
【置頂】面試知識點
專案經歷
0 機器學習的原理 參考
就比如說性別分類吧,機器學習通過訓練資料的特徵(比如人的身高體重)和資料的輸出變數(如人的性別)來訓練一個分類或者回歸模型,用這個模型來預測新的資料。
梯度下降和線性迴歸!!!前者是優化方法(用於nn中後向傳播的引數更新)後者是分類方法,用於前向傳播得到輸出值
0 迴歸和分類的區別 參考
迴歸常用來預測一個連續值比如說預測今天我被lamda錄取的概率,分類常用來預測一個離散值比如說貼標籤。
0 什麼是線性迴歸
在我看來,線性迴歸相當於一種擬合,他們是建構函式模型來擬合樣本資料,在擬合的過程中 他會考慮樣本的方差和偏差 。
0 什麼是邏輯迴歸
邏輯迴歸有點像像線性迴歸,不過他們倆有區別:
1邏輯迴歸是非線性的
2 邏輯迴歸相當於對線性迴歸的值域壓縮到01之間
啟用函式可以使輸出值與輸入值變得非線性(不使用啟用函式的話深度神經網路實際上和多層感知機就沒區別了,全是線性組合)這裡寫連結內容,可微且單調(當優化方法是基於梯度的時候這個性質就是必須的),同時啟用函式還能控制輸出值範圍,使得基於梯度的優化方法變得更穩定
0 sigmoid 和softmax區別 這裡寫連結內容
sigmoid將一個一維實值對映到01區間中的一個實值(tanh是-1 1 區間)
softmax將一個k維實值向量對映到01區間的另一個實值向量
0 講一下邏輯迴歸(sigmoid)的定義函式(損失函式,梯度下降)參考 參考2必看ng
0 詳細講一下softmax的定義函式(損失函式,雅可比矩陣)
0 你在兩篇論文中扮演的角色
第一篇論文是第四作者,那時我剛進入實驗室,只參與了一些資料預處理和論文修訂工作,並沒有參與核心模型設計。
第二篇論文是第三作者,這一階段我和組內一位博士生(論文的第一作者,第二作者為導師)一起合作研究,由他指導大方向,我來負責實驗復現,程式碼編寫。論文中的創新點(多級注意力機制)是我們一起討論得出的。可以說第二篇論文我是全程參與的。
實際上multi-level attention那篇之前三月試投了coling,但是很多細節都沒打磨好(比如一些使用不同語料的對比實驗)。coling三個審稿人的意見分別是(2,3,4)(滿分是5分),很遺憾最終還是沒能用回覆改變2分那位審稿人的意見,但是我覺得過程才是重要的,這段經歷也讓我覺得我更適合科研而不是工作,同時我也發現了平臺的重要性,大工的nlp實力確實不強,如果我確定走學術路線,必須去爭取進入一個更高層次的平臺。
凸優化的使用條件: 1 目標函式是凸函式(也就是任意兩點連線上的值大於對應自變數處的函式值) 2
變數所屬集合是凸集合(也就是任意兩個元素連線上的點也在集合中)
凸優化問題中區域性最優解就等於全域性最優解,凸優化應用到機器學習領域主要是用來調整和更新引數
- CNN部分
1.1 一般訓練模型的資料集分為哪幾種
一般訓練模型分三個資料集,訓練集用來訓練模型,更新權重。驗證集用來評估模型的效能,看有沒有欠擬合或者過擬合。測試集是我們最後要預測的資料集,一般來說是沒有標籤的。
1.2 對深度學習的理解(CNN卷積,池化)
那我就講講我對CNN和RNN的理解吧,首先CNN他有兩個最重要的操作:卷積和池化參考
cnn卷積相當於一種壓縮資訊的實值對映,在影象處理中,他是利用畫素點和周圍畫素的資訊與卷積核做內積,用求和後的新值表示這個視窗區域的特徵值;在自然語言處理中,是用一個單詞和他的線性上下文組成的視窗與卷積核內積然後求和,最終得到一個句子的特徵向量。
cnn池化相當於在卷積的基礎上進一步壓縮資訊,使得特徵向量更小,更易於處理,常用的有平均池化和最大池化,就是用視窗內的最大值或者平均值代替整個視窗。
1.2.1cnn的區域性感知和引數共享
cnn的區域性感知是指濾波器根據視窗進行卷積
cnn的引數共享是指視窗權重不變
1.2.2cnn的優點和侷限性(和lstm相比,為什麼第二篇不用cnn)
優點: 卷積視窗可以實現同時用過去和未來的資訊判斷當前的資訊
侷限性: 首先,cnn的卷積視窗不可能太大而且他還是固定的,這樣的話在文字的長距離依賴關係中明顯不如lstm
2.3 講講最熟悉的演算法
簡單的梯度下降梯度更新
手寫Logistic迴歸
2.5 線性迴歸對於資料的假設是怎樣的 參考
1就是因變數y是多個自變數x之間的線性組合。
2 資料樣本點之間獨立同分布(也就是隨機變數服從同一分佈且相互獨立)
3 樣本點沒有測量誤差(實際上這是不可能實現的,但是實際中會假設滿足這個條件來降低模型複雜度)
2.6 說說你的論文 並行多池化CNN 生物醫學事件觸發詞的識別吧
這篇論文是第四作者,當時剛加入實驗室,所以只是做了一些資料預處理和跑跑實驗的工作,但是我對論文的模型還是有了解的。
首先論文做的觸發詞識別是事件抽取的一個子任務,生物醫學事件呢主要由觸發詞和要素組成的,觸發詞一般是動詞或者動名詞,他是觸發這個事件的詞,比如說“蛋白質降低了血液流動性”那這裡降低就是一個生物醫學事件的觸發詞,這個事件波及的物件,也就是血液這個詞就是要素,要素也可以看成是觸發詞和實體之間的一種複雜關係。
我們提出的觸發詞識別的模型的主要特點一個是並行,一個是多池化。
1 首先在輸入層,我們用Gdep和Word2vecf得到了基於依存關係的詞向量,然後用這個詞向量拼接距離向量來表示一個單詞,這裡的距離向量呢代表了這個單詞到句子中的觸發詞的距離,你像剛才的降低他的距離就是0因為他是觸發詞。
2 然後在卷積層,我們用了不同大小的卷積視窗來獲得句子的特徵向量,不同視窗的卷積是並行的。
3 在池化層呢我們把特徵向量一分為二,,分的原則是觸發詞前的特徵表示和觸發詞後的特徵表示,然後對這個一分為二的特徵向量分別進行池化,相當於一個特徵向量得到兩個池化值。這裡不同視窗得到的特徵向量也是並行多池化處理的,最後的結果會被連線在一起送入softmax分類器。
為什麼多池化?
