
基於Kafka與Spark的實時大資料質量監控平臺
微軟的ASG (應用與服務集團)包含Bing,、Office,、Skype。每天產生多達5 PB以上資料,如何構建一個高擴充套件性的data audit服務來保證這樣量級的資料完整性和實時性非常具有挑戰性。本文將介紹微軟ASG大資料團隊如何利用Kafka、Spark以及Elasticsearch來解決這個問題。
案例簡介
本案例介紹了微軟大資料平臺團隊設計和部署的基於開源技術(Kafka、Spark、ElasticsSearch、Kibana)的大資料質量監控平臺,這個平臺具有實時、高可用、可擴充套件、高度可信的特性,成為微軟Bing、Office365、Skype等年收入270+億美元的業務在監控資料質量方面的可靠技術保障。
同時,基於業務需要,我們在設計和實現中達成下面一系列的目標:
監控流式資料的完整性與時延;
需要監控的資料管道(pipeline)具有多個數據生產者、多處理階段、多資料消費者的特性;
資料質量的監控需要近實時(near real time);
資料質量發生問題的時候,需要提供相應的診斷資訊來幫助工程師迅速解決問題;
監控平臺的服務本身需要超級穩定和高可用, 大於99.9%線上時間;
監控與審計本身是高度可信;
平臺架構可以水平擴充套件 (Scale out)。
背景及問題引入
為了服務微軟的Bing、Office 365以及Skype業務,我們的大資料平臺需要處理每天高達十幾PB級別的海量大資料,所有的資料分析、報表、洞見以及A/B測試都依賴於高質量的資料,如果資料質量不高的話,依賴資料做決策的業務都會受到嚴重影響。
與此同時,微軟業務對於實時資料處理的需求也日益增加,以前監控批處理資料(batch data)的很多解決方案已經不再適用於實時的流式資料的質量監控。
在另外一個層面,基於歷史原因,各個業務集團往往使用不同的技術、工具來做資料處理,怎麼整合這樣異構的技術、工具以及在此之上的資料質量監控也是一個急需解決的問題。
圖1是我們資料處理平臺的一個概念性架構。從資料生產者這端,我們通過在客戶端以及服務端使用通用的SDK,按照通用的schema來產生資料,資料通過分佈在全世界的資料收集服務(collectors)來分發到相應的Kafka, 然後通過pub/sub模式由各種各樣的計算以及儲存框架來訂閱。
這樣各種團隊就可以選擇他們最熟悉或者一直以來使用的工具來做處理。例如,從實時處理的角度,各個業務團隊可以選用比如Spark或者微軟的USQL streaming處理框架,以及其他第三方的工具來做一些特定場景的分析,比如日誌分析的Splunk、互動式分析的Interana等。在批處理框架上,使用者可以選用開源社群的Hadoop,、Spark或者微軟的Cosmos等。
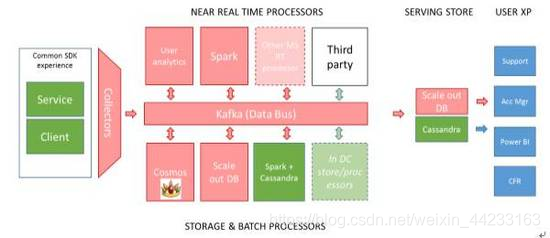
圖1: 整合各個業務集團的異構資料系統的架構
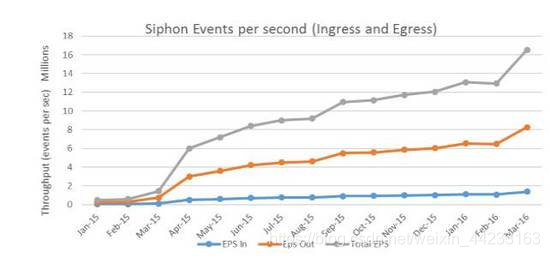
圖2:快速增長的實時資料
如圖2所示,我們在遷移大資料到圖1架構的過程中,也看到實時流式資料的快速增長。每天峰值訊息高達一萬億個以上,每秒處理一百三十萬個訊息, 每天處理3.5PB流式資料。
資料監控的場景以及工作原理
3.1資料監控場景
基於業務需求,我們總結概括了需要被監控的資料處理管道特性(如圖3)
多資料生產者(multiple data producers),資料來自客戶端和服務端;
多個數據消費者(multiple data consumers),這裡特指各種資料處理框架;
多資料監控階段(multiple stages),從資料產生到資料處理,資料往往流經多個數據管道的元件,我們需要通過監控確保每個階段資料都不會發生丟失、高時延、以及異常。
