
一篇文章掌握Sql-On-Hadoop核心技術
1. SQL On Hadoop 分類
1.1 查詢延時分類
AtScale 在 2016 年的一篇名為 [15]The Business Intelligence for Hadoop Benchmark 的 SQL On Hadoop 效能測評報告中指出:受查詢資料量大小,查詢型別 (join 表個數,表大小,是否聚合),併發使用者量等因素影響,沒有一個 SQL On Hadoop 系統能夠在所有場景下勝出。 比如 Impala 和 Presto 在併發場景下效能比較優越,Spark SQL 大表 Join 效能比較好。然而對於所有 SQL On Hadoop 而言,大表 Join 都比較慢。
在眾多的 SQL On Hadoop 系統中,有必要對其進行一個分類。一般而言,使用者更關心的是查詢時延,根據使用者提交查詢到結果返回的時間長短,將 SQL 查詢分為如下三類:batch SQL,interactive SQL,operation SQL, 如圖 1。
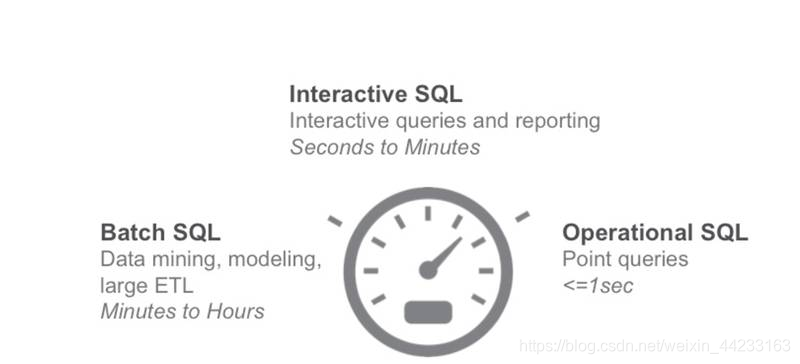
圖 1 SQL On Hadoop 分類, 摘自文獻 [14]
Batch SQL,Batch SQL 的查詢時間通常在分鐘,小時級別,一般用於複雜的 ETL 處理,資料探勘,高階分析。由於 Batch SQL 的查詢延時比較高,因此支援查詢內 (Intra-query) 容錯是該類系統必須具備的屬性,查詢內容錯是指,當節點宕機或者查詢內部某個 Task 失敗時,系統必須能夠重新提交該 task 而不是重新提交整個查詢來進行容錯。Batch SQL 中最典型的系統是 Hive。Spark SQL 也可以歸類到該系統。
Interactive SQL,Interactive SQL 也叫做互動式 SQL 查詢,使用者通常在同一個表上反覆的執行不同的查詢,Interactive SQL 的查詢時間通常在毫秒級或者秒級以內,一般不超過分鐘級別。由於該類系統主要追求低延遲,而不過分強調查詢內部容錯,所以當某個 task 失敗時,可以重新提交該查詢以便進行容錯,因為重新提交一個 SQL 查詢的執行時間通常很短。Interactive SQL 在實現上通常採用 MPP 架構,並且將熱點資料快取到記憶體中,比如 Presto,Impala,Drill,HAWQ。鑑於 Spark SQL 也具有非常高效的查詢速度,Spark SQL 也可以歸類到 Interactive SQL 中。
Operation SQL, 通常是單點查詢,延時要求小於 1 秒,該類系統主要是 HBase。
1.2 架構分類
1.2.1 MPP 架構
MPP 架構的優點是查詢速度快,通常在秒計甚至毫秒級以內就可以返回查詢結果,這也是為何很多強調低延遲的系統採用 MPP 架構的原因。
下面重點看下 MPP 架構的缺點,MPP 架構最主要的缺點是不支援細粒度的容錯,叢集節點數量很難擴充套件到 100 個以上,如果叢集出現落後節點,那麼將影響整個系統的查詢效能,此外不管 MPP 節點數量的多少,併發查詢的數量通常只能達到 20 個左右。
容錯,MPP 架構的容錯特點是粗粒度容錯,不能處理落後節點 (Straggler node)。粗粒度容錯是指,某個 task 執行失敗將導致整個查詢失敗,然後系統重新提交整個查詢來獲取結果。這種容錯方式只適用於 Iterative SQL 這種低延遲的工作負載,而不適合 Batch SQL 場景,因為 Batch SQL 查詢時間通常在分鐘小時級別,重新提價一個查詢代價太高。
落後節點,當一個節點執行速度慢於其他節點時,將導致整個系統的查詢效能下降。
擴充套件性:受落後節點的影響,MPP 架構很難擴充套件到 100 個節點以上。如果某個節點慢於其他節點,那麼整個系統的查詢效能將受限於這個最慢的節點,而與叢集節點數量無關。需要注意的是,在大型叢集中落後節點是普遍存在的,隨著叢集節點數量的增加,落後節點出現的概率也增加,[13] 針對磁碟故障概率的統計如下:

如果叢集包含 1000 個未使用一年的磁碟,那麼每年將有大約 20 磁碟出現故障,平均每兩週就會出現一個故障。當磁碟使用超過一年後,每年磁碟故障出現的概率將達到 8% 左右,平均每週將出現大約兩次故障。由於這個原因,MPP 架構很難擴充套件到 100 個節點以上,一般在 50 個節點左右。
