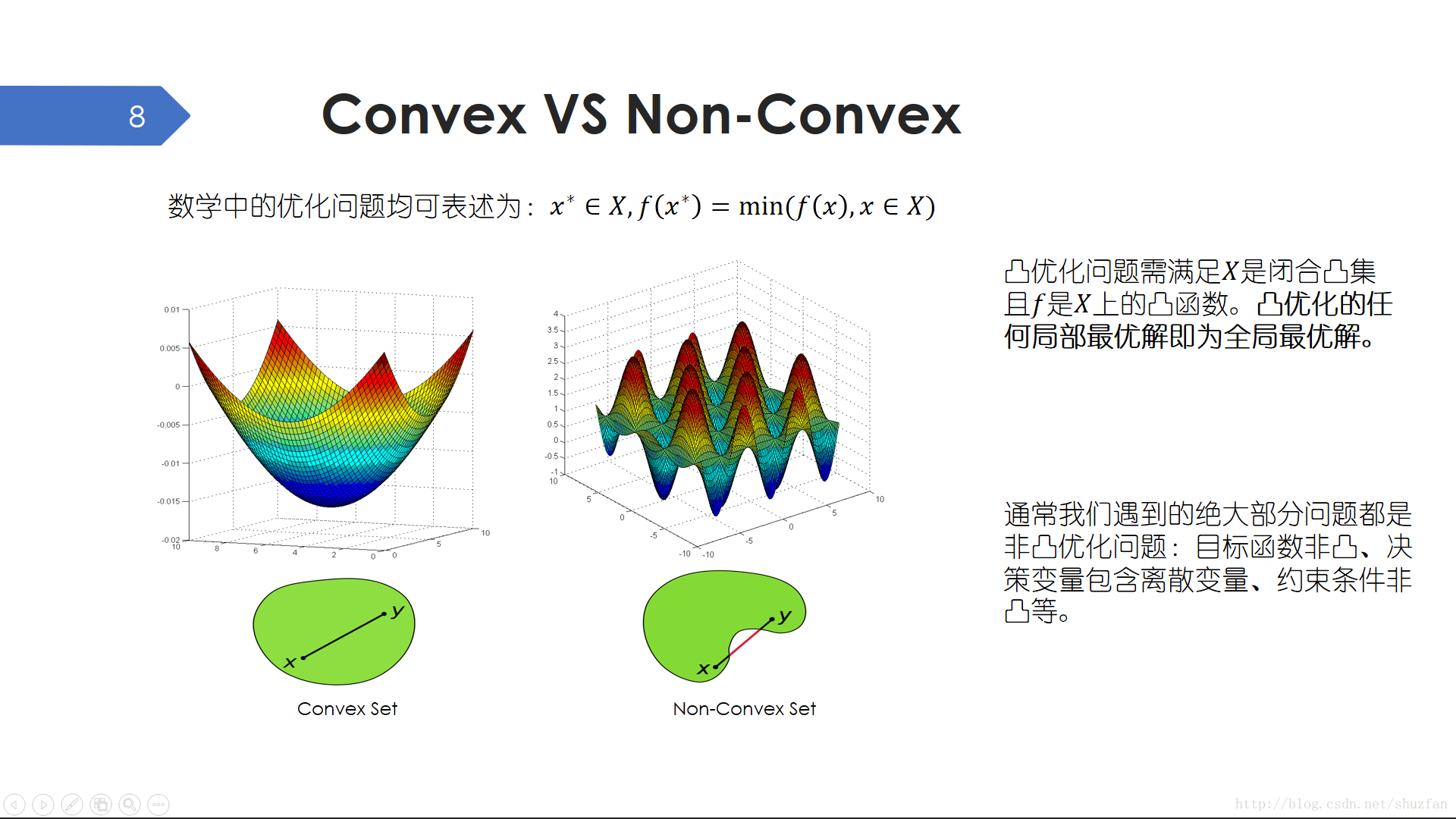
數學中所有的優化問題都可以描述為在一個解空間中找到使目標值最小的解的問題。然後,這類最優化問題又可以被分為 凸優化 和 非凸優化問題。 凸優化是一個非常簡單的問題,並且有著一個特別好的性質:任何區域性最優解即為全域性最優解。但是,絕大部分實際問題都是非凸的,直觀上體現為解空間有著很多區域性最小點。
幸好,我們的直線擬合問題是一個簡單的凸優化問題,其有著唯一最優解(當資料點對稱分佈時可能不滿足)。
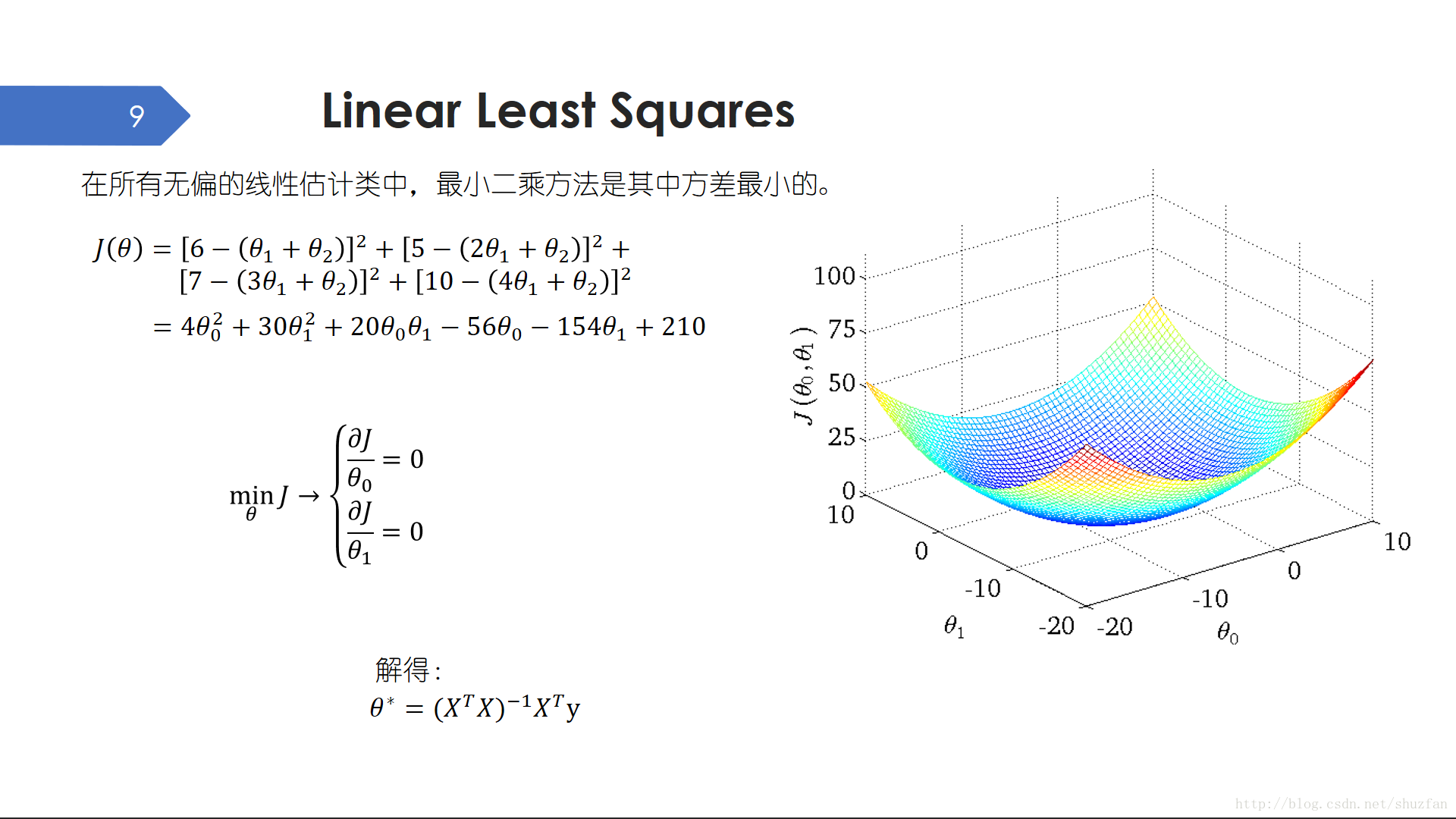
為了求解直線引數,我們之前定義了最小化誤差的平方和作為我們的損失函式。為什麼用誤差平方和而不是用誤差絕對值?誤差的立方?
於是,我們又要引入最小二乘法(又稱最小平方法)這種數學優化技術。在所有無偏的線性估計類中,最小二乘方法是其中方差最小的。
當我們把資料點帶入目標函式並整理,我們發現這只是一個簡單的雙變數二次函式,其解空間如上右圖所示,即只有一個全域性最小點。 此時,極值點即為全域性最小點。因此,我們令偏導數為0,則可以求出一個解。
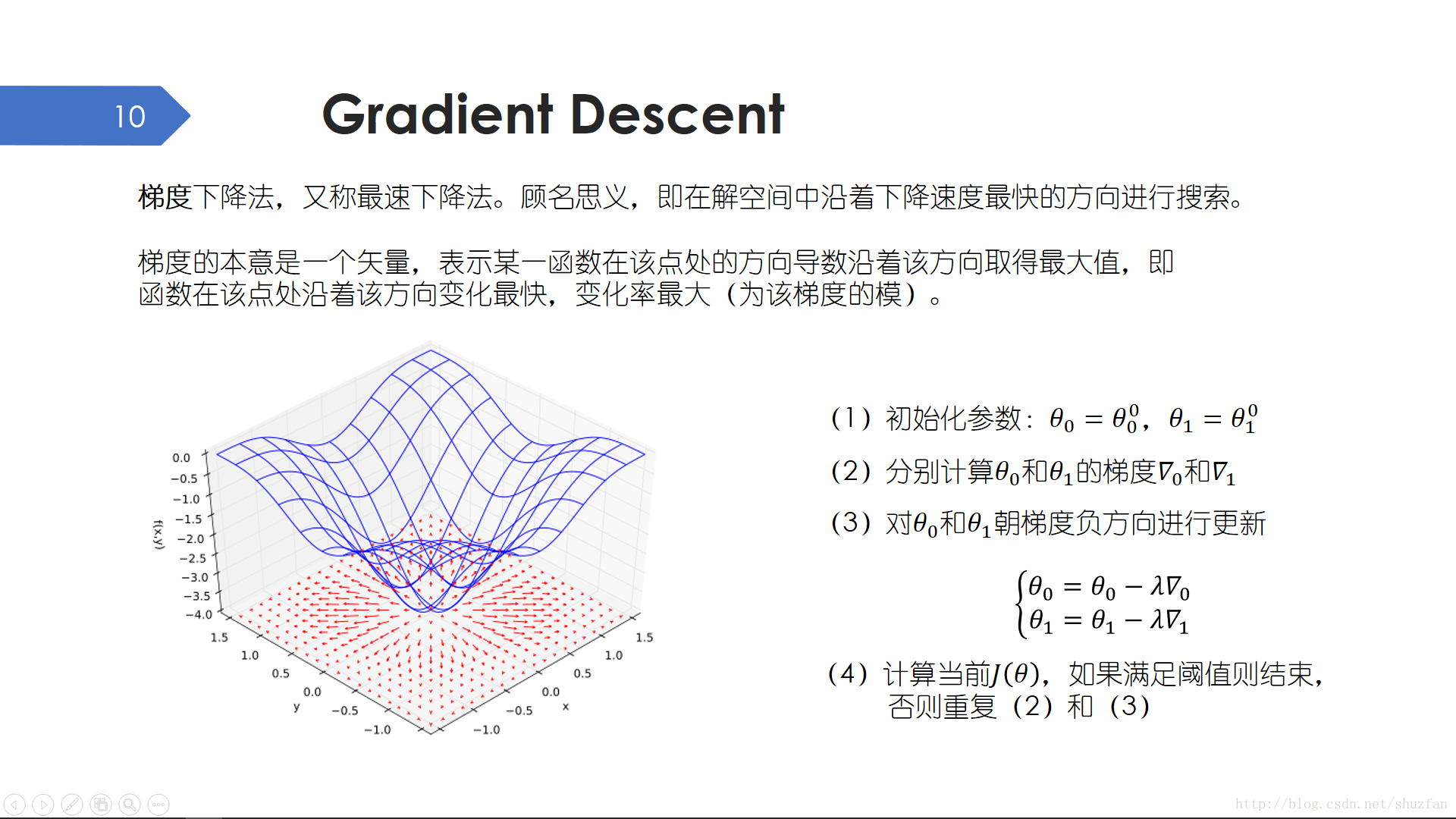
上面我們已經根據偏導為0求出了線性迴歸的統一解,但是這種方法並不是一直有效的,特別是矩陣求逆困難或者不能求逆時。為此,這裡引入另外一種經典的數值優化方法 —— 梯度下降法。
梯度下降法,又稱最速下降法。顧名思義,即在解空間中沿著下降速度最快的方向進行搜尋。最簡單的,一條直線,其梯度就是其斜率,那麼我們沿著斜率的反方向移動,數值下降的最快。上左圖中藍色曲線表示 \(f(x,y)=-(cos^2x+cos^2y)^2\), 下面的紅色箭頭表示每一點的梯度。
於是,簡單的梯度下降方法就是初始化引數後不斷迭代執行 計算梯度 <——> 更新引數,直至目標函式值滿足要求。
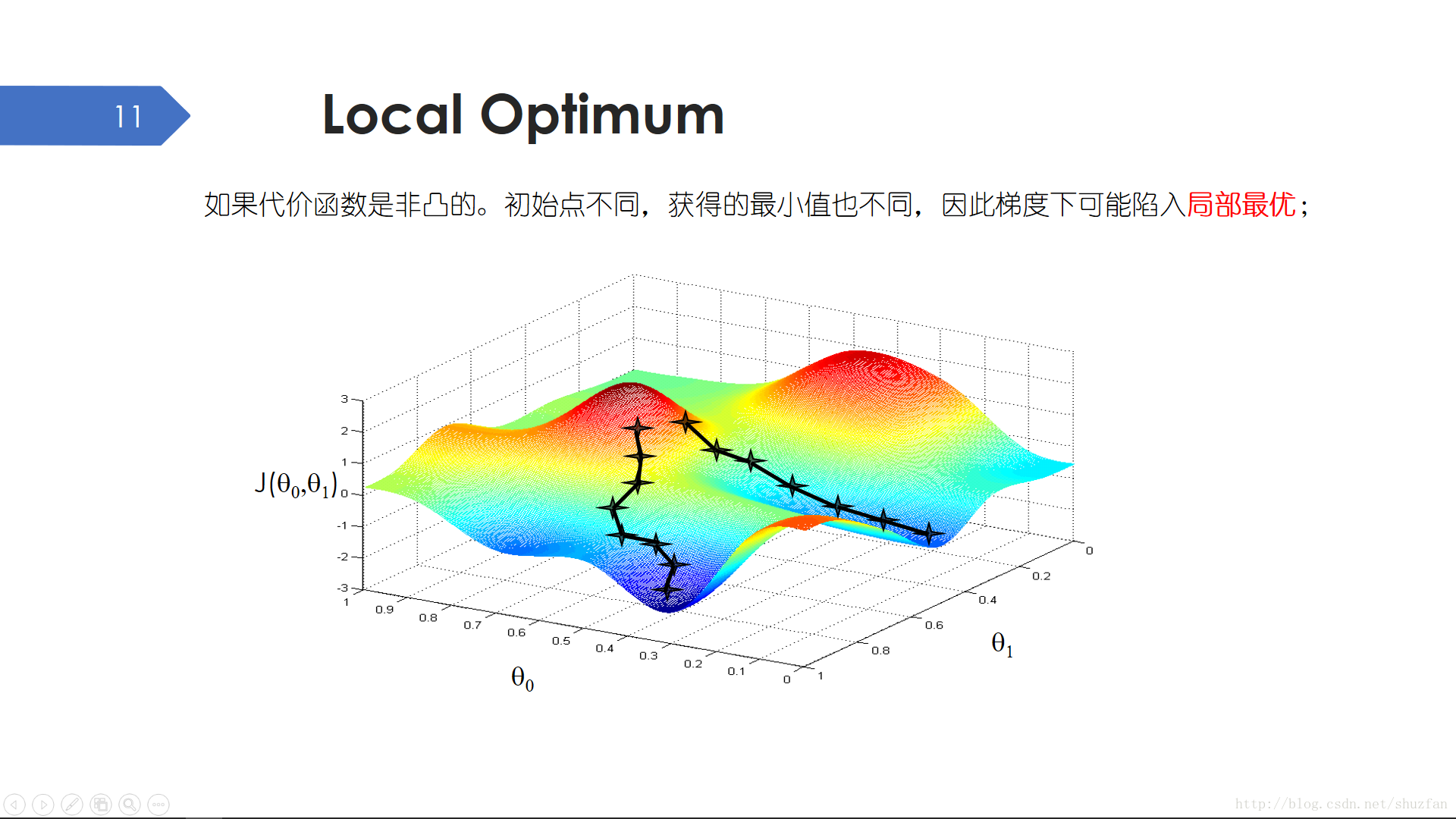
由於梯度下降演算法需要隨機初始化引數,因此當解空間有多個極小值點時,梯度下降演算法有可能會陷入區域性最優。
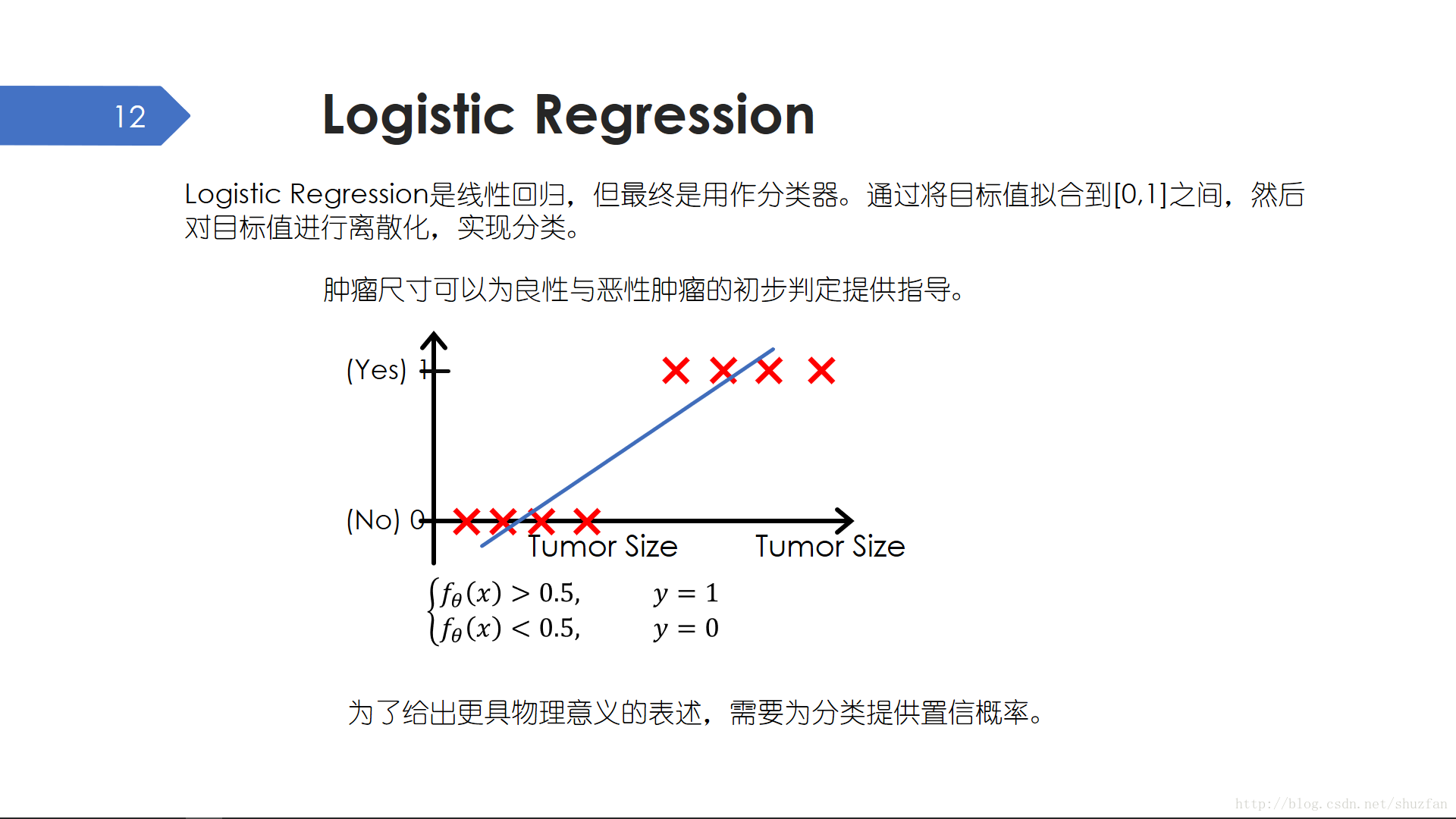
線性迴歸用於連續數值迴歸,邏輯迴歸則用做離散的二分類。比如,腫瘤可以分為良性腫瘤與惡性腫瘤,一般需要病理切片才可以確診,但可以通過觀察腫瘤尺寸來為初步判定提供指導。上圖橫軸表示腫瘤尺寸,縱軸非0即1表示是否為惡性腫瘤。我們可以利用前面的線性迴歸方法找到一條直線,然後醫生診斷時可以將患者的腫瘤尺寸代入直線方程,如果迴歸得到的數值大於0.5則判斷為惡性腫瘤。
上面的例子其實說明了:迴歸 + 判決 ——> 分類。
但是,如果患者問醫生:“我有多大機率是惡性腫瘤?” 醫生該怎麼回答。
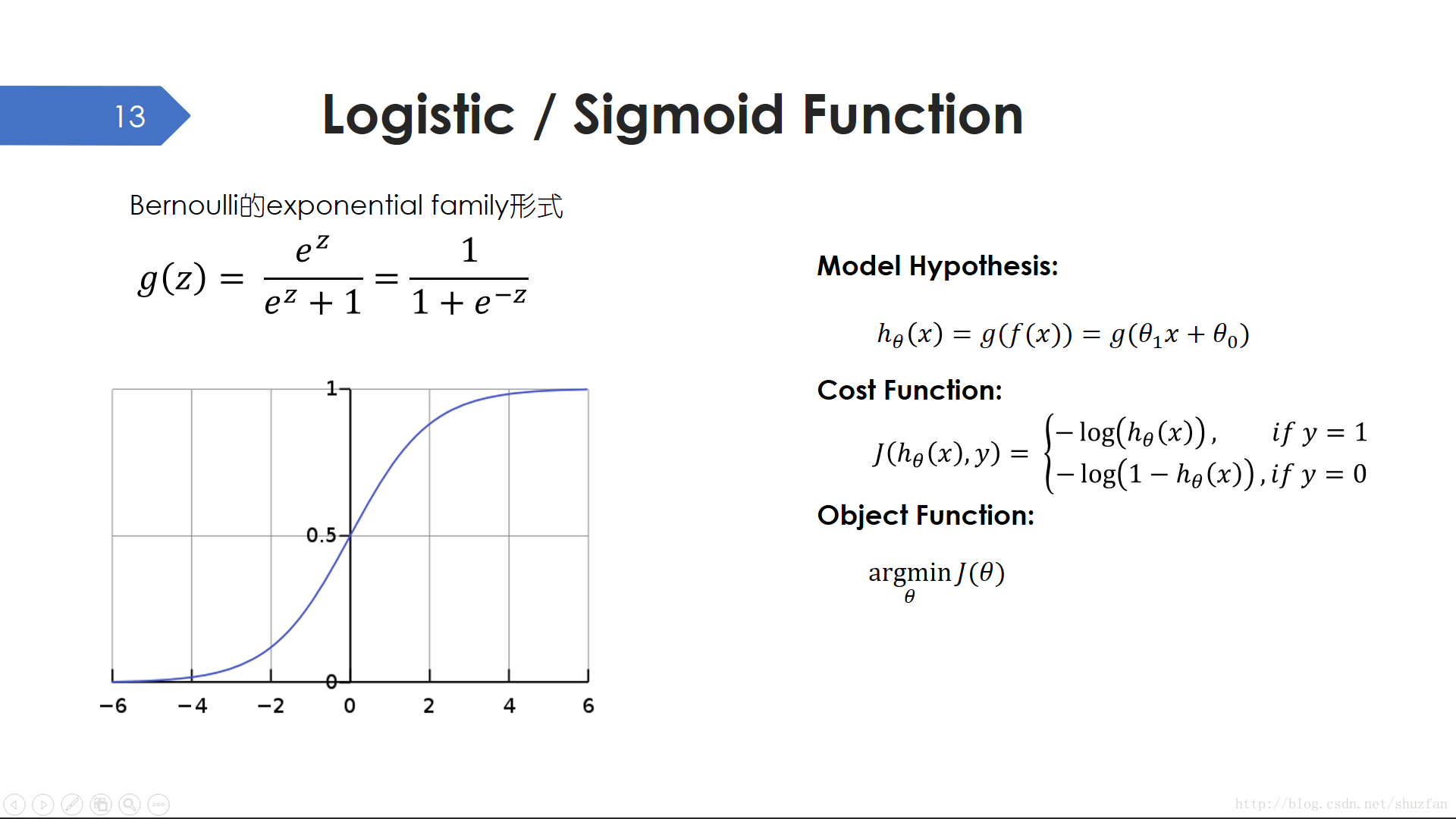
為了獲得有意義的概率輸出,我們需要追加一個Logistic非線性函式。由於該函式長得像“S”形,所以又叫Sigmoid函式。 該函式可以把無窮區間內的數值壓縮到 [0,1] 之間。
於是,我們的模型假設,完整的邏輯迴歸,相當於線性迴歸加上一個非線性Logistic函式。而我們的代價函式也變成了交叉熵。

原始的邏輯迴歸只能用於處理二分類問題,但實際中更多的問題其實是多分類問題。最簡單的將二分類技術應用於N分類問題的方法是:訓練N個二分類器。