因為一個句子裡可能有多個生物醫學事件,如果僅僅對整個句子求max值,顯然會丟失資訊,而觸發詞作為事件的觸發因素,以他作分界是合理的
使用的什麼優化方法?
adadelta,好處是不用設定學習率,自適應學習
- LSTM部分
Rnn呢實際上相當於一種較深層次的神經網路,他是對神經網路展開多個step,每個step會共享同一個神經網路模組,正是由於這種顯著的序列性質,rnn在處理自然語言問題的時候有很大的優勢。但是,她也有一個明顯的缺點:一旦序列過長,可能會引發梯度消失的問題,也就是說(畫圖)反向傳播過程中鏈式法則的連乘操作會導致梯度越來越小。為了解決這個問題,才有了LSTM,lstm呢有個顯著的特徵,就是他引入了cell狀態和門這兩個概念,cell狀態由兩部分組成:一個是過去的資訊,一個是當前的資訊,兩個資訊相加得到cell當前時刻的狀態。由於是相加的形式,cell僅僅通過遺忘門決定記憶多少過去的資訊,從而解決了長期依賴的問題,同時各個門的輸出實際上都是上一時刻cell狀態的複合函式,這樣反向求導的時候,連乘的沒一項變成了連加,就緩解了梯度的消失,當然了,lstm是不能完全解決梯度小時問題的,因為他只是將每一步的求導變成求和,但是鏈式法則的連乘依然是存在的。
在lstm的基礎上也出現了一些變體,比如我們論文中用到的雙向lstm,他呢就是對一個句子正向和反向各自處理一遍,這樣的話相當於正向過程中利用了過去的也就是前文中的資訊,而反向過程中則可以利用未來的也就是後文中的資訊來決斷當前的資訊。
2.4 梯度下降法是什麼(lamda詹德川)
2.5 牛頓迭代是什麼(lamda詹德川)
2.6 說一下神經網路的優缺點(復旦)
就拿我接觸過的lstm吧,它本質上是一種RNN,有很多變種,RNN優缺點,LSTM的改進等等
2.7 實習幹了什麼,怎麼做的,以及複述了一個用於關係抽取的網路模型(對論文專案進行講解)
使用BLSTM做的模型(注意那個圖)
對資料的處理
畫網路模型圖,從輸入層到輸出層,隱層,dropout ,用的什麼優化函式
2.8 LSTM之父
Jürgen Schmidhuber 尤爾根 施密德胡波
2.9 Attention之父
Attention機制最早是在視覺影象領域提出來的,應該是在九幾年思想就提出來了,但是真正火起來應該算是google mind團隊的這篇論文《Recurrent Models of Visual Attention》[14],他們在RNN模型上使用了attention機制來進行影象分類。隨後,Bahdanau等人在論文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用類似attention的機制在機器翻譯任務上將翻譯和對齊同時進行,他們的工作算是是第一個提出attention機制應用到NLP領域中。
https://blog.csdn.net/yimingsilence/article/details/79208092
https://blog.csdn.net/sparkexpert/article/details/72785304
attention看起來很高階,實際上他的思想非常簡潔,它主要是受到人腦的注意力模型的啟發,因為人在觀察眼前的事物的時候,只會聚焦到一小部分畫面而對其他部分選擇性忽視,就比如說攝影吧,為什麼單反拍出來的照片比手機拍的更抓人眼球?就是因為單反虛化好,這裡虛化就相當於刻意模糊掉畫面裡次要內容和背景,突出主體(比如說睡覺的小貓咪啊什麼的),這就是一種現實中的attention,那麼注意力機制應用到文字領域,其實相當於一種文字聚焦模型,基本思想是對文字分配不同的注意力,使得不同的內容對整個文字的貢獻各不相同,句子的主幹單詞會被分配更多的注意力。比如說我們在第二篇論文中使用的一種多級注意力機制,
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
attention是受到人腦注意力模型的啟發,可以看作是一種資源分配模型,在某個特定時刻,人的注意力總是集中在畫面中的某個焦點部分,而對其他部分視而不見。attention應用到文字領域有一個很大的好處,就是他可以針對長文字選擇性地關注那些比較重要的單詞,比如說“我特別想進入lamda深造”,那麼加了注意力機制的神經網路在理解這句話的時候就可能會對“我lamda深造”三個詞增加權重,這樣的話就相當於抽取了一個句子的主幹資訊。
最基本的attention是應用在機器翻譯的Encoder-Decoder模型,沒有引入attention的模型中句子裡每個單詞對於翻譯目標單詞的貢獻都是一樣的,引入attention之後,會更多地關注對句子含義貢獻大的單詞。
2.10 手寫一下你用的attention公式
Attention-Based Bidirectional Long Short-Term Memory Networks for
Relation Classification(這篇論文的註釋版再看一遍)
先是tanh啟用隱層狀態
然後softmax獲得att矩陣
然後隱層輸出與att矩陣點乘
最後結果tanh啟用
配套https://blog.csdn.net/appleml/article/details/78043041
2.11 你論文的motivation是什麼
篇章中不僅句內單詞有聯絡,句子之間也是有聯絡的
2.12 實驗細節
如果測試集的正確率比訓練集高很多,可能會出現哪些問題參考
1 訓練集上過擬合
可以考慮:1.1 人工減少特徵維度
1.2 dropout 保持輸入輸出神經元不變,在前向和後向傳播過程中隨機刪除一些隱藏單元,達到正則化的效果(原因是:減少的隱層單元實際上增加了網路的稀疏性,從而減少了不同特徵之間的關聯性,因為過擬合他其實根本原因就是特徵維度太多了,有些特徵之間就會存在很多特定的關聯性)
1.3 正則化; 保留所有的特徵,通過降低引數θ的值,來影響模型
1.3 引入隨機噪音來避免過擬合
2 訓練集樣本不均勻 比如負例過多,考慮去負例,保持10:1
如果訓練集的正確率一直上不去,可能會出現哪些問題 參考
1 訓練集欠擬合,特徵維度過少,導致擬合的函式無法滿足訓練集,誤差較大。
考慮增加特徵維度來解決。
怎麼實現的
訓練集測試集是如何組成的
損失函式用的什麼
用的語料包括那些
2.12.1 說說你的multi-level attention based BLSTM nn for event extraction
這篇論文我是第三作者,我和組裡的一位博士生(也就是一作)一起做出的這篇論文,我的主要工作呢是模型搭建和多級注意力的實現。首先,生物醫學事件抽取呢分了三個子任務,分別是觸發詞識別,要素識別和後處理構成事件,這三個過程是序列的,也就是先找出觸發詞,再找出要素,最後就用觸發詞和要素構成事件。
我們在觸發詞識別和要素識別中用了同樣的神經網路模型,我們這個模型最主要額特點是 雙詞向量機制和多級注意力機制:
首先,在輸入層,我們使用了兩套詞向量作為cell的兩個輸入,其中一套是基於依存關係訓練得到的詞向量,另一套是隨機初始化後跟隨網路訓練更新,前一個可以看作包含普遍特徵資訊,後一個可以看作包含了task-specific的資訊。
然後在網路層,我們使用了雙向lstm,正向的話可以更好地利用過去的資訊,反向的話可以更好地利用未來的資訊。
然後對於隱層輸出,我們使用了多級注意力機制,首先word-level att是對句子裡的每個單詞分配注意力,然後求得句子的特徵向量,之後sentence-level att再對不同的句子向量分配注意力,新的句子表示最後被送到softmax分類器中進行分類。
2.13 遇到過什麼問題,怎麼解決的?