併發,MPP 架構的併發查詢數量和叢集節點數量無關。MPP 是對稱結構,當執行一個查詢時,該查詢將被排程到叢集中的每一個節點執行,這意味著一個包含 4 個節點的 MPP 叢集和一個包含 400 個節點的 MPP 叢集所支援的併發查詢數量是相同的,也就是說,併發查詢數量和叢集節點數量無關,一般而言,當併發查詢個數達到 20 左右時,整個系統的吞吐已經達到滿負荷狀態。
綜上所述,MPP 架構不適合大規模部署,如果需要大規模部署,可以考慮 Spark Sql 這樣的系統。
1.2.2 非 MPP 架構
典型的非 MPP 架構有 Hive,Spark Sql。他們分別構建在 MR 和 Spark 之上,優點是叢集節點數量可以擴充套件到幾百甚至上千個,支援細粒度容錯。缺點是查詢速度可能不如 MPP 架構。
2. 執行引擎的設計
2.1. 優化器
目前 SQL On Hadoop 的查詢優化器主要有兩種:基於規則的 (Rule-Based Optimizer) 和基於代價的 (Cost-Based Optimizer CBO)。基於規則的優化器簡單,易於實現,通過內建的一組規則來決定如何執行查詢計劃,這裡不做介紹。
設計一個好的 CBO 優化器非常具有挑戰性,一個好的 CBO 依賴於詳細可靠的統計資訊,比如每個列的最大值,最小值,表大小,表分割槽資訊,桶資訊,然而在 SQL On Hadoop 中,通常缺乏可靠的統計結果,代價估計代數,這使得在 SQL On Hadoop 中引入 CBO 很困難。儘管如此,鑑於 CBO 在執行可以更加智慧的進行查詢優化,仍然有越來越多的 SQL On Hadoop 開始支援 CBO,比如 Hive,Spark SQL(計劃中)。
CBO 主要用來優化 shuffle,join,如何儘可能的避免 shuffle,提高 join 執行速度是 CBO 主要關注的問題,其中 Join 的實現方式和 Join 順序是重點考慮的。在 SQL On Hadoop 主要有四種 join 實現方式:shuffle hash join,broadcast join,Bucket join,cartesian join:
shuffle hash join,在 map 階段按照 join key 對兩個表執行 hash shuffle,這樣擁有相同 join key 的元組將 shuffle 到同一個節點,在 reduce 階段對錶進行 join。
broadcast join,當一個大表 join 一個小表時,並且小表可以完全放到記憶體中,此時可以將小表廣播到大表所在的每一個計算節點,然後執行 join。這種 join 方式叫做 broadcast join 或者 map join。Broadcast join 優點是避免了 shuffle,提高 join 效能。
Bucket join, 假設表 A 和表 B 使用 bucket 分割槽策略儲存,並且表 A 和表 B 的 bucket 個數為 n,此時可以按照如下方式 join:bucket 1 of A join bucet 1 of B,…,bucket n of A join bucket n of B。
Bucket join 優點是可以對兩個大表執行 join,並且不需要將資料放到記憶體中,在 Hive 和 Spark2.0 中都支援 Bucket join。
cartesian join,也叫做笛卡兒積 join,對兩個表執行笛卡兒積 join,結果集中元素的數量是兩個表大小的乘積。比如表 A 有 10 萬行,表 B 有 10 萬行,那麼笛卡兒積 join 之後的表大小將達到 100 萬條資料。因此除非到萬不得已,否則不會使用笛卡兒積 join。
表的 join 順序 (Join order) 主要有兩種:left-deep tree(下圖左),bushy tree(下圖右)。一個好的 CBO 應該能夠根據 SQL 語句的特點,來自動選擇使用 Left-deep tree 還是 bushy tree 執行 join。
Left-deep tree, 如果對 A,B,C,D 執行 join,那麼首先 A join B 得到一個臨時表 AB 並 AB 物化到磁碟,然後 AB join C 得到中間臨時表 ABC 並物化到磁碟,最後 ABC joinD 得到最終結果。可以發現,這種 join 順序非常簡單,缺點是隻能序列 join,並且由於產生了大量的中間臨時表,因此不太適合 OLAP 中的星型和雪花模型。
bushy tree, 採用 bushy tree 方式,可以並行執行 A join B 和 C joinD。然後將二者的結果 AB 和 CD 進行 join 得到最終結果。Bushy tree 優點是可以並行 join,並且能夠很好的處理星型模型和雪花模型。