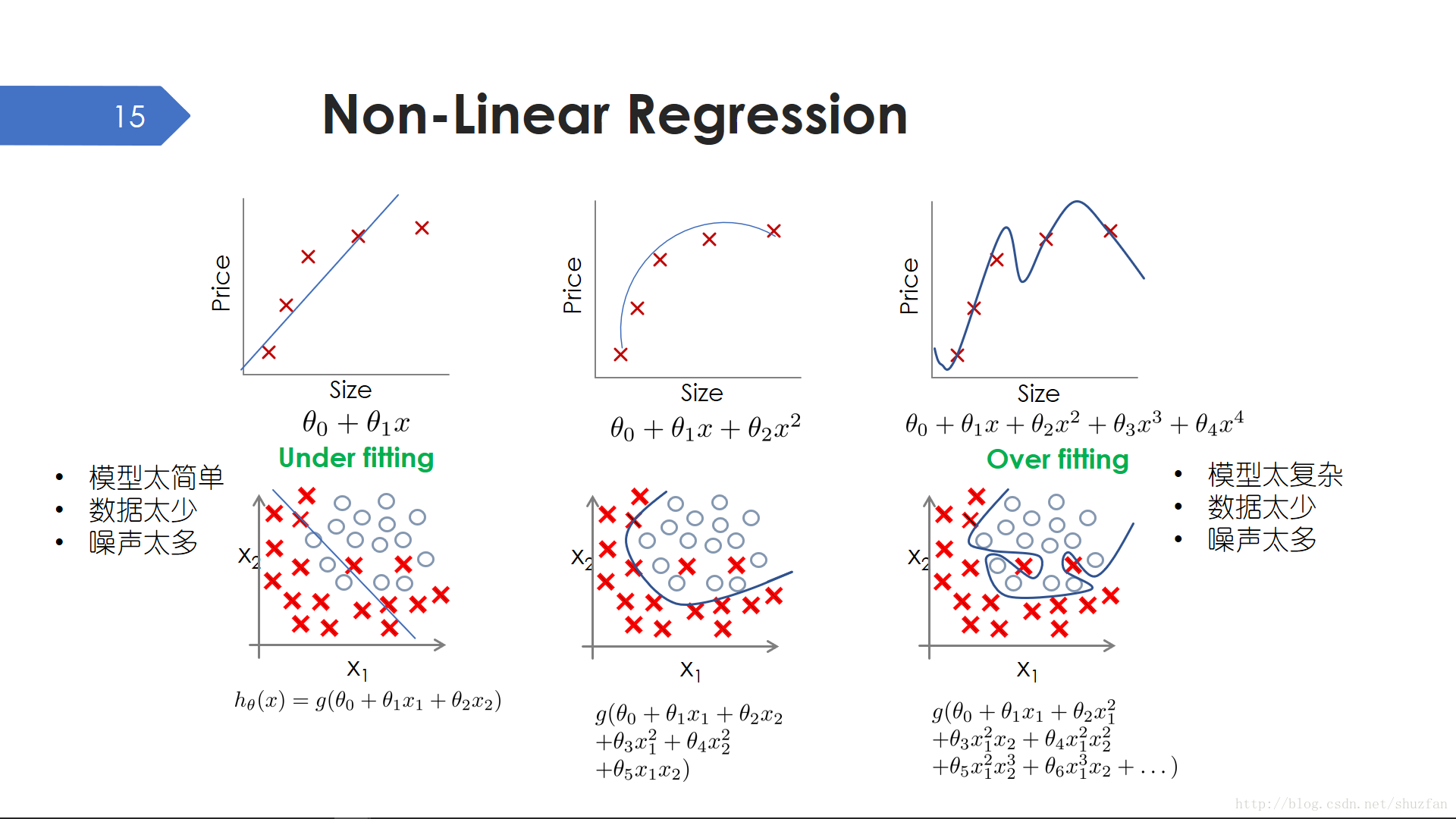
上面我們使用了最簡單的線性假設,當我們的模型假設上升為更高階的非線性模型時,我們便引入了非線性迴歸。
非線性迴歸其實和線性迴歸很多地方非常相似,但有一點需要注意,那就是 過擬合 的問題。上左圖是一個典型的一次模型欠擬合的示例,欠擬合表示模型能力不足以描述資料分佈;當採用二次模型時,資料擬合就比較合理了;但是當採用更高階的四次模型時,我們會發現曲線 過度 擬合了資料,雖然曲線經過了每個樣本點,但直觀上這並不是我們想要的。
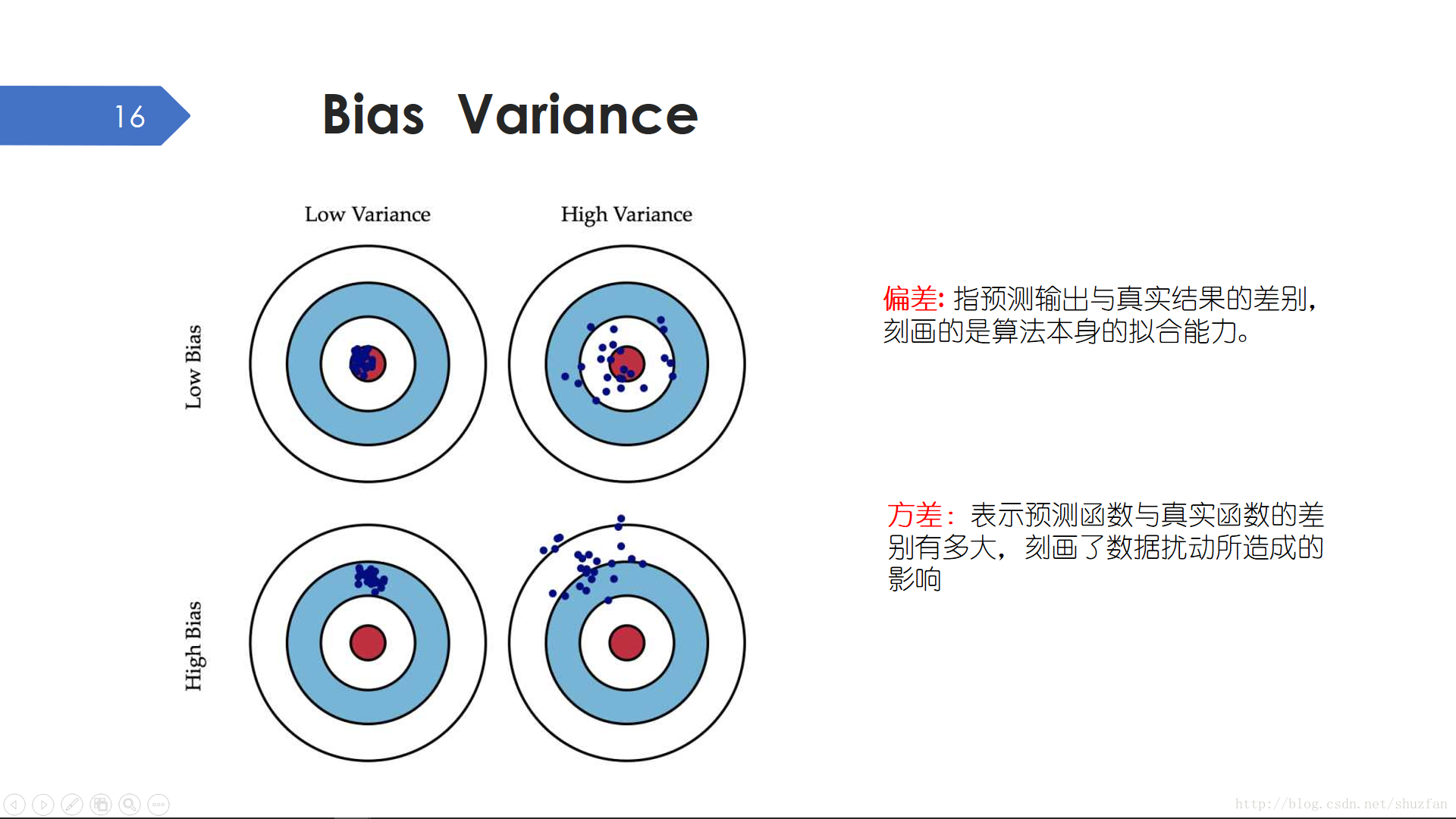
在上一張PPT中,我們通過畫圖的形式比較直觀的觀察了欠擬合和過擬合的樣子。這裡引入 Bias(偏差) 和 Variance(方差)來定量的描述這幾種模型狀態。
偏差: 偏差描述的是模型的準確性,偏差比較大表明模型欠擬合。在靶標圖上表示為:落點遠離靶心。
方差: 方差描述的是模型的穩定性,方差比較大通常表示過擬合。在靶標圖上表示為:落點非常散亂。
偏差的概念比較好理解,方差的概念可能還需要再次解釋一下。 大家可能聽說過Bagging方法:採用同一種模型假設,有放回地從訓練資料中抽取一部分資料,然後重複得到N個模型。如果這N個模型實際測試時表現差異很大,就可以認為是高方差。
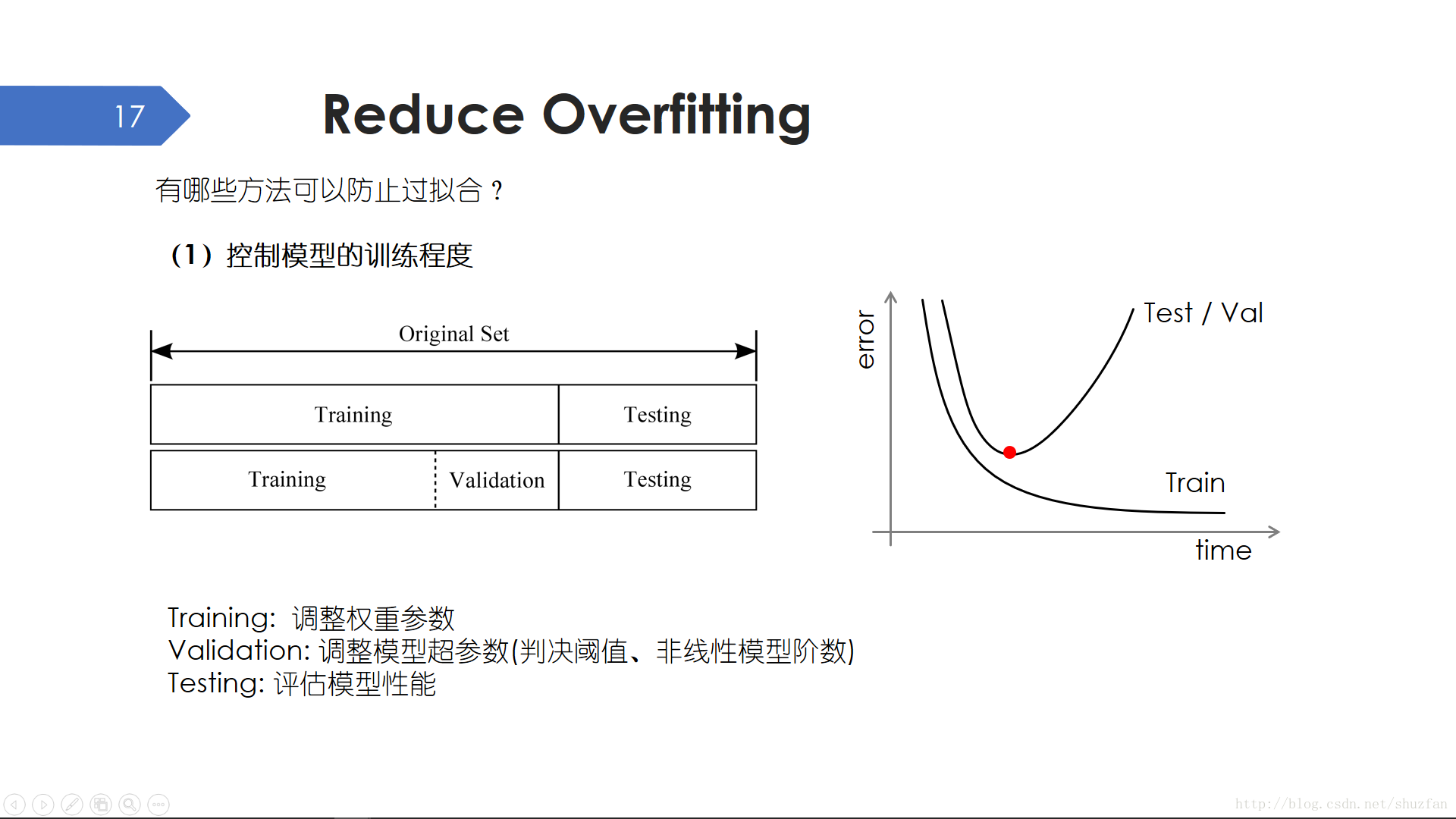
過擬合在模型訓練中是經常遇到的問題。防止過擬合的一個有效方法就是控制模型的訓練程度。
我們通常會將資料劃分為兩部分(訓練集和測試集)或者三部分(訓練集、驗證集和測試集)。訓練集用來學習模型引數,比如邏輯迴歸中的直線斜率和截距;驗證集用來調整一些模型超引數,比如邏輯迴歸分類惡性腫瘤中,我們將概率閾值設為0.5;測試集用來測試模型的效能。
我們可以在訓練過程中不斷繪製訓練誤差和測試誤差相對訓練時間的變化曲線,通過觀察曲線我們來判斷是否過擬合。顯然,測試誤差逐漸增大,訓練誤差持續減小,二者差距逐步擴大,表明模型正在經受過擬合的風險。
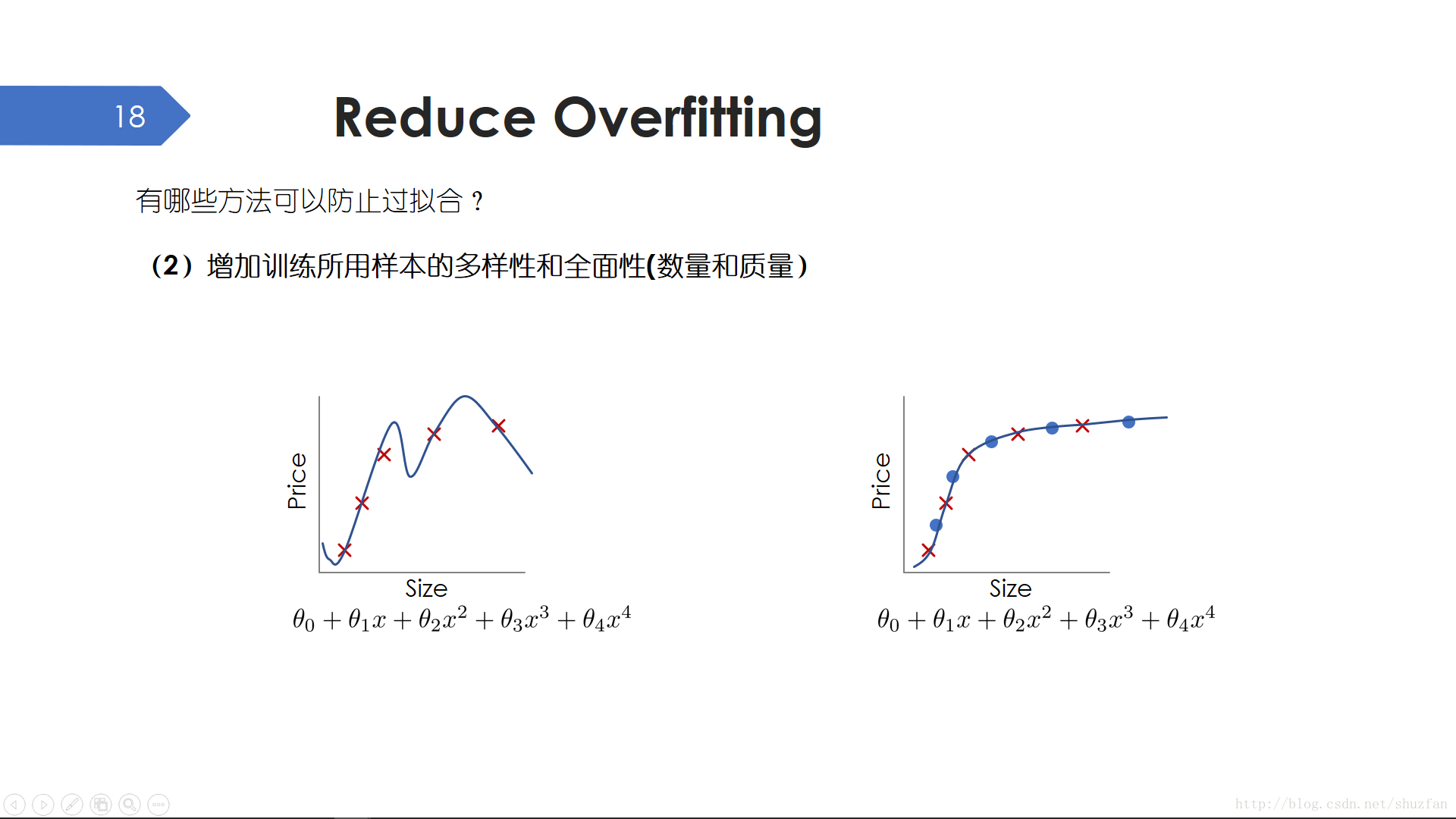
降低過擬合最有效最直接的方法還是增加更多高質量的訓練樣本。有些時候,冥思苦想怎麼解決過擬合,還不如多搞點資料立竿見影。因為,資料多了通常更利於我們發現和學習統計規律。

另外一種普遍使用的防止過擬合的方法就是控制模型的複雜度。顯然從前面的例子我們知道,複雜的模型更容易過擬合,但過於簡單的模型又容易欠擬合。 那我們該如何選擇一個合適複雜度的模型?一種比較呆的方式是準備一系列複雜度由低到高的模型進行訓練,然後觀察其測試集表現。
通過觀察不同的模型表示式,我們可以發現如果對高階項的係數加以約束,那麼高階模型便可以退化為低階模型,從而降低模型複雜度。於是,我們修改之前的代價函式,在原來的基礎上增加對引數的約束,主要包括L1正則化(絕對值)和L2正則化(平方)。
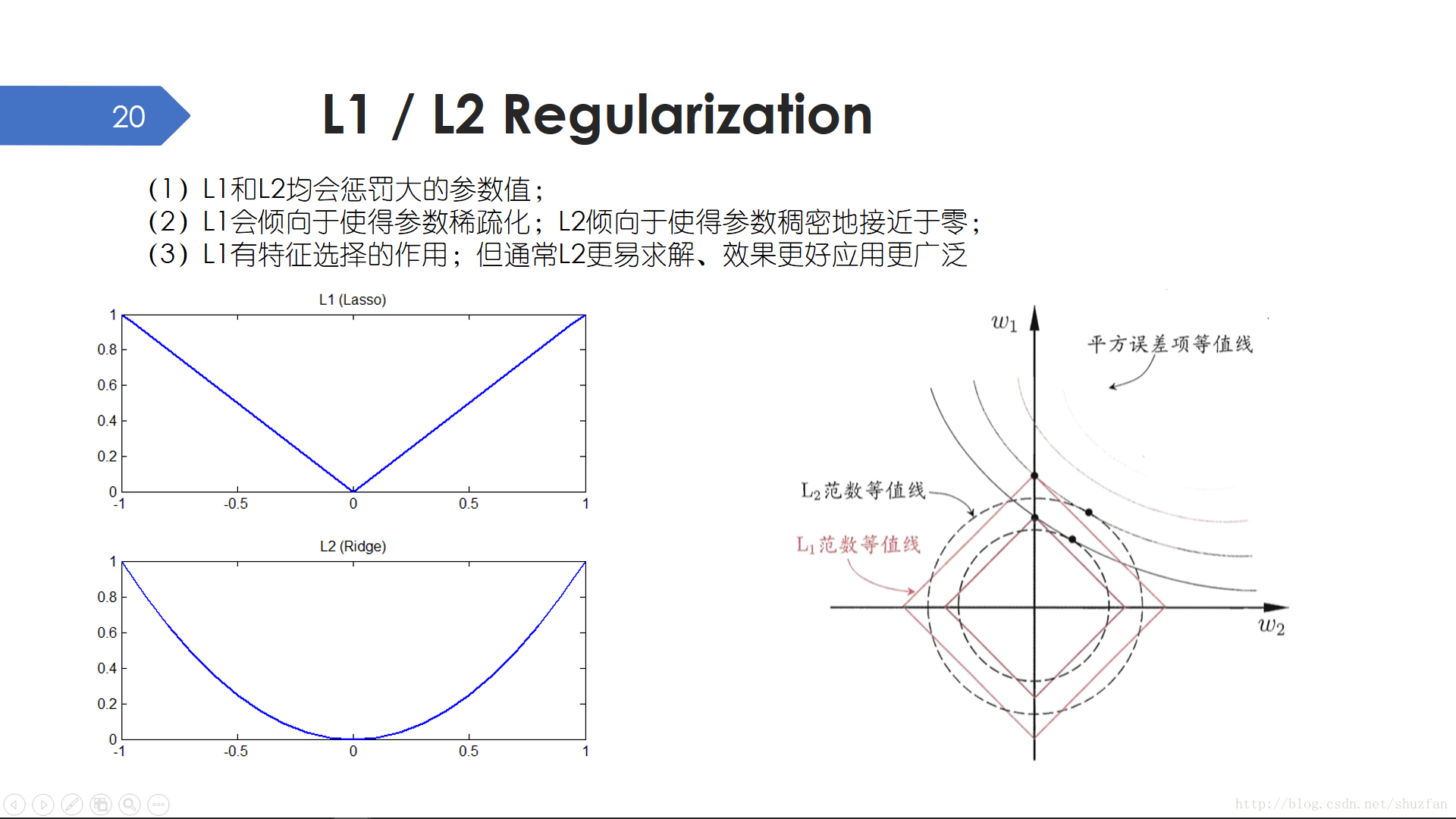
L1和L2正則化都有縮小引數的作用。
但L1會傾向於使得引數稀疏化(一些值為0);L2傾向於使得引數稠密地接近於零。關於這一點的解釋,可以從梯度上認識:L2的梯度在接近0點附近時會變得很小,這會明顯放緩引數的更新;但L1的梯度是保持恆定的,即會一直以大學習率更新引數。另一種解釋是從解空間來看,平方誤差項和L2正則項的交點更容易出現在凸點處。
