
TensorFlow 1.0.0rc1上玩量化神經網路 ——轉自 慢慢學TensorFlow 微信公眾號
這裡的量化不是指“量化交易(Quantitative trade)”,而是 Quantization ,即離散化,注意是否走錯片場。
前言
開發神經網路時最大的挑戰是讓它真正起作用,訓練時一般希望速度越快越好,準確率越高越好。使用浮點演算法是保持結果精確最簡單的方式,GPU 擁有加速浮點演算法的庫,所以很自然地,不需要過多關注其他數值格式。
最近,有很多神經網路模型投入實際應用。訓練計算需求隨研究者數目線性增長,但預測所需的週期與使用者數目成正比。這意味著純預測的效率成為迫在眉睫的問題。
這就是量化神經網路的用武之地。該方法包括很多不同技巧,以相對 32 位浮點更緊湊的方式對數值進行儲存和計算。
本文關注 8 bit 量化,後續文章還會再講。
量化神經網路的可行性
訓練神經網路時,對權值做很多微小的改動,這些微小增量一般需要浮點精度才能正常工作(也有一些研究工作使用量化網路進行訓練)。
使用預訓練的模型執行預測則不同。深度網路的奇妙特性是對輸入噪聲容忍度很高。如果你考慮識別照片中物體,網路能忽略所有 CCD 噪聲,光照變化和其他不重要的差異,而把注意力放在更重要的相似性。
該功能意味著網路可以把低精度計算作為另一種噪聲源,在容納更少資訊的數值格式下仍然能產生準確的預測結果。
量化神經網路的必要性
神經網路模型可能佔據大量磁碟空間,例如原始的 AlexNet (浮點格式)需要超過 200 MB。
由於一個模型中常常有數百萬連線,幾乎所有空間都被神經元連線的權值所佔據。況且這些權值都是有些微不同的浮點數,簡單的壓縮格式(如 zip)不能很好地壓縮。它們分佈在大量層中,每層權值都趨向於某個確定區間的正態分佈,例如(-3.0, 6.0)。
量化網路最初的動機是減小模型檔案尺寸(用 8-bit 量化可以縮小到原來 25%),在模型載入後仍然轉換回浮點數,這樣你已有的浮點計算程式碼無需改動即可正常執行。
具體方法是在網路權值儲存為檔案時,將每層最小值、最大值儲存下來,然後將每個浮點數值採用 8-bit 整數表示(在最大值、最小值範圍內空間線性劃分 256 段,每段用一個唯一的 8-bit 整數表示在該段內的實數值)。
例如,在 (-3.0, 6.0) 區間內,位元組 0 表示 -3.0, 位元組 255 表示 6.0, 以此類推,位元組 128 表示 1.5。
另一個量化的動機是降低預測過程的計算資源需求,這時需要將完整計算都採用 8-bit 實現。該方案實施也更加困難,因為需要修改所有計算程式碼,同時也有更大的潛在回報。讀取 8-bit 數值只需要相對浮點數值 25% 記憶體頻寬,你可以更好利用 caches,避免訪存瓶頸。你也可以使用 SIMD 指令,在一個時鐘週期內實現更多計算。一些情況下你還可以用 DSP 晶片加速 8-bit 計算。
將計算移植到 8-bit 可以幫助你更快地執行模型,功耗更低(在移動裝置上尤其重要)。它也打開了一扇通向大量不能高效執行浮點計算程式碼的嵌入式系統的大門,讓物聯網世界大量應用成為可能。
為什麼不直接用低精度訓練?