剛開始準備使用attention的時候,嘗試了很多中方法,比如說,曾經嘗試過一種固定的attention,就是隻給句子中的觸發詞和要素各分配0.5的權重,其他部分權重為0,也試過以觸發詞為中心,按照正態分佈給上下文分配attention,他們效果都不太理想,最後還是選定了self-attention,他相當於一個可學的隨機向量,可以跟隨網路訓練而自己調整權重
2.14 論文最自豪的點(你這個是以句子為單位的,那你這個第二級注意力是怎麼個attention法)
多級注意力機制,,我們這個第二級注意力機制呢,主要是為了同一個batch裡(要素候選都是並行處理的嘛),區分出哪些可能是
3.相關
3.1對人工智慧的看法 (南大)
雖然人工智慧現在是weak
AI,但是在很多領域的應用都已經獲得了非常好的經濟和社會效益,比如醫療診斷,自動駕駛等等。也許在十年前,我們根本無法想象會有一臺叫AlphaGo的機器能在圍棋這樣一個象徵人類智慧的專案中擊敗最頂尖的人類的,這一切,都要感謝人工智慧。因此,我認為人工智慧是真正的未來。當然,現階段AI還遠未達到強人工智慧的水平,因此,我們現在要做的就是捉緊時間研究人工智慧,掌握人工智慧,就好比那些在手刨地時代掌握了農具的人一樣,將會獲得巨大的競爭優勢。
3.2machine learning現階段的問題 (上交)
我從來沒有想過這個問題,也承認自己自學的時候有點兒死,沒有站在整個領域的角度去看過,只重視一些演算法
3.3你最近看了什麼論文?發表在什麼期刊上?作者是誰?(上交)
3.4 統計某市的下水井蓋個數(北大軟微,類似的還有估算出租車數量) 參考
一般雨水管道檢查井是30m一個,汙水井間距大一點。瞭解城市規模與路網密度的關係,知道了城市的大概面積,可以算出道路的長度,然後可以推算出井蓋的總數。
3.5 機器學習瞭解多少,看過什麼(lamda吳建鑫)(優點,侷限性)
目前我做的都是深度學習方向的研究,沒有怎麼系統地看教學視訊,都是遇到什麼問題解決什麼問題這樣在實踐中學習,比如早期接觸神經網路,對xx感覺沒掌握要領,就看了西瓜書以及一些blog。。。。。(這裡xx可以是貝葉斯或者什麼機器學習演算法的推導,然後老師可能會順著這個問你怎麼推導貝葉斯,你就能順著往坑裡跳了,記得一定精心準備幾個西瓜書的推導
3.6 了不瞭解本人是做什麼研究的(lamda吳建鑫)
導師主頁一定要看
3.7 看成績單,問如何進行文獻檢索(南大)
選修課也很重要啊,先看看自己選過哪些再重點複習相關的。參考
如果知道文章標題啊,DOI啊(Digital Object Unique
Identifier,即數字物件唯一識別符號,通俗一點來講,DOI就是一篇文獻的身份證),作者名和期卷號啊直接上谷歌學術搜就行,如果剛入門的話,早期得先搜一下關鍵詞,然後從結果裡找一些引用高的文獻讀一下(當然越近越好,老古董讀起來不太容易理解),如果對某篇文獻感興趣,接著搜一下那篇論文的通訊作者,一般來說都會是個大牛。實際上讀完這幾篇高引用論文之後,很有可能會發現他們的參考文獻中有很多重疊的,那些論文也是必讀的。實際上如果僅僅為了入門瞭解的話,還有個簡單方法,搜一下相關綜述,可以說非常全的介紹了,我早起就是看的review(笑)。後期深入之後,肯定要跟蹤前沿動態,這時候就搜一下之前找到的那些大牛近幾年的publication,或則乾脆直接關注他們的谷歌學術賬戶,跟蹤他們的進展
3.8 大學什麼科目學的比較好(哈工大)
想想挖坑
3.8 做過的專案涉及到的演算法有什麼(哈工大),寫過哪些大的程式設計專案?
課程設計算嗎,課程設計的話寫過小型編譯器,我主要負責的是遞迴下降語法分析
美賽用過主成分分析和BP神經網路等,實驗用過lstm
3.9 邏輯迴歸和線性迴歸的區別是什麼(軟體所)
參考
我認為邏輯迴歸有點像是對線性迴歸做了一個值域壓縮,將y 的閾值從y∈(+∞,−∞)壓縮到(0,1),也就是說兩個問題本質上都是一致的,就是模型的擬合(匹配)。 但是分類問題的y值(也稱為label), 更離散化一些. 而且, 同一個y值可能對應著一大批的x, 這些x是具有一定範圍的。
3.10 有沒有聯絡過其他老師?
聯絡過復旦的邱錫鵬老師,當時邱老師讓我讀他的一篇論文,讓我做review,那篇論文是關於多工學習的,那我就講講我做review的思路吧,我一般讀論文,先是看摘要,然後通讀一遍論文,因為我之前沒接觸過這個東西,所以從他的參考文獻中又多讀了幾篇引用的論文,發現他這個模型實際上是在他自己前幾篇論文的基礎上做的進一步改進,我就綜合他的這幾篇論文中提出的模型的演化歷史寫了review。
3.11 你認為他的論文的主要創新點是什麼(也可以說你最近讀過什麼論文,順勢回答這篇,注意瞭解一下GAN)
GAN+lstm內部結構微調
3.12 如果實現一個功能有兩種方法,第一種是不一定能做出來,比較陌生,需要佔用挺多時間的方法,第二種是比較熟悉,但是隻能實現所有功能的百分之八十,那你會選擇哪種方法?
