
千萬級別資料表建立索引
業務背景
最近一個開發維護的公眾號管理系統使用者表(user_info)資料已經達到15,000k了,而此時有一個業務場景需要將公眾號的使用者資訊重新同步一次,且後臺原有過針對單個公眾號的使用者同步,但是已經非常難以使用,因為同步時間太長了,以前的同步使用者方式大概流程如下:
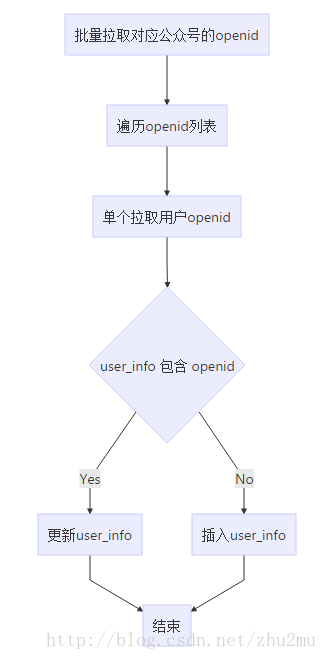
通過上面的流程可以看出來更新使用者流程過程非常耗時,每個使用者更新下來應該需要300ms左右,因為這涉及到每次更新一個使用者都需要呼叫一次微信介面,然後單個更新使用者資訊又分兩步a.查詢使用者是否存在、b.不存在則更新。其中user_info表已經針對openid建立了普通索引,查詢起來比較快。那麼一個30W粉絲的公眾號資料更新可能就需要14hour左右,這個時間是無法接受的。那麼應該如何來進行優化呢?很明顯可以這下面兩點開始:
1. 拉取微信使用者資訊使用批量介面,批量介面一次可以拉取100個使用者資訊;
2. 插入使用者資料使用批量插入、更新介面每次可以插入100條(這個數量如何確定的?其實只要資料庫插入的時間和拉取使用者資料差不多就可以了,沒必要一次插入幾千、幾萬條,因為介面資料如何沒有準備好的話該過程也是在等待)。
上面兩點可以優化效能,其中第一點沒什麼好說的呼叫公眾平臺的批量介面,第二代批量插入資料庫,而且要求:使用者存在時更新使用者資訊、使用者不存在時插入使用者資訊。
可以用下面語句滿足上面業務:
insert into tableName(id,name1,name12) values (a,b,c),(d,c,e) on DUPLICATE KEY UPDATE name1=values(name1),name2=values(name2)Mybaits寫法
<insert id="batchInsert">
insert into tableName(id 上面滿足業務需要的insert sql語句建立在資料有唯一索引的情況下,例如要限制插入使用者資訊不重複那麼需要針對openid來建立唯一索引才能滿足需求。這個時候問題就來了,如何修改千萬級別的資料表索引呢?而且該資料表還是一個業務活躍表。
伺服器效能
8核16G 300G SSD 雲主機 效能還過的去其他網絡卡什麼的不用考慮太多同機房應用伺服器這些不是效能瓶頸,主要是唯一索引過程需要排序要消耗不少CPU。
建索引前準備
這種千萬級別的==活躍==資料表肯定需要找專家一起評估一番才敢開始動手,於是第一步找有經驗的DBA同事一起協商下根據當前資料伺服器效能、資料量、業務請求等多方面評估修改索引的風險和影響。根據歷史經驗DBA給除了幾分鐘肯定不行的評估,讓我直接建。然後就是業務方面的評估,索引期間對業務的影響,因為索引過程中會導致資料伺服器效能變慢,因此我們決定找一個使用者不太活躍的時間段來開始。那麼接下來就是準備步驟了。整理大致步驟如下:
- 找出user_info表 openid重複的資料;
- 重複資料只保留一條;
- 刪除openid普通索引;
- 建立openid唯一索引。
開始執行
由於歷史遺留問題,實際操作步驟更為複雜:
1. create table user_info_duplicate like user_info; //建立臨時表用來備份重複資料
2. insert into user_info_duplicate select * from user_info group by openid having count(*) > 1;
3. SELECT openid from user_info_duplicate; //匯出重複的openid到檔案(用子查詢的方式刪除會特別慢)
4. 提供刪除openid的指令碼檔案提執行sql
5. 刪除openid為null的資料
DELETE from user_info where openid is null;
DELETE from user_info_duplicate where openid is null;
- drop INDEX
openid_indexon user_info; //刪除舊索引; - ALTER TABLE user_info ADD UNIQUE openid_u_index(openid); // 建立唯一索引;
8、insert ignore into user_info select * from user_info_duplicate; //把資料還原
總結
其中有幾個步驟需要特別說明下:
- 第一是重複資料部分之後要先建立唯一索引再還原資料否則怕在業務過程中被刪除的使用者更新了使用者表導致基於openid的唯一索引建立失敗;
- 另外需要關注的是第6和第7步應該更換一下位置,否則會導致業務非常緩慢,因為在很多業務依賴索引openid_index來執行時,突然索引被清除了那麼千萬基本的表肯定會有大量的查詢超時,導致業務異常,我們就是按照這個悲劇式的步驟執行的,果然最後悲劇了;
- 最後非同步還原資料的時候要用ignore關鍵字避免插入重複的資料,因為在建立索引過程中由於業務在執行可能會有與備份表相同的使用者進入業務系統更新使用者表(進入公眾號進行操作時會自動更新使用者資訊到資料庫)
最終資料庫索引建立過程花了大概 36min。效能不錯的虛擬機器花費了這麼長時間,這個過程中業務一直超時,還好執行時間段使用者比較少,影響不是特別大。真是一個不小的教訓。
Query OK, 0 rows affected (36 min 13.23 sec)
Records: 0 Duplicates: 0 Warnings: 0最後更新系統程式碼為批量更新,300,000K 使用者更新花費了大概 1hour,更新速度提升了10+倍。基本上面是每100呼叫戶花費1s更新。