
Coursera | Andrew Ng (02-week-1-1.10)—梯度消失與梯度爆炸
該系列僅在原課程基礎上部分知識點添加個人學習筆記,或相關推導補充等。如有錯誤,還請批評指教。在學習了 Andrew Ng 課程的基礎上,為了更方便的查閱複習,將其整理成文字。因本人一直在學習英語,所以該系列以英文為主,同時也建議讀者以英文為主,中文輔助,以便後期進階時,為學習相關領域的學術論文做鋪墊。- ZJ
轉載請註明作者和出處:ZJ 微信公眾號-「SelfImprovementLab」
1.10 vanishing/exploding gradients (梯度消失與梯度爆炸)
(字幕來源:網易雲課堂)
One of the problems of training neural network, especially very deep neural networks, is data vanishing/exploding gradients. What that means is that when you’re training a very deep network, your derivatives or your slopes can sometimes get either very very big or very very small, maybe even exponentially small, and this makes training difficult. In this video, you see what this problem of exploding or vanishing gradients really means, as well as how you can use careful choices of the random weight initialization to significantly reduce this problem.
訓練神經網路尤其是深度神經網路所面臨的一個問題是,梯度消失或梯度爆炸,也就是說 當你訓練深度網路時,導數或坡度有時會變得非常大,或非常小 甚至以指數方式變小, 這加大了訓練的難度,這節課 你將會瞭解梯度消失或爆炸問題的真正含義,以及如何更明智地選擇隨機初始化權重,從而避免這個問題。
Let’s say you’re training a very deep neural network like this, to save space on the slide, I’ve drawn it as if you have only two hidden units per layer, but it could be more as well. But this neural network will have parameters
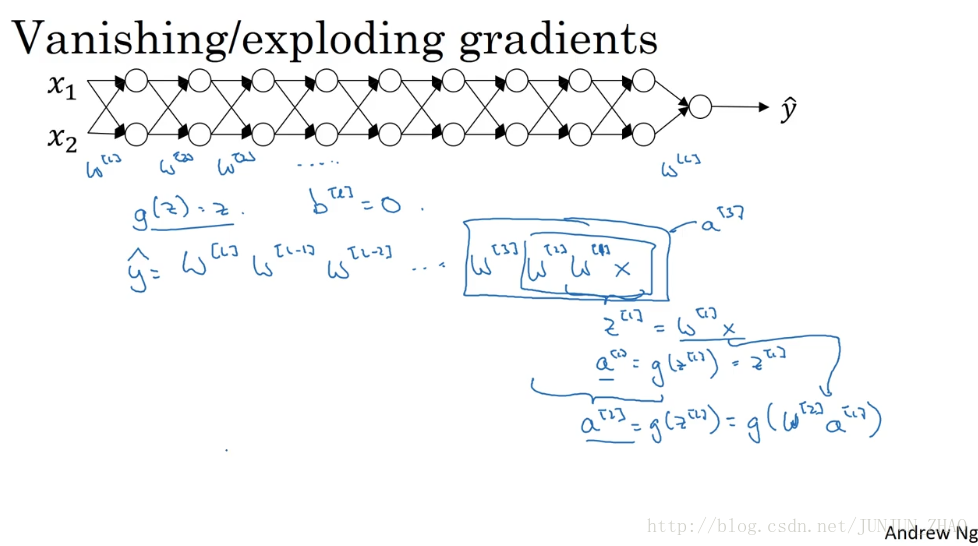
假設你正在訓練這樣一個極深的神經網路,為了節約幻燈片上的空間,我畫的神經網路每層只有兩個隱藏單元,但它可能含有更多,但這個神經網路會有引數
該系列僅在原課程基礎上部分知識點添加個人學習筆記,或相關推導補充等。如有錯誤,還請批評指教。在學習了 Andrew Ng 課程的基礎上,為了更方便的查閱複習,將其整理成文字。因本人一直在學習英語,所以該系列以英文為主,同時也建議讀者以英文為主,中文輔助,以便後期
該系列僅在原課程基礎上部分知識點添加個人學習筆記,或相關推導補充等。如有錯誤,還請批評指教。在學習了 Andrew Ng 課程的基礎上,為了更方便的查閱複習,將其整理成文字。因本人一直在學習英語,所以該系列以英文為主,同時也建議讀者以英文為主,中文輔助,以便後期
該系列僅在原課程基礎上部分知識點添加個人學習筆記,或相關推導補充等。如有錯誤,還請批評指教。在學習了 Andrew Ng 課程的基礎上,為了更方便的查閱複習,將其整理成文字。因本人一直在學習英語,所以該系列以英文為主,同時也建議讀者以英文為主,中文輔助,以便後期
該系列僅在原課程基礎上部分知識點添加個人學習筆記,或相關推導補充等。如有錯誤,還請批評指教。在學習了 Andrew Ng 課程的基礎上,為了更方便的查閱複習,將其整理成文字。因本人一直在學習英語,所以該系列以英文為主,同時也建議讀者以英文為主,中文輔助,以便後期
在吳恩達深度學習視訊以及大樹先生的部落格提煉筆記基礎上添加個人理解,原大樹先生部落格可檢視該連結地址大樹先生的部落格- ZJ
Optimization Algorithms
2.1 Mini-batch Gradient Descent (M 【1】大規模資料
【2】隨機梯度下降
【3】小批量梯度下降
【4】隨機梯度下降的收斂
Answer:BD
A 錯誤。學習率太小,演算法容易很慢
B 正確。學習率小,效果更好
C 錯誤。應該是確定閾值吧
D 正確。曲線不下降,說明學習率選的太大
【5】線上學習
Exercise 1:Linear Regression---實現一個線性迴歸
在本次練習中,需要實現一個單變數的線性迴歸。假設有一組歷史資料<城市人口,開店利潤>,現需要預測在哪個城市中開店利潤比較好?
