
併發程式設計:原子性問題,可見性問題,有序性問題。
以下是本文的目錄大綱:
一.記憶體模型的相關概念
二.併發程式設計中的三個概念
三.Java記憶體模型
一.記憶體模型的相關概念
大家都知道,計算機在執行程式時,每條指令都是在CPU中執行的,而執行指令過程中,勢必涉及到資料的讀取和寫入。由於程式執行過程中的臨時資料是存放在主存(實體記憶體)當中的,這時就存在一個問題,由於CPU執行速度很快,而從記憶體讀取資料和向記憶體寫入資料的過程跟CPU執行指令的速度比起來要慢的多,因此如果任何時候對資料的操作都要通過和記憶體的互動來進行,會大大降低指令執行的速度。因此在CPU裡面就有了快取記憶體。
也就是,當程式在執行過程中,會將運算需要的資料從主存複製一份到CPU的快取記憶體當中
| 1 |
i = i + 1; |
當執行緒執行這個語句時,會先從主存當中讀取i的值,然後複製一份到快取記憶體當中,然後CPU執行指令對i進行加1操作,然後將資料寫入快取記憶體,最後將快取記憶體中i最新的值重新整理到主存當中。
這個程式碼在單執行緒中執行是沒有任何問題的,但是在多執行緒中執行就會有問題了。在多核CPU中,每條執行緒可能運行於不同的CPU
比如同時有2個執行緒執行這段程式碼,假如初始時i的值為0,那麼我們希望兩個執行緒執行完之後i的值變為2。但是事實會是這樣嗎?
可能存在下面一種情況:初始時,兩個執行緒分別讀取i的值存入各自所在的CPU的快取記憶體當中,然後執行緒1進行加1操作,然後把i的最新值1寫入到記憶體。此時執行緒2的快取記憶體當中i的值還是0,進行加1操作之後,i的值為1,然後執行緒2把i的值寫入記憶體。
最終結果i的值是1,而不是2。這就是著名的快取一致性
也就是說,如果一個變數在多個CPU中都存在快取(一般在多執行緒程式設計時才會出現),那麼就可能存在快取不一致的問題。
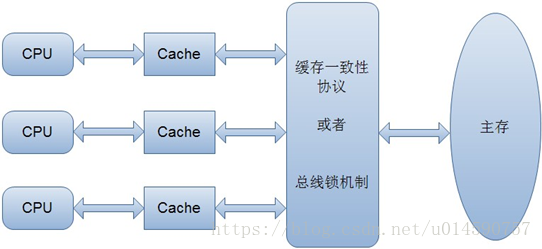
為了解決快取不一致性問題,通常來說有以下2種解決方法:
1)通過在匯流排加LOCK#鎖的方式
2)通過快取一致性協議
這2種方式都是硬體層面上提供的方式。
在早期的CPU當中,是通過在總線上加LOCK#鎖的形式來解決快取不一致的問題。因為CPU和其他部件進行通訊都是通過匯流排來進行的,如果對匯流排加LOCK#鎖的話,也就是說阻塞了其他CPU對其他部件訪問(如記憶體),從而使得只能有一個CPU能使用這個變數的記憶體。比如上面例子中如果一個執行緒在執行 i = i +1,如果在執行這段程式碼的過程中,在總線上發出了LCOK#鎖的訊號,那麼只有等待這段程式碼完全執行完畢之後,其他CPU才能從變數i所在的記憶體讀取變數,然後進行相應的操作。這樣就解決了快取不一致的問題。
但是上面的方式會有一個問題,由於在鎖住匯流排期間,其他CPU無法訪問記憶體,導致效率低下。
所以就出現了快取一致性協議。最出名的就是Intel 的MESI協議,MESI協議保證了每個快取中使用的共享變數的副本是一致的。它核心的思想是:當CPU寫資料時,如果發現操作的變數是共享變數,即在其他CPU中也存在該變數的副本,會發出訊號通知其他CPU將該變數的快取行置為無效狀態,因此當其他CPU需要讀取這個變數時,發現自己快取中快取該變數的快取行是無效的,那麼它就會從記憶體重新讀取。
二.併發程式設計中的三個概念
在併發程式設計中,我們通常會遇到以下三個問題:原子性問題,可見性問題,有序性問題。我們先看具體看一下這三個概念:
1.原子性
原子性:即一個操作或者多個操作 要麼全部執行並且執行的過程不會被任何因素打斷,要麼就都不執行。
一個很經典的例子就是銀行賬戶轉賬問題:
比如從賬戶A向賬戶B轉1000元,那麼必然包括2個操作:從賬戶A減去1000元,往賬戶B加上1000元。
試想一下,如果這2個操作不具備原子性,會造成什麼樣的後果。假如從賬戶A減去1000元之後,操作突然中止。然後又從B取出了500元,取出500元之後,再執行 往賬戶B加上1000元 的操作。這樣就會導致賬戶A雖然減去了1000元,但是賬戶B沒有收到這個轉過來的1000元。
所以這2個操作必須要具備原子性才能保證不出現一些意外的問題。
同樣地反映到併發程式設計中會出現什麼結果呢?