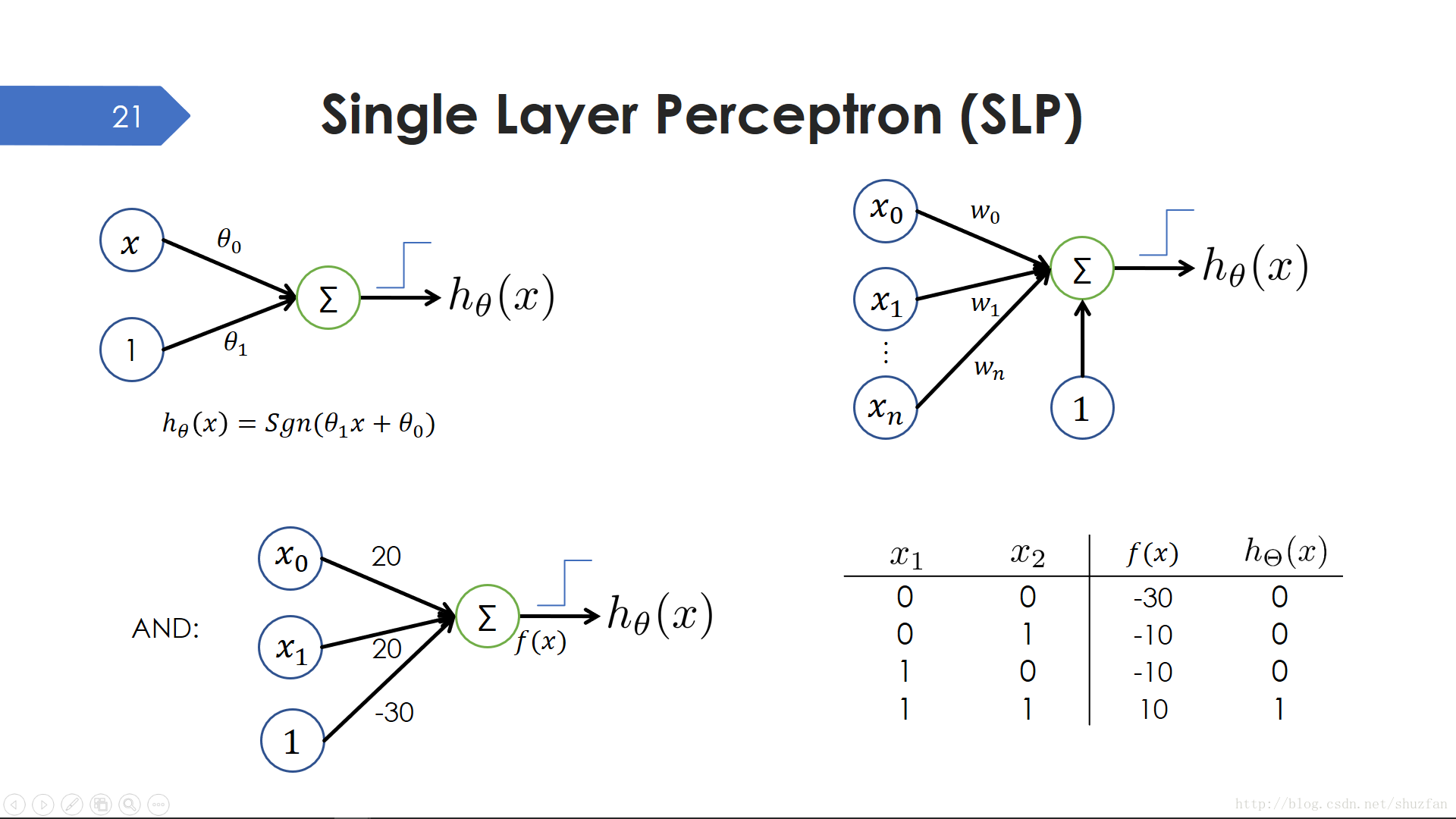
我們之前提到的線性模型加上一個階躍函式就可以構成一個 單層感知機。 同樣地,也有多變數單層感知機。單層感知機可以輕鬆解決 “與” 問題。
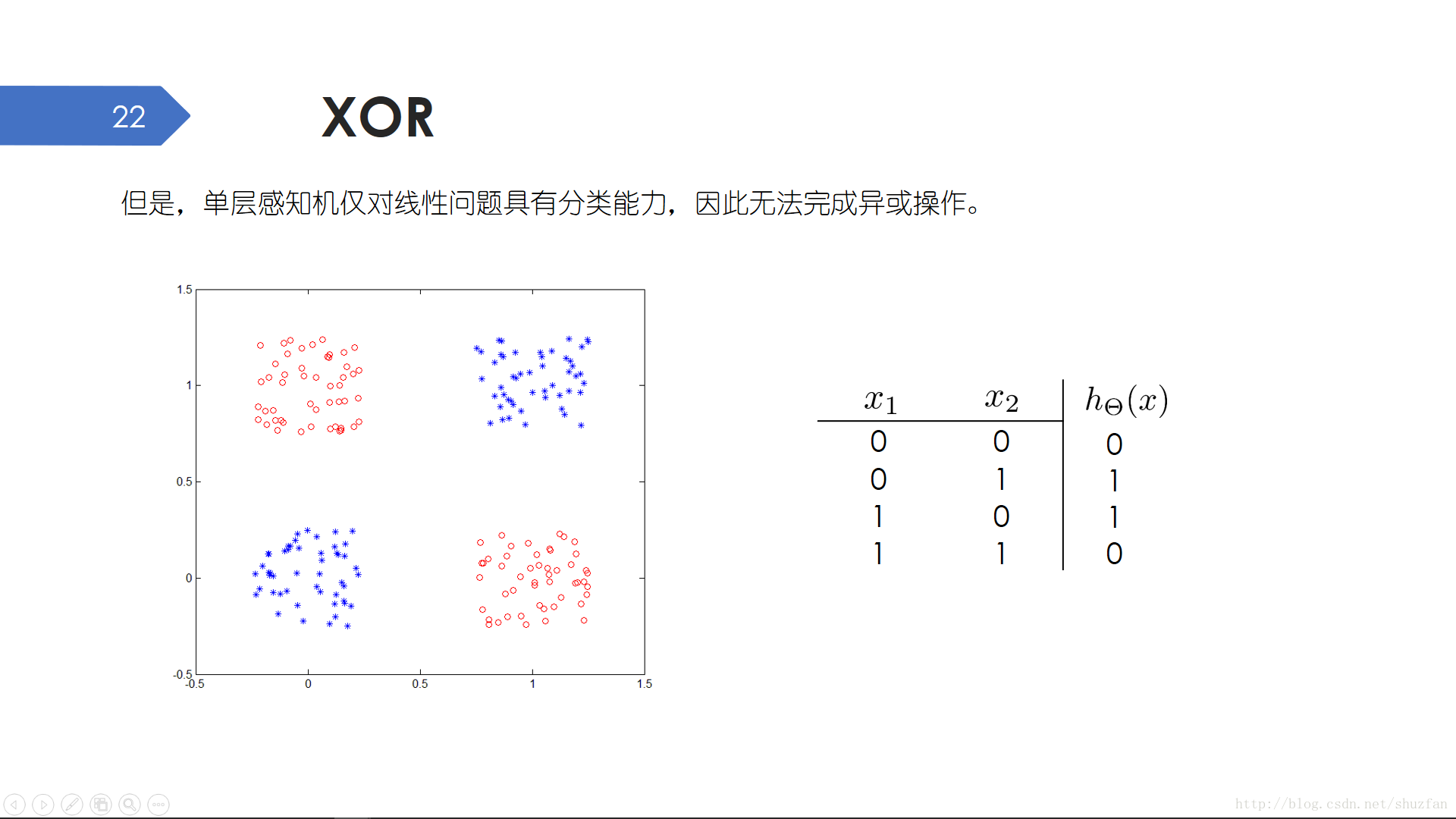
但是單層感知機的線性分類能力並不足以解決 “異或”問題。
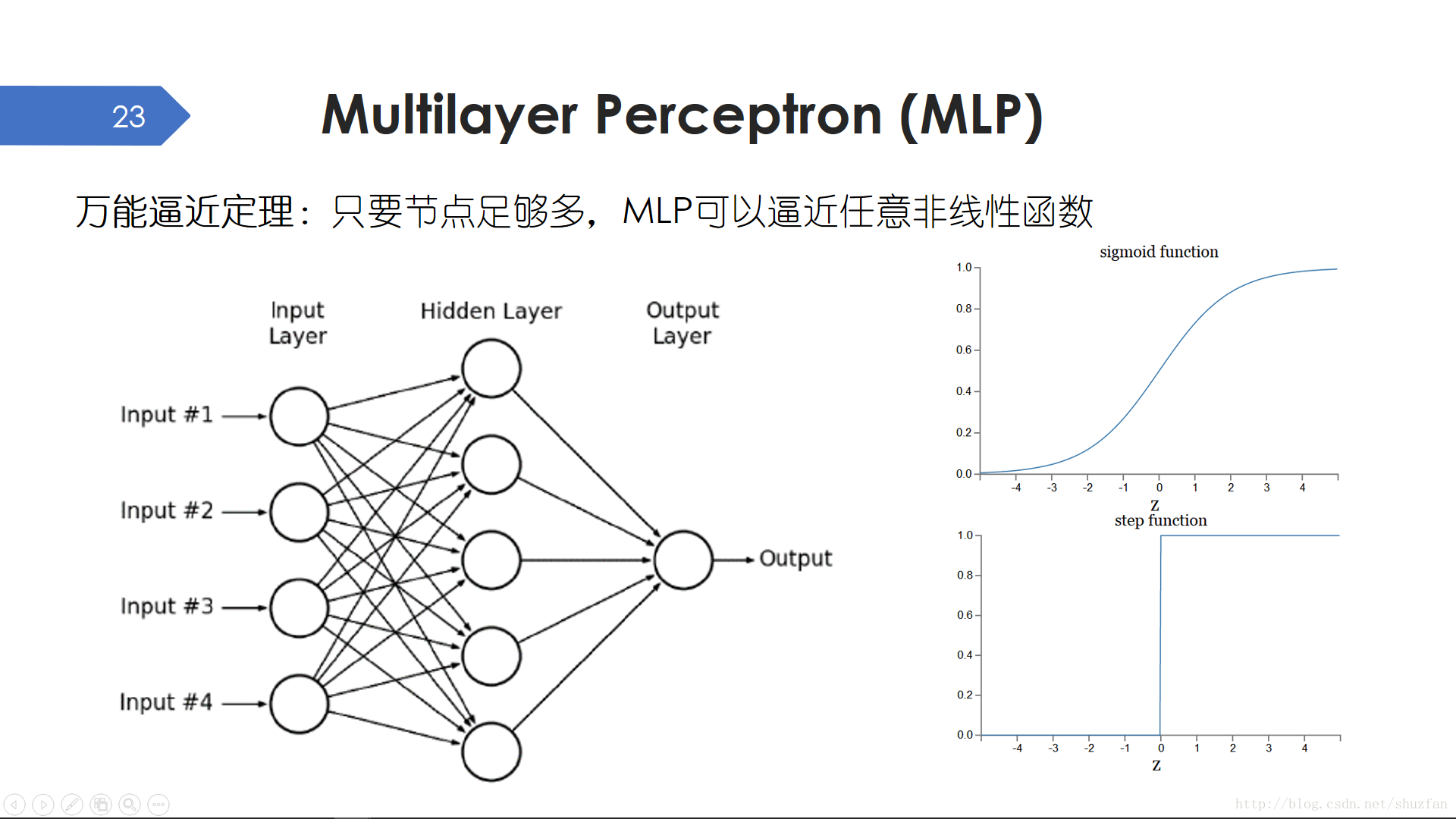
理論證明,多層感知機,只要節點足夠多,就可以逼近任意非線性函式。證明很簡單,無限階躍訊號求和可以任意逼近。
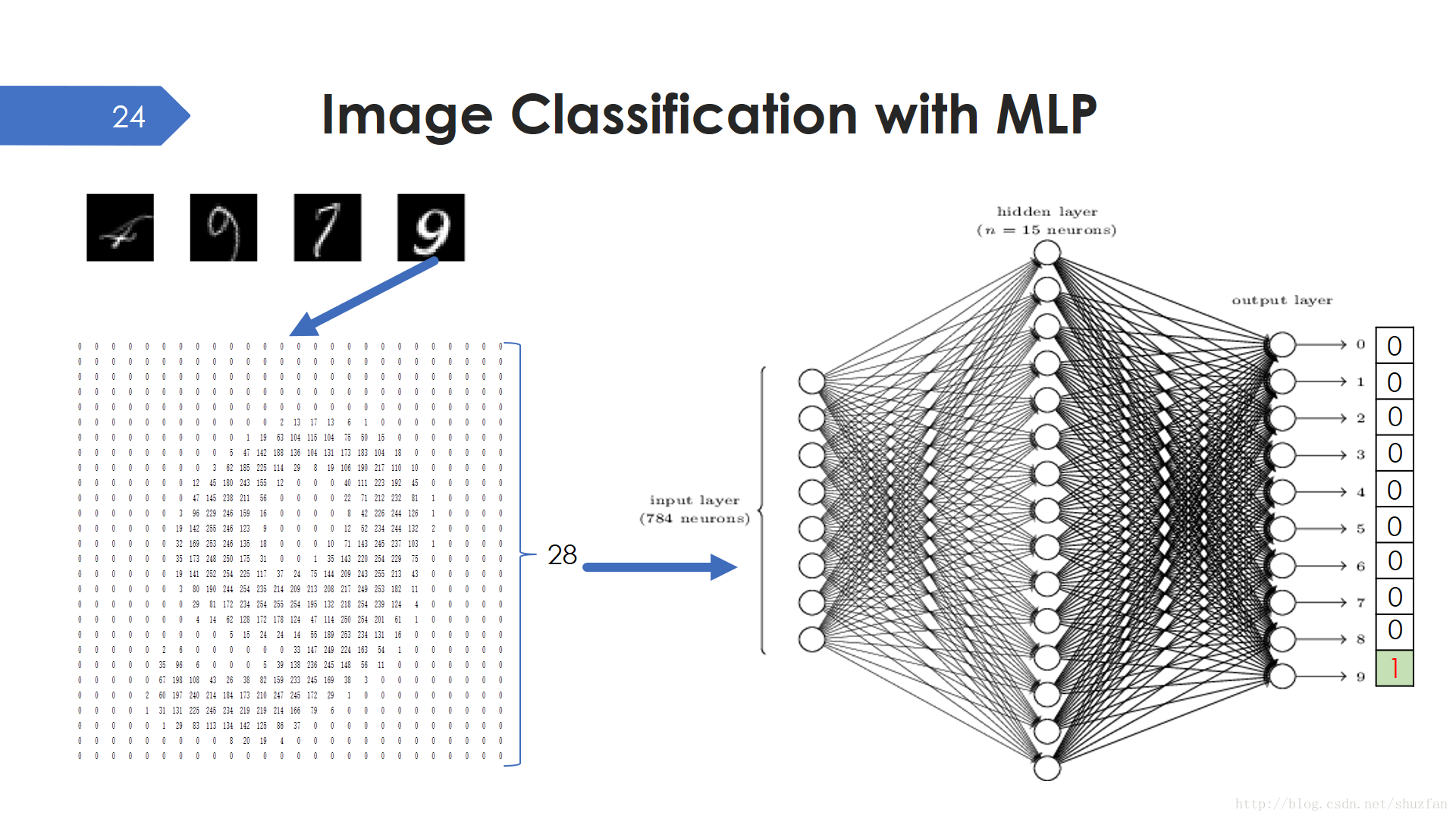
既然瞭解到了多層感知機,那麼使用MLP對影象進行分類也是理所當然的了。比如我們要對手寫數字進行識別,影象大小為 28x28=784。 那麼這個問題就可以如上圖所示解決:輸入784個變數,中間有一個隱藏層,然後輸出10個數值用於對應數字0-9的概率。上面的三層感知機,包含一個輸入層、一個隱藏層、一個輸出層,但實際只擁有兩級引數。另外,之所以稱中間的層為隱藏層,大體是因為中間東西太多看不清楚,而我們只能看清輸入和輸出。

但是當我們的待分類圖片特別大時,比如做汽車分類。假設彩色影象寬和高分別為400和300,則畫素個數為360000,如果我們第一個隱層有N個節點,那麼單單是第一層的引數就有360000*N這麼多。所以MLP的一大缺點就是引數太多,引數過多帶來的是硬體裝置的壓力、訓練的難度以及過擬合的風險。

MLP的缺點幾乎註定了其在機器學習的早期階段難有大的作為。早期的機器學習方法大多屬於兩段式方法。第一段:根據先驗知識提取一些高階的特徵,比如SIFT、LBP、顏色直方圖等。這些特徵基本都是人為設計的,然後用於描述影象顏色、紋理、結構之類的關鍵資訊。原始的畫素資訊可以認為是低階的特徵,維度很高;而特徵提取可以看作一個變相的降維。第二階段:利用之前提取的高階特徵,然後結合一些具體的分類和迴歸方法。
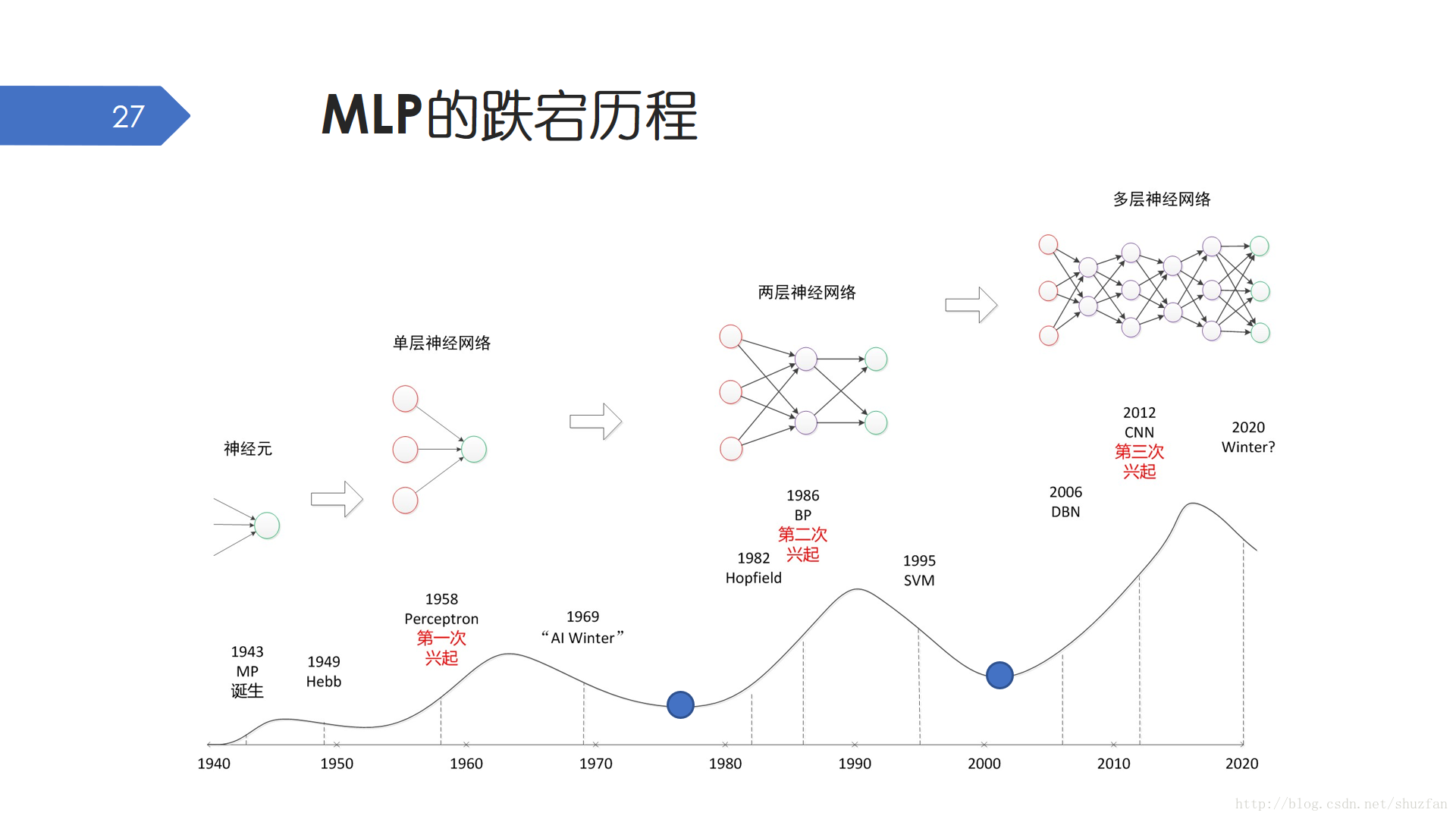
所以縱觀MLP的歷史發展,大致有三個重要的階段。早期的單層感知機不能解決異或問題,後來的多層感知機儘管有著萬能逼近定理結合梯度反傳演算法的支援,但因為時代的侷限性還是被SVM打壓。一直到後來的卷積神經網路。
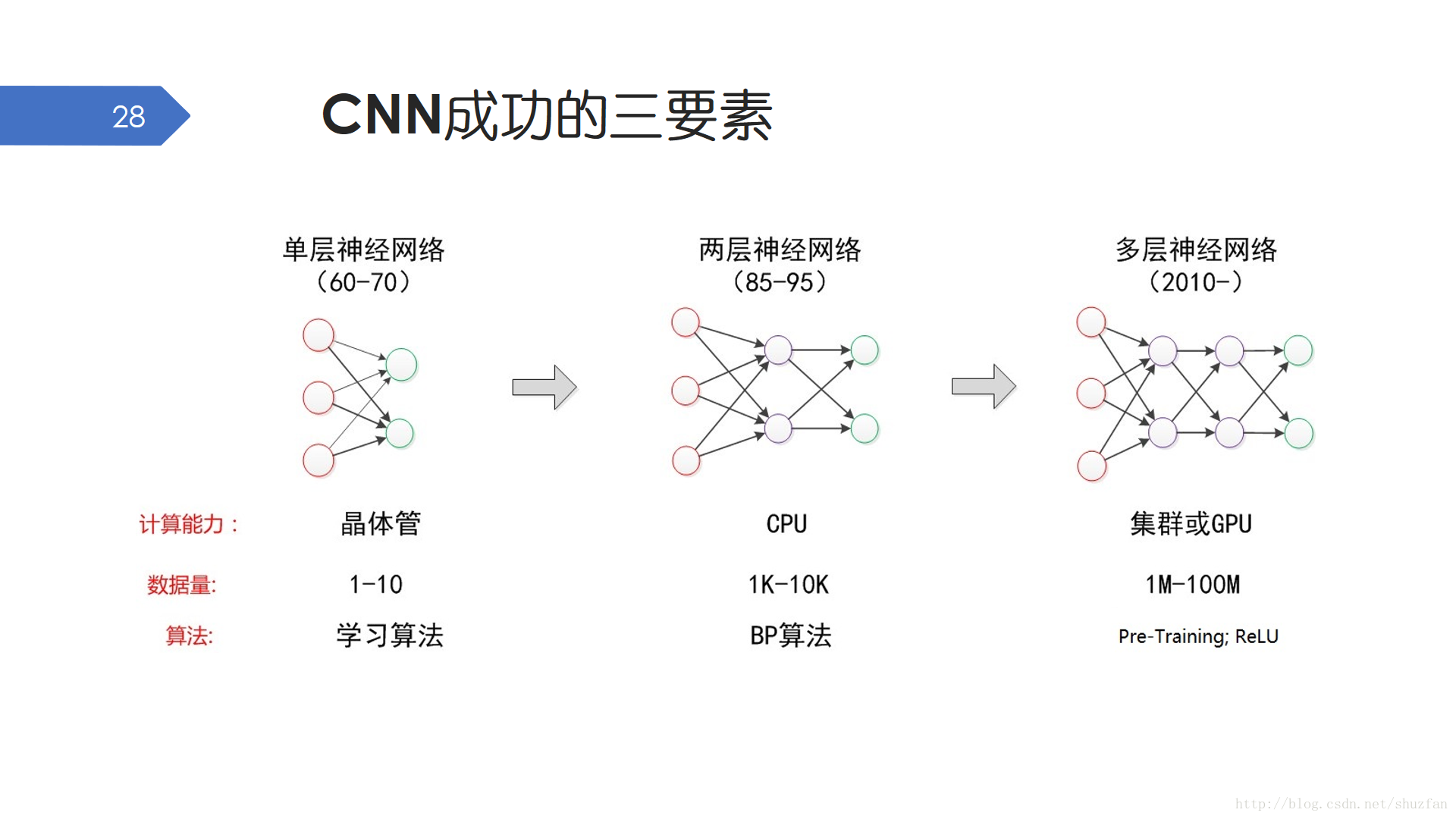
卷積神經網路的成功除了演算法上的進步,時代背景環境的發展也是重要因素。
- 卷積神經網路通常有大量引數需要學習,因此計算機硬體計算能力的提升,特別是GPU的發展,為神經網路的發展提供了重要的支撐。當然,賣顯示卡的NVIDIA也起飛了。
- 另外就是網際網路的發展使得影象視訊資源大大豐富起來,神經網路已經有機會獲得其所需的百萬級別規模的訓練資料。
- 當然,眾多研究人員在神經網路訓練方法、機理探究等方面做出的突破也是CNN成功的重要因素。
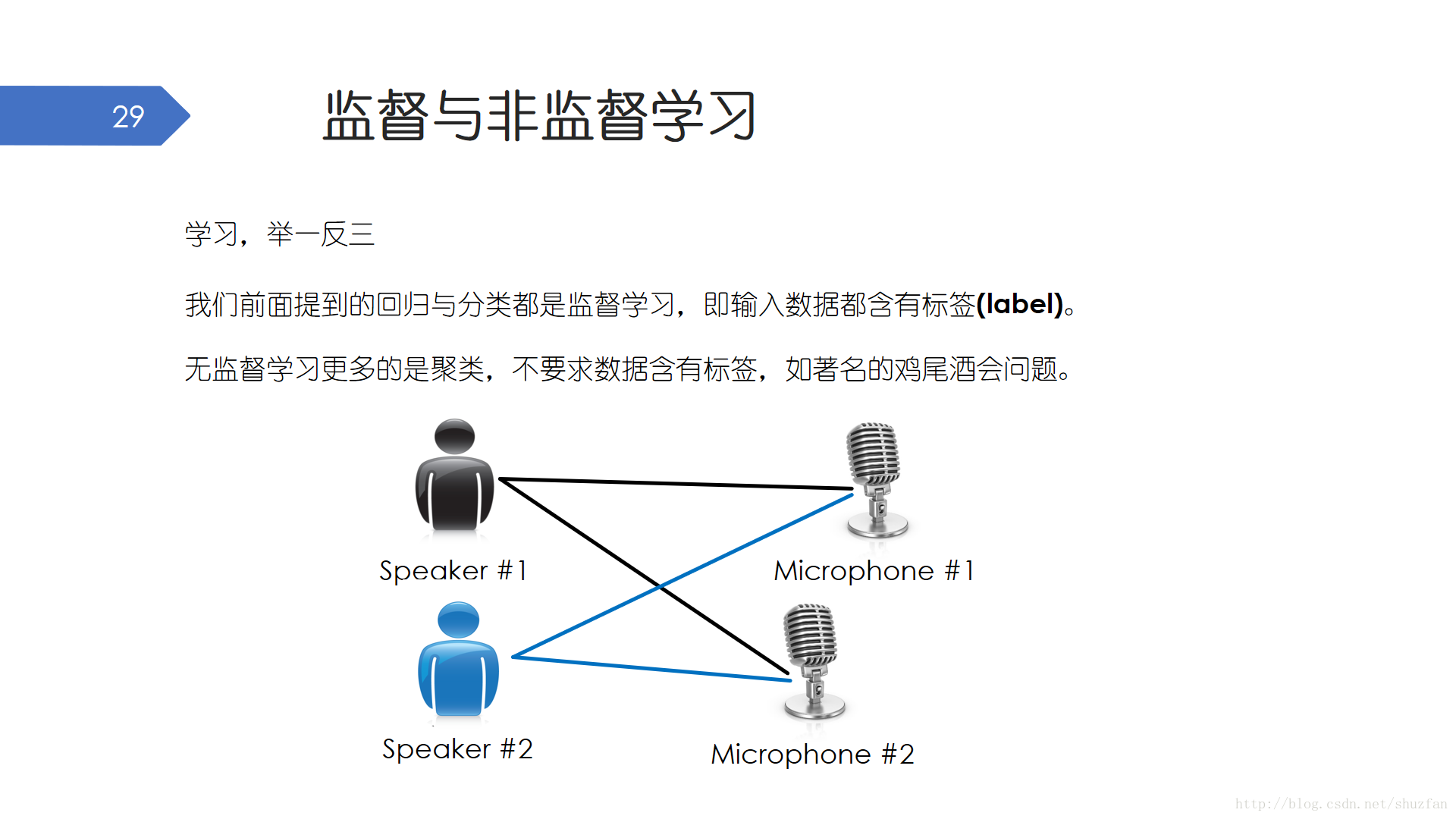
最後,在第一部分“相關基礎”環節,再提一下 “監督學習” 與 “非監督學習”概念。
所謂的學習,就是 舉一反三。 用已有的知識來解決類似的已知的或未知的問題。