圖 2left-deep tree 和 bushy tree, 摘自文獻 [16]
2.2. 查詢執行引擎
查詢執行引擎 (query execution engine) 是 SQL On Hadoop 的核心元件。查詢執行引擎的好壞對查詢效能的影響非常大。目前主要有兩種查詢執行:火山執行模型和向量化執行引擎。在後面的向量化執行引擎章節中有詳細的介紹。
3. 效能優化
從硬體資源角度將效能優化分為 3 個部分:
磁碟優化:資料本地化,減少中間結果的物化,資料壓縮,列儲存檔案,分割槽,塊級索引
CPU 優化:向量化執行引擎,動態程式碼生成,輕量級壓縮演算法,任務啟動優化
記憶體和 CPU 快取:記憶體壓縮列儲存,堆外儲存,快取敏感資料結構和演算法
3.1 資料本地化
SQL On Hadoop 設計的一個基本原則是:將計算任務移動到資料所在的節點而不是反過來。這主要出於網路優化的目的,因為資料分佈在不同的節點,如果移動資料那麼將會產生大量的低效的網路資料傳輸。資料本地化一般分為三種:節點區域性性 (Node Locality), 機架區域性性 (Rack Locality) 和全域性區域性性 (Global Locality)。節點區域性性是指將計算任務分配到資料所在的節點上,此時無需任何資料傳輸,效率最佳。機架區域性性是指將計算任務移動到資料所在的機架,雖然計算任務和資料分屬不同的計算節點,但是因為機架內部網路傳輸速度明顯高於機架間網路傳輸,所以機架區域性性也是一種不錯的方式。其他的情況屬於全域性區域性性,此時需要跨機架進行網路傳輸,會產生非常大的網路傳輸開銷。
排程系統在進行任務排程時,應該儘可能的保證節點區域性性,然後是機架區域性性,如果以上兩者都不能滿足,排程系統也會通過網路傳輸將資料移動到計算任務所在的節點,雖然效能相對低效,但也比資源空置比較好。
為了實現資料本地化排程,排程系統會結合延遲排程演算法來進行任務排程。核心思想是優先將計算任務排程到資料所在的節點 i,如果節點 i 沒有足夠的計算資源,那麼等待幾秒鐘後如果節點 i 依然沒有計算資源可用,那麼就放棄資料本地化將該計算任務排程到其他計算節點。
3.2 減少中間結果的物化
在一個追求低延遲的 SQL On Hadoop 系統中,儘可能的減少中間結果的磁碟物化可以極大的提高查詢效能。 如下圖,Hive 執行引擎採用 pull 獲取資料,其優點是可以進行細粒度的容錯,缺點是下游的 MapReduce 必須等待上游 MapReduce 完全將資料寫入到磁碟後才能開始 pull 資料。Presto 採用 push 方式獲取資料,資料完全以流的方式在不同 stage 之間進行傳輸,中間結果不需要物化到磁碟,從而使得 presto 具有非常高效的執行速度,缺點是不能支援細粒度的容錯。
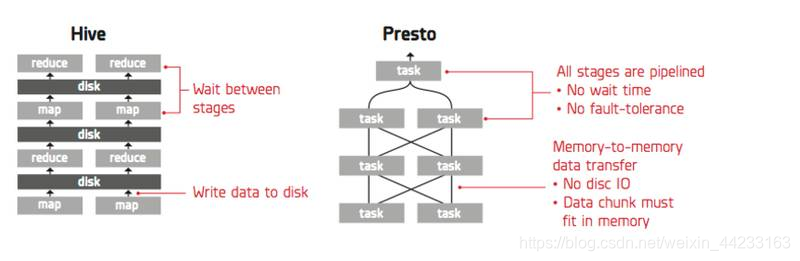
圖 3push 和 pull
3.3 列儲存
傳統的關係儲存模型將一個元組的列連續儲存,即使只查詢一個列,也需要將整個元組讀取出來,可以發現,當查詢只有少量列時,效能非常低。
列儲存的思想是將元組垂直劃分為列族集合,每一個列族獨立儲存,列族可以退化為只僅包含一個列的平凡列族。當查詢少量列時,列儲存模型可以極大的減少磁碟 IO 操作,提高查詢效能。當查詢的列跨越多個列族時,需要將儲存在不同列族中列資料拼接成原始資料,由於不同列族儲存在不同的 HDFS 節點上,導致大量的資料跨越網路傳輸,從而降低查詢效能。因此在實際使用列族時,通常根據業務查詢特點,將頻繁訪問的列放在一個列族中。
在傳統的資料庫領域中,人們已經對列儲存進行了非常深刻的研究,並且很多研究成果已經被應用到工業領域,其中包括輕量級壓縮演算法,直接操作壓縮資料,延遲物化,向量化執行引擎。可是縱觀目前 SQL On Hadoop 系統,這些技術的應用仍然遠遠的落後於傳統資料庫,在最近的一些 SQL On Hadoop 中已經添加了向量化執行引擎,輕量級壓縮演算法,但是諸如直接操作壓縮資料,延遲解壓等技術還沒有被應用到 SQL on Hadop 系統。關於列儲存的更多內容可以參見 [20]。
列儲存壓縮
列儲存壓縮演算法具有如下特點:
壓縮比 列儲存模型具有非常高的壓縮比,通常可以達到 10:1,而行儲存壓縮比通常只有 4:1。如圖 4:
圖 4 重量級壓縮演算法