3.12
一個舞會,頭上有白帽子和黑帽子,而且所有人中至少有一頂黑帽子。每個人都能看見除自己之外的所有帽子顏色。如果有人發現自己的帽子是黑的,就在關燈的時候鼓掌。第一次,大家互相看其他人帽子顏色。關燈之後沒人鼓掌。第二次,關燈之後還是沒人鼓掌。第三次關燈的時候響起了掌聲。問場上有多少頂黑帽子?
第一次沒有人鼓掌,說明至少兩頂帽子,否則只有一定的話那個人看到的其他人都是白帽子,那他自己肯定就知道了自己是黑的。
第二次沒人鼓掌,說明至少有三頂帽子,這時候已經知道至少兩頂了,假設真的只有兩頂的話,每個黑人看到的都應該是一定黑貓,他們肯定就知道自己和另外一個人是黑人
第三次鼓掌 說明就是三頂帽子,也就是每個黑人看到的都是兩頂黑帽子
4 美賽
4.1 美賽用了什麼
pca主成分分析,pca的原理
bp神經網路 ,bp神經網路的原理
專業課
- C/C++
1.1 請用英語說一下面向物件和麵向過程的區別 參考(南大)
“面向過程”是一種是事件為中心的程式設計思想。就是分析出解決問題所需的步驟,然後用函式把這寫步驟實現,並按順序呼叫。
”面向物件“是以**“物件”為中心的程式設計思想。
簡單的舉個例子(面試中注意舉例):汽車發動、汽車到站。汽車啟動是一個事件,汽車到站是另一個事件,面向過程程式設計的過程中我們關心的是事件,而不是汽車本身。針對上述兩個事件,形成兩個函式,之後依次呼叫。對於面向物件來說,我們關心的是汽車這類物件,兩個事件只是這類物件所具有的行為。而且對於這兩個行為的順序沒有強制要求。
面向過程的思維方式是分析綜合**,面向物件的思維方式是構造。
“Process-oriented” is an event-centric programming idea. Is to analyze the steps required to solve the problem, and then use the function to achieve this write step, and call in order.
“Object-oriented” is an object-centered programming idea.
A simple example: cars start, cars arrive. The car startup is an event, and the car arrival is another event. In the course of process-oriented programming, we care about the event, not the car itself. For the above two events, two functions are formed and then called one after another. For object orientation, we are concerned with objects such as cars. Two events are just the behavior of such objects. And there is no requirement for the order of these two behaviors.
The process-oriented way of thinking is analysis and synthesis, and the object-oriented way of thinking is construction.
1.2 malloc函式申請一個二維陣列(CUHK)參考1 參考2
//一維陣列
char * p=(char *)malloc(sizeof(char)*列數);
free(p);
//二維陣列 使用二級指標
char **p;
p =(char**)malloc(行數*sizeof(char*));
for(int i=0;i<列數;i++)
{
p[i]=(char *)malloc(列數*sizeof(char));
}
for(int i=0;i<列數;i++) free(p[i]);
free(p);
//二維陣列 使用指向陣列的指標
char (*p)[行數]=(char(*)[行數])malloc(sizeof(char)*行數*列數);
free(p);
1.3給你一個數組,設計一個既高效又公平的方法隨機打亂這個陣列(此題和洗牌演算法的思想一致)
為了保證公平,每個數只能被選中和移動一次,那麼我可以每次隨機選一個數移動到最後的位置,然後遞迴移動前n-1個數
1.4各類變數的記憶體分配 參考
char 1 位元組 short 2位元組 int 4位元組 long 4位元組 long long 8位元組float 4位元組 double 8位元組
記憶體分配順序:首先將全域性變數和靜態本地變數分配在靜態儲存區,然後將宣告的區域性變數分配在棧區作用域結束後系統自動收回,最後將動態申請的空間分配在堆區,由程式設計師手動釋放。
1.4.1 全域性,靜態,區域性的區別
全域性和區域性的區別主要在生存週期和作用域
靜態主要是相對自動變數而言,他倆的主要區別是儲存位置和初始化,前者存在靜態儲存區且只初始化一次
1.5 多型和繼承 參考
繼承:新類從已有類那裡得到已有的特性,比如說交通工具這個類中有屬性速度,那麼汽車這個新類就可以從交通工具中繼承這個屬性
多型:一個介面,多種方法,在子類中重寫父類的虛擬函式,當用父類指標呼叫這個虛擬函式的時候實際上呼叫的是重寫後的函式
- 資料結構與常用演算法
2.1 用O(n)複雜度找到一組數中出現次數最多的數字和這組數的中位數 (CUHK)參考1
設數A出現次數超過一半。每次刪除兩個不同的數,在剩餘的數中,數A出現的次數仍超過一半。通過重複這個過程,求出最後的結果(複雜度呢??)