我們前面提到的 分類 和 迴歸都屬於監督學習,因為我們的訓練資料是有 標籤的。我們訓練的對不對、準不準,是可以通過和真實結果(ground truth)直接進行對比而知曉的。就比如說,大家為了考試去刷題,題目都是有答案的,這樣我們才能不斷糾錯反饋進步。
但是還有另外一種學習,叫做 無監督學習,無監督學習最難的地方在於我們沒有 標籤。目前的無監督學習更多的是解決 聚類 的問題。 一個經典的無監督學習的例子叫做 “雞尾酒會問題”,是計算機語音識別領域的一個問題。當前語音識別技術已經可以以較高精度識別一個人所講的話,但是當說話的人數為兩人或者多人時,語音識別率就會極大的降低,這一難題被稱為雞尾酒會問題。(通訊訊號處理專業,有些人會稱之為盲訊號分離或者訊號的盲原分離。)

深度卷積神經網路可以認為就是高階點的 多層感知機。 深度卷積神經網路的深入學習需要閱讀大量的論文,可以百度Github開源專案 —— “深度學習論文閱讀路線圖”。
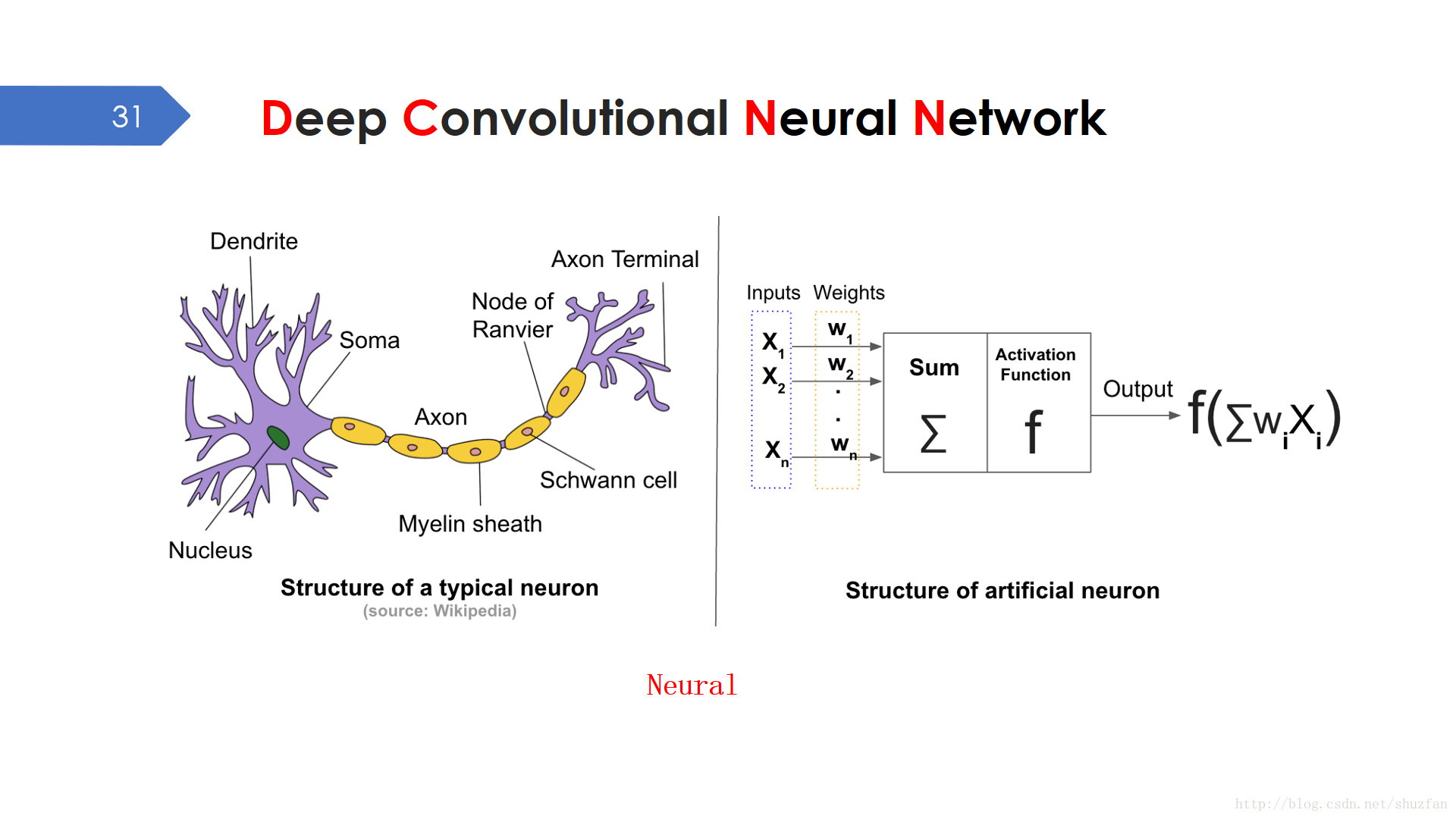
深度卷積神經網路(DCNN)中 “Neural” 一詞來源於神經元模型。一個典型的生物神經元,是一個多輸入單輸出的資訊處理單元。而我們的感知機模型基本就是因此而來的。
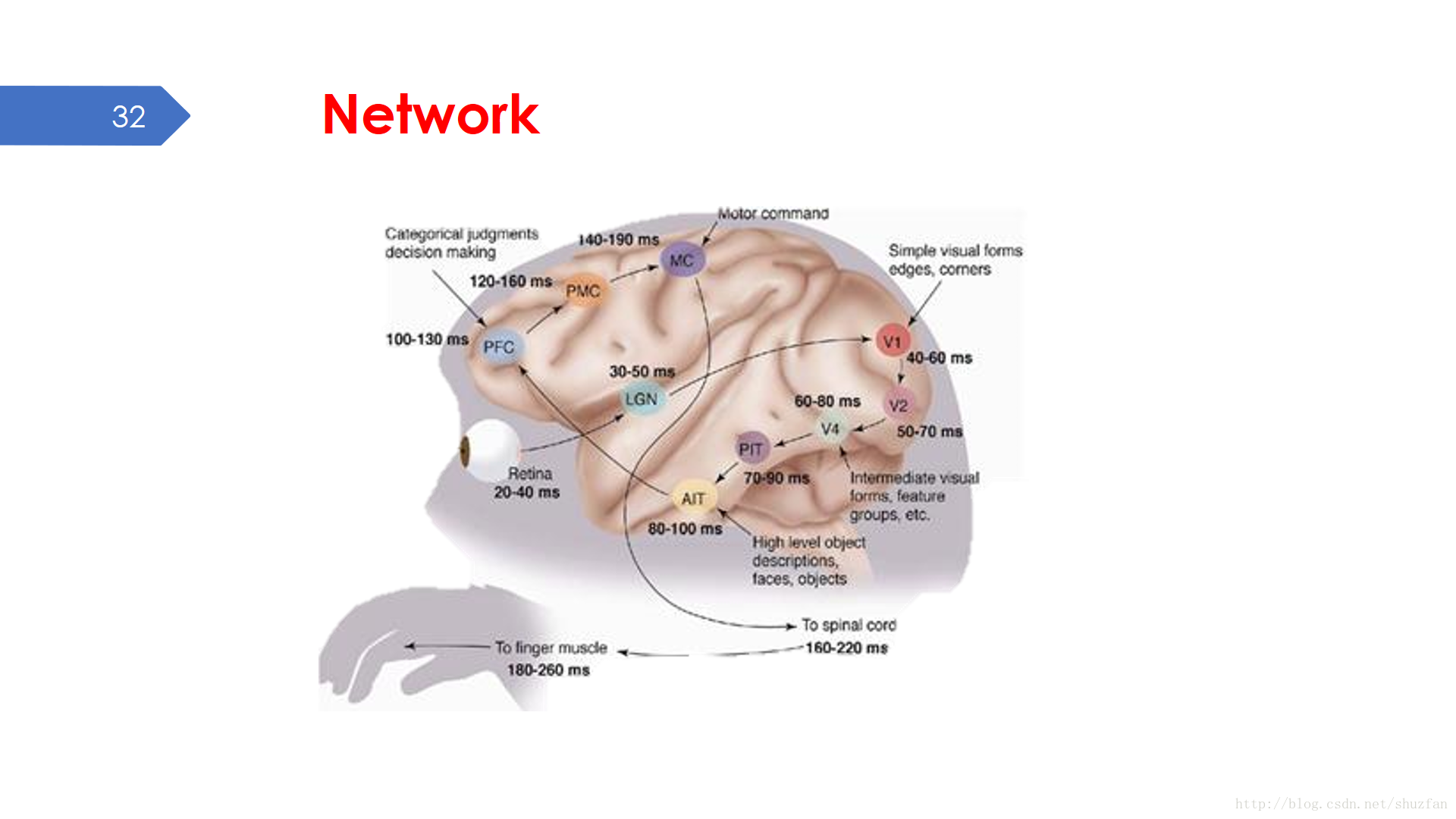
“Network” 的概念也很清晰。生物學家發現人類大腦處理任務是分層的,同時眾多神經元協同工作共同成了功能強大的神經網路。
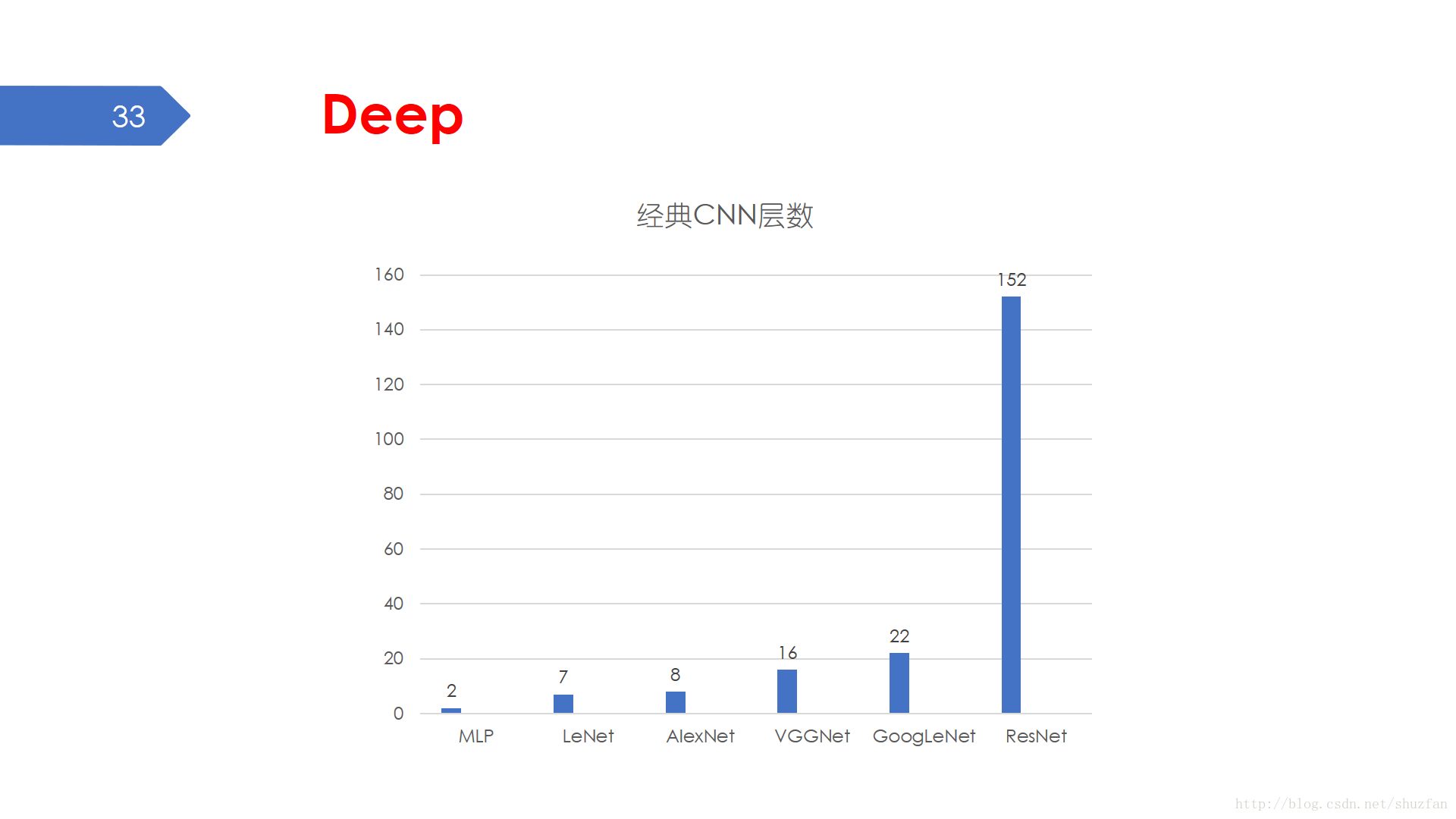
“Deep” 形容的就是網路的層數。早期的感知機可能只有3層(一個輸入層、一個輸出層、一個隱藏層),但是最新的DCNN已經超過了1000層。
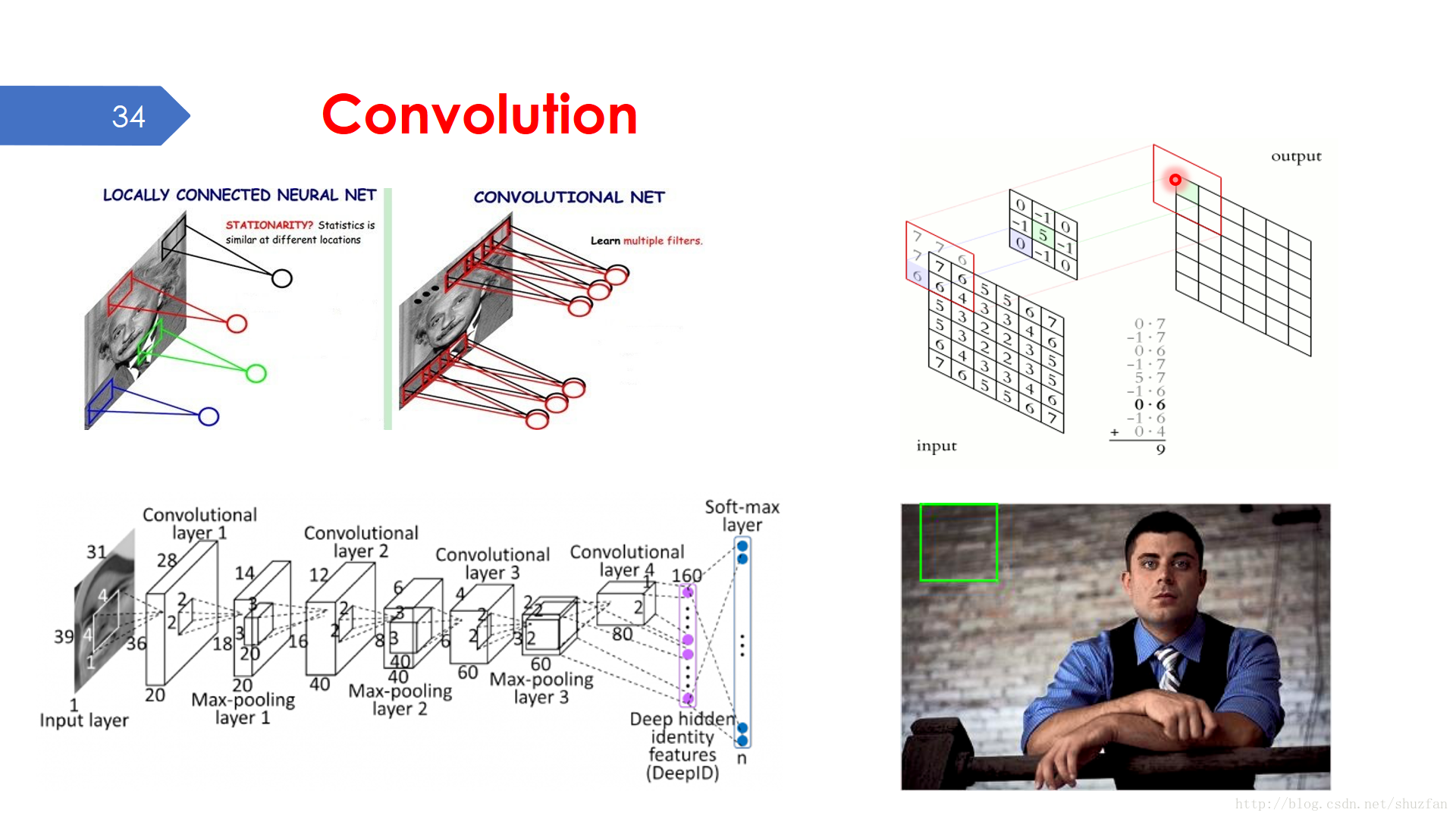
“Convolution” 是一種特殊的 “取樣” 方式。 前面我們看到的感知機的輸入都是一個一個的數值,儘管我們可以將一幅影象拉成一個向量並送入感知機,但這樣卻會極大削弱影象固有的 區域性相關性。為了更好的保留區域性相關性資訊,最直接的方式就是整塊整塊的輸入,具體實現起來很像滑動視窗。 學過數字訊號處理或者進一步選修過數字影象處理的,應該對卷積這一概念比較熟悉。
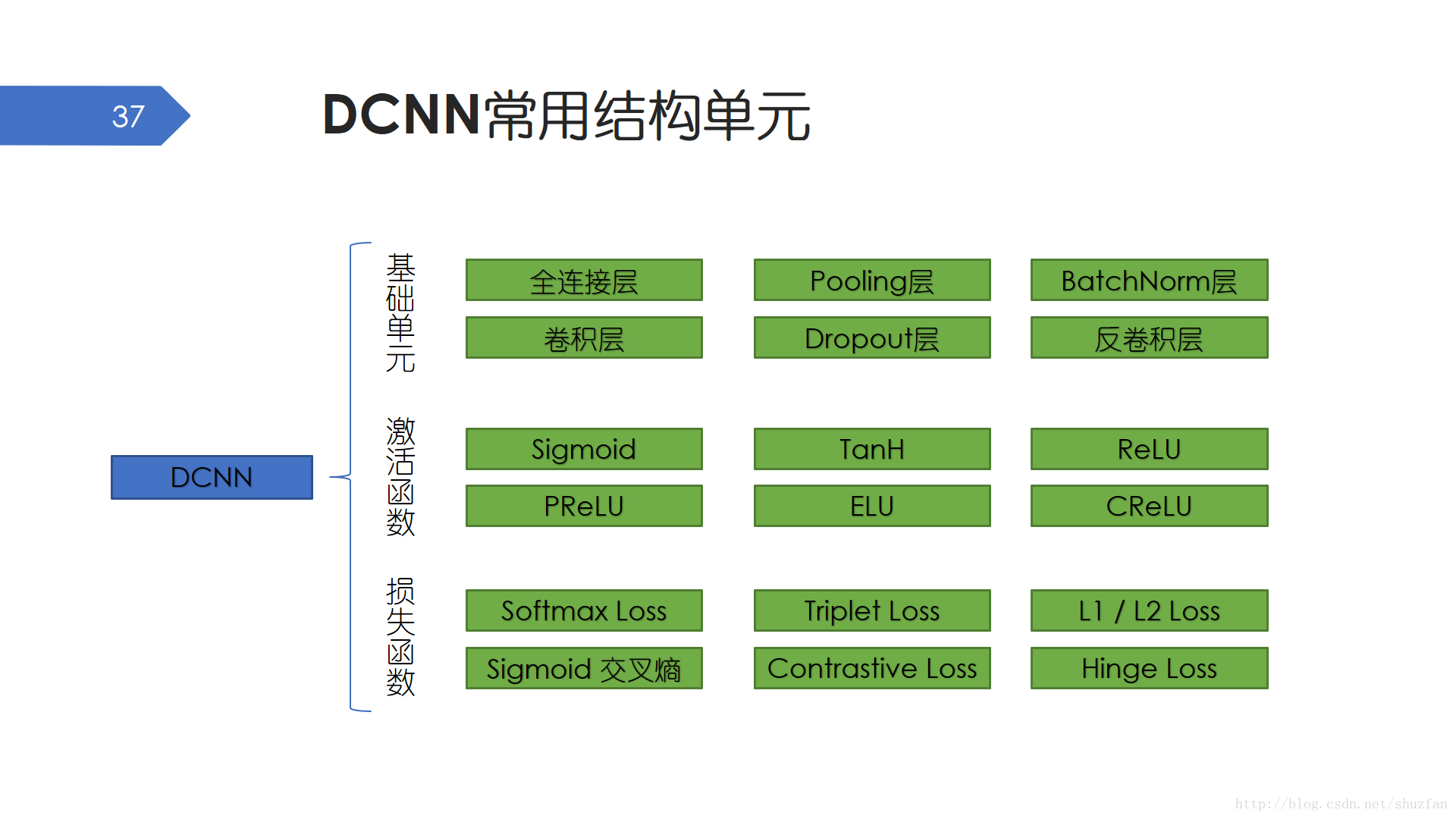
我們注意到,深度卷積神經網路的構成是 分層的。 層 這一概念帶給我們最直觀的感受是我們可以像組裝樂高積木一樣,用不同功能的模組來構成千奇百怪的網路模型。下面我們就介紹一些常用的模組 —— 層。
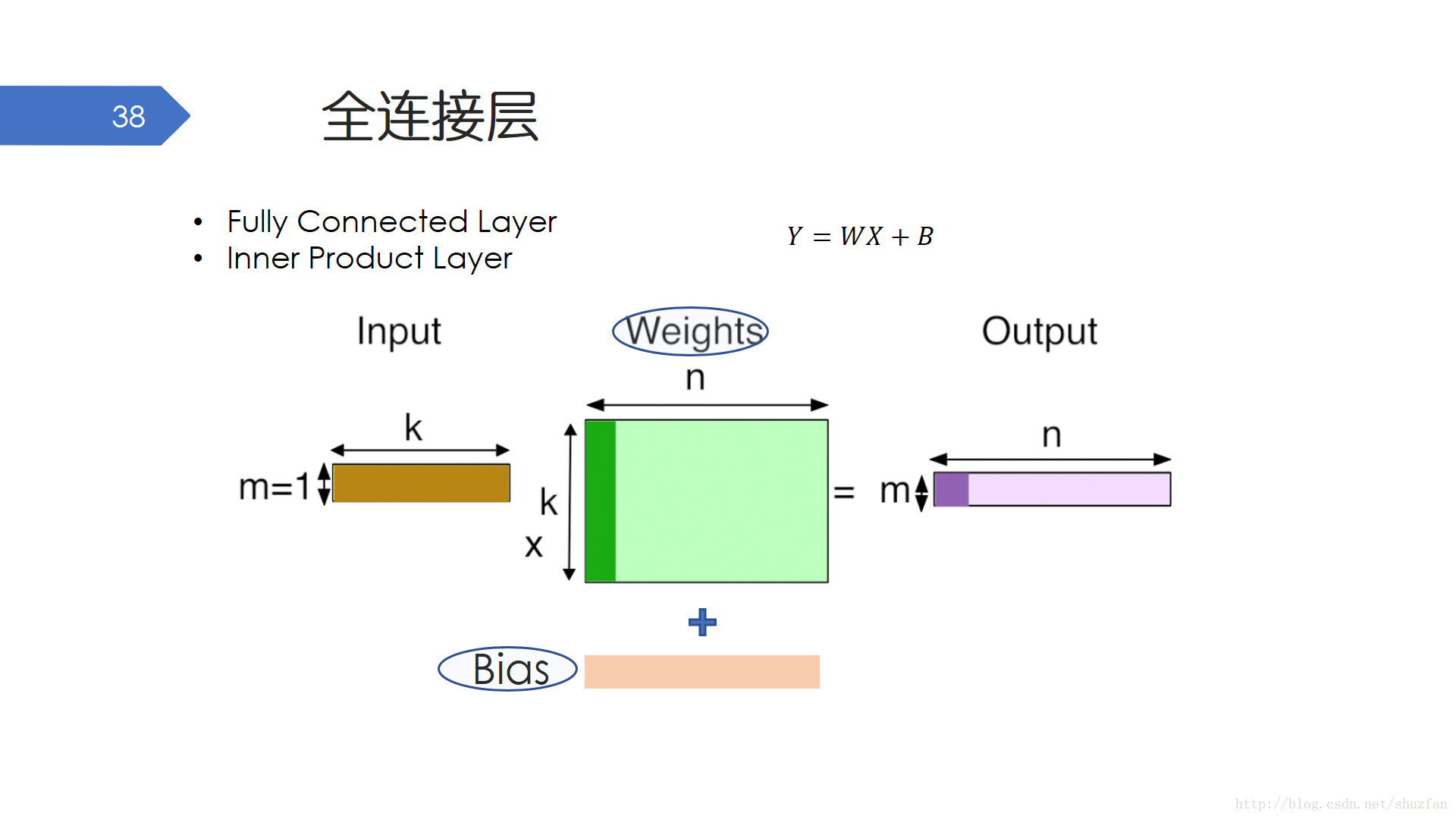
首先當然是全連線層。這層很簡單,而且我們前面提到的多層感知機預設就使用了這種結構。該層會預設將任意維度的輸入首先 “平鋪”成一維向量,然後執行y=wx+b的操作。 需要學習的引數主要有w和b。儘管全連線層引數通常比較多,但由於我們可以利用很多高度優化的基礎線性運算庫(比如MKL、OpenBLAS等),因此執行效率還是蠻高的。
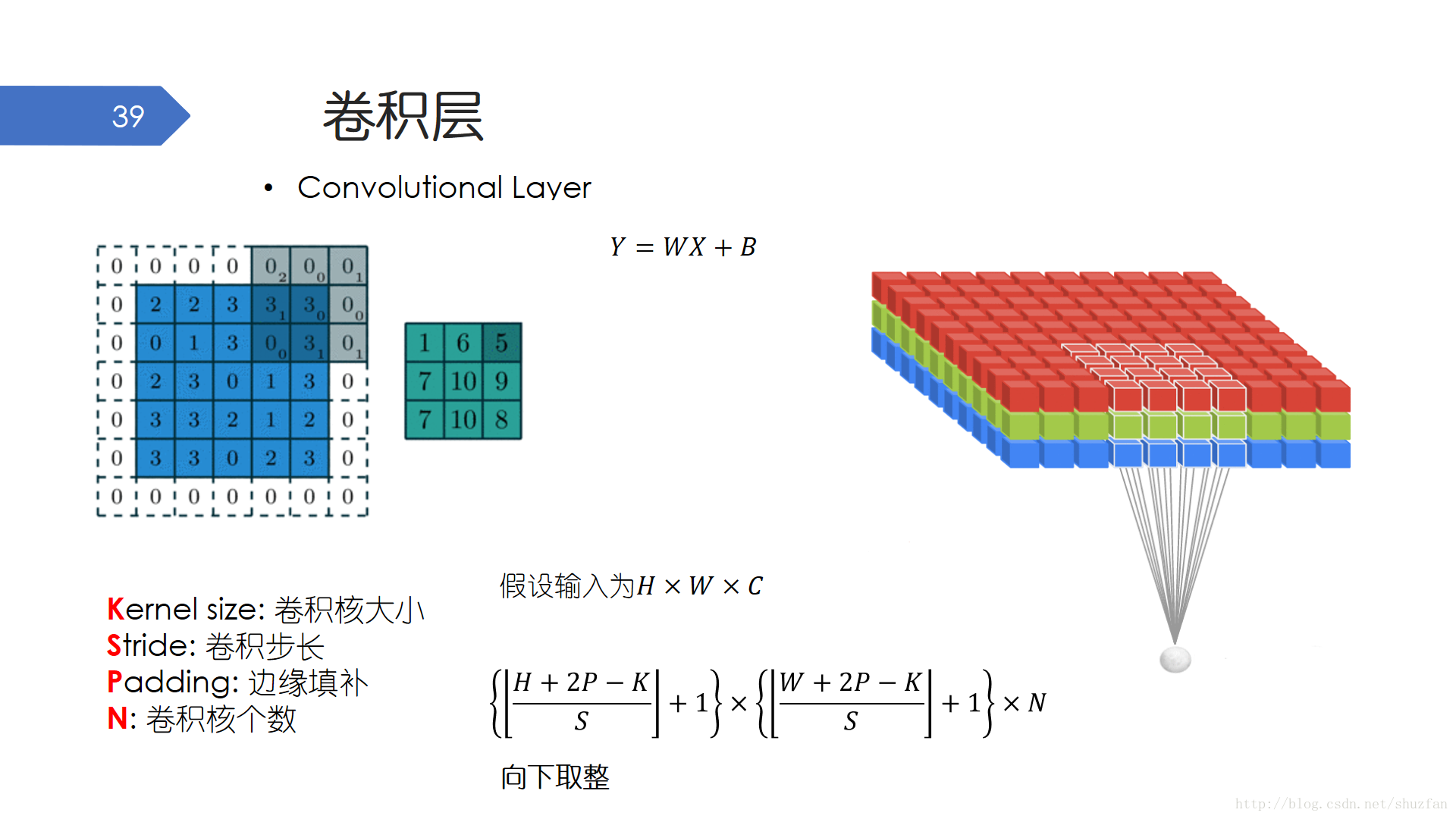
由於DCNN更多的被用來處理影象,因此卷積層的使用頻率是最高的。 當把卷積看作滑窗的時候,其實我們可以很容易想到有哪些有關卷積的超引數需要我們提前設定好:視窗大小,我們一般稱之為卷積核大小;卷積核的個數;視窗的滑動步長;還有就是影象邊緣是否需要填補。我們除了要能夠計算清楚卷積後的輸出維度之外,還必須清楚的是:每一個卷積核通常都是3D的,以彩色影象為例,一個卷積核除了有寬和高兩個維度外,還有第3個維度用於處理RGB通道。