歷史資料如下:第一列表示城市人口數,單位為萬人;第二 Lecture 10—Advice for applying machine learning
10.1 如何除錯一個機器學習演算法?
有多種方案:
1、獲得更多訓練資料;2、嘗試更少特徵;3、嘗試更多特徵;4、嘗試新增多項式特徵;5、減小 λ;6、增大 λ
為了避免一個方案一個方 【1】無監督演算法
【2】聚類
【3】代價函式
【4】
【5】K的選擇
【6】降維
Answer:本來是 n 維,降維之後變成 k 維(k ≤ n)
【7】
【8】
Answer: 斜率-1
【9】
Answer: x 是一個向
本系列文章是coursera上Andrew Ng的《Machine Learning》的測驗題,每次測驗都會有不同的錯,記錄下來,不定時的補充。錯的題目希望能幫我改正一下,我改錯的也希望大家能提出。
Lecture 11—Machine Learning System Design
11.1 垃圾郵件分類
本章中用一個實際例子: 垃圾郵件Spam的分類 來描述機器學習系統設計方法。首先來看兩封郵件,左邊是一封垃圾郵件Spam,右邊是一封非垃圾郵件Non-Spam:垃圾郵件有很多features。如果我 一、Coursera 斯坦福機器學習課程,Andrew Ng
Coursera連線不上,修改hosts檔案
機器學習工具Octave安裝(Win10環境)
課程地址和軟體下載
Lecture 12 支援向量機 Support Vector Machines
12.1 優化目標 Optimization Objective
支援向量機(Support Vector Machine) 是一個更加強大的演算法,廣泛應用於工業界和學術界。與邏輯迴歸和神經網路相比, SVM在學習複雜的非 Lecture 14 Dimensionality Reduction 降維
14.1 降維的動機一:資料壓縮 Data Compression
現在討論第二種無監督學習問題:降維。 降維的一方面作用是資料壓縮,允許我們使用較少的記憶體或磁碟空間,也加快演算法速度。
例子: 假設我們用兩個特徵描述一個物 Lecture 15 Anomaly Detection 異常檢測
15.1 異常檢測問題的動機 Problem Motivation
異常檢測(Anomaly detection)問題是機器學習演算法的一個常見應用。這種演算法雖然主要用於無監督學習問題,但從某些角度看,它又類似於一些監督學習問題。舉例: Lecture 16 Recommender Systems 推薦系統
16.1 問題形式化 Problem Formulation
在機器學習領域,對於一些問題存在一些演算法, 能試圖自動地替你學習到一組優良的特徵。通過推薦系統(recommender systems),將領略一小部分特徵學習的思想。 Lecture17 Large Scale Machine Learning大規模機器學習
17.1 大型資料集的學習 Learning With Large Datasets
如果有一個低方差的模型, 通常通過增加資料集的規模,可以獲得更好的結果。
但是如果資料集特別大,則首先應該檢查這麼大規模是否真 Lecture 18—Photo OCR 應用例項:圖片文字識別
18.1 問題描述和流程圖 Problem Description and Pipeline
影象文字識別需要如下步驟:
1.文字偵測(Text detection)——將圖片上的文字與其他環境物件分離開來2.字元切分(Character
隨機梯度下降
隨機梯度下降原理
小批量梯度下降
小批量梯度下降vs隨機梯度下降
隨機梯度下降的收
Definition
定義(1):
在不需要具體程式設計的情況下賦予計算機自我學習的能力。 - Arthur Samuel(1959)。例如: 程式的編寫者可能是某個領域的菜鳥,例如圍棋,但是通過機器學習,計算機獲得瞭如果才能贏得策略,成為了圍棋高手。
定義(2): 相關推薦
Coursera | Andrew Ng (02-week-1-1.10)—梯度消失與梯度爆炸
Coursera | Andrew Ng (02-week-1-1.5)—為什麼正則化可以減少過擬合?
Coursera | Andrew Ng (02-week-2-2.3)—指數加權平均
Coursera | Andrew Ng (01-week-1-1.3)—用神經網路進行監督學習
Coursera | Andrew Ng (02-week2)—改善深層神經網路:優化演算法
【原】Coursera—Andrew Ng機器學習—Week 10 習題—大規模機器學習
Stanford coursera Andrew Ng 機器學習課程程式設計作業(Exercise 1)Python3.x
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 10—Advice for applying machine learning
【原】Coursera—Andrew Ng機器學習—Week 8 習題—聚類 和 降維
機器學習之Coursera Andrew Ng 《Machine Learning》 week 6 test 2
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 11—Machine Learning System Design
【原】Coursera—Andrew Ng機器學習—彙總(課程筆記、測驗習題答案、程式設計作業原始碼)
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 12—Support Vector Machines 支援向量機
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 14—Dimensionality Reduction 降維
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 15—Anomaly Detection異常檢測
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 16—Recommender Systems 推薦系統
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 17—Large Scale Machine Learning 大規模機器學習
【原】Coursera—Andrew Ng機器學習—課程筆記 Lecture 18—Photo OCR 應用例項:圖片文字識別
Andrew Ng 機器學習筆記 15 :大資料集梯度下降
Week One - 1. Andrew Ng - 什麼是機器學習?