2.1.2 找出一個數組中出現次數超過一半的數(北大軟微) 參考
基本思路見連結
2.2“棧”的實現(用陣列和連結串列怎麼實現)(上科大)參考
先談談棧的最重要特點:先入後出,其次他包含兩種必要操作:入棧頂和棧頂出棧
陣列實現的思想很簡單。利用一個變數count來記錄棧頂下標,通過改變棧下標值來模擬出入棧。
連結串列實現依靠表頭指標作為棧頂指標,採用頭插法插入和刪除操作。
2.3矩陣相乘的時間複雜度 (上科大)參考
如果用樸素的演算法,mxn的矩陣和nxk的矩陣相乘的運算量是O(mnk),原因是,計算結果是一個mk矩陣,這說明至少需要進行mk次運算,而每次運算還要進行n次的求和運算(左邊的每一行*右邊的每一列)
當然,如果用平行計算的話,比如python裡的tensor.dot函式替代for迴圈,時間複雜度會大大降低
2.4什麼是NP難問題(浙大)
2.5 逆波蘭(南大)
2.6 快排複雜度是多少,並且黑板上手寫證明。(lamda俞楊,其他的排序複雜度也要會)參考
快排可以看作一種遞迴樹他的的時間複雜度是O(nlogn),證明主要從以下三點
1
當遞迴樹趨於平衡時也就是快排的最好情況,複雜度與樹高有關,經過子問題劃分為複雜度相等的兩個子序列,由不等式推斷可得O(nlogn)
2
當遞迴樹極端不平衡(如原有資料就是正序或者逆序的),每次劃分後只得到一個序列(另一個序列為空),由不等式推斷得O(n^2)
3
平均情況下設樞軸的關鍵字應該在第k的位置(1≤k≤n),那麼(具體見演算法筆記裡夾得紙)

2.7 簡述如何“快速選到第n個數”(快速選擇,複雜度為O(n))(lamda俞楊)參考
當資料量少,可以直接裝進陣列的話,可以採用類似快排的思想,每一步都是把大於某值的數放在一邊,小於某值的放在另一邊,如果大數區間容量大於n,就在大數區間繼續劃分直到大數區間容量為n,否則在小數區間劃分,直到小數區間的大數區容量為n-k;時間複雜度為O(n)
類似的還有快速選到最大的n個數//快速選到中位數(也就是第n/2大的數)
當資料量太多不能用陣列儲存,就建一個小頂堆,新元素比堆頂大就插入,當插入次數為n堆頂就是所求。建堆O(m),插入O(logm),假設一共m個數,則O(m+n*logm)
2.7 解釋一下什麼是時間複雜度(南大)參考
時間複雜度實際上以一種度量,並不是真正意義上的演算法執行時間,相當於給你一把尺子去量一下這個演算法的耗時他主要是為了描述,時間複雜度的關注點是演算法中基本操作的重複次數,根據這個次數來估計演算法耗時。同時為了簡化問題,時間複雜度只考慮了最高項的階數,因為問題規模足夠大時其他項的貢獻可以忽略。
2.8 B樹是什麼?主要作用是什麼? (哈工大)
B樹是一種平衡的多叉樹,它最初啟發於二叉查詢樹,因為二叉查詢樹呢有個缺點,就是資料一多,他的深度就比較高,而你每查詢一次節點就相當於訪問一次磁碟,這樣的話就會降低速度,B樹的根本思想就是在一個節點上存更多的索引資訊,也就是改二叉為多叉,減少查詢時的io操作.
- 作業系統(重要)
3.1什麼是虛擬記憶體(上科大)
3.2 作業系統執行緒跟程序的區別 (lamda) 參考
1 執行緒可以看作是一個輕量級的程序,兩者的主要區別是:執行緒是CPU排程和分派的基本單位,而程序是系統資源分配的基本單位。
2 引入執行緒的目的是為了提高系統的併發性,這是因為,同一程序內的不同執行緒切換不會引起程序切換,從而避免系統呼叫,減少了系統開銷。
3 程序和執行緒的關係有個很好的例子:比如把咱們面試過程看成一個程序,那麼老師要做的是提出問題,我要做的是聽問題,思考問題,如果僅僅有程序,那麼這三件事必須一件件完成,也就是老師在提出問題時,我不能同時進行思考,執行緒就是為了解決這個問題,程序中的每個事件分配一個執行緒,這些執行緒可以併發執行,從而提高。
- 資料庫
4.1幾個正規化是什麼(浙大) 參考
1NF: 欄位是最小的的單元不可再分
2NF:滿足1NF,表中的欄位必須完全依賴於全部主鍵而非部分主鍵 (一般我們都會做到)
3NF:滿足2NF,非主鍵外的所有欄位必須互不依賴
4NF:滿足3NF,消除表中的多值依賴
4.2 關係模式和關係
你可以理解為資料表。“關係模式”和“關係”的區別,類似於面向物件程式設計中”類“與”物件“的區別。”關係“是”關係模式“的一個例項,你可以把”關係”理解為一張帶資料的表,而“關係模式”是這張資料表的表結構
4.3資料庫增刪改查
- 計算機網路
- 計算機組成原理
- 編譯原理
7.1 做過什麼大型的程式碼專案?
寫過小型編譯器,我主要做詞法分析和遞迴下降語法分析
7.1.1 遞迴下降語法分析和lr分析的區別
8.軟體工程
8.1 軟體錯誤怎麼找啊 參考
軟體錯誤有好多種,而且在整個軟體開發週期中可能會擴散,不過一般來說邊界值是最容易出錯的,其次還可以通過追蹤一條資料的完整流程來判斷錯誤,還不行那就隨機測試了(笑,靠天吃飯
8.2 軟體測試的內容 參考
軟體測試主要有兩點:一個是驗證verification,一個是確認validation
驗證的話就是說你軟體是不是正確地實現了這個功能,也就是do it right
確認的話就是說你軟體實現的這個功能是不是正確的,也就是do the right thing
8.3軟體包括那些
軟體的話不僅僅包括程式,還應該有相應的文件
簡單點說就是 程式+文件
9 開放性問題
9.1 證明一個有m個元素的數列a(全是整數),讓你證明存在i<=j使得(ai+…+aj) mod m = 0.