儘管卷積的操作稍顯複雜,但還是屬於線性操作,因為其本質還是加權求和。
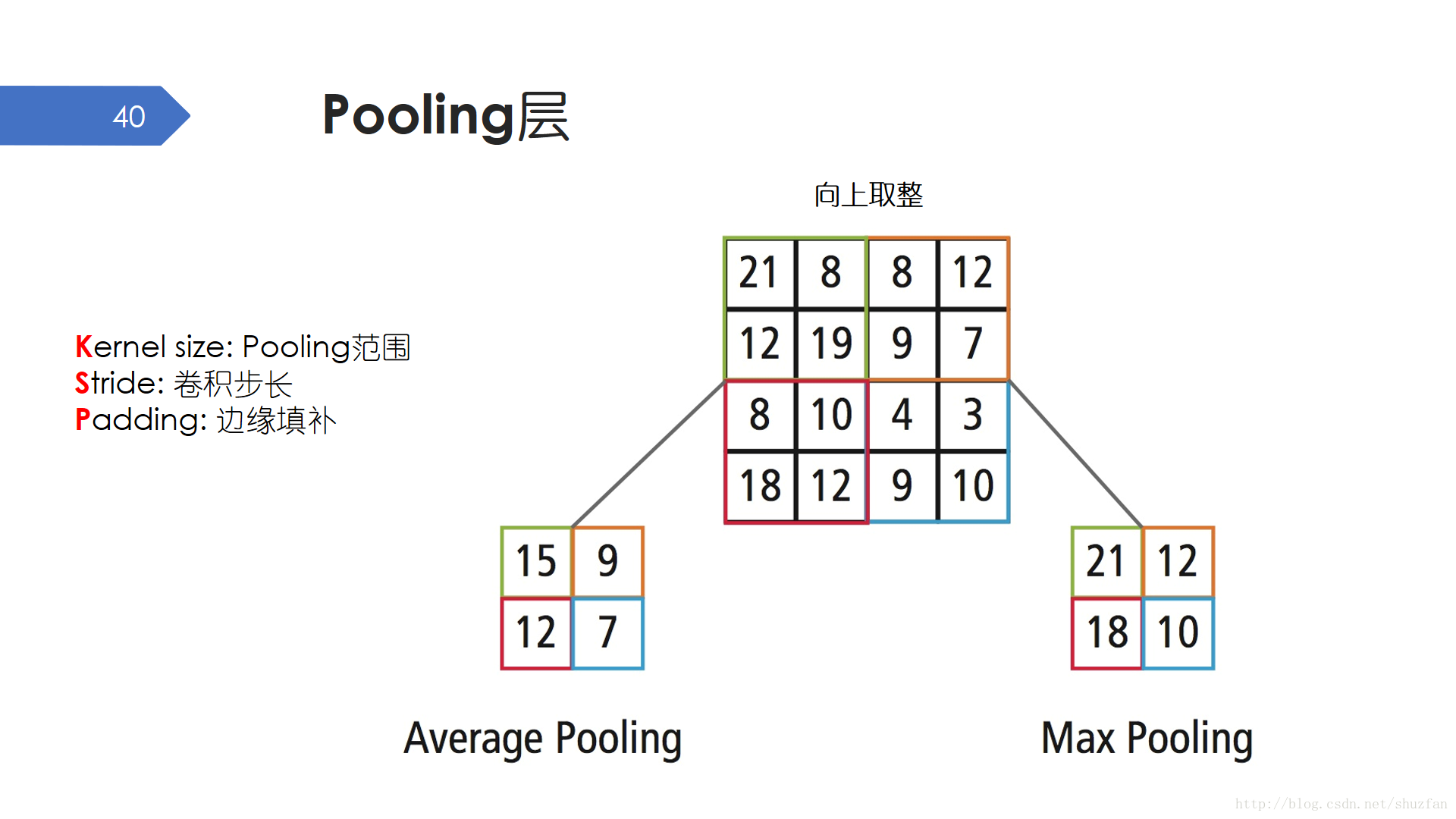
Pooling,中文通常翻譯為 池化。 Pooling層的操作方式和卷積很像,都是滑動視窗,但沒有需要學習的引數。Pooling有Max Pooling 和 Average Pooling兩種。前者返回視窗範圍內的最大值,後者返回視窗內數值的均值。
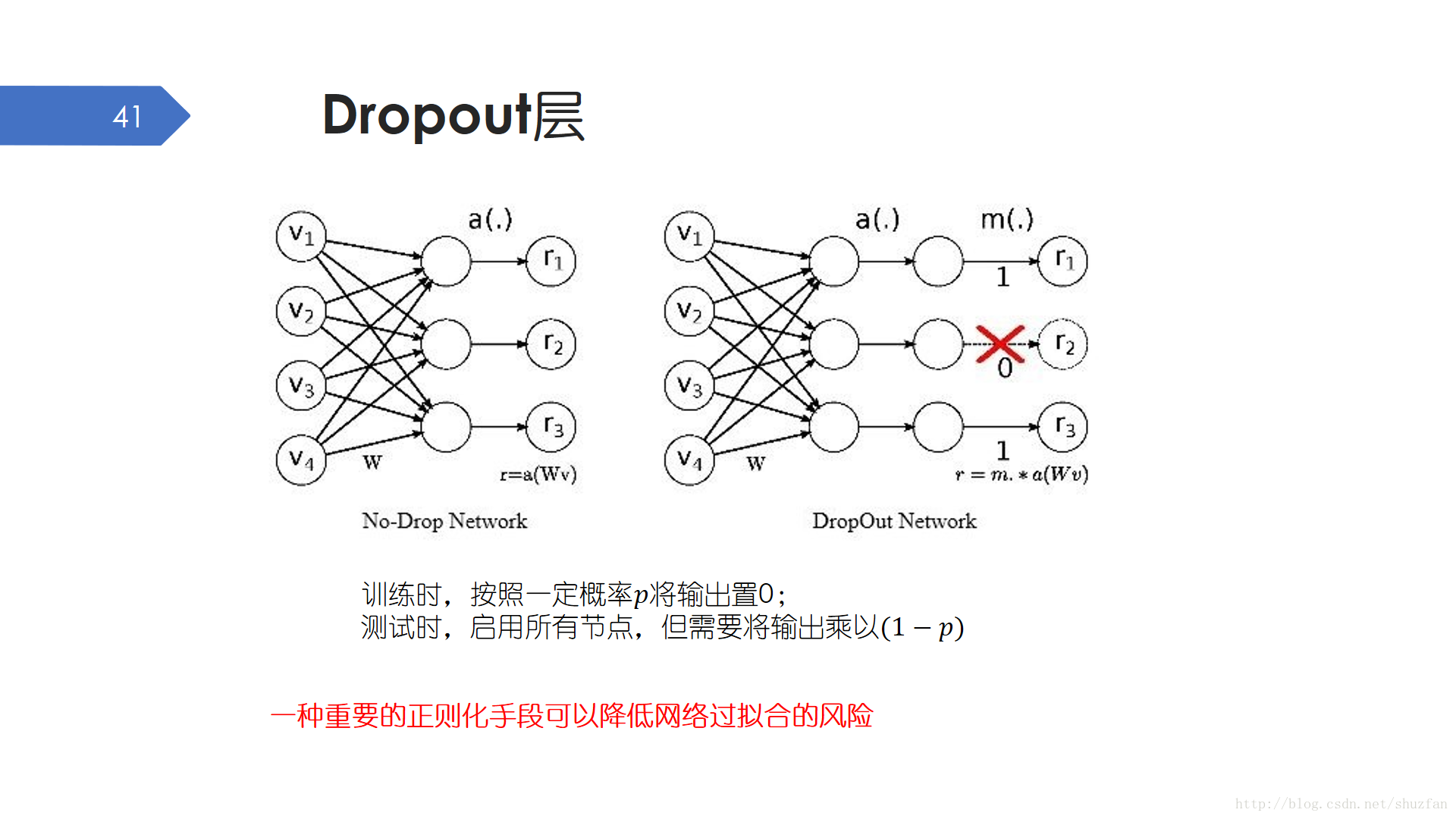
Dropout層用來減輕網路過擬合的風險。Dropout沒有需要學習的引數,只是需要提前設定一個概率p。訓練時,按照一定概率p將輸出置0;測試時,啟用所有節點,但為了數值均衡需要將輸出乘以(1-p)。
我們可以簡單思考下Dropout防止過擬合背後的原理。
- 讓輸出更稀疏,而稀疏一直都是重要的正則化手段;
- 隨機輸出置0,相當於給訓練引入更多幹擾。雖然增加訓練難度,但也會讓模型更魯棒;
- 由於是隨機操作,相當於每次都在訓練不同的模型。有點類似於Bagging方法。
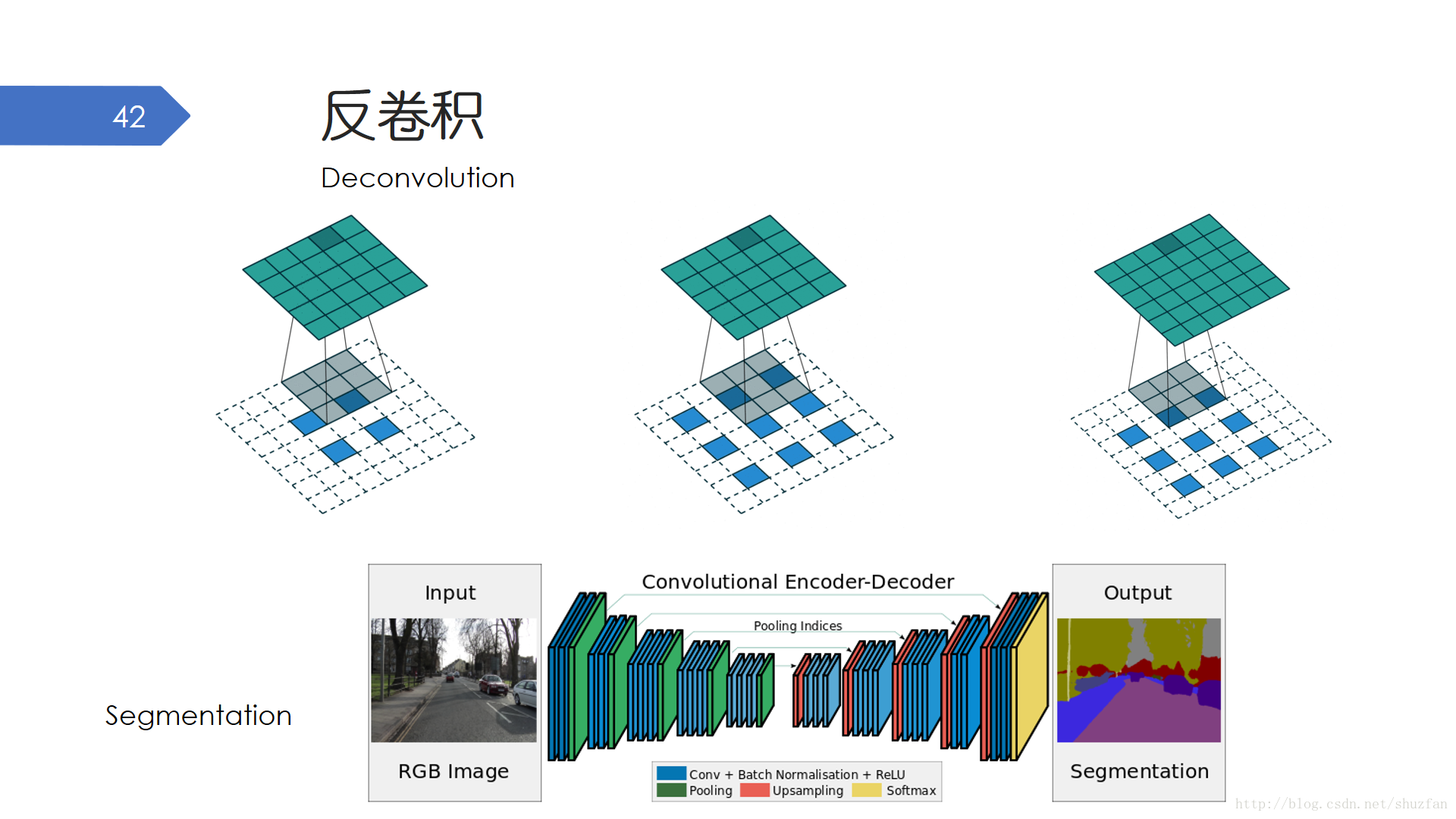
卷積通常會使得輸出的寬和高變小,反捲積則致力於將輸出尺寸變大。反捲積最早應用在影象的語義分割上,因為語義分割要求輸出和輸入一樣大小。 反捲積的操作方式類似於卷積,只不過會實現對輸入進行插值或者說填空。
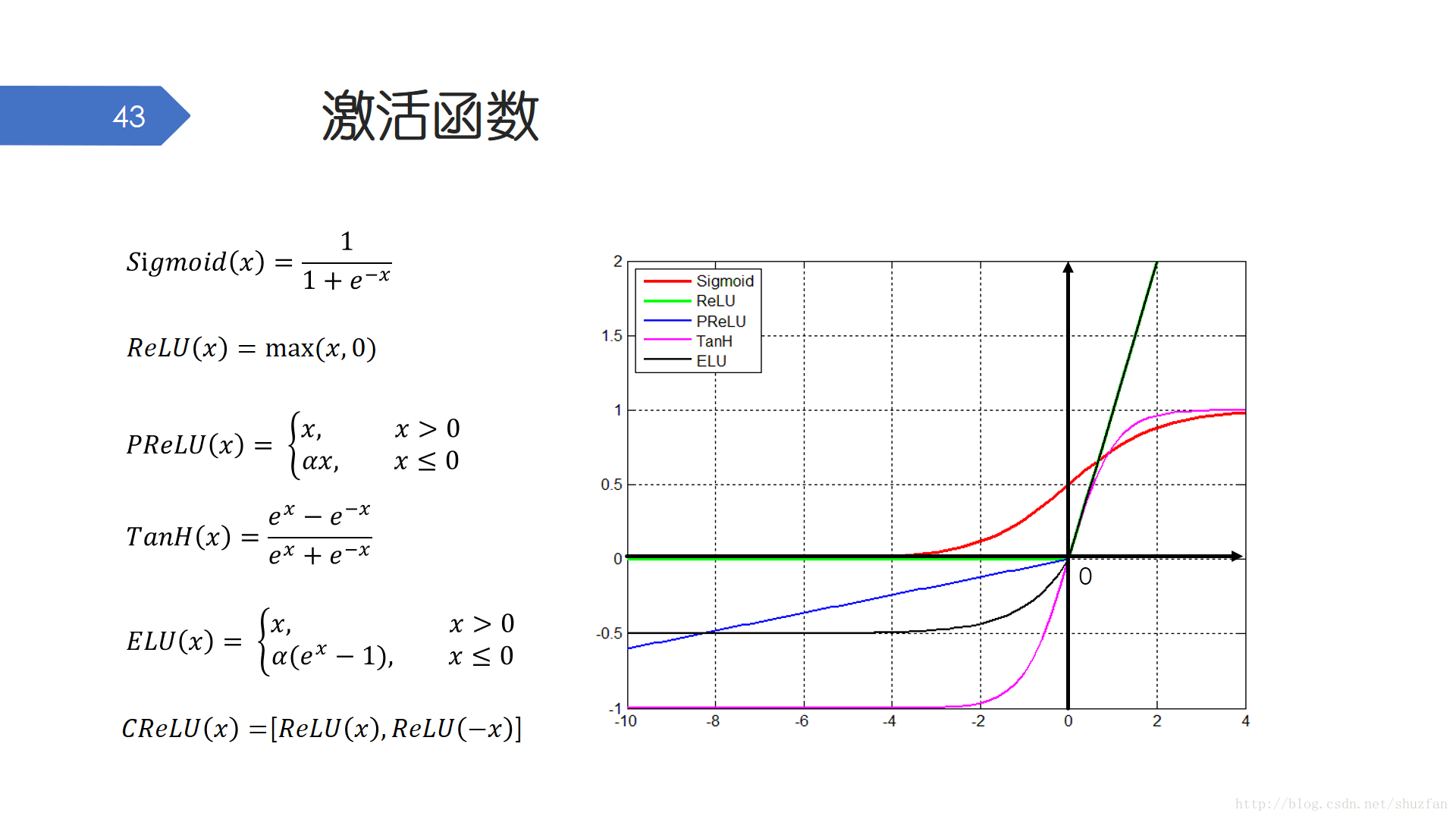
我們在前面已經接觸到了Sigmoid啟用函式。 啟用函式通常都是非線性變換,其主要目的也是為了讓網路擁有更強大的非線性表示能力。Sigmoid和TanH因為可以對資料範圍進行壓縮,有些特殊的場合還是有需求的;但更多的網路所採用的其實還是ReLU啟用函式(包含一些變種,但還是ReLU更常用)。
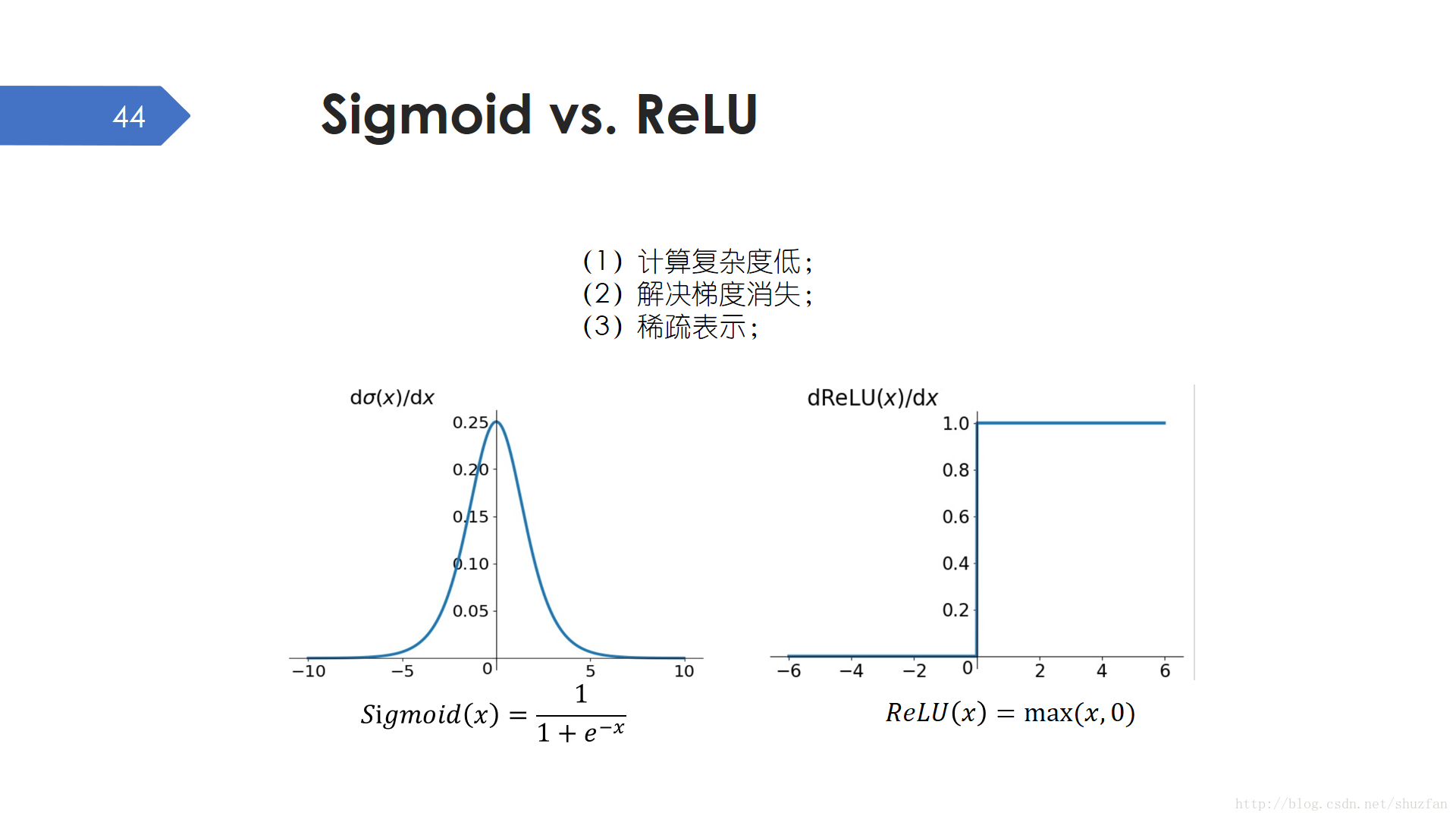
之所以ReLU會取代Sigmoid而佔據主流地位,主要原因有:
- ReLU計算複雜度低,包括求導也簡單;
- ReLU可以解決Sigmoid帶來的梯度消失問題,因為ReLU對有效值的梯度始終為1,而Sigmoid的梯度值總小於1/4;
- ReLU可以讓輸出稀疏,稀疏是個正則化的好東西;

接下來開始介紹幾個常用的損失函式,首先是Sigmoid交叉熵。 其一般用於二分類問題,也可以用於相互不獨立的1對多問題。比如一個實際上包含3個二分類的問題:是否喜歡吃西瓜?是否喜歡吃草莓?是否喜歡吃蘋果?可以存在同時喜歡3種水果的人。此外還需要注意的是,在進行Sigmoid概率歸一化時要注意數值溢位的問題,比如 \(x\) 遠小於0,那麼我們計算時就不應當使用 \(1/(1+e^{-x})\) 而應當使用 \(e^x/(1+e^{x})\)
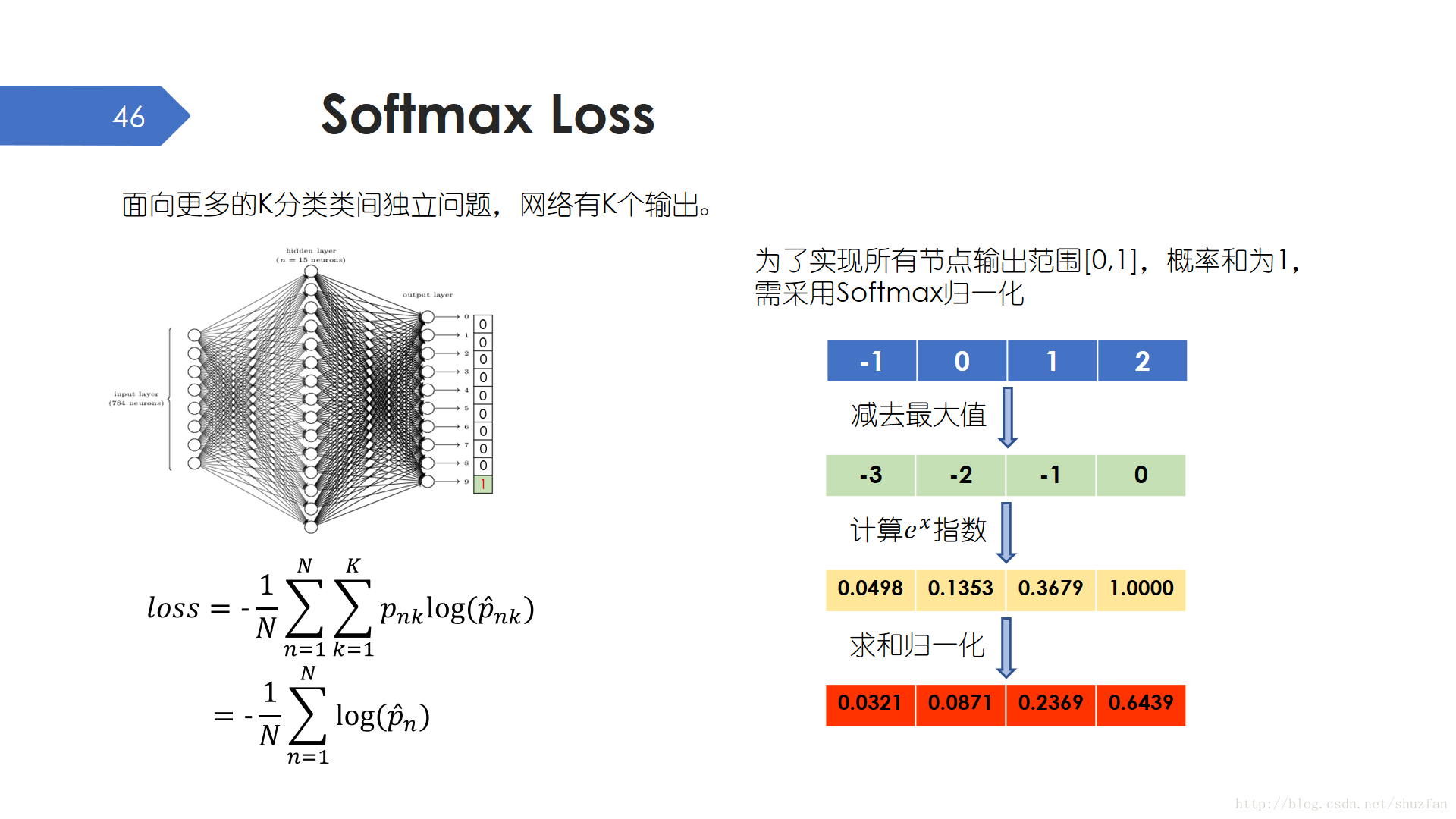