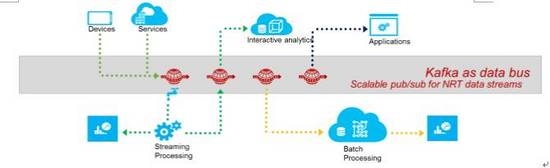
圖3: 多資料生產者、多階段、多資料消費者的資料管道
3.2工作原理
基於圖3的資料管道,我們把問題具體化為如何確保基於Kafka的資料管道上下游的資料完整性、實時性、資料異常的監測。圖4是一個抽象化的監控架構以及工作原理。
藍色元件是資料管道里資料流經的各個處理階段;綠色元件是本文中實時資料質量監控的核心服務Audit Trail。在資料流經各個元件的同時,相應的審計(audit)資料也會同時發到Audit Trail, 這個審計資料可以看作是一種元資料(meta data),它包含關於資料流的資訊,例如該訊息是在哪個資料中心、哪臺機器產生;該訊息包含幾條記錄、大小、時間戳等。Audit Trail彙總了各個資料處理元件發來的元資料後,就可以實時做各種資料質量的評估,比如資料在此時刻的完整性如何、實時性如何、有無異常。
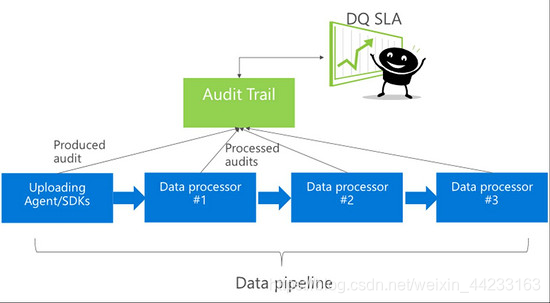
圖4:資料流與監控流,監控流實時彙總到Audit Trail
基於圖5的審計元資料,一旦發生資料質量問題,工程師可以快速定位是哪個資料中心的哪臺伺服器在什麼時間段發生了問題,然後快速採取相應行動來解決或緩解問題,並把對下游資料處理的影響降到最低。

圖5: 審計元資料的結構
可被監控的資料質量問題可以分為如下幾類:
資料時延超出規定的SLA (service level agreement)
工程師可以通過如圖6所示的時延狀態圖快速瞭解在資料質量時延這個維度是否正常,這對於對實時性要求比較嚴格的資料產品及應用非常重要,如果資料延遲到來,很多時候就失去了意義。
需要注意的是,圖表在這裡起到的只是輔助作用,在真正的生產環境中是通過系統API呼叫來定期檢查SLA的符合情況,一旦超出時延閾值,會通過電話、簡訊等手段通知值班的工程師來實時解決問題。
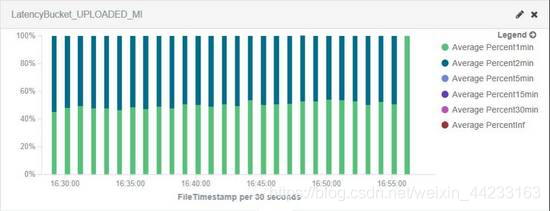
圖6:簡單時延柱狀圖
資料在移動中發生丟失導致完整性不滿足SLA (service level agreement)
工程師可以通過圖7中所示簡單圖表來了解資料完整性的狀態,圖7所示包含兩個資料處理階段:一個數據生產者和兩個資料消費者的應用案例。所以圖表中實際上是三條線,綠色是生產者的實時資料量,藍色和紫色線是兩個資料消費者處理的資料量。如果在理想情況下,資料完整性沒有問題,這三條線是完全重合。本例中在最後一個點出現了分叉,代表資料完整性出現問題,需要工程師進行干預。
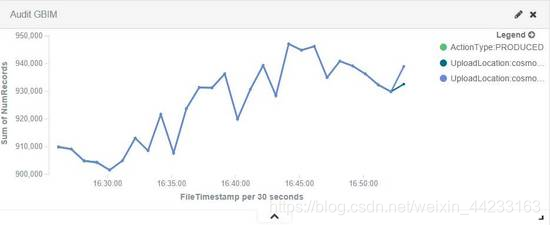
圖7:簡單完整性圖表
資料本身發生異常-通過異常檢測來實時監控
資料本身發生異常,我們由相應的基於統計元資料的異常檢測(如圖8)來做實時監控。異常檢測是一個在工業界非常普遍的問題和挑戰,幾乎每個網際網路公司都會有做異常檢測的服務或平臺,但是做好很不容易,這是一個可以單獨寫一篇文章的大題目,這裡只是單闢一個章節做簡單的演算法介紹。
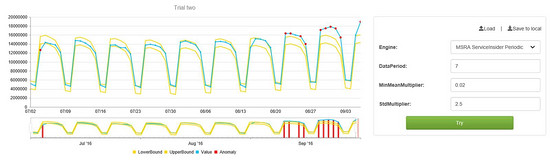
圖8:基於審計資料的異常檢測
本例是通過對於資料量的異常檢測來發現上游寫log問題,或者其他資料生產的邏輯問題。
3.3異常檢測
異常檢測演算法1
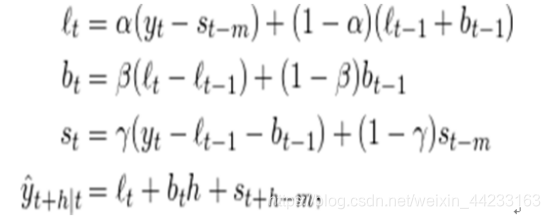
圖 9 Holt-Winters演算法
我們採用了Holt-Winters演算法(圖9)來訓練模型和做預測,並在此之上做了很多改進來增加演算法的強健性和容錯能力。