反證法,假設不存在,那麼任意一個數mod m都不等於零,ai mod m 只能有m-1種可能(也就是ai只能有m-1種可能),ai +ai-1 mod m也不會等於零,則ai-1 只能由m-2種(因為ai有m-1種而ai-1 mod m也不能等於0相當於又減少了一種) 依次類推,a1只能有零種,矛盾
數學課
- 線性代數(重要)
1.0 什麼是行列式 參考
行列式是一個函式,它可以將方陣(注意只有方陣才有行列式)對映到一個實值,他等於矩陣特徵值的乘積,也就是說,他的大小可以衡量矩陣變換後空間擴大或者縮小的情況。比如:如果行列式為0那麼說明空間至少沿著某一維完全收縮了,使其失去了所有體積,行列式為1則說明矩陣變換沒有改變空間體積
1.0.1 矩陣轉置 矩陣的逆
以對角線為軸的映象,手面朝向自己表示原矩陣,先翻過手背,再逆時針旋轉90°得到矩陣轉置
方陣A和方陣A的逆
1.0.2矩陣乘積和點乘
矩陣乘法AB是A(mn)的行向量與B(nm)的列向量的每一項對應相乘後求和,A的列數必須和B的行數保持一致
點乘可以用矩陣乘法表示 A點乘B = ATB
1.0.3 正交矩陣
矩陣的轉置和矩陣的乘積=單位陣,那麼這個矩陣就是正交矩陣,他的列向量組一定是標準正交向量組
1.1 特徵值、特徵向量的求法、意義(上科大) 參考
物理意義:首先,矩陣可以看作是一種線性變換也可以看做一種空間影象,那麼矩陣乘法就可以看作是一種影象在方向和長度上的變換,我們說某個矩陣的特徵向量可以看做一種特徵影象,這種特殊影象經過這個矩陣所定義的運動變換之後得到的新影象相比原來的特徵影象只發生了伸縮變化而沒有發生旋轉變換,伸縮的比例呢就是他的特徵值。
求法:通過一個等式來求特徵值 |蘭姆達E - A|=0 求出特徵值之後通過等式 蘭姆達x = A x求出對應的特徵向量x
1.1.2 特徵分解 參考
矩陣分解為由其特徵值和特徵向量表示的矩陣之積的方法
如果矩陣的特徵值全都不同,那麼他的所有特徵向量都是線性無關且正交的,那麼矩陣A就可以被對角化,這個過程就是特徵分解 A=VΛV−1 其中 V=[x1,x2,⋯,xn]V=[x1,x2,⋯,xn] , Λ=Diag(λ1,λ2,⋯,λn)Λ=Diag(λ1,λ2,⋯,λn) 。
PCA的本質就是協方差矩陣的對角化nono 奇異值分解
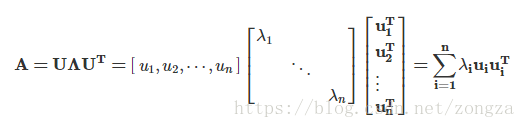
1.1.3 什麼是矩陣的對角化
按照我的理解,矩陣對角化實際上就是一個特徵分解的過程,如果一個方陣的特徵值全都不相同,那麼這個方陣就能相似於由特徵值組成的對角矩陣,他們之間的相似變換矩陣p和p-1就是由特徵向量組成的
奇異值分解有點像特徵分解的推廣版本,因為特徵分解只是針對方陣的嘛,非方陣想進行矩陣分解的話就可以通過奇異值代替
1.2 矩陣的秩(上科大) 參考
物理意義: 之前說過了,矩陣可以看做是一種影象也可以看作是一種線性變換,那麼按照我的理解,一個矩陣的秩相當於別的影象經過這個矩陣定義的線性變換後得到的影象的空間維度
1 比如說變換矩陣【【0,0】【0,0】】無論什麼樣的影象,進過這種變換之後都被壓縮成一個點,所以這個矩陣的秩就是0
2 再比如說變換矩陣【【1,-1】【1,-1】】他的兩個列向量是在一條直線上的,因此無論什麼影象,經過變換後都會被壓縮成一條直線,那麼這個矩陣的秩就是1
3 再比如變換矩陣【【1,-1】【1,1】【1,2】】他的兩個列向量在三維空間中確定了一個平面,其它影象經過這種變換後的影象一定屬於這個平面,因此他的秩是2
1.3 什麼是線性相關(lamda)什麼是線性表示 參考1 參考2
線性相關是判斷一組向量是否可以通過適當的線性組合表示成一個零向量. 線性組合中至少有一個非零因子
線性表示是判斷一組向量是否可以通過適當的線性組合表示另外一個向量. 線性組合中可以全是零
OR
線性相關是判斷一組向量中任意一個向量都不能表示成其他向量的線性組合
1.4 什麼是正則化
正則的本質是對要優化的引數進行約束,在機器學習中這個引數就是一種特徵,通過限制這個特徵的數量級來避免過擬合。
- 高等數學
2.0 零點存在定理
函式在a-b的閉區間連續 ,且f(a)*f(b)<0那麼開區間(a,b)之間一定存在零點 ξ
2.0 函式連續的定義
函式連續有三個條件,一個是在該點有定義,一個是在該點有極限,並且這個極限的值等於該點的函式值
2.1 你說你數學比較好,那說一下函式零點怎麼求
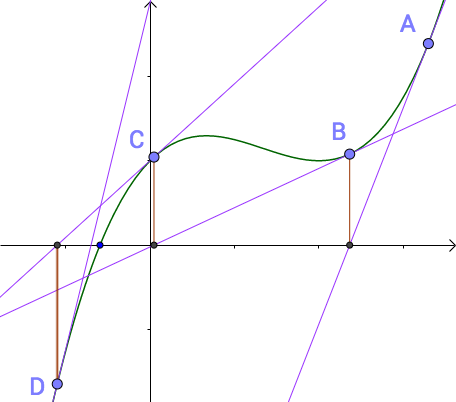
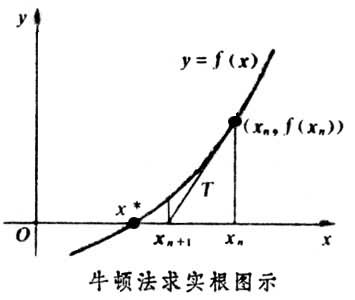
當時只說了個二分法,其實牛頓迭代,遺傳演算法(這個沒看懂)都可以啊
牛頓迭代:他的原理是用泰勒公式的一階展開這條直線近似模擬曲線,然後不斷地迭代更新這條直線,一直更新到用於模擬的那條直線的根收斂於實際曲線的根 參考 參考
遺傳演算法:沒看懂
2.1.2 函式極值點怎麼求(也就是導數為0的點,也就是最優化問題)
求函式極值可以看作是求導數為0的點,因此可以用牛頓二階迭代來求零點,他原理是利用泰勒公式的二階展開,求展開後的零點,然後不斷地更新迭代。一般來說牛頓法比梯度下降更快,因為後者是一階收斂,前者二階收斂,二階相當於考慮了梯度的梯度,也就是說,牛頓法在判斷那個方向梯度最大的同時還會考慮走了這個方向之後梯度是否會變得更大,因此更好地利用了全域性資訊,所以相對更快 參考1 參考
參考
梯度下降:每次選梯度反方向走一步(也就是下降最快的方向),這個方法有個缺點就是,步長如果太長,可能會在最優值附近徘徊,步長太小,前進就太慢 參考
梯度下降:梯度下降就是上面的推導,要留意,在梯度下降中,對於θ的更新,所有的樣本都有貢獻,也就是參與調整θ.其計算得到的是一個標準梯度。因而理論上來說一次更新的幅度是比較大的。如果樣本不多的情況下,當然是這樣收斂的速度會更快啦~
隨機梯度下降:可以看到多了隨機兩個字,隨機也就是說用樣本中的一個例子來近似所有的樣本,來調整θ,因而隨機梯度下降是會帶來一定的問題,因為計算得到的並不是準確的一個梯度,容易陷入到區域性最優解中
批量梯度下降:其實批量的梯度下降就是一種折中的方法,他用了一些小樣本來近似全部的,其本質就是隨機指定一個例子替代樣本不太準,那我用個30個50個樣本那比隨機的要準不少了吧,而且批量的話還是非常可以反映樣本的一個分佈情況的。
2.1.3手寫logistics迴歸和梯度下降公式
2.1.4為什麼優化時選擇梯度方向,梯度方向為什麼是變化最快的方向?
