
計數排序及C語言實現
之前討論的插入排序、歸併排序、堆排序和快速排序都是基於比較的排序演算法,對於所有的比較排序演算法,其複雜度最優也要O(nlgn)。證明過程請參考演算法導論第八章第一節。
今天介紹一種非比較排序,名為計數排序。
基本思想是:對於每一個元素,確定小於該元素的個數,就可以將該元素排在正確的位置。該演算法能達到線性時間複雜度,也就是O(n)。
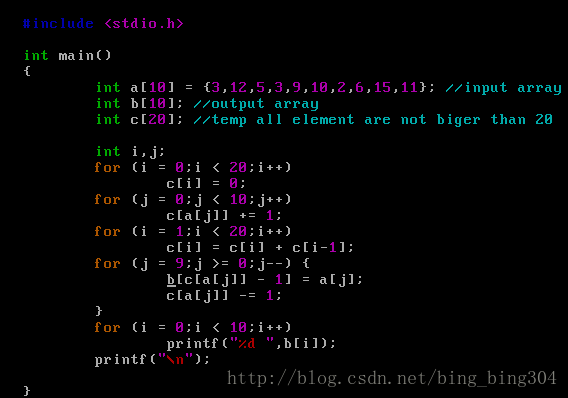
程式中,陣列a為輸入陣列(未排序陣列),b為輸出陣列,c為中間陣列。20的意思是假設陣列中每個元素均為小於20的非負整數。
相關推薦
計數排序及C語言實現
之前討論的插入排序、歸併排序、堆排序和快速排序都是基於比較的排序演算法,對於所有的比較排序演算法,其複雜度最優也要O(nlgn)。證明過程請參考演算法導論第八章第一節。 今天介紹一種非比較排序,名為計數排序。 基本思想是:對於每一個元素,確定小於該元素的個數,就可以將該
排序系列之(4)希爾排序及C語言實現
希爾排序(Shell Sort)也稱為遞減增量排序演算法,是插入排序的一種高速而安定的改良版。因希爾(Donald L. Shell)於1959年提出而得名。各種實現在如何進行遞減上有所不同。 希爾排序是基於插入排序的以下兩點性質而提出改進方法的: 插入排序在對幾乎已經排好序的資料操作時, 效率高, 即可以達
排序系列之(1)歸併排序及C語言實現
有很多演算法在結構上是遞迴的:為了解決一個給定的問題,演算法需要一次或多次遞迴的呼叫其本身來解決相關的問題。這些演算法通常採用分治策略:將原問題劃分成n個規模較小而結構與原問題相似的子問題;遞迴的解決這些子問題,然後將結果合併,就能得到原問題的解。 分治模式在遞迴時一般都有三
插入排序演算法及C語言實現
插入排序演算法是所有排序方法中最簡單的一種演算法,其主要的實現思想是將資料按照一定的順序一個一個的插入到有序的表中,最終得到的序列就是已經排序好的資料。 直接插入排序是插入排序演算法中的一種,採用的方法是:在新增新的記錄時,使用順序查詢的方式找到其要插入的位置,然後將新記錄插入。 很多初學者所說的插入排
快速排序演算法(QSort,快排)及C語言實現
上節介紹瞭如何使用起泡排序的思想對無序表中的記錄按照一定的規則進行排序,本節再介紹一種排序演算法——快速排序演算法(Quick Sort)。 C語言中自帶函式庫中就有快速排序——qsort函式 ,包含在 <stdlib.h> 標頭檔案中。 快速排序演算法是在起泡排序的基礎上進行改進的一種演算
希爾排序演算法(縮小增量排序)及C語言實現
希爾排序,又稱“縮小增量排序”,也是插入排序的一種,但是同前面幾種排序演算法比較來看,希爾排序在時間效率上有很大的改進。 在使用直接插入排序演算法時,如果表中的記錄只有個別的是無序的,多數保持有序,這種情況下演算法的效率也會比較高;除此之外,如果需要排序的記錄總量很少,該演算法的效率同樣會很高。希爾排序就是
九大排序演算法-C語言實現及詳解
概述 排序有內部排序和外部排序,內部排序是資料記錄在記憶體中進行排序,而外部排序是因排序的資料很大,一次不能容納全部的排序記錄,在排序過程中需要訪問外存。 我們這裡說說八大排序就是內部排序。 當n較大,則應採用時間複雜度為O(nlog2n)的排序方法:快
二叉排序樹(BST)的思路及C語言實現
請注意,為了能夠更好的理解二叉排序樹,我建議各位在看程式碼時能夠設定好斷點一步一步跟蹤函式的執行過程以及各個變數的變化情況 一.動態查詢所面臨的問題 在進行動態查詢操作時,如果我們是在一個無序的線性表中進行查詢,在插入時可以將其插入表尾,表長加1即可;刪除時
快速排序(分而治之策略及C語言實現)
提出的問題 分而治之的策略 重要的分而治之演算法 快速排序 問題 要在一個長為x,寬為y的長方形中畫出均勻且大小相等的正方形 那麼正方形的邊長為多少 (1)可以看出正方形的邊長需要是x和y的最大公約數 如何求最大公約數?