有一些實驗使用低位寬進行訓練,但結果顯示需要使用高於 8-bit 來處理反向傳播梯度值。這使得實現訓練異常複雜,從純預測開始是合理的。我們也有很多訓練好的浮點模型,用得多了自然十分了解,將它們直接轉換格式是非常方便的。
如何量化你的模型
TensorFlow 在產品級別內在支援 8-bit 計算。它也有一個將用浮點訓練好的模型轉換為等效的利用量化演算法進行預測的圖。
例如,你可以將最新 GoogLeNet 模型轉換為 8-bit 計算:
$ curl http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz -o /tmp/inceptionv3.tgz
$ tar xzf /tmp/inceptionv3.tgz -C /tmp/
$ cd ~/tensorflow-1.0.0-rc1/
$ bazel build tensorflow/tools/quantization:quantize_graph
$ bazel-bin/tensorflow/tools/quantization/quantize_graph \
--input=/tmp/classify_image_graph_def.pb \
--output_node_names="softmax" \
--output=/tmp/quantized_graph.pb \
--mode=eightbit
執行截圖見下圖所示:

這樣將會產生一個新模型 quantized_graph.pb,與原始模型執行相同計算,但內部使用 8-bit 計算,所有權值也做 8-bit 量化。
如果你注意檔案尺寸,會發現它只有原先模型的 1/4 ( 23MB vs 91 MB)。
你仍然可以執行這個模型使用幾乎相同輸入和輸出,並獲得等價的結果。下面是例子:
$ bazel build tensorflow/examples/label_image:label_image
$ bazel-bin/tensorflow/examples/label_image/label_image \
--image=<input-image> \
--graph=/tmp/quantized_graph.pb \
--labels=/tmp/imagenet_synset_to_human_label_map.txt \
--input_width=299 \
--input_height=299 \
--input_mean=128 \
--input_std=128 \
--input_layer="Mul:0" \
--output_layer="softmax:0"
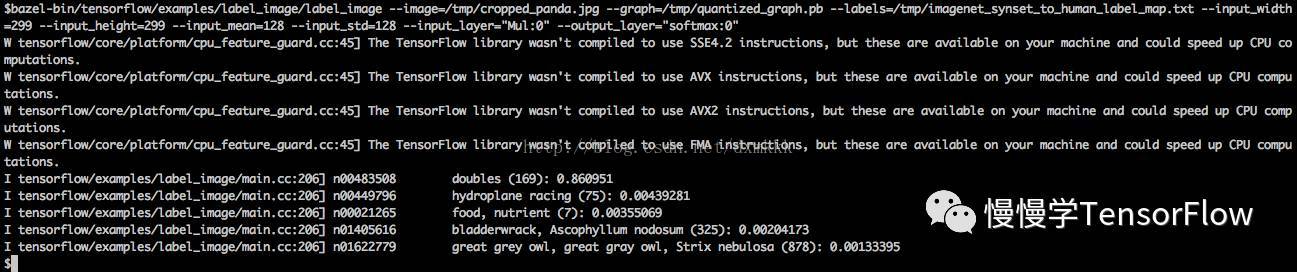
用原始模型執行結果如圖所示:
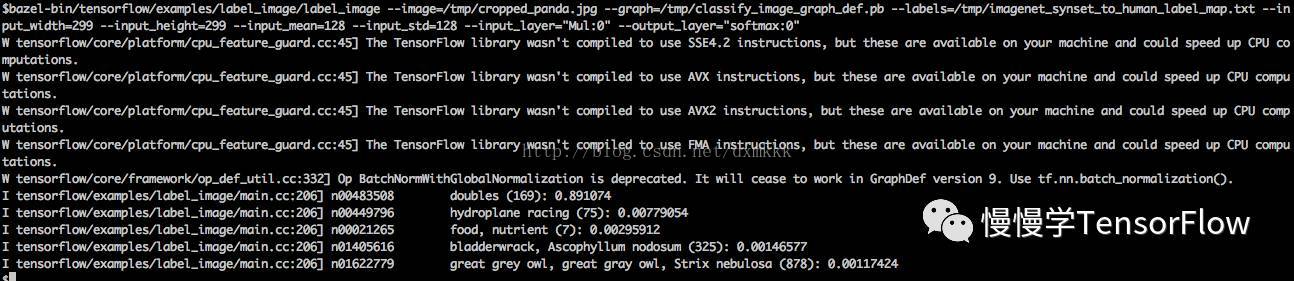
你會看到新量化的圖,輸出與原始模型非常近似的結果。
量化過程是怎樣的
TF 已經通過編寫等價的預測時常用的 8-bit 版本運算子實現了量化計算,這些運算子包括卷積、矩陣乘、啟用函式、下采樣和拼接。轉換指令碼首先替換所有已知的運算子為等價的量化運算子。