輕量級壓縮演算法 (Leight-Weight Compression) 輕量級壓縮演算法是 CPU 友好的。行儲存模型只能使用 zip,lzo,snappy 等重量級壓縮演算法,這些演算法最大的缺點是壓縮和解壓縮速度比較慢,通常每秒只能解壓至多幾百兆資料。相反,列儲存模型不僅可以使用重量級壓縮演算法,還可以使用一些非常輕量級的壓縮演算法,比如 Run-length encode,Bit Vector。輕量級壓縮演算法不僅具有較好的壓縮比,而且還具有非常高的壓縮和解壓速度。目前在 ORC File 和 Parquet 儲存中,已經支援 Bit packing,Run-length enode,Dictionary encode 等輕量級壓縮演算法。
直接操作壓縮資料 (Operating Directly on Compressed Data) 當使用輕量級壓縮演算法時,可能無需解壓即可直接獲取計算結果。例如:Run Length Encode 演算法將連續重複的字元壓縮為字元個數和字元,比如 aaaaaabbccccaaaa 將被壓縮為 6a2b4c4a,其中 6a 表示有連續 6 個字元 a。現在假設一個某列包含上述壓縮的字串,當執行 select count(*) from table where columnA=’a’時,不需要解壓 6a2b4c4a,就能夠知道 a 的個數是 10。
需要注意的是,由於行儲存只能使用重量級壓縮演算法,所以直接操作壓縮資料不能被應用到行儲存。
延遲解壓 parquet 中的資料按塊儲存,每個塊儲存了最小值,最大值等輕量級索引,比如某個塊的最小值最大值分別是 100 和 120,這表明該塊中的任意一條資料都介於 100 到 120 之間,因此當我們執行 select column a from table where v>120 時,執行引擎可以跳過這個資料塊,而不必將其解壓再進行資料過濾。相反,在行儲存中,必須將資料塊完整的讀取到記憶體中,解壓,然後再進行資料過濾,導致不必要的磁碟讀取操作。
3.4 塊級索引
傳統資料庫使用索引來優化查詢效能,然而受限於 HDFS block 的放置策略,使用索引來優化 SQL On Hadoop 不是一件容易的事情。目前大部分 SQL On Hadoop 系統都不支援全域性索引,取而代之使用的是塊級索引,比如 Hive Index,ORC File,Parquet。塊級索引的思想是在每一個數據塊中新增一些諸如最大值,最小值的輕量級索引,當 SQL 引擎掃描 HDFS 檔案時,可以跳過不符合條件的 Block,從而減少磁碟 IO 提高查詢效能。如下圖,在 ORC File 中,每一個 Stripe 都包含一個 Index Data,Index Data 中儲存了列的最大值,最小值。當執行引擎執行 filter 這種查詢時,只需要讀取 Index Data 就行,如果符合條件就讀取 Row Data,否則可以直接跳過 Row Data 的讀取,從而減少磁碟 IO,提高查詢效能。
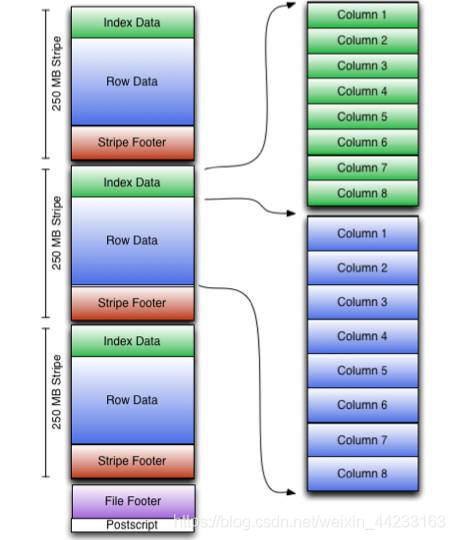
圖 3-3 ORC Storage
最大值,最小值這樣的統計索引主要用於優化範圍查詢效能,對於單點查詢通常可以使用布隆過濾器作為索引,布隆過濾器可以在資料量非常大的情況下快速的查詢資料。
3.5 分割槽
MPP 資料庫根據分割槽策略將一個表水平或者垂直切分為一個子表集合,不同的子表儲存在不同的節點,這樣可以並行的處理不同的子表。典型的分割槽策略有雜湊,範圍。
SQL On Hadoop 中也存在表分割槽的概念,一個表分割槽儲存在一個 HDFS 檔案目錄下,檔案目錄以列名 = 列值方式儲存。比如我們在 Hive 中執行如下 SQL:
CREATE TABLE test_table(id string,name int) PARTITION BY(ds string)。
當向 test_table 中插入如下元組時:
(id=‘10010’,name=‘sql on hadoop’,ds=‘2017-05-31’)
(id=‘10010’,name=‘sql on hadoop’,ds=‘2017-05-32’)
HDFS 中將建立如下目錄:
/user/hive/warehouse/test_table/ds=2017-05-31
/user/hive/warehouse/test_table/ds=2017-05-32
當執行 SELECT * FROM test_table WHERE ds=’2017-05-31’時,只需要掃描 ds=2017-05-31目錄即可,這樣可以跳過大量無關資料的掃描,從而加快資料查詢速度。