實際當中我們遇到更多的其實是獨立N分類問題,比如之前提到的手寫數字識別分10類,這個時候我們通常使用Softmax Loss。其實該loss也是一種交叉熵,但由於往往使用one shot label,即每個樣本的標籤是一個 1xN 維向量,且向量只有對應具體類別的位置處數值才為1,其餘全部為0,因此該loss函式會退化為 \(-log(p_i)\)的簡單形式。
為了使得輸出資料範圍在 [0,1]之間且之和為1,我們通產會採用softmax歸一化。

L1和L2 loss通常用於數值迴歸,其定義比較簡單,後面會給出具體的例子。此外,還有以下幾點補充:
- L2 Loss中,之所以除以2N,只是為了在求導時比較方便而已;
- L1 和 L2哪個更好用一點,更多的時候真的要看經驗;
- 通常在L1 和 L2 Loss之前都會對輸入做歸一化(常用單位方差歸一化),以防止數值溢位和Loss動盪;
—————————————————————————————————————————————
接下來介紹一些神經網路求解優化相關的一些東西:
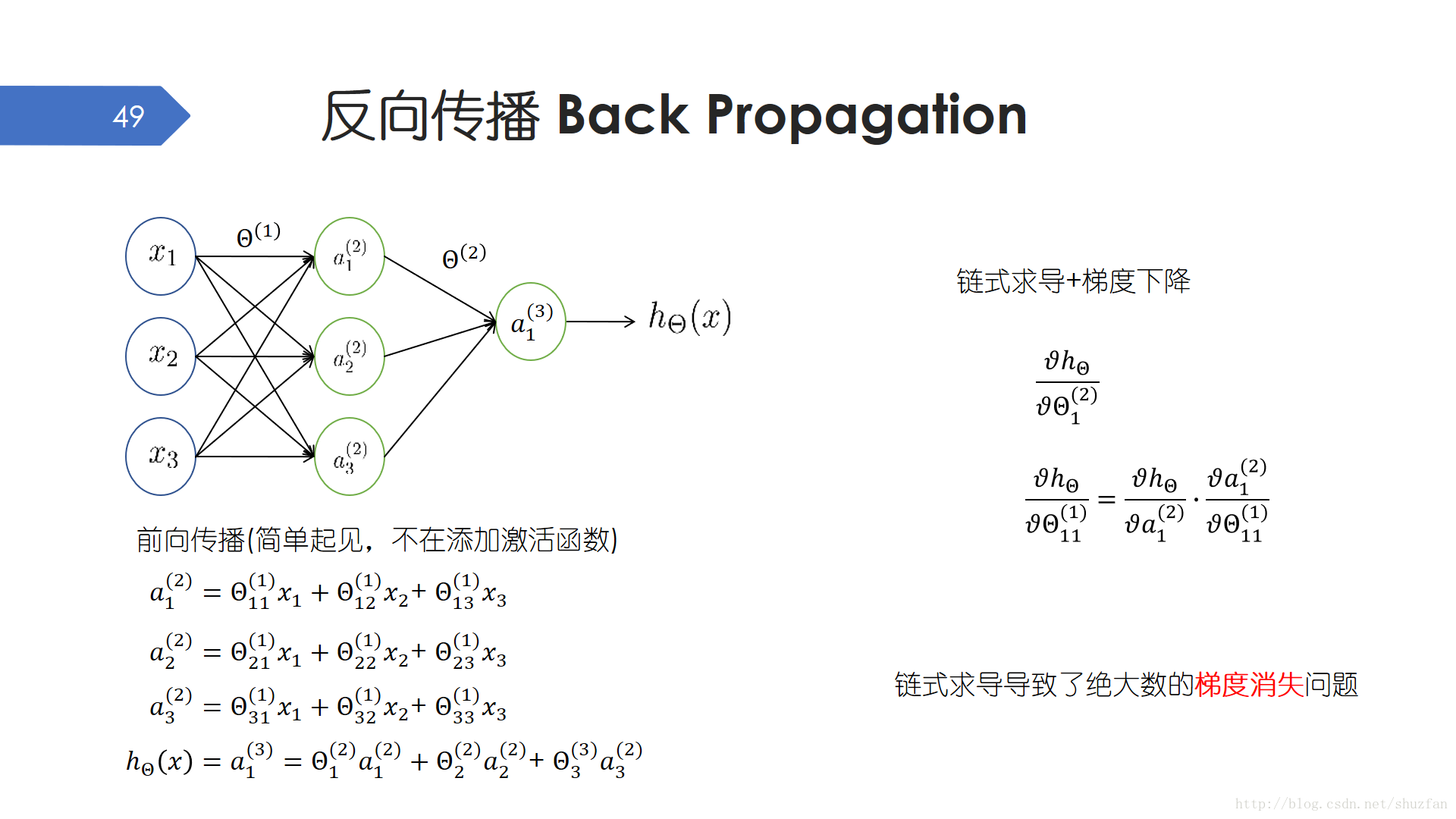
神經網路的優化求解,主體上是基於 反向傳播這一框架,然後使用 梯度下降 這一核心演算法。
我們需要梯度下降來更新引數,那麼就需要計算每一個引數的偏導數。反向傳播其實就是我們熟悉的鏈式求導,這主要是因為我們的網路是分層的,可以看作函式巢狀。
因為鏈式求導是一個連續乘積的形式,如果每個中間梯度的幅值都比較小,這將導致最後計算出的梯度異常小,這就是所謂的 梯度消失現象,反之也有所謂的 梯度爆炸。 這其實我們放棄 Sigmoid 而改用 ReLU啟用函式的原因所在,ReLU求導梯度幅值保持為1。

在前面我們就已經介紹過 梯度下降 這一優化方法。事實上,我們之前介紹的方法確切來說應當稱為 批量梯度下降,因為我們將全部訓練樣本(點)帶入了我們的代價函式中來計算梯度。 這樣做的好處是梯度估計準確,但是缺點也很多:當考慮所有樣本時,計算壓力會很大(記憶體不夠用),同時也很難線上新增新的樣本。

我們採用一種簡化的方式:計算某個樣本的梯度,用一個樣本的梯度去代替整體樣本的梯度。
因為我們是用一個樣本的梯度來估計整個資料集的梯度,具有一定的的隨機性(誤差),因此稱為隨機梯度下降。

為了提高效率,我們採用一個折衷的版本。我們使用小批量的(mini-batch)訓練資料來估計梯度。事實上,絕大部分場景下我們使用的都是該處理方式。
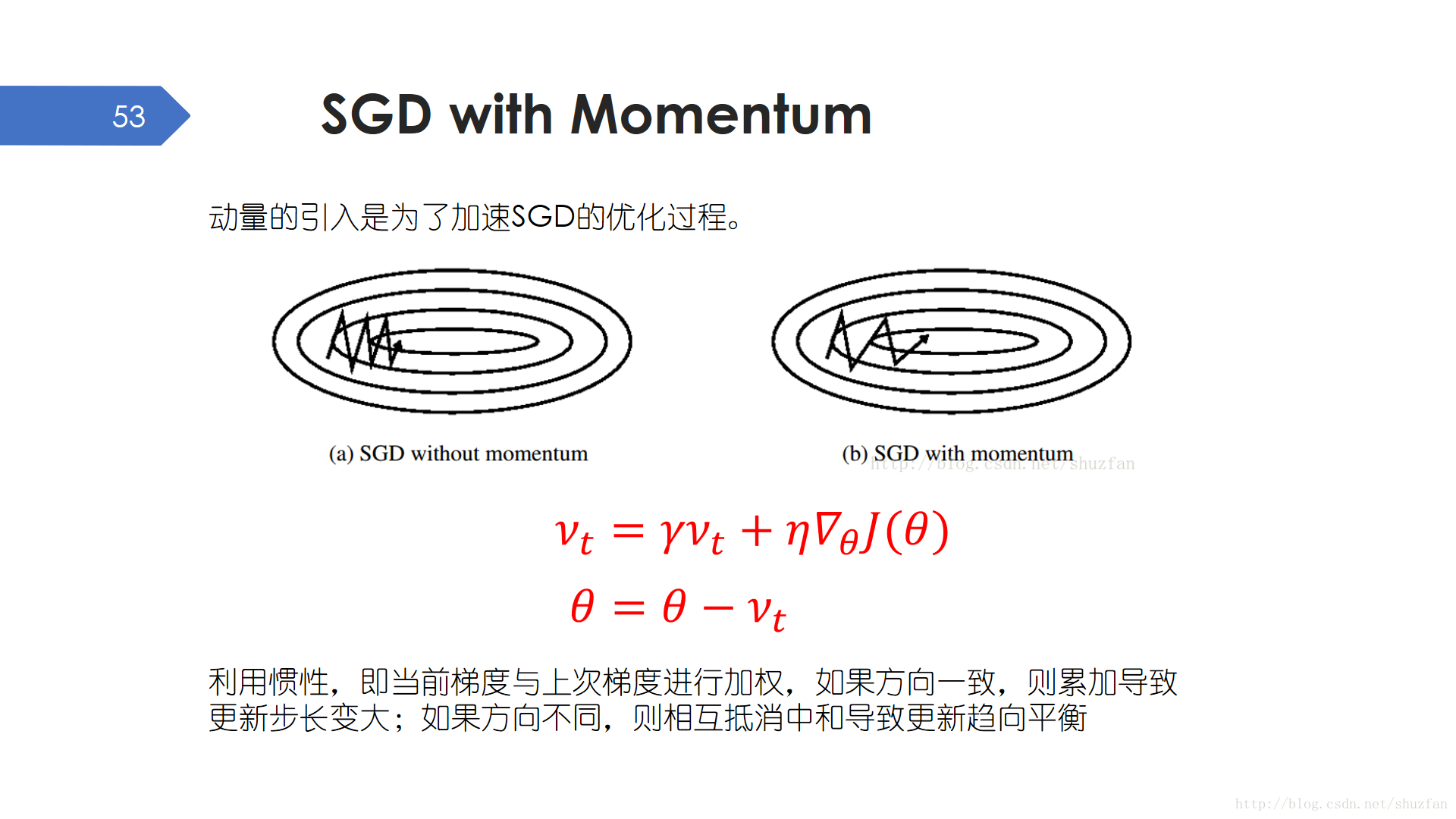
動量的引入是為了加速SGD的優化過程。簡單分析下公式就會發現,帶動量的SGD在計算當前梯度時會加上一部分上次的梯度。由於梯度是帶方向的向量,當前梯度與上次梯度進行加權,如果方向一致,則累加導致更新步長變大;如果方向不同,則相互抵消中和導致更新趨向平衡。

另外就是引數初始化的問題。我們一般採用隨機引數初始化,主要是為了破壞網路的對稱性。試想,如果所有引數都初始化一樣,那網路的很多連線就會因為重複而浪費。隨機通常採用均勻分佈和高斯分佈,因為二者都只需要均值和方差兩個引數便可以控制。通常都是採用零均值,置於方差早期大多根據經驗設定,後來也有人進行具體研究,比較有代表性的就是 Xavier 和 MSRA方法,二者的出發點基本一致。
神經網路可以說在學習一個非常複雜的非線性表示式來描述輸入資料的分佈。學習到最後收斂了應當是一個穩定的分佈,而每一層的分佈也應當是穩定的。但可惜的是,每一層的引數每次都在更新導致其分佈也在變化,這不利於 “資訊的流動”。因此,我們應當儘量保證每一層同分布。於是Xavier經過推導認為某一層引數的方差應當同時等於輸入和輸出神經元個數的倒數,折衷後就有了上面的表示式。 MSRA的推導也類似,只不過採用了高斯分佈。

