
python 中 set 和 dict 的實現原理
阿新 • • 發佈:2019-01-11
1. dict 和 list 查詢效能的比較
from random import randint def load_list_data(total_nums, target_nums): """ 從檔案中讀取資料,以list的方式返回 :param total_nums: 讀取的數量 :param target_nums: 需要查詢的資料的數量 """ all_data = [] target_data = [] file_name = "G:/慕課網課程/AdvancePython/fbobject_idnew.txt" with open(file_name, encoding="utf8", mode="r") as f_open: for count, line in enumerate(f_open): if count < total_nums: all_data.append(line) else: break for x in range(target_nums): random_index = randint(0, total_nums) if all_data[random_index] not in target_data: target_data.append(all_data[random_index]) if len(target_data) == target_nums: break return all_data, target_data def load_dict_data(total_nums, target_nums): """ 從檔案中讀取資料,以dict的方式返回 :param total_nums: 讀取的數量 :param target_nums: 需要查詢的資料的數量 """ all_data = {} target_data = [] file_name = "G:/慕課網課程/AdvancePython/fbobject_idnew.txt" with open(file_name, encoding="utf8", mode="r") as f_open: for count, line in enumerate(f_open): if count < total_nums: all_data[line] = 0 else: break all_data_list = list(all_data) for x in range(target_nums): random_index = randint(0, total_nums-1) if all_data_list[random_index] not in target_data: target_data.append(all_data_list[random_index]) if len(target_data) == target_nums: break return all_data, target_data def find_test(all_data, target_data): #測試執行時間 test_times = 100 total_times = 0 import time for i in range(test_times): find = 0 start_time = time.time() for data in target_data: if data in all_data: find += 1 last_time = time.time() - start_time total_times += last_time return total_times/test_times if __name__ == "__main__": all_data, target_data = load_list_data(10000, 1000) # all_data, target_data = load_list_data(100000, 1000) # all_data, target_data = load_list_data(1000000, 1000) # all_data, target_data = load_dict_data(10000, 1000) # all_data, target_data = load_dict_data(100000, 1000) # all_data, target_data = load_dict_data(1000000, 1000) last_time = find_test(all_data, target_data) print(last_time)
由上可以得出結論:
(1)dict的查詢效能遠遠大於list
(2) 在list中,隨著list資料亮的增大,查詢的時間也會增大; 在 dict中,查詢元素的時間不會隨著資料量的增大而增大,其時間複雜度為O(1)
2. 為什麼 dict的查詢效能會遠遠的大於 list呢?
是因為dict 中的 key 和set 中的元素值都是 可hash的。
以dict為例,原理如下所示:
dict中建立的hash表如下:

圖1
hash表的查詢:
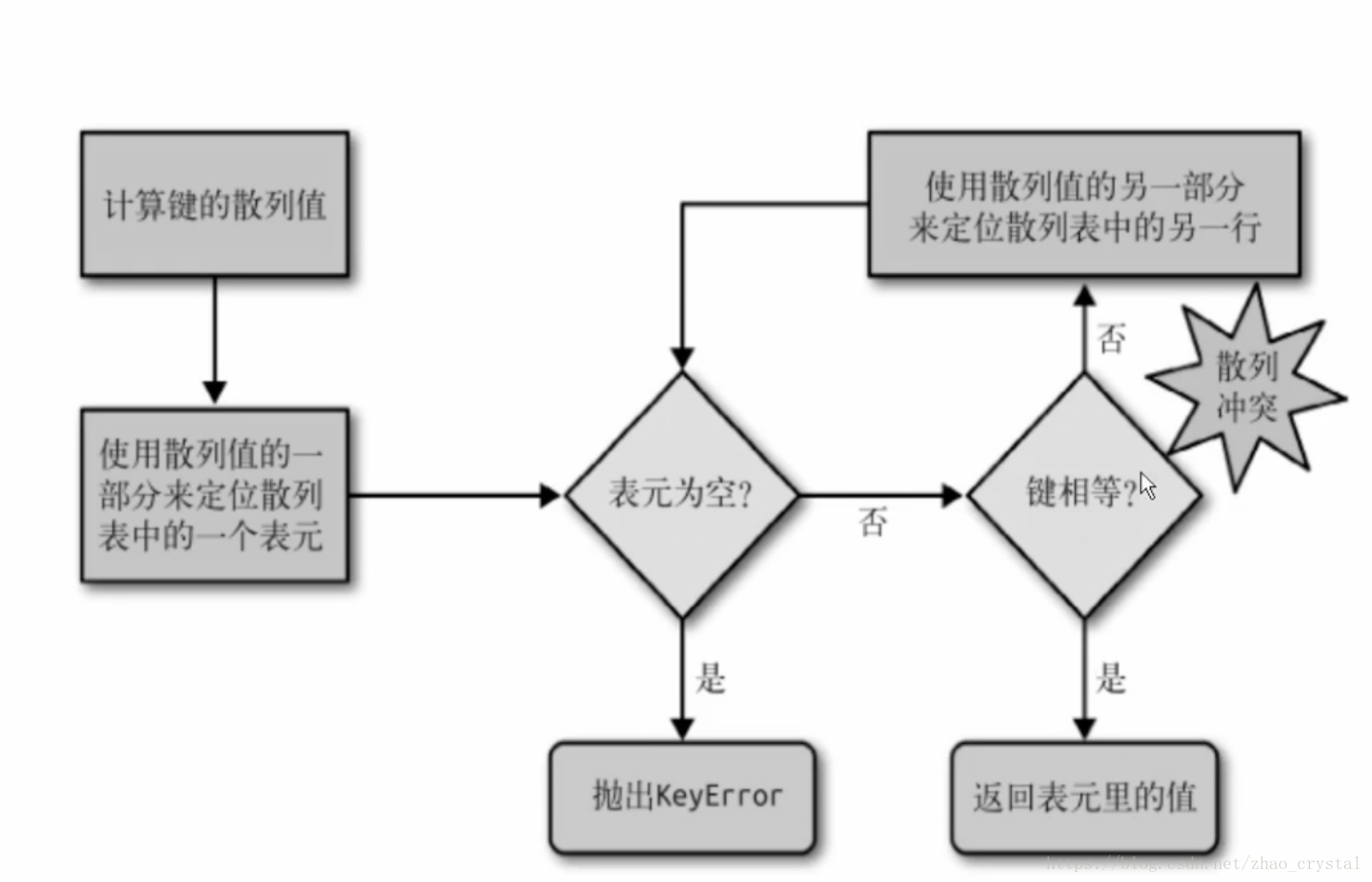
圖2
故:
(1) dict的key 或者 set的值都必須是可hash的
不可變物件,都是可hash的,str,fronzenset, tuple, 自己實現的類(帶有__hash__魔法函式)
(2) dict的記憶體花銷大(hash簡單的來說即對映,如圖1所示,對映之後,不可能是連續的存在記憶體空間中的,總有一些記憶體時空的,當發現記憶體空間中的“空”只有1/3時,便會觸發擴容操作,以免引起hash衝突),但是查詢速度快。自定義的物件,或者python內部的物件都是dict包裝的。
(3)dict的儲存順序和元素的新增順序有關
(4)新增的資料有可能改變已有的資料順序(擴容時,需要將原來的dict,複製移動到新的記憶體空間,此時將“擠出”已有的“空”,所以每個key的偏移可能改變)