舉個最簡單的例子,大家想一下假如為一個32位的變數賦值過程不具備原子性的話,會發生什麼後果?
| 1 |
|
假若一個執行緒執行到這個語句時,我暫且假設為一個32位的變數賦值包括兩個過程:為低16位賦值,為高16位賦值。
那麼就可能發生一種情況:當將低16位數值寫入之後,突然被中斷,而此時又有一個執行緒去讀取i的值,那麼讀取到的就是錯誤的資料。
2.可見性
可見性是指當多個執行緒訪問同一個變數時,一個執行緒修改了這個變數的值,其他執行緒能夠立即看得到修改的值。
舉個簡單的例子,看下面這段程式碼:
| 1 2 3 4 5 6 |
|
假若執行執行緒1的是CPU1,執行執行緒2的是CPU2。由上面的分析可知,當執行緒1執行 i =10這句時,會先把i的初始值載入到CPU1的快取記憶體中,然後賦值為10,那麼在CPU1的快取記憶體當中i的值變為10了,卻沒有立即寫入到主存當中。
此時執行緒2執行 j = i,它會先去主存讀取i的值並載入到CPU2的快取當中,注意此時記憶體當中i的值還是0,那麼就會使得j的值為0,而不是10.
這就是可見性的問題,執行緒1對變數i修改了之後,執行緒2沒有立即看到執行緒1修改的值。
3.有序性
有序性:即程式執行的順序按照程式碼的先後順序執行。舉個簡單的例子,看下面這段程式碼:
| 1 2 3 4 |
|
上面程式碼定義了一個int型變數,定義了一個boolean型別變數,然後分別對兩個變數進行賦值操作。從程式碼順序上看,語句1是在語句2前面的,那麼JVM在真正執行這段程式碼的時候會保證語句1一定會在語句2前面執行嗎?不一定,為什麼呢?這裡可能會發生指令重排序(InstructionReorder)。
下面解釋一下什麼是指令重排序,一般來說,處理器為了提高程式執行效率,可能會對輸入程式碼進行優化,它不保證程式中各個語句的執行先後順序同程式碼中的順序一致,但是它會保證程式最終執行結果和程式碼順序執行的結果是一致的。
比如上面的程式碼中,語句1和語句2誰先執行對最終的程式結果並沒有影響,那麼就有可能在執行過程中,語句2先執行而語句1後執行。
但是要注意,雖然處理器會對指令進行重排序,但是它會保證程式最終結果會和程式碼順序執行結果相同,那麼它靠什麼保證的呢?再看下面一個例子:
| 1 2 3 4 |
|
這段程式碼有4個語句,那麼可能的一個執行順序是:

那麼可不可能是這個執行順序呢: 語句2 語句1 語句4 語句3
不可能,因為處理器在進行重排序時是會考慮指令之間的資料依賴性,如果一個指令Instruction 2必須用到Instruction 1的結果,那麼處理器會保證Instruction 1會在Instruction2之前執行。
雖然重排序不會影響單個執行緒內程式執行的結果,但是多執行緒呢?下面看一個例子:
| 1 2 3 4 5 6 7 8 9 |
//執行緒1: context = loadContext(); //語句1 inited = true; //語句2
//執行緒2: while(!inited ){ sleep() } doSomethingwithconfig(context); |
上面程式碼中,由於語句1和語句2沒有資料依賴性,因此可能會被重排序。假如發生了重排序,線上程1執行過程中先執行語句2,而此是執行緒2會以為初始化工作已經完成,那麼就會跳出while迴圈,去執行doSomethingwithconfig(context)方法,而此時context並沒有被初始化,就會導致程式出錯。
從上面可以看出,指令重排序不會影響單個執行緒的執行,但是會影響到執行緒併發執行的正確性。
也就是說,要想併發程式正確地執行,必須要保證原子性、可見性以及有序性。只要有一個沒有被保證,就有可能會導致程式執行不正確。
三.Java記憶體模型

在前面談到了一些關於記憶體模型以及併發程式設計中可能會出現的一些問題。下面我們來看一下Java記憶體模型,研究一下Java記憶體模型為我們提供了哪些保證以及在java中提供了哪些方法和機制來讓我們在進行多執行緒程式設計時能夠保證程式執行的正確性。
在Java虛擬機器規範中試圖定義一種Java記憶體模型(Java Memory Model,JMM)來遮蔽各個硬體平臺和作業系統的記憶體訪問差異,以實現讓Java程式在各種平臺下都能達到一致的記憶體訪問效果。那麼Java記憶體模型規定了哪些東西呢,它定義了程式中變數的訪問規則,往大一點說是定義了程式執行的次序。注意,為了獲得較好的執行效能,Java記憶體模型並沒有限制執行引擎使用處理器的暫存器或者快取記憶體來提升指令執行速度,也沒有限制編譯器對指令進行重排序。也就是說,在java記憶體模型中,也會存在快取一致性問題和指令重排序的問題。
Java記憶體模型規定所有的變數都是存在主存當中(類似於前面說的實體記憶體),每個執行緒都有自己的工作記憶體(類似於前面的快取記憶體)。執行緒對變數的所有操作都必須在工作記憶體(各自的快取中)中進行,而不能直接對主存進行操作。並且每個執行緒不能訪問其他執行緒的工作記憶體。
舉個簡單的例子:在java中,執行下面這個語句:
| 1 |
i = 10; |
執行執行緒必須先在自己的工作執行緒中對變數i所在的快取行進行賦值操作,然後再寫入主存當中。而不是直接將數值10寫入主存當中。
那麼Java語言本身對原子性、可見性以及有序性提供了哪些保證呢?