因為梯度方向下降最快,為什麼最快呢,因為你把函式進行泰勒展開,f(x0+dx) =f(x0)+f ‘ (x0)dx +。。。,那麼f(x0+dx)-f(x0)約等於f ‘ (x0)dx 當dx=f ‘ (x0)時兩者差值最大,類似的多元函式中的dx就是他的梯度
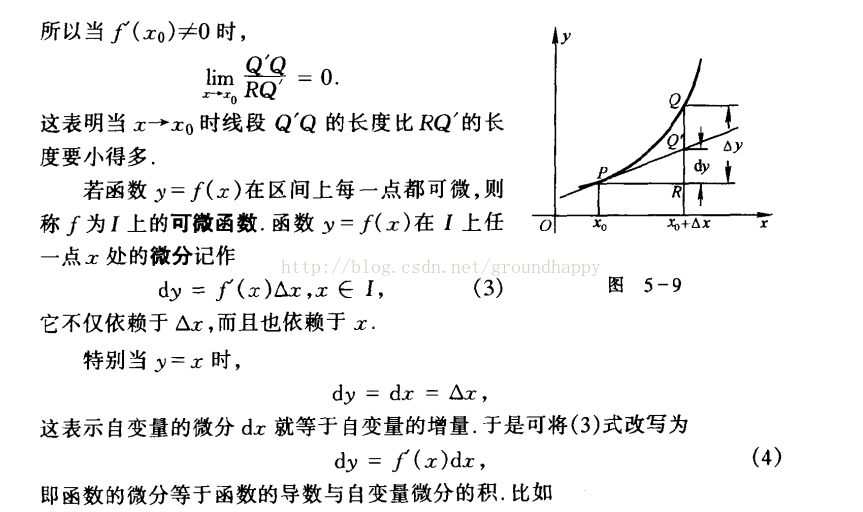
2.2 什麼是導數,什麼是微分,什麼是積分 參考
導數就是函式在這一點變化率
微分是函式導數乘以自變數的增量,他是因變數的增量的線性主部,▲y=dy+o(▲x)
導數和微分的區別。
當自變數x發生一個極小的偏移deta x 後 變化了相對於原y值的一個增量deta y
導數指的是 deta y/ deta x的值,表示的是斜率
微分指的是 deta y的線性主部 參看圖5-9
積分
定積分是某種特殊合式的極限
不定積分是某個函式f(x)的原函式的集合
2.3什麼是鏈式法則
鏈式法則是用來求複合函式的導數,也就是偏導數的。比如說y是x的函式 z是y的函式那麼dz/dx =dz/dy * dy/dx
再比如 u v是x y的函式,f是u v的函式,那麼df/dx=df/dudu/dx + df/dvdv/dx
3.1 什麼是大數定律(LAMDA)先通俗講再舉例
大數定律通俗一點來講,就是樣本數量很大的時候,樣本均值和數學期望充分接近,也就是說當我們大量重複某一相同的實驗的時候,其最後的實驗結果可能會穩定在某一數值附近。就像拋硬幣一樣,當我們不斷地拋,拋個上千次,甚至上萬次,我們會發現,正面或者反面向上的次數都會接近一半,也就是這上萬次的樣本均值會越來越接近50%這個真實均值,隨機事件的頻率近似於它的概率。
3.1.2什麼是中心極限定理 參考
中心極限定理是說當樣本數量無窮大的時候,樣本均值的分佈呈現正態分佈(邊說邊比劃正態曲線)
大數定律和中心極限定理的區別:
前者更關注的是樣本均值,後者關注的是樣本均值的分佈,比如說擲色子吧,假設一輪擲色子n次,重複了m輪,當n足夠大,大數定律指出這n次的均值等於隨機變數的數學期望,而中心極限定理指出這m輪的均值分佈符合圍繞數學期望的正態分佈
3.2 全概率公式與貝葉斯公式 參考
全概率是用原因推結果,貝葉斯是用結果推原因
++++++++++++++++++++++++++++++++++++++++
全概率:P(A)=P(B1)P(A|B1)+P(B2)P(A|B2)+P(B3)P(A|B3)+⋯
把Bi看作是事件A發生的一種“可能途徑”,P(A|B1)則是通過這種途徑得到A的可能性,而途徑的選擇是隨機的,因此可以把P(A)看作不同途徑概率的和
村莊 小偷
+++++++++++++++++++++++++++++++++++++++++
貝葉斯 利用貝葉斯定理,我們可以通過條件概率P(Y|X)P(Y|X)計算出P(X|Y)P(X|Y),從某種意義上說,就是“交換”條件
這裡貝葉斯可以看作求某種途徑佔所有途徑的比例
+++++++++++++++++++++++++++++++++++++++++
貝葉斯用在機器學習中:
比如性別分類,在身高體重等因素已知的情況下判斷男性或者女性,這裡假設身高體重都是正態分佈,這樣就可以根據u和σ2求出來某一性別下他的身高=xx的概率大小也就是條件概率繼而求出P(性別|身高,體重)
P(性別|身高,體重)=p(身高|性別) * p(體重|性別) / ∑ P(身高,體重|性別) 分母是常數
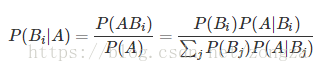
3.2.2 鏈式法則
P(X1,X2,…,Xn)=P(X1)P(X2|X1)…P(Xn|X1,X2,…,Xn−1)…………
鏈式法則通常用於計算多個隨機變數的聯合概率,特別是在變數之間相互為(條件)獨立時會非常有用。注意,在使用鏈式法則時,我們可以選擇展開隨機變數的順序;選擇正確的順序通常可以讓概率的計算變得更加簡單。
3.2.3 什麼是概率分佈
概率分佈是描述一個隨機變數的不同取值範圍及其概率的函式,函式中有一些引數可以調整這一分佈的範圍和取值概率,有了這個函式,就可以計算n次實驗後某事件發生的概率。
3.2.4 連續和離散分佈
離散分佈:隨機變數只在一些有限的位置取值,例如拋硬幣,他的期望可以通過直接累積相加得到也就是ΣxP(x)
連續分佈:隨機變數的取值是連續且無窮的,例如01之間任取一個數,他的期望可以通過積分求得也就是∫xP(x)dx
3.2.5說一下正態分佈
正態分佈又稱高斯分佈,他是連續型隨機變數的分佈,它主要由兩個引數u和σ^2,也就是期望和方差,遵從正態分佈的隨機變數滿足這樣一個規律:取值離u越近的概率越大,同時σ描述了分佈的胖瘦,他越大,曲線越矮胖,越小,曲線越高瘦。
3.2.6 說一下t分佈
t分佈主要針對正態分佈且方差未知的總體,如果你的樣本很少而你還相求均值的時候就得用t分佈
3.3 方差相關(lamda吳建鑫)
0 概念