目前大部分 SQL On Hadoop 都支援分割槽功能,比如 Hive,Presto,Impala,Spark SQL。
3.6 壓縮
一般情況下,壓縮 HDFS 中的檔案可以極大的提高查詢效能。壓縮能夠減少資料所佔用的儲存空間,減少磁碟 IO 的讀寫,提高資料處理速度,此外,壓縮還能夠減少網路傳輸量,提高網路傳輸速度。在 SQL On Hadoop 中,壓縮主要應用在 HDFS 中的資料來源,shuffle 資料,最終計算結果。
如果應用程式是 io-bound 的,那麼壓縮資料可以提高資料處理速度,因為壓縮後的資料變小了,所以可以增加資料讀寫速度。需要主要的是,壓縮演算法並不是壓縮比越高越好,壓縮率越高的演算法壓縮和解壓縮速度就越慢,使用者需要在 cpu 和 io 之間取得一個良好的平衡。例如 gzip2 擁有非常高的壓縮比,但是其壓縮和解壓縮速度卻非常慢,甚至可能超過資料未壓縮時的讀寫時間,因此沒有 SQL On Hadooop 系統使用 gzip2 演算法,目前在 SQL On Hadoop 系統中比較流行的壓縮演算法主要有:Snappy,Lzo,Glib。
如果應用程式是 cpu-bound 的,那麼選擇一個可以 splittable 的壓縮演算法是很重要的,如果一個檔案是 splittabe 的,那麼這個檔案可以被切分為多個可以並行讀取的資料塊,這樣 MR 或者 Spark 在讀取檔案時,會為每一個數據塊分配一個 task 來讀取資料,從而提高資料查詢速度。
3.7 向量化執行引擎
查詢執行引擎 (query execution engine) 是資料庫中的一個核心元件,用於將查詢計劃轉換為物理計劃,並對其求值返回結果。查詢執行引擎對資料庫系統性能影響很大,目前主要的執行引擎有如下四類:Volcano-style,Block-oriented processing,Column-at-a-time,Vectored iterator model。下面分別介紹這四種執行引擎。
Volcano-style, 最早的查詢執行引擎是 Volcano-style execution engine(火山執行引擎,火山模型),也叫做迭代模型 (iterator model),或者 one-tuple-at-a-time。在這種模型中,查詢計劃是一個由 operator 組成的 tree 或者 DAG,其中每一個 operator 包含三個函式:open,next,close。Open 用於申請資源,比如分配記憶體,開啟檔案,close 用於釋放資源,next 方法遞迴的呼叫子 operator 的 next 方法生成一個元組。圖 1 描述了 select id,name,age from people where age >30 的火山模型的查詢計劃,該查詢計劃包含 User,Project,Select,Scan 四個 operator,每個 operator 的 next 方法遞迴呼叫子節點的 next,一直遞迴呼叫到葉子節點 Scan operato,Scan Operator 的 next 從檔案中返回一個元組。
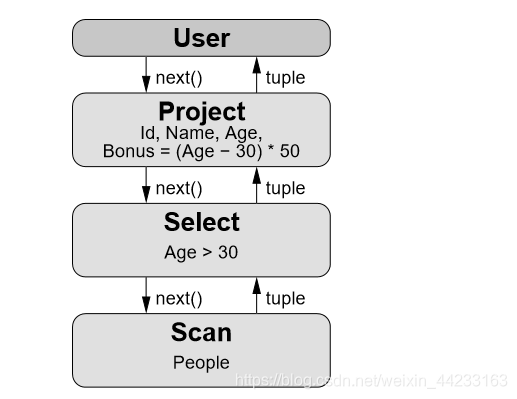
圖 3-4 火山模型 摘自文獻 [2,page 39]
火山模型的主要缺點是昂貴的解釋開銷 (interpretation overhead) 和低下的 CPU Cache 命中率。首先,火山模型的 next 方法通常實現為一個虛擬函式,在編譯器中,虛擬函式呼叫需要查詢虛擬函式表, 並且虛擬函式呼叫是一個非直接跳轉 (indirect jump), 會導致一次錯誤的 CPU 分支預測 (brance misprediction), 一次錯誤的分支預測需要十幾個週期的開銷。火山模型為了返回一個元組,需要呼叫多次 next 方法,導致昂貴的函式呼叫開銷。[] 研究表明,在採用火山執行模型的 MySQL 中執行 TPC-H Q1 查詢,僅有 10% 的時間用於真正的查詢計算,其餘的 90% 時間都浪費在解釋開銷 (interpretation overhead)。其次,next 方法一次只返回一個元組,元組通常採用行儲存,如圖 3-5 Row Format,如果順序訪問第一列 1,2,3,那麼每次訪問都將導致 CPU Cache 命中失敗 (假設該行不能完全放入 CPU Cache 中)。如果採用 Column Format,那麼只有在訪問第一個值時才出現快取命中失敗,後續訪問 2 和 3 時都將快取命中成功, 從而極大的提高查詢效能。