1.原子性
在Java中,對基本資料型別的變數的讀取和賦值操作是原子性操作,即這些操作是不可被中斷的,要麼執行,要麼不執行。
上面一句話雖然看起來簡單,但是理解起來並不是那麼容易。看下面一個例子i:
請分析以下哪些操作是原子性操作:
| 1 2 3 4 |
x = 10; //語句1 y = x; //語句2 x++; //語句3 x = x + 1; //語句4 |
咋一看,有些朋友可能會說上面的4個語句中的操作都是原子性操作。其實只有語句1是原子性操作,其他三個語句都不是原子性操作。
語句1是直接將數值10賦值給x,也就是說執行緒執行這個語句的會直接將數值10寫入到工作記憶體中。
語句2實際上包含2個操作,它先要去讀取x的值,再將x的值寫入工作記憶體,雖然讀取x的值以及將x的值寫入工作記憶體這2個操作都是原子性操作,但是合起來就不是原子性操作了(可能讀取完就被中斷了)。
同樣的,x++和 x = x+1包括3個操作:讀取x的值,進行加1操作,寫入新的值。
所以上面4個語句只有語句1的操作具備原子性。
也就是說,只有簡單的讀取、賦值(而且必須是將數字賦值給某個變數,變數之間的相互賦值不是原子操作)才是原子操作。
不過這裡有一點需要注意:在32位平臺下,對64位資料的讀取和賦值是需要通過兩個操作來完成的,不能保證其原子性。但是好像在最新的JDK中,JVM已經保證對64位資料的讀取和賦值也是原子性操作了。
從上面可以看出,Java記憶體模型只保證了基本讀取和賦值是原子性操作,如果要實現更大範圍操作的原子性,可以通過synchronized和Lock來實現。由於synchronized和Lock能夠保證任一時刻只有一個執行緒執行該程式碼塊,那麼自然就不存在原子性問題了,從而保證了原子性。
2.可見性
對於可見性,Java提供了volatile關鍵字來保證可見性。
當一個共享變數被volatile修飾時,它會保證修改的值會立即被更新到主存,當有其他執行緒需要讀取時,它會去記憶體中讀取新值。(volatile會立刻更新)
而普通的共享變數不能保證可見性,因為普通共享變數被修改之後,什麼時候被寫入主存是不確定的,當其他執行緒去讀取時,此時記憶體中可能還是原來的舊值,因此無法保證可見性。
另外,通過synchronized和Lock也能夠保證可見性,synchronized和Lock能保證同一時刻只有一個執行緒獲取鎖然後執行同步程式碼,並且在釋放鎖之前會將對變數的修改重新整理到主存當中。因此可以保證可見性。(個人的理解是他們的效率太慢了)
3.有序性
在Java記憶體模型中,允許編譯器和處理器對指令進行重排序,但是重排序過程不會影響到單執行緒程式的執行,卻會影響到多執行緒併發執行的正確性。
在Java裡面,可以通過volatile關鍵字來保證一定的“有序性”(具體原理在下一篇博文講述)。另外可以通過synchronized和Lock來保證有序性,很顯然,synchronized和Lock保證每個時刻是有一個執行緒執行同步程式碼,相當於是讓執行緒順序執行同步程式碼,自然就保證了有序性。
另外,Java記憶體模型具備一些先天的“有序性”,即不需要通過任何手段就能夠得到保證的有序性,這個通常也稱為 happens-before 原則。如果兩個操作的執行次序無法從happens-before原則推匯出來,那麼它們就不能保證它們的有序性,虛擬機器可以隨意地對它們進行重排序。