概率論中方差用來度量隨機變數和其數學期望(即均值)之間的偏離程度。統計中的方差(樣本方差)是每個樣本值與全體樣本值的平均數之差的平方值的平均數1 方差的計算方法,他會提前寫好一個方差表示式問你對不對,如果不對的話請寫出正確的表示式;
注意點1 實際上n應為n-1
注意點2 M和u的區別,前者是所有樣本xi的均值後者是隨機變數X的數學期望,前者分母n-1後者n2 方差中n-1的含義參考
是為了保證計算出來的方差沒有偏差。實際上將Xi-X拔擴充套件為Xi-u+(u-X拔)之後可得到除以n所得到的方差始終小於真正的方差,偏差的大小是1/n *真實方差的平方,為了去掉這個偏差才最終變為n-13 如果寫一個程式計算方差,那麼計算一次記憶體訪問幾次
這裡就不考慮缺頁了,假設資料全都在一頁中且頁已經調入記憶體
首先求樣本均值需要一個for迴圈n次
其次計算方差也需要一個for迴圈求差值,差值的平方,差值的平方的和
所以一共2n次。
3.3.2 協方差與相關係數
它可以用來度量兩個隨機變數的相關性
Cov(X,Y)=E((X−E(X))(Y−E(Y)))
3.3.3 獨立和不相關 方差與相關係數
相關描述的是隨機變數之間線性相關而方差或者說獨立性描述的是值相關,所以隨機變數之間獨立則一定不相關但是不相關不一定獨立(不如可能存在非線性函式使得兩個隨機變數能滿足該函式提供的對映)
3.4極大似然估計與機器學習隨機梯度下降演算法
3.10 什麼是事件的獨立性
某一事件發生的概率完全不受到其他事件的影響,用公式表示就是P(A,B)=P(A)*P(B)
3.11設麼是隨機變數
隨機變數並不是一個真的變數,它更像是將樣本空間的結果對映到真值的函式,讓我們可以將事件空間的形式概念抽象出來
3.12 什麼是數學期望
隨機變數的均值(不同於樣本均值),大數定律指出如果樣本足夠的話,樣本均值才會無限接近期望
3.13 什麼是馬爾科夫鏈?參考
馬爾可夫鏈描述了隨機變數的一個狀態序列,在這個狀態序列裡未來資訊只與當前資訊有關,而與過去的資訊無關。他有兩個很重要的假設:
1 t+1時刻的狀態的概率分佈只與t時刻有關
2 t到t+1的狀態轉移與t值無關
一個馬爾可夫模型可以看作是狀態空間(也就是所有可能狀態)+狀態轉移矩陣(也就是一個條件概率分佈)+ 初始概率分佈(就是初始化狀態)
3.4有一蘋果,兩個人拋硬幣來決定誰吃這個蘋果,先拋到正面者吃。問先拋這吃到蘋果的概率是多少?
第一次拋硬幣後兩人的先後順序就確定了,假設A先於B,那麼A只能在1357.。。等奇數次拋硬幣,現在我們吧問題分成兩個部分,實際上第三次以後贏和第一次以後贏他面臨的處境一樣,他在第一次贏的概率是1/2,在第三次以後贏的概率是1/21/2p,所以有p=1/2+1/4*p,解出來的p就是先拋贏的概率
當然也可以用等比數列求,第一次+第三次+。。。。加到最後0
3.5一副撲克牌54張,現分成3等份每份18張,問大小王出現在同一份中的概率是多少?
先求總的分配方案:M=(C54取18)(C36取18)(C18取18)種分法
再求大小王在一份的分配方案:N=(C3取1)(C52取16)(C36取18)*(C18取18)種
3.6一條長度為l的線段,隨機在其上選2個點,將線段分為3段,問這3個子段能組成一個三角形的概率是多少?
運用線性規劃的思想,假設l被分成x,y-x,l-y的三個線段,期中y>x,l>y,利用三角形兩邊之和大於第三邊可以得到三個方程組,畫圖求解
3.7你有兩個罐子以及50個紅色彈球和50個藍色彈球,隨機選出一個罐子然後從裡面隨機選出一個彈球,怎麼給出紅色彈球最大的選中機會?在你的計劃裡,得到紅球的機率是多少?
在一個罐子中抽到紅球的最大概率是1,也就是罐子裡全都是紅球,而另一個罐子裡是剩餘紅球和全部的籃球,能得到當罐子一的紅球越少,罐子二中的紅球所佔的比例就越大,抽中的概率也就越大,所以最好的分配方案是一個罐子有一個紅球,另一個罐子有49紅50藍,這樣總概率是1/21+1/2(49/99)
3.8給你一個骰子,你扔到幾,機器將會給你相應的金錢。比如,你扔到6,機器會返回你6塊錢,你扔到1,機器會返回你1塊錢。請問,你願意最多花多少錢玩一次?
就是求一下數學期望,因為假設你玩無窮次,根據大數定律,實際上你的收益就是隨機變數的數學期望,他等於11/6+21/6+…=3.5,你不能花比這更多的錢,否則會賠本
3.9有一對夫婦,先後生了兩個孩子,其中一個孩子是女孩,問另一個孩子是男孩的概率是多大?
答案是2/3.兩個孩子的性別有以下四種可能:(男男)(男女)(女男)(女女),其中一個是女孩,就排除了(男男),還剩三種情況。其中另一個是男孩的佔了兩種,2/3. 之所以答案不是1/2是因為女孩到底是第一個生的還是第二個生的是不確定的。
X是隨機變數,X在[0,1]之間,E[X]=u,1>c,請證明P(X < cu)<=(1-u)/(1-cu)
缺少
兩個正太分佈相加是不是正太分佈
- 離散數學
4.1全序,偏序
偏序只對部分元素成立關係R,全序對集合中任意兩個元素都有