圖 3-6 行儲存和列儲存
Block-oriented processing,Block-oriented processing 模型是對火山模型的一個改進,該模型一次 next 呼叫返回一批元組, 元組個數在 100-1000 不等,next 內部使用一個迴圈來處理這批元組。在圖 1 的火山模型中,Select operator next 方法可以如下實現:
def next():Array[Tuple]={
// 呼叫子節點的 next 方法,返回一個元組向量,該向量包含 1024 個元組
val tuples=child.next()
val result=new ArrayBuffer[Tuple]
for(i=0;i30) result.append(tuples(i))
}
result// 返回結果
}
Block-oriented processing 模型的優點是一次 next 返回多個元組,減少了解釋開銷,同時也被證明增加了 CPU Cache 的命中率,當 CPU 訪問元組中的某個列時會將該元組載入到 CPU Cache(如果該元組大小小於 CPU Cache 快取行的大小), 訪問後繼的列將直接從 CPU Cache 中獲取,從而具有較高的 CPU Cache 命中率,然而如果之訪問一個列或者少數幾個列時 CPU 命中率仍然不理想。該模型最大的一個缺點是不能充分利用現代編譯器技術,比如在上面的迴圈中,很難使用 SIMD 指令處理資料。
Column-at-a-time 模型,向量化執行的最早歷史可以追朔到 MonetDB[], 在 MonetDB 提出了一個叫做 Column-at-a-time 的查詢執行模型,該模型中每一次 next 呼叫返回一個或者多個列,每個列以陣列形式返回。該模型優點是具有非常高的查詢效率,缺點是一個列資料需要被物化到記憶體甚至磁碟,導致很高的記憶體佔用和 io 開銷,同時資料不能放到 CPU Cache 中,導致較低的 CPU Cache 命中率。
Vectored iterator model,VectorWise 提出了 Vectored iterator model 模型,該模型是對 Column-at-a-time 的改進,next 呼叫不是返回完整的一個列,而是返回一個可以放到 CPU Cache 的向量。該模型避免了 Column-at-a-tim CPU Cache 命中率低的缺點。Vectored iterator model 最大的優點是可以使用執行時編譯器 (JIT) 動態的生成更適合現代處理器的指令,比如 JIT 可以生成 SIMD 指令來處理向量。考慮 TPC-H Q1 查詢:SELECT l_extprice*(1-l_discount)*(1+l_tax) FROM lineitem。該 SQL 查詢的執行計劃如下:
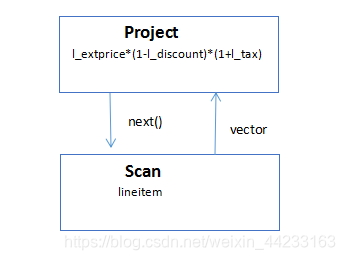
其中 Project operator 的 next 方法可以如下實現 (scala 虛擬碼):
def next():Array[Tuple]={
val tuples=child.next()
var result=new ArrayBuffer[Int]
for(i=0;i
近幾年,一些 SQL On Hadoop 系統引入了向量化執行引擎,比如 Hive,Impala,Presto,Spark 等,儘管其實現細節不同,但核心思想是一致的:儘可能的在一次 next 方法呼叫返回多條資料,然後使用動態程式碼生成技術來優化迴圈,表示式計算從而減少解釋開銷,提高 CPU Cache 命中率,減少分支預測。
Impala 中的向量化執行引擎本質上屬於 Block-oriented processing,imapla 的每次 next 呼叫返回一批元組,這種模型仍然具有較低的 CPU Cache 命中率,同時也很難使用 SIMD 等指令進行優化,為了緩解這個問題,Impala 使用動態程式碼生成技術,對於大迴圈,表示式計算等進行使用動態程式碼生成來進行優化。
在 Spark2.0 中,實現了基於 Parquet 的向量化執行引擎 [12],該執行引擎屬於 Vectored iterator model,引擎在呼叫 next 方法時以列儲存格式返回一批元組,可以使用迴圈來處理該批元組。此外為了更充分的利用現代 CPU 特性,Spark 還支援整階段程式碼生成技術,核心思想是將多個 operator 編譯到一個方法中,從而減少解釋開銷。