強健性上的改進包括:
使用Median Absolute Deviation (MAD) 得到更好的估值;
處理資料丟點和噪聲 (例如資料平滑)。
功能上的改進包括:
自動獲取趨勢和週期資訊;
允許使用者人工標記和反饋來更好的處理趨勢變化。
通過比較預測值和實際值,我們採用GLR (Generalized Likelihood Ratio) 來發現異常點。在這上面我們也做了相應的改進,包括:
Floating Threshold GLR, 基於新的輸入資料動態調整模型;
對於噪聲比較大的資料做去除異常點。
異常檢測演算法2
這是一個基於Exchangeability Martingale的線上時間序列的異常檢測演算法,其核心就是假設資料的分佈是穩定的。如果新的資料點的加入導致資料的分佈(distribution)發生比較大的變化,我們就認為異常發生了。所以基於歷史資料,我們需要定義一個新值異常公式(New value strangeness)。下面是這些公式的構成,對數學不感興趣的讀者可以略去。
在某個時刻t, 我們收到一個新的資料點,對於歷史每個資料i:
s[i] = strangeness function of (value[i], history)
Let p[t] = (#{i: s[i] > s[t]}+ r*#{i: s[i]==s[t]})/N, where r is uniform in (0,1)
Uniform r makes sure p is uniform
Exchangeability Martingale: Mt=i=1tϵpiϵ-1
EMtp1,p2,…pt-1=Mt-1
Integrate ϵpiϵ-1 over [0,1] and pi is uniform
報警觸發門檻通過Doob’s maximal inequality控制
Prob (∃ t :Mt>λ)<1λ
對於異常點,Martingale的值就會大於門檻值。
異常檢測演算法3
這是一個簡單而非常有效的基於歷史資料的指數平滑演算法。
它首先基於歷史資料生成動態上下界:
Threshold (width) = min(max(M1Mean, M2Standard Deviation), M3*Mean) (M1
Alert: |Value – predicated value| > Threshold
預測值 = S1+12S2+14S3+18S4+116S51+12+14+18+116
優點在於處理週期性資料的異常檢測很好,並且允許使用者反饋和標記來調整動態上下界。
系統設計概述
基於業務場景的需要,我們在設計和實現中需要達成一系列的目標以及處理相應的挑戰:
監控流式資料的完整性與時延;
需要監控的資料管道(pipeline)具有多個數據生產者、多處理階段、多資料消費者的特性;
資料質量的監控需要近實時(near real time);
資料發生問題的時候,提供相應的診斷資訊來幫助工程師迅速解決問題;
監控平臺的服務本身需要超級穩定和高可用, 99.9%以上線上時間;
監控與審計本身是高度可信;
平臺架構可以水平擴充套件 (Scale out)。
4.1高可用可擴充套件的架構
如圖10所示,審計元資料通過前端服務(front end web service)到達Kafka, 我們利用Kafka來實現高可用的臨時儲存(transient storage), 這樣,我們的資料生產者和消費者在傳送審計資料的同時,就不會發生阻塞進而影響更重要的資料流。
通過Spark streaming的應用,把審計資料按照時間視窗聚合,同時有相應的邏輯處理去重,晚到以及非順序到來的資料,同時做各種容錯處理保證高可用。