小的子圖在輸入和輸出部分有轉換函式實現浮點到 8-bit 的轉換。以下是一個例子,展示了它們的模樣。
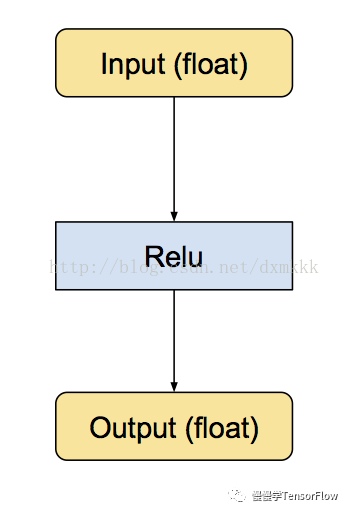
首先是原始的 Relu 運算子,具有浮點輸入和輸出:
接下來是等價的轉換後的子圖,仍然為浮點輸入和輸出,但內部轉換為 8-bit,這樣所有計算都是以 8-bit 實現:
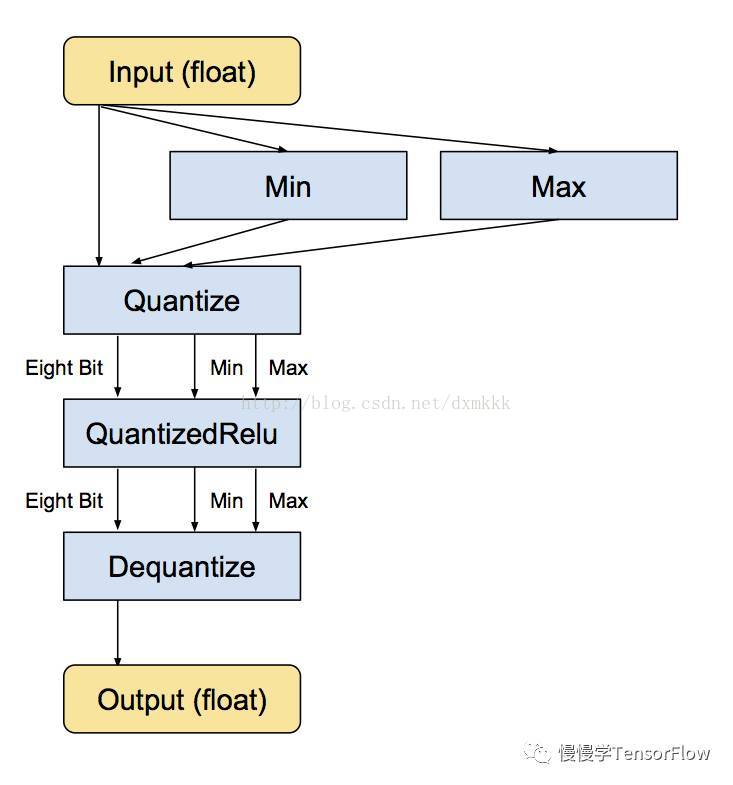
最小和最大值運算子實際上是根據輸入浮點值進行計算,之後送入 Quantize 運算子將輸入張量轉換為 8-bit。
每個獨立運算子轉換完畢,下一步是去除不必要的轉換。如果存在一串連續的浮點運算子,它們都以浮點張量傳遞結果,那麼會存在大量相鄰的 反量化/量化運算子。在該步檢測以上情形,識別出彼此可以抵消,之後便刪除這些不必要的步驟,如下圖所示:
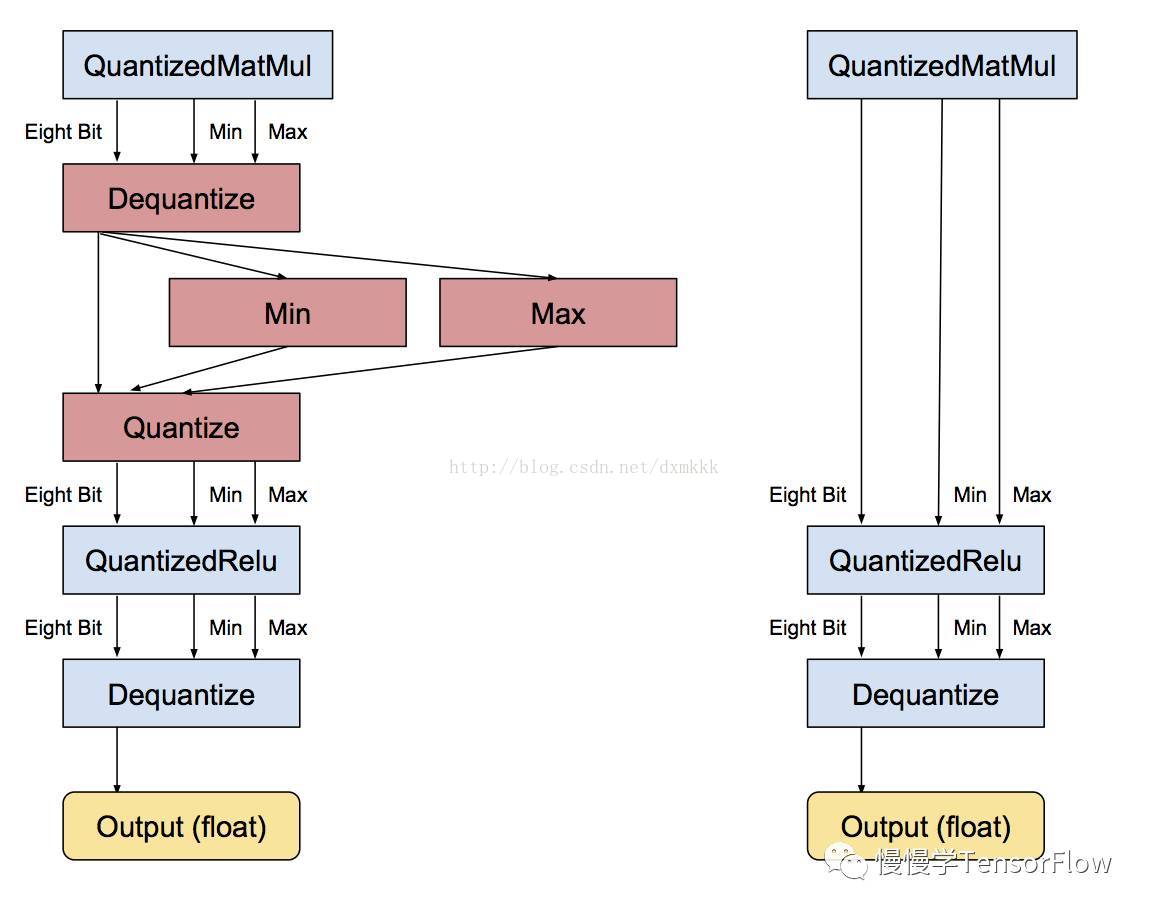
應用到大規模模型,所有運算子都有量化版本,可以實現一張全部張量計算都以 8-bit 實現的圖,無需轉換回浮點。
內容譯自: https://www.tensorflow.org/versions/r1.0/how_tos/quantization/
部分圖片來源:https://petewarden.com/2016/05/03/how-to-quantize-neural-networks-with-tensorflow/