3.8 動態程式碼生成
動態程式碼生成一般和向量化執行引擎結合使用,因為向量執行引擎的 next 方法內部可以使用 for 迴圈來處理元組向量或者列向量,使用動態程式碼生成技術可以在執行時對 next 方法生成更高效的執行程式碼。研究證明向量化執行引擎和動態程式碼生成可以減少解釋開銷 (interpretation overhead), 見文獻 [18],主要影響以下三個方面:
Select, 當 select 語句中包含複雜的表示式計算時,比如 avg,sum,count,select 的計算效能主要受 CPU Cache 和 SIMD 指令影響。當資料不能放到 CPU Cache 時,CPU 大部分時間都在等待資料從記憶體載入到 CPU Cache,因此當 CPU 執行計算所需的資料在 CPU Cache 中時可以極大的提高計算效能。一條 SIMD 指令可以同時計算多個數據,因此使用 SIMD 指令執行表示式計算可以提高計算效能。
where,與 Select 語句不同的是 Where 語句一般不需要複雜的計算,影響 where 效能更多的是分支預測。如果 CPU 分支預測錯誤,那麼之前的 CPU 流水線將全被清洗,一次 CPU 分支預測錯誤可能至少浪費十幾個指令週期的開銷。通過使用動態程式碼生成技術,JIT 編譯器能夠自動的生成分支預測友好的指令。
Hash,hash 演算法影響 equal-join,group 的查詢效能,hash 演算法的 CPU Cache 命中率很低。[18] 描述了一種快取友好的 hash 演算法,可以顯著的提高 hash 計算效能。
動態程式碼生成有兩種:C++ 系和 java 系。其中 C++ 系可以直接生成本機可執行二進位制程式碼,並且能夠生成高效的 SIMD 指令,例如 Impala 使用 C++ 實現查詢執行引擎,同時使用 LLVM 編譯器動態的生成本機可執行二進位制程式碼,LLVM 可以生成 SIMD 指令對錶達式執行計算。Java 系利用反射機制動態的生成 java 位元組碼,一般而言,不能充分利用 SIMD 指令進行優化,Spark 使用反射機制動態的生成 java 位元組碼,通常很難直接利用 SIMD 進行表示式優化。此外在 Spark2.0 中所提供的整階段程式碼生成 (Whole-Stage Code Generation) 技術也是動態程式碼生成技術將多個 Operator 編譯成一個方法進行優化。
需要注意的是,動態程式碼生成技術並不總是萬能藥,在下圖中,impala 的動態程式碼生成技術並沒有提高 TPC-DS Q42,Q52,Q55 的查詢速度,主要原因這些 SQL 語句的 SELECT 語句中並沒有什麼複雜的計算。
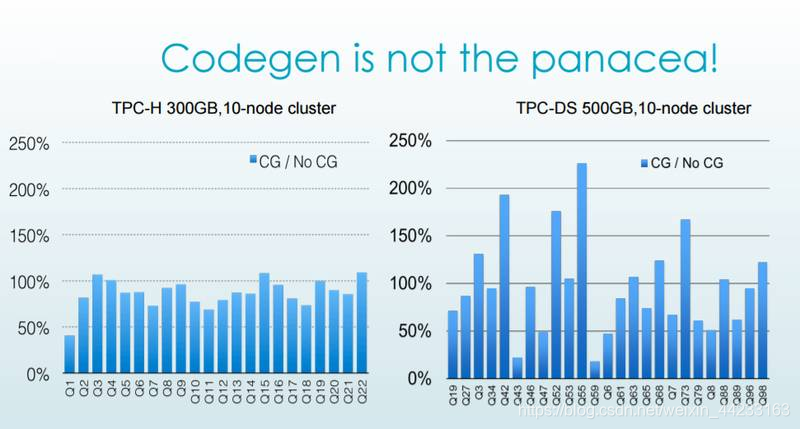
3.9 堆外儲存
使用 JVM 實現的查詢執行引擎依賴於 GC 回收記憶體,每一次 Full GC 會暫停所有工作執行緒,一次 GC 通常在分鐘級別以上,導致所有 SQL 查詢計算停止,從而嚴重的影響查詢效能並且可能會導致一些非常奇怪的異常出現,比如網路超時,shuffle 獲取資料資料失敗。為了減少 GC 對程式效能的影響,許多 SQL On Hadoop 使用堆外儲存 (off heap) 來儲存資料。
堆外儲存所需的記憶體由作業系統管理而不是 Java GC,java.nio 提供了一些用於讀寫堆外儲存的類,可以在堆外儲存中儲存 Int,Double 這種基元型別,也可以儲存 map,struct 這種複合物件,當儲存複合物件時需要將複合物件序列化儲存到堆外儲存,在讀取時也需進行反序列化。因為序列化 / 反序列化會消耗大量的 CPU 計算,因此在使用堆外儲存時需要在 GC 和 cpu 之間進行一個合理的平衡。
3.10 記憶體壓縮列儲存
在記憶體中快取熱點資料是提高查詢效能的一個基本優化手段。在記憶體中快取熱點資料需要考慮至少考慮三個問題: 第一,如何減少資料的記憶體佔用,第二,如何提高 CPU Cache 命中率,第三,如果使用 JVM 系統,還要考慮如何減少 GC 次數和 GC 時間。這裡需要重點關注的是如何提高 CPU Cache 的命中率。
這三個問題可以通過使用記憶體壓縮列儲存來解決:
