
【機器學習】Ranking SVM原理
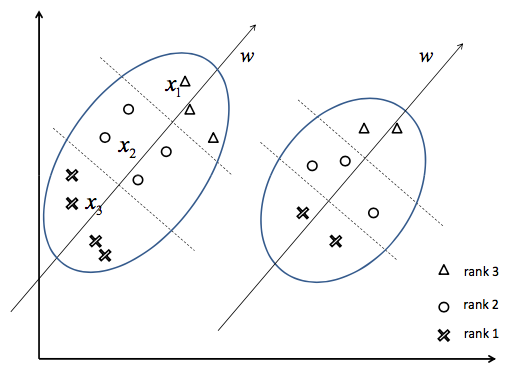
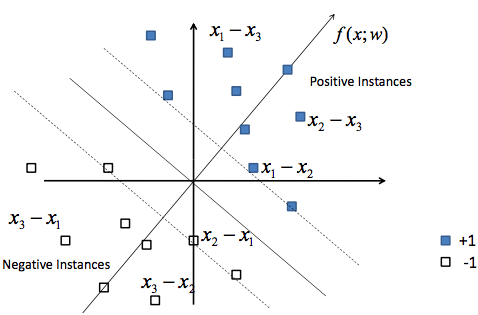
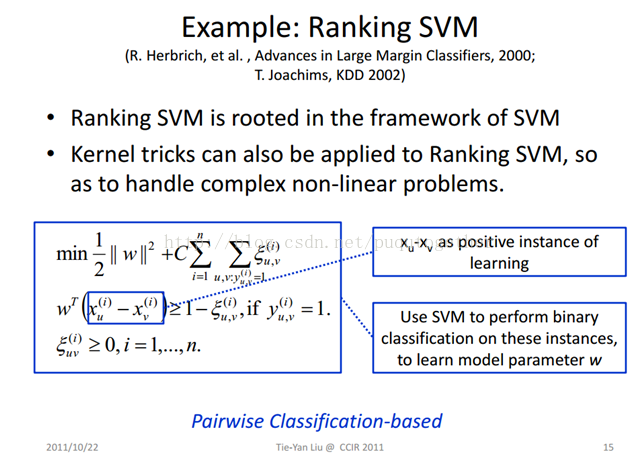
假定有x1,x2,x3三個點,查詢q,對應的查詢排序結果為x1,x2,x3。那麼可獲得新的點,即x1-x2,x1-x3, x2-x3, x2-x1,x3-x1,x3-x2,它們的標籤分別為1,1,1,-1,-1,-1。
有了資料點,以及標籤,就領用傳統的SVM,訓練出超平面。
在測試的時候,我們就把一個query的所有結果先構建所有可能的pair,然後輸入到學習到的模型中,得到每個pair的相對順序。根據推算就可以得到所有搜尋結果的排序了。
缺點
1. 沒考慮查詢與文件的關係
相關推薦
【機器學習】Ranking SVM原理
假定有x1,x2,x3三個點,查詢q,對應的查詢排序結果為x1,x2,x3。那麼可獲得新的點,即x1-x2,x1-x3, x2-x3, x2-x1,x3-x1,x3-x2,它們的標籤分別為1,1,1,-1,-1,-1。 有了資料點,以及標籤,就領用傳統的SVM,訓練出超平面。 在測試的時候,
【機器學習】HOG+SVM進行車輛檢測的流程及原始碼
在進行機器學習檢測車道線時,參考了這篇博文,基於LBP+SVM實現了車道線檢測的初步效果。覺得講解很到位,程式碼也容易理解和修改,故在此分享,供更多人學習。原地址:https://www.cnblogs.com/louyihang-loves-baiyan/p/4658478.html HOG
【機器學習】Weighted LSSVM原理與Python實現:LSSVM的稀疏化改進
【機器學習】Weighted LSSVM原理與Python實現:LSSVM的稀疏化改進 一、LSSVM 1、LSSVM用於迴歸 2、LSSVM模型的缺點 二、WLSSVM的數學原理 三、WLSSVM的python實現 參
【機器學習】Apriori演算法——原理及程式碼實現(Python版)
Apriopri演算法 Apriori演算法在資料探勘中應用較為廣泛,常用來挖掘屬性與結果之間的相關程度。對於這種尋找資料內部關聯關係的做法,我們稱之為:關聯分析或者關聯規則學習。而Apriori演算法就是其中非常著名的演算法之一。關聯分析,主要是通過演算法在大規模資料集中尋找頻繁項集和關聯規則。
【機器學習】支援向量機SVM原理及推導
參考:http://blog.csdn.net/ajianyingxiaoqinghan/article/details/72897399 部分圖片來自於上面部落格。 0 由來 在二分類問題中,我們可以計算資料代入模型後得到的結果,如果這個結果有明顯的區別,
【機器學習】支持向量機(SVM)
cto nom 機器 ins 神經網絡 學習 參數 mage 36-6 感謝中國人民大學胡鶴老師,課程深入淺出,非常好 關於SVM 可以做線性分類、非線性分類、線性回歸等,相比邏輯回歸、線性回歸、決策樹等模型(非神經網絡)功效最好 傳統線性分類:選出兩堆數據的質心,並
【機器學習】--SVM從初始到應用
圖片 eight 不變 VM 向上 解決 支持向量 In TP 一、前述 SVM在2012年前還是很牛逼的,但是12年之後神經網絡更牛逼些,但我們還是很有必要了解SVM的。 二、具體 1、問題引入 要解決的問題:基於以下問題對SVM進行推導 1.1 3條線都可以將兩邊點分類
【機器學習】最小二乘法支援向量機LSSVM的數學原理與Python實現
【機器學習】最小二乘法支援向量機LSSVM的數學原理與Python實現 一、LSSVM數學原理 1. 感知機 2. SVM 3. LSSVM 4. LSSVM與SVM的區別 二、LSSVM的py
【機器學習】最大熵模型原理小結