ElasticsSearch作為儲存聚合的審計資料,通過Kibana做報表展示,進而通過Data Analysis service對外提供API來使得使用者獲取各種資料質量資訊。
Data Analysis Service作為最終的API端,提供各種資料完整性、實時性、異常的資訊。
上述元件,每個都設計成可以獨立水平擴充套件(Scale out), 並且在設計上保證高容錯已實現高可用性。
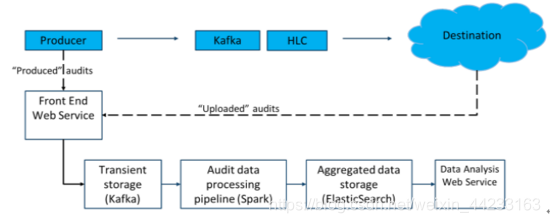
圖10:Audit Trail資料處理架構
4.2異地雙活的可靠性保障
通過雙資料中心Active-Active災備(Disaster recovery)如圖11所示,來進一步保證高可用高可靠的服務。整體架構保證資料流同時通過兩個同構的審計處理管道進行處理,即使一個數據中心因為各種原因下線,整體服務還是處於可用狀態,進而保證全天候的資料質量審計與監控。
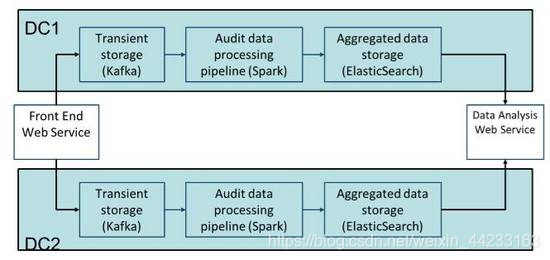
圖11:雙資料中心Active-Active Disaster Recovery
4.3高度可信的審計與監控服務
對於任何監控服務來說,經常被質疑的就是是否監控服務本身的結果是準確可信的。為了保證這一點,我們通過兩種方式來保證服務的可信度:
用來審計自身(Audit for audit)(圖12);
Synthetic probe。
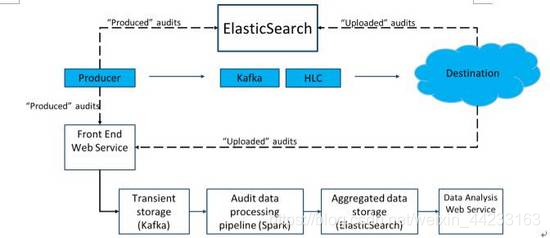
圖12:審計自身
在基於Kafka/Spark/ES的管道之外,我們還有一套獨立的經由ES的審計元資料的處理管道,通過比較上述兩個管道的結果,我們就能保證審計資料的可靠性。
另外,基於synthetic probe的方式,我們每分鐘會發送一組synthetic資料進入前端服務(front end web service), 然後試圖從Data Analysis web service 讀出,通過這種方式進一步保障資料的可靠性。
4.4輔助資料質量問題的診斷
當資料質量發生問題,Audit Trail提供了原始的審計元資料來幫助工程師進一步做問題的診斷。工程師可以使用這些元資料和他們自己的trace來進一步JOIN, 來提供一種互動式的診斷,如圖13。

圖13:把Trace和審計元資料做JOIN, 視覺化的互動診斷檢視
效果評估與總結
通過上述系統架構的設計與部署,我們實現了一系列支援公司Bing,、Office,、Skype業務發展的資料質量監控目標:
監控流式資料的完整性與時延;
需要監控的資料管道(pipeline)具有多個數據生產者、多處理階段、多資料消費者的特性;
資料質量的監控需要近實時(near real time);
資料發生問題的時候,需要提供相應的診斷資訊來幫助工程師迅速解決問題;
監控平臺的服務本身需要超級穩定和高可用, 99.9%線上時間
監控與審計本身是高度可信;
平臺架構可以水平擴充套件 (Scale out)。
同時,我們準備開源這個平臺服務,因為我們相信這個服務本身是一個足夠通用化的解決方案,可以應用於很多公司的資料質量監控場景。
結語
為了幫助大家讓學習變得輕鬆、高效,給大家免費分享一大批資料,幫助大家在成為大資料工程師,乃至架構師的路上披荊斬棘。在這裡給大家推薦一個大資料學習交流圈:658558542 歡迎大家進群交流討論,學習交流,共同進步。
當真正開始學習的時候難免不知道從哪入手,導致效率低下影響繼續學習的信心。
但最重要的是不知道哪些技術需要重點掌握,學習時頻繁踩坑,最終浪費大量時間,所以有有效資源還是很有必要的。
最後祝福所有遇到瓶疾且不知道怎麼辦的大資料程式設計師們,祝福大家在往後的工作與面試中一切順利。