為了保證分佈穩定統一,前面設計了特殊的網路引數初始化策略。事實上,我們還可以通過更加強硬的手段在每一個卷積層或者全連線層後追加一個Batch Normalization層來對輸出進行0均值單位方差歸一化。 歸一化的方法很簡單:減去均值除以方差。由於均值和方差是通過一個batch的樣本計算得到的,因此叫Batch Normalization。
—————————————————————————————————————————————
接下來介紹一些經典的神經網路模型:
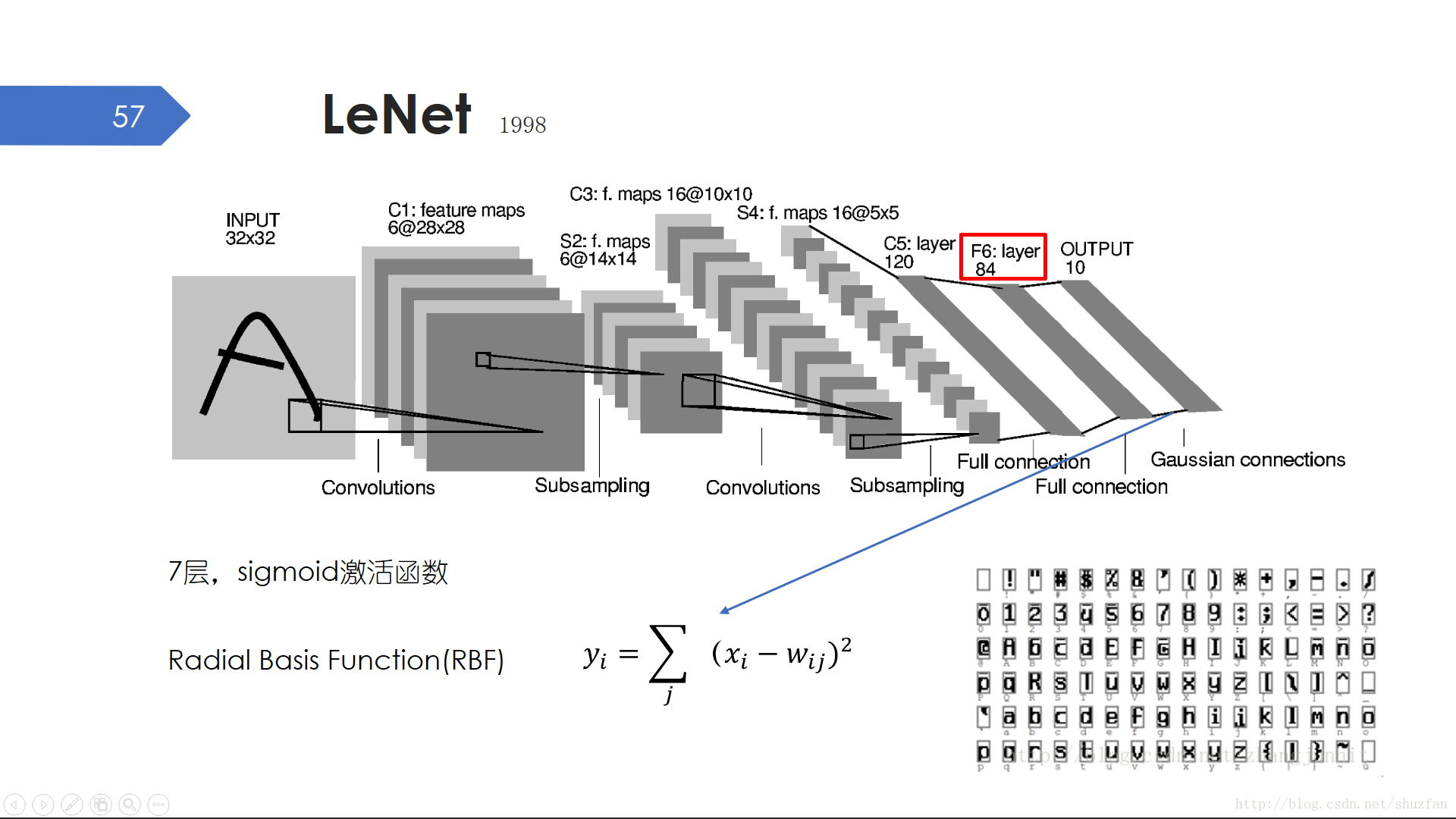
LeNet被美國銀行和郵政系統用來識別支票、郵政編碼中的的手寫或機打數字。LeNet共有7層,主要使用了卷積層和全連線層,引數也不算多,但準確性很高,其可被商用便可證明。
早期的神經網路研究領域一片灰暗,LeNet就像那一點星火。
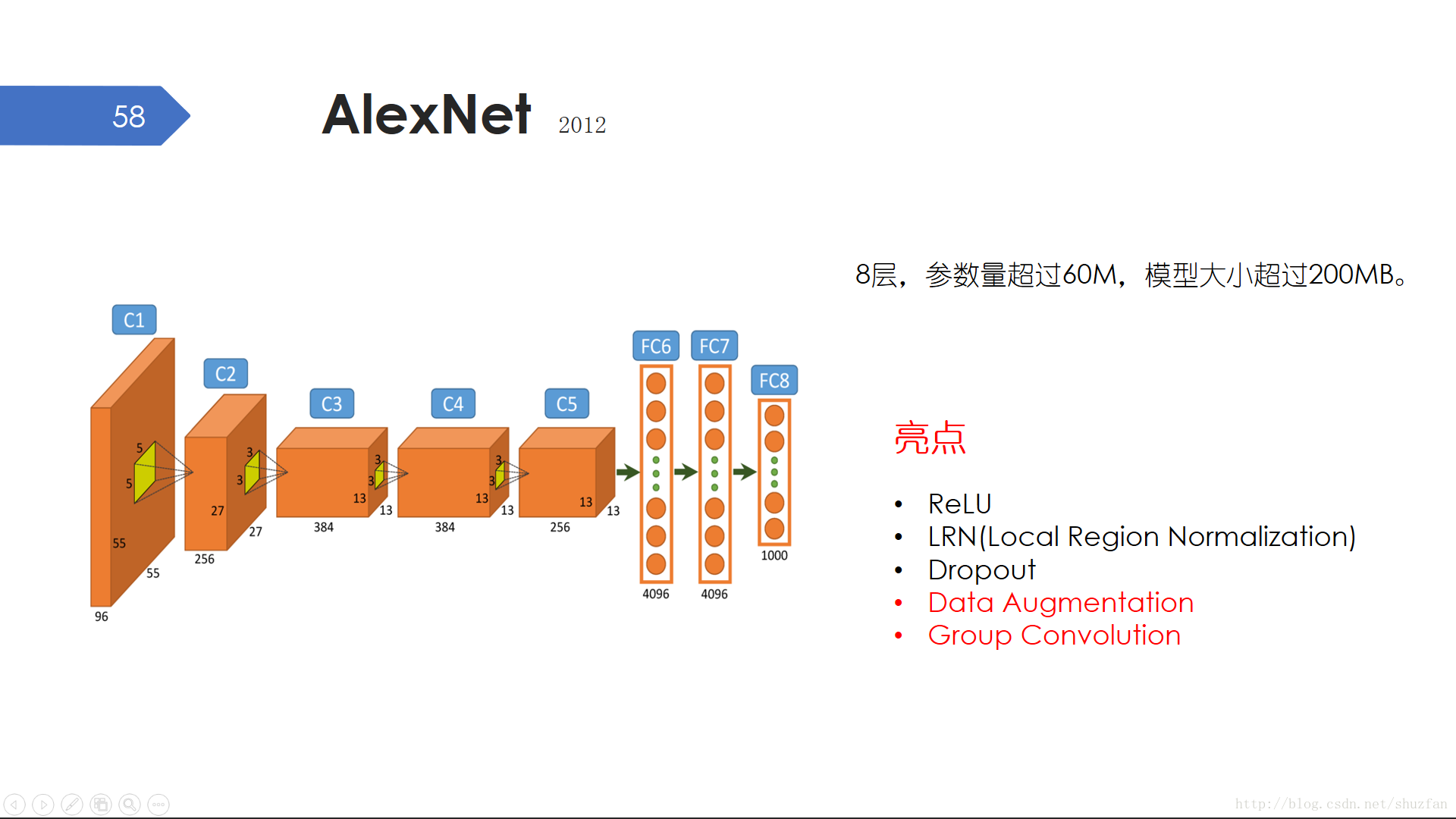
以深度卷積神經網路為代表的這場AI大火真正熱烈起來應該始於2012年的AlexNet。 在ImageNet這一大規模影象識別比賽上,基於DCNN的ImageNet以壓倒性的優勢奪冠。儘管當時很多人表示對ImageNet的通用性特別是可解釋性很懷疑。因為它的引數太多了,超過60M的引數使得ImageNet變成了一個黑箱,我們根本無法瞭解這個箱子裡面所包含的隱層到底學到了什麼。
效果好才是王道,DCNN很快流行起來。
ImageNet使用了很多優化技術來提高模型效果,比如我們已經介紹過的ReLU啟用層和Dropout層。還有LRN層,雖然現在已經不是很常用了,大家現在基本都在使用BatchNorm層。另外兩種值得一提的就是Data Augmentation(資料擴增)和 Group 卷積。

Data Augmentation(資料擴增)是在深度學習中普遍使用的一種技術或者說策略,其目的就是為了增強訓練資料的多樣性。一方面,神經網路模型通常有巨量引數,即模型很容易過擬合,因此增加資料多樣性可以有效降低過擬合的風險。另一方面,深度學習內部的學習機理我們其實並不清楚,我們其實不能高估其能力,比如簡單的手寫數字畫素取反就會導致錯誤的識別,因此增加更多各種各樣的訓練樣本,有助於提高模型的泛化能力。(所謂的泛化能力是指模型在未曾見過的資料上的表現)
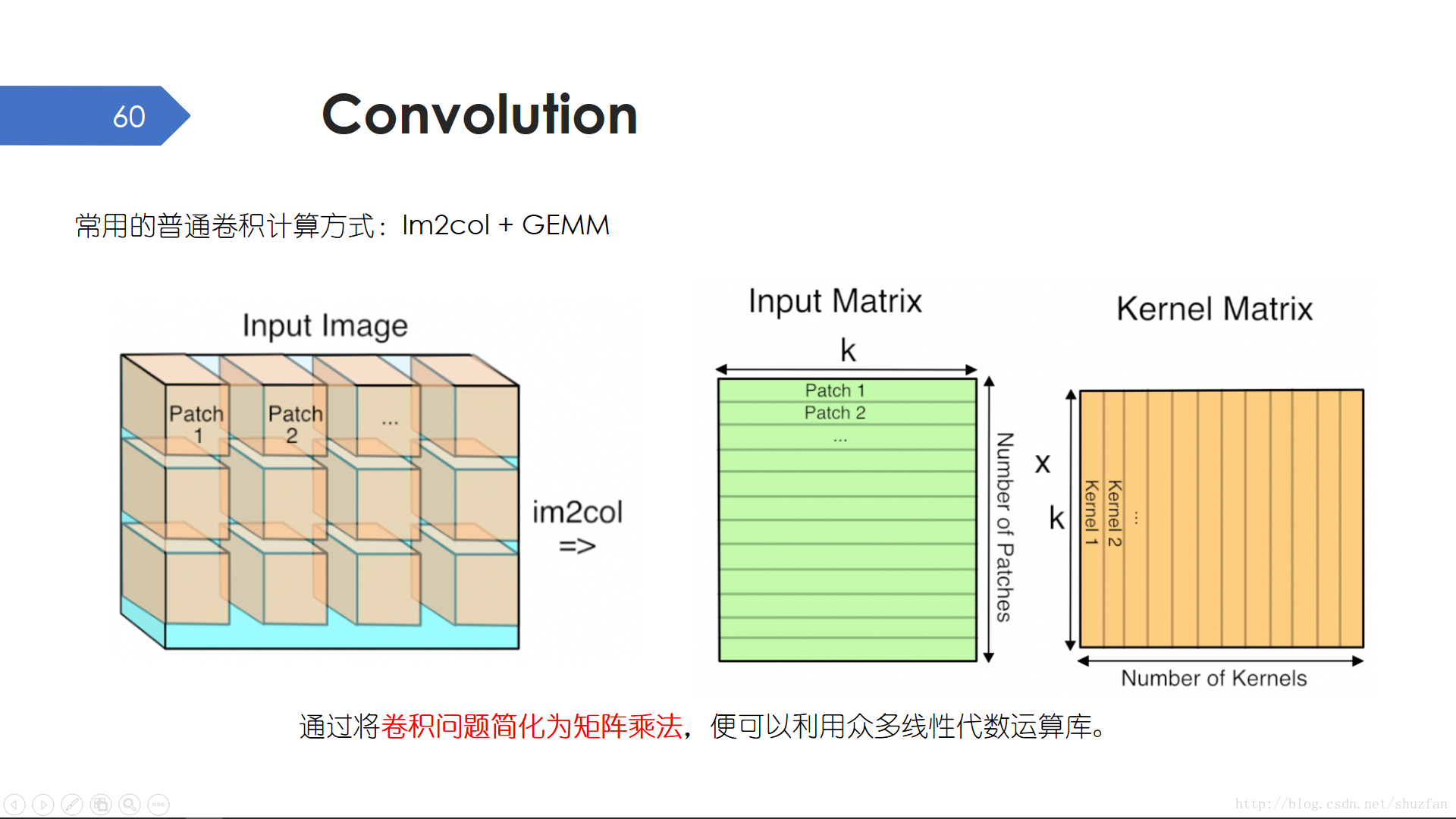
AlexNet中使用了Group卷積這一特殊操作,在瞭解該卷積之前我們先說一下普通卷積是怎樣實現的。由於卷積的普遍使用,因此弄清楚卷積的原理和實現方式是很重要的。
卷積最常用的實現方式是 im2col + GEMM(影象塊展開 + 矩陣乘法)。我們知道卷積的原理就是滑動視窗,然後視窗內做點積運算。滑窗意味著迴圈,如果我們每滑動一次就做一次點積運算,這樣效率就太低了。於是我們把整個過程分為兩步:第一步對影象滑窗遍歷,每滑動一次就把影象塊展開作為臨時矩陣的一行;第二步直接進行一個大的矩陣乘法。
上述這種卷積實現方法速度較快的原理其實就是用空間換時間。因為要把每次滑動的塊展開並存儲,因此記憶體佔用較大。 因為可以把很多小的點積運算變成一個大的矩陣乘法,因此效率更高。