堆排序(C語言實現)
names 博客 鏈接 c語言實現 建立 ron 要求 clas [1] 之前的博客介紹介紹了數組的兩種排序算法:插入排序和歸並排序(採用遞歸),見鏈接http://blog.csdn.net/u013165521/article/detai
排序的C語言實現
emp 定義 als ret std 冒泡 urn merge 結點 #include <stdio.h> #include <string.h>#include <ctype.h> #include <stdlib
歸並排序(C語言實現)
ngs 基本 merge 兩個 它的 efi 分別是 void rec 合並排序(MERGE SORT)是又一類不同的排序方法,合並的含義就是將兩個或兩個以上的有序數據序列合並成一個新的有序數據序列,因此它又叫歸並算法。 它的基本思想就是假
數據結構8: 雙向鏈表(雙向循環鏈表)的建立及C語言實現
clas truct 開始 麻煩 使用 解釋 display 表頭 後繼 之前接觸到的鏈表都只有一個指針,指向直接後繼,整個鏈表只能單方向從表頭訪問到表尾,這種結構的鏈表統稱為 “單向鏈表”或“單鏈表”。 如果算法中需要頻繁
數據結構11: 棧(Stack)的概念和應用及C語言實現
next ret 額外 轉換 lib 順序存儲 順序棧 就是 函數 棧,線性表的一種特殊的存儲結構。與學習過的線性表的不同之處在於棧只能從表的固定一端對數據進行插入和刪除操作,另一端是封死的。 圖1 棧結構示意圖 由於棧只有一邊開口存取數據,稱開口的那一端
排序(C語言實現)
內部排序 利用 int 分治 arr 個數 size quic 外部排序 讀數據結構與算法分析 插入排序 核心:利用的是從位置0到位置P都是已排序的 所以從位置1開始排序,如果當前位置不對,則和前面元素反復交換重新排序 實現 void InsertionSort
順序表(線性表的順序儲存結構)及C語言實現
1.邏輯結構上呈線性分佈的資料元素在實際的物理儲存結構中也同樣相互之間緊挨著,這種儲存結構稱為線性表的順序儲存結構。 也就是說,邏輯上具有線性關係的資料按照前後的次序全部儲存在一整塊連續的記憶體空間中,之間不存在空隙,這樣的儲存結構稱為順序儲存結構。使用順序儲存結構儲存的資料,第一個元素所在的地
Canny邊緣檢測演算法原理及C語言實現詳解
Canny運算元是John Canny在1986年提出的,那年老大爺才28歲,該文章發表在PAMI頂級期刊上的(1986. A computational approach to edge detection. IEEE Transactions on Pattern Analy
氣泡排序,C語言實現
氣泡排序是一種穩定排序,時間複雜度平均為O(n^2),最好的時間複雜度為O(n),最壞為O(n^2)。 排序時每次只比較當前元素與後一個 元素的大小,如果當前元素大於後一個元素,則交換,如此迴圈直到隊尾,每輪排序都可以保證將當前排序下最大的元素送到未排序部分的隊尾。 有n個元素要排列,故要
冒泡排序,C語言實現
最大的 pri col src 當前 == int bubuko ngs 冒泡排序是一種穩定排序,時間復雜度平均為O(n^2),最好的時間復雜度為O(n),最壞為O(n^2)。 排序時每次只比較當前元素與後一個 元素的大小,如果當前元素大於後一個元素,則交換,如此循環直
插入排序,C語言實現
插入排序是穩定排序,時間複雜度最低為O(n),最高為O(n^2),平均為O(n^2)。 插入排序是將陣列分為兩部分,一部分已經排好序,另一部分未排好序,每次從未排好序的部分取第一個元素插入到已經排好序的部分正確的位置,如此迴圈n-1次。 就好像你手裡有十張牌,左手有一張,右手有九張。每次從