最大熵模型(maximum entropy model, MaxEnt)也是很典型的分類演算法了,它和邏輯迴歸類似,都是屬於對數線性分類模型。在損失函式優化的過程中,使用了和支援向量機類似的凸優化技術。而對熵的使用,讓我們想起了決策樹演算法中的ID3和C4.5演算法。理解了最
【機器學習】XgBoost 原理詳解 數學推導
XgBoost (Xtreme Gradient Boosting 極限 梯度 增強) 1.基本描述: 假設Xg-模型有 t 顆決策樹數,t棵樹有序串聯構成整個模型,各決策樹的葉子節點數為 k1,k2,...,kt,
【機器學習】AdaBoost 原理詳解 數學推導
AdaBoost 自適應 增強 Boosting系列代表演算法,對同一訓練集訓練出不同的(弱)分類器,然後集合這些弱分類器構成一個更優效能的(強)分類器
【機器學習】SVM核函式的計算
J=∑iαi−12∑i∑jαiαjdidjk(xi)Tk(xj)=∑iαi−12∑i∑jαiαjdidjK(xi,xj)subjectto∑αidi=0,0≤αi≤C 在優化好αi拉格朗日量後,我們得
【機器學習】SVM基礎知識+程式碼實現
1. 基本知識 二分類:通過分離超平面對資料點進行分類,訓練分離超平面。 原理:最大化支援向量到分離超平面的距離。支援向量:離分離超平面最近的點。 2. 完全線性可分(硬間隔) 2.1 SVM基本型 分離超平面:。(訓練中更新w和b,或alpha,使得分離超
【機器學習】【層次聚類演算法-1】HCA(Hierarchical Clustering Alg)的原理講解 + 示例展示數學求解過程
層次聚類(Hierarchical Clustering)是聚類演算法的一種,通過計算不同類別資料點間的相似度來建立一棵有層次的巢狀聚類樹。在聚類樹中,不同類別的原始資料點是樹的最低層,樹的頂層是一個聚類的根節點。建立聚類樹有自下而上合併和自上而下分裂兩種方法,本篇文章介紹合併方法。層次聚類的合併演算法層次聚
【機器學習】用libsvm C++訓練SVM模型
前言:本文大水文一篇,大神請繞道。在正文之前,首先假設讀者都已經瞭解SVM(即支援向量機)模型。 1. introduction libsvm是臺灣大學林智仁(Chih-Jen Lin)教授於2001年開發的一套支援向量機的工具包,可以很方便地對資料進行分類
【機器學習】tensorflow: GPU求解帶核函式的SVM二分類支援向量機
SVM本身是一個最優化問題,因此理所當然可以用簡單的最優化方法來求解,比如SGD。2007年pegasos就發表了一篇文章講述簡單的求解SVM最優化的問題。其求解形式簡單,但是並沒有解決核函式計算量巨大的問題。這裡給出了一個tensorflow的帶核函式的SVM
【機器學習】決策樹(上)——從原理到演算法實現
前言:決策樹(Decision Tree)是一種基本的分類與迴歸方法,本文主要討論分類決策樹。決策樹模型呈樹形結構,在分類問題中,表示基於特徵對例項進行分類的過程。它可以認為是if-then規則的集合,也可以認為是定義在特徵空間與類空間上的條件概率分佈。相比樸素
【機器學習】LDA線性判別分析原理及例項
1、LDA的基本原理 LDA線性判別分析也是一種經典的降維方法,LDA是一種監督學習的降維技術,也就是說它的資料集的每個樣本是有類別輸出的。這點和PCA不同。PCA是不考慮樣本類別輸出的無監督降維技術。LDA的思想可以用一句話概括,就是“*投影后類內方
【機器學習】支援向量機SVM及例項應用
【機器學習】支援向量機1.分類超平面與最大間隔2.對偶問題與拉格朗日乘子法3.核函式4.軟間隔與正則化 準備: 資料集 匯入SVM模組 步驟:1.讀取資料集 2.劃分訓練樣本與測試樣本 3.訓練SVM
【機器學習】決策樹演算法的基本原理
參考周志華老師的《機器學習》一書,對決策樹演算法進行總結。 決策樹(Decision Tree)是在已知各種情況發生概率的基礎上,通過構建決策樹來求取淨現值期望值大於等於0的概率,評價專案風險,判斷其可行性的決策分析方法,是直觀運用概率分析的圖解法。