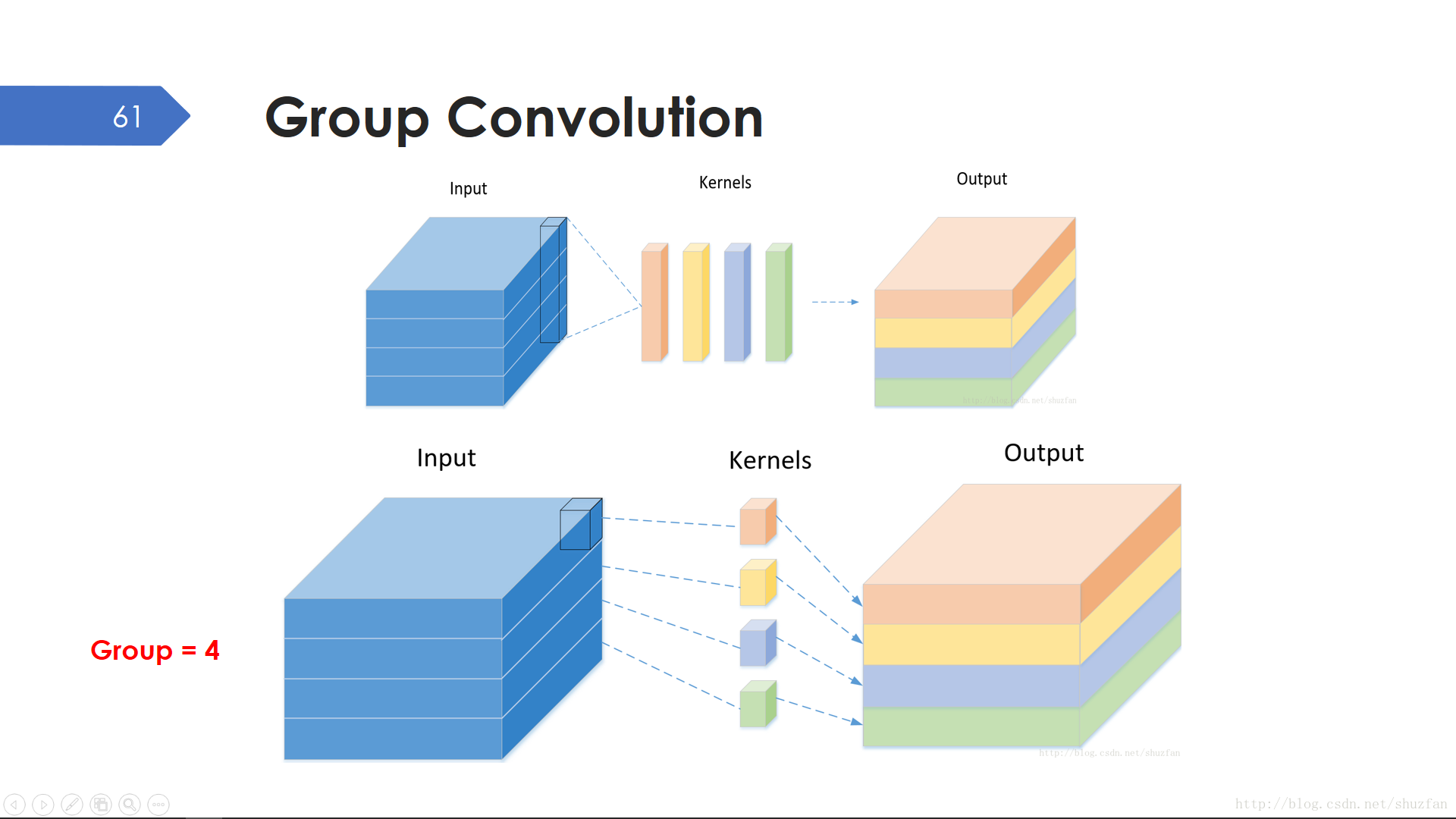
普通的卷積其卷積核是3D的,且第3個維度等於輸入feature map的channel數,如上圖頂部所示。在AlexNet中使用了一種與眾不同的Group卷積,以Group=4為例,此時每個卷積核的第3個維度僅僅等於輸入feature map的channel數的1/4。
從上圖我們可以看出,如果使用了Group,那麼輸出的維度不會有變化,但引數的數量卻會平方倍減少。當初AlexNet使用Group=2的原因僅僅是GPU視訊記憶體不夠,但卻沒有料到這一操作在目前很多神經網路加速方法中被用的風生水起(大佬就是大佬)。
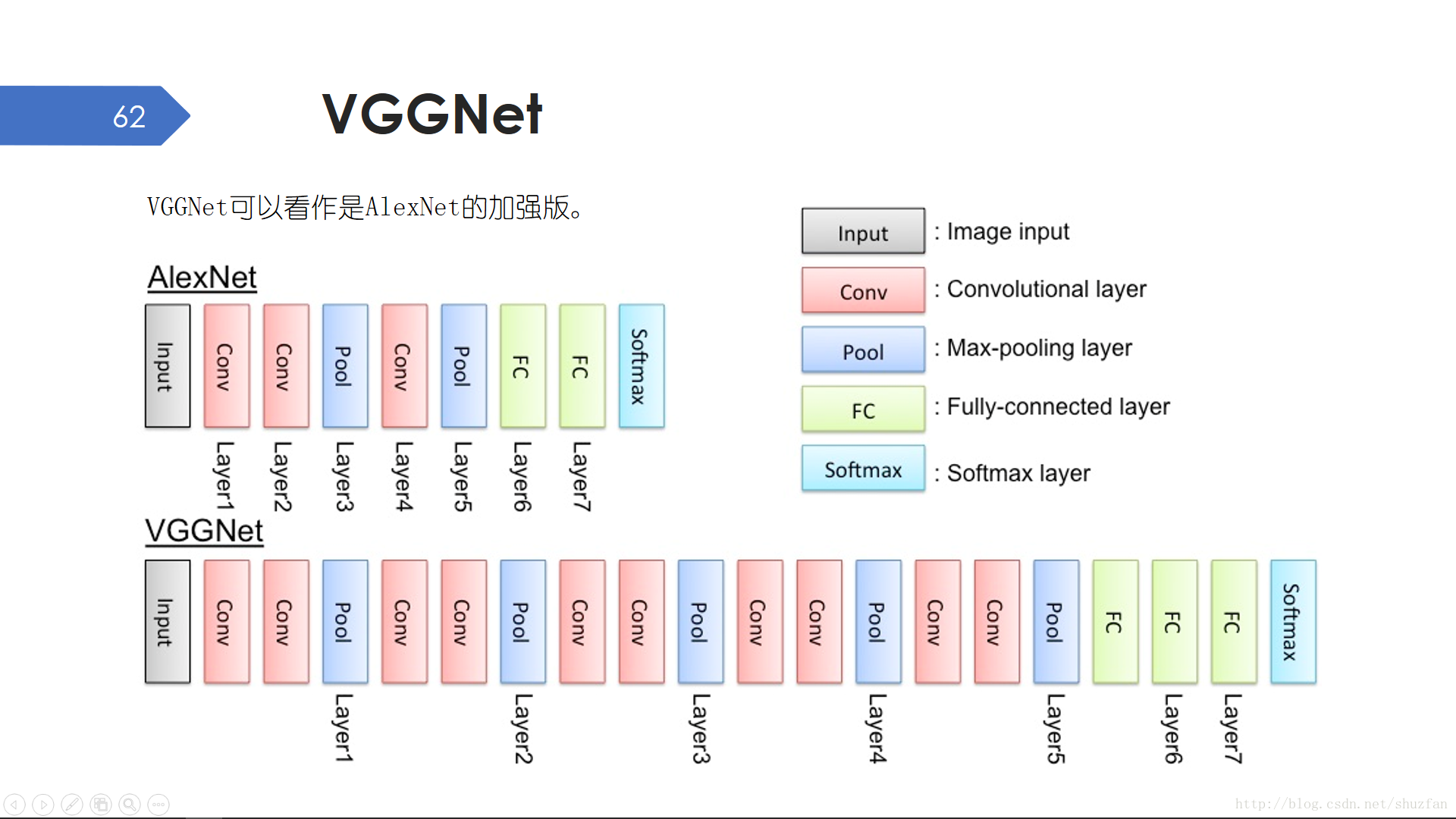
VGGNet可以看作是AlexNet的加強版。提升神經網路表達能力最直接的方法就是把網路變寬變深,VGGNet在寬度上作了進一步增強,但模型的引數量也多的讓人窒息。
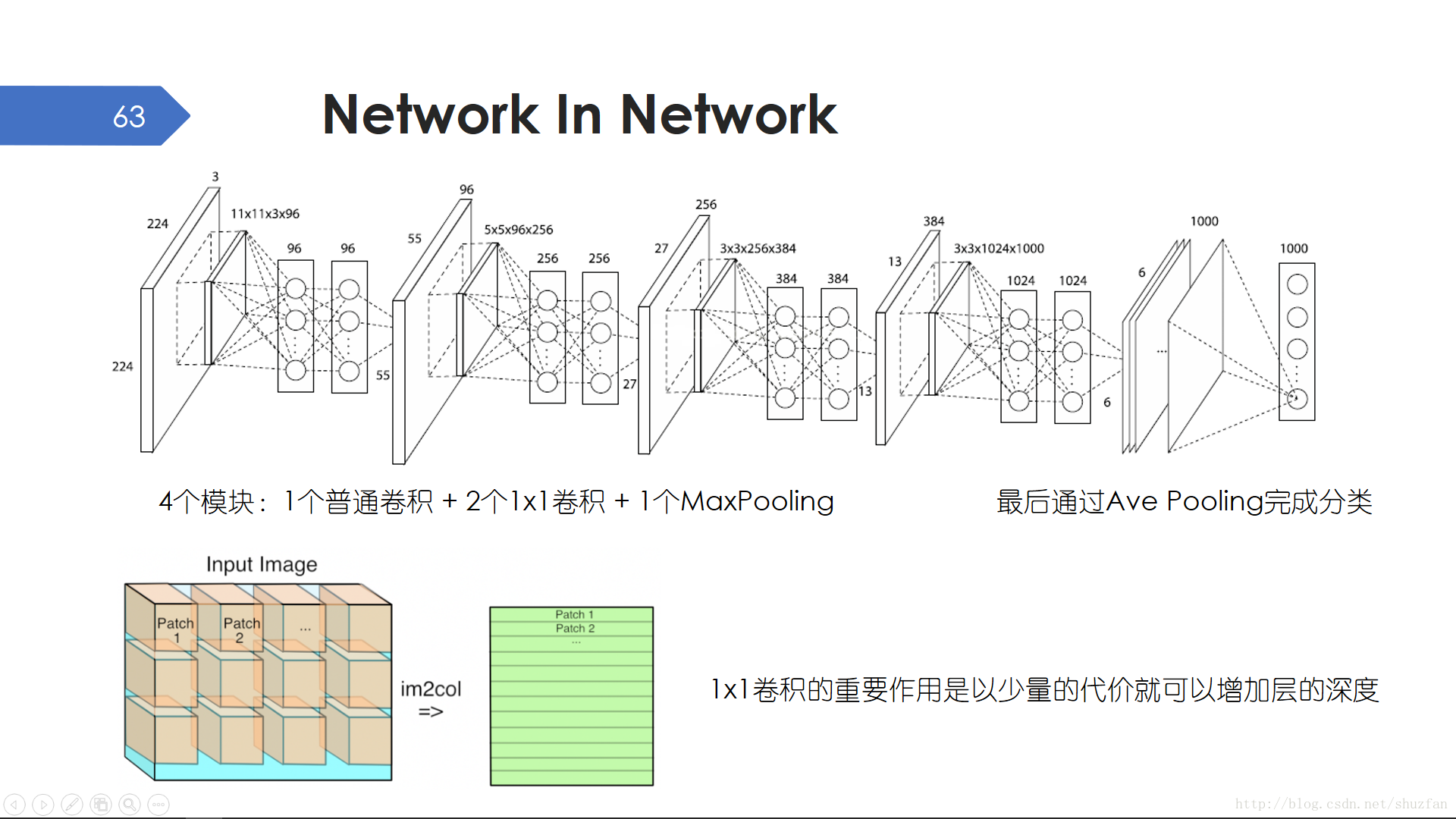
通常把網路變深所帶來的收益要高於把網路變寬。 Network in Network 簡稱NIN,採用了標準的模組化設計。NIN的一大亮點是大量使用了1x1卷積,以少量的引數就可以增加層的深度。此外,1x1卷積可以省略im2col步驟,直接通過矩陣乘法完成,因此效率更高。
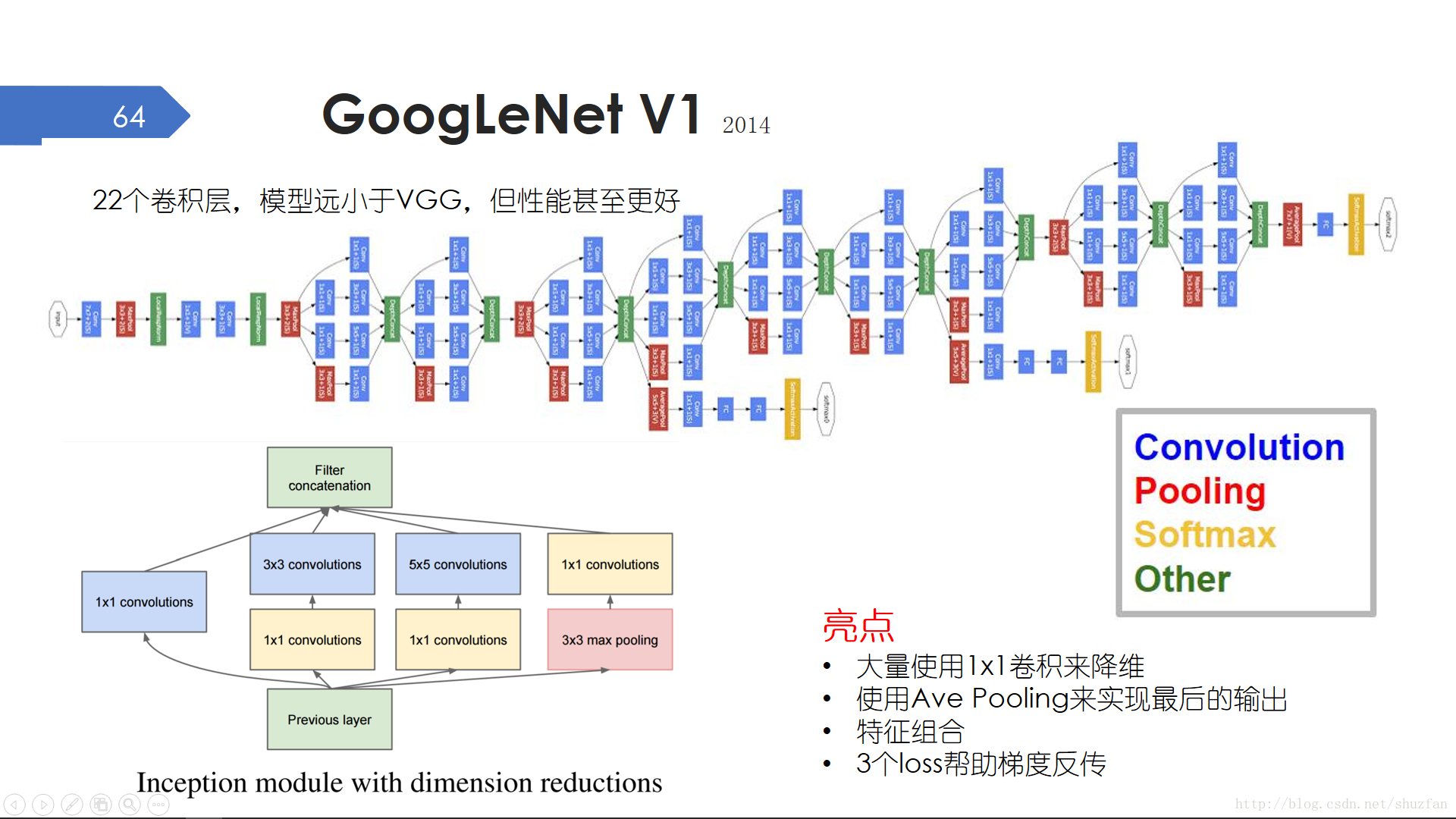
如果說VGGNet以簡單粗獷取勝,那麼GoogLeNet可以說把設計玩到了極致。GoogLeNet為了向LeNet致敬,特意將名字中的字母 “L”大寫。
GoogLeNet共有22個卷積層,模型大小約50MB,遠小於VGGNet的(約)500M,但效能很接近。GoogLeNet大體上也是模組化設計,其模組叫做 “Inception module”。“Inception”一詞來源於電影盜夢空間,因為裡面小李子說 “We need to go deeper”。該標準模組中對輸入施加不同的卷積核,然後將多個分支的特徵進行拼接,這樣便可以綜合利用不同的特徵。此外,由於網路太深可能導致梯度消失,因此整個網路共使用了3個Loss來幫助梯度反傳。
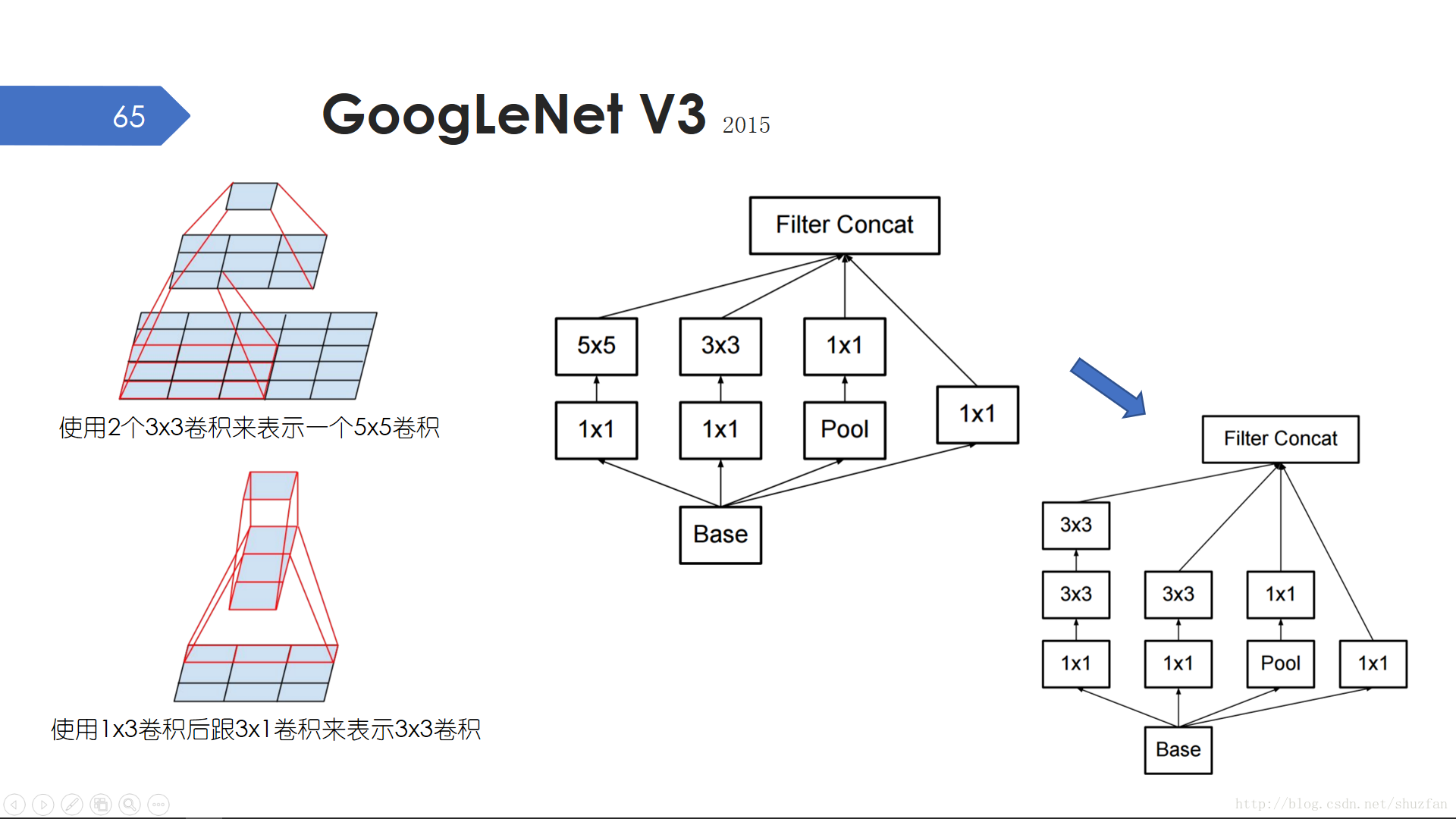
GoogLeNet有好幾個進化版本。對於V3版本,主要的改進是用小卷積核級聯來代替大卷積核,比如兩個3x3卷積層相當於一個5x5卷積層,但引數量只有18/25。然後也用1xn卷積後跟nx1卷積來代替nxn卷積,這樣引數量就只有2/n。
GoogLeNet網路比較深效能也不錯,但訓練難度比較高,明顯比VGGNet要高,所以VGGNet流傳好像更多一點。
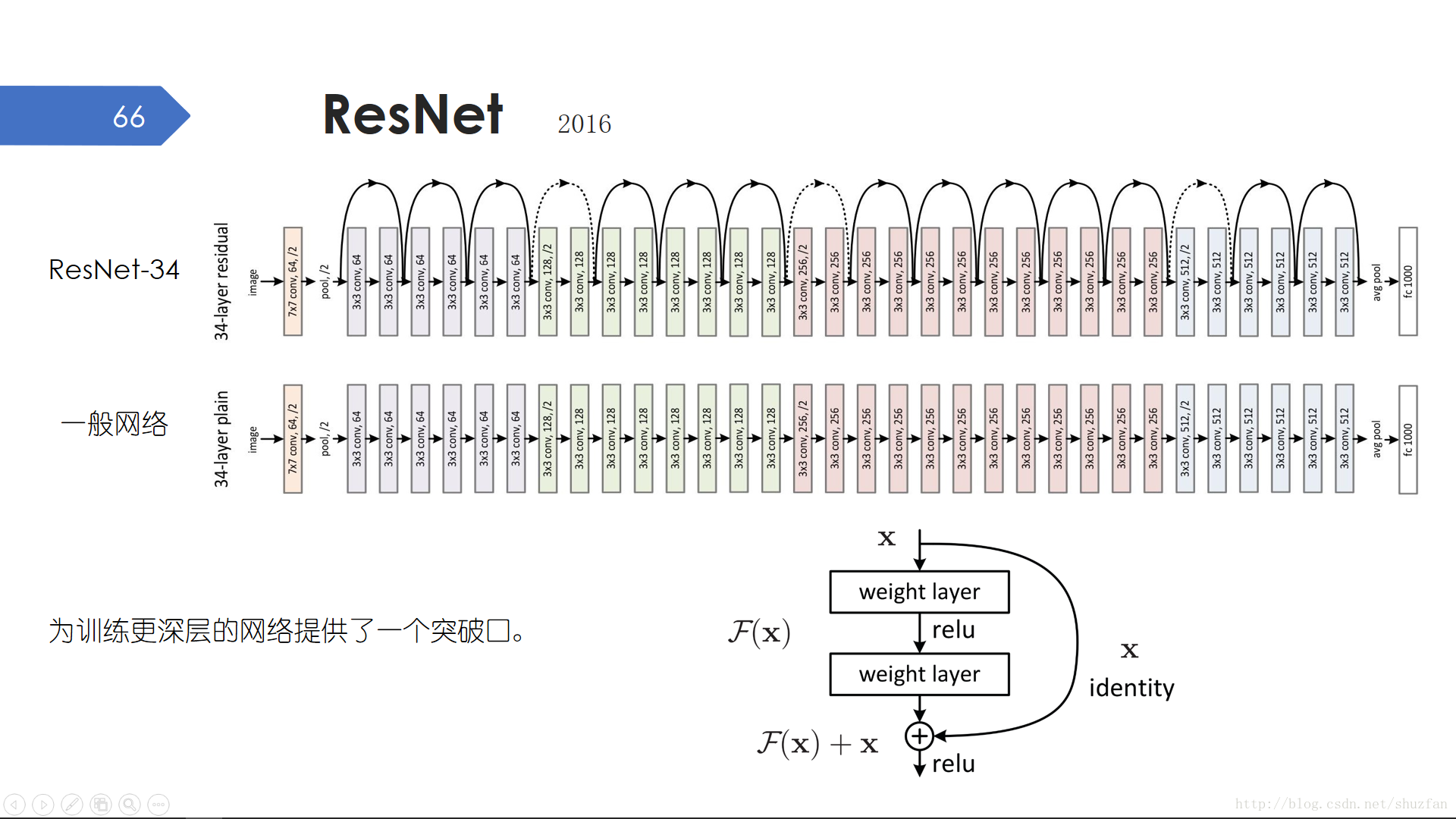
ResNet,又叫“殘差網路”,其最大的貢獻是為深層網路的訓練提供了一個突破口。ResNet34,ResNet152以至於後面1001層的也出現了。ResNet和普通的直線型結構相比,主要是多了一些 “跳接”。
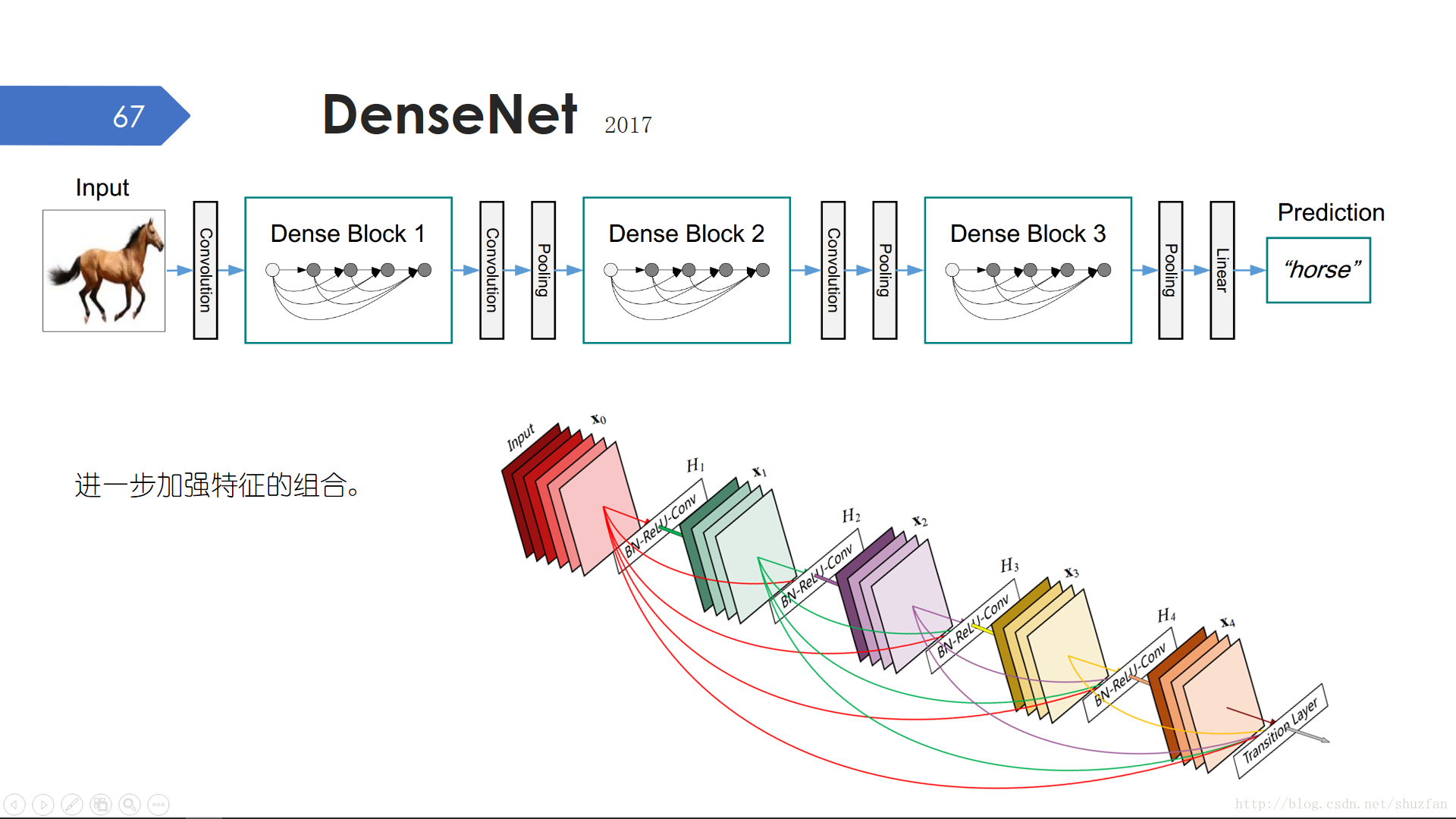
DenseNet相比ResNet最大的改進就是引入了更多的 “跳接”,同時將ResNet中的 “+” 操作改為了特徵拼接。