減少記憶體佔用,在記憶體列儲存中,如果列元素型別是基元型別 (Int,Double,Long 等),那麼每一個列儲存為一個數組,如果列元素是 Map,Struct 這種負責物件,可以將其序列化為一個位元組資料進行儲存。陣列可以被壓縮儲存,需要注意的是,在選擇壓縮演算法時,一般不會選擇重量級壓縮演算法,雖然重量級壓縮演算法具有較高的壓縮率,但是它在壓縮和解壓縮時非常慢,這將嚴重的影響查詢效能。在記憶體壓縮列儲存中,輕量級壓縮演算法具有更高執行效率,這是因為輕量級壓縮演算法在進行壓縮和解壓時幾乎不需要太多的 CPU 計算。在 Spark SQL 的記憶體壓縮列儲存中 [10],使用的就是 Run length encode,dictionary encode 等輕量級壓縮演算法。
提高 CPU Cache 命中率,記憶體列儲存具有較好的 CPU Cache 命中率,因為列資料連續儲存,所以當 CPU 訪問陣列中某個元素時可以將該元素臨近的資料一起載入到 CPU Cache 快取行中,這樣 CPU 訪問該元素的下一個元素時就不需要訪問記憶體了,從而提高 CPU Cache 命中率,提高查詢計算效能。
減少 GC 時間,最後,記憶體列儲存對於 JVM 系統也是友好的。首先,JVM 中每個物件都包含一個物件頭,這個物件頭的開銷通常需要 12 個位元組,如果我們將 Int 按行儲存,那麼每個 Int 都將至少浪費 12 個位元組的儲存空間佔用。相反,如果將 Int 儲存為一個數組,那麼每個 Int 只需要 4 個位元組,可以減少 3 倍的儲存空間佔用。記憶體列儲存還可以減少 GC 時間,GC 時間主要和物件數量呈正相關,通過採用記憶體列儲存,每個列作為一個數組物件儲存,可以極大的減少物件數量,減少 GC 時間。
3.11 快取敏感演算法
自從 CPU Cache 出現以來,人們對於快取敏感演算法的研究就從未停止。所謂的快取敏感演算法,就是編寫 CPU Cache 命中率高的演算法。在這個領域已經有了大量的研究,比如磁碟索引 B-tree 的快取敏感實現,記憶體索引 T-tree 的快取敏感實現,連結串列,雜湊表等等。
快取敏感演算法通常比較複雜,並且不易理解,因此將所有演算法都設計成快取敏感的是不明智的,事實上大部分 SQL 計算主要為排序,聚合,join,只需對這些演算法進行優化即可。在 Spark SQL 實現了快取敏感的 Sort 演算法,該演算法應用在基於 sort 的 shuffle,排序和 join,優化後的 Sort 效能至少提高了 3 倍。
4. 其他
目前在 SQL On Hadoop 領域中存在種類繁雜的開源軟體,儘管其具體的實現細節和應用場景不同,但是仍然有一些共同的技術被廣泛採用:列儲存,向量化執行引擎,快取熱點資料,記憶體壓縮列儲存等。
由於設計決策,架構的不同,不同 SQL On Hadoop 仍然有許多不同的地方:
統一資源管理,一個支援統一資源排程的 SQL On Hadoop 系統非常具有研究價值,因為在一個大型複雜的分散式叢集中,不可能只有一種計算框架擁有資料,更多的是多種工作負載不同的計算框架同時部署在同一叢集,比如 Spark,MR,Hive,SparkSql,Impala,為了避免不同計算框架之間的資源競爭,需要使用統一的資源排程框架進行資源管理,使用統一資源管理可以避免計算框架申請過多的資源導致叢集,作業系統等出現不穩定狀態,Yarn 和 Mesos 是兩個最流行的開源資源管理框架。Impala,SparkSql 等都支援 Yarn 進行統一資源排程,presto 目前不支援 yarn。
容錯粒度,Impala,Presto,drill 這些採用 MPP 架構的系統不支援細粒度的容錯。Spark Sql,Hive 這些系統通過借鑑底層系統 MR 和 Spark 的容錯機制,也實現了細粒度的容錯。
JVM, 大部分 SQL On Hadoop 都採用 JVM 語言來實現,部分系統採用非 Jvm,比如 Impala 使用 C++ 實現查詢執行引擎。
最後,所有的 SQL On Hadoop 都應該儘可能的追求快速,易使用。查詢速度越快,就越能適應更多的場景。支援 ANSI SQL 而不是其他語言可以減少使用者學習曲線,避免使用者陷入到過多的語言特性中。
結語
為了幫助大家讓學習變得輕鬆、高效,給大家免費分享一大批資料,幫助大家在成為大資料工程師,乃至架構師的路上披荊斬棘。在這裡給大家推薦一個大資料學習交流圈:658558542 歡迎大家進群交流討論,學習交流,共同進步。
當真正開始學習的時候難免不知道從哪入手,導致效率低下影響繼續學習的信心。
但最重要的是不知道哪些技術需要重點掌握,學習時頻繁踩坑,最終浪費大量時間,所以有有效資源還是很有必要的。
最後祝福所有遇到瓶疾且不知道怎麼辦的大資料程式設計師們,祝福大家在往後的工作與面試中一切順利。