
Java虛擬機器記憶體管理知識總結
0、Java 對記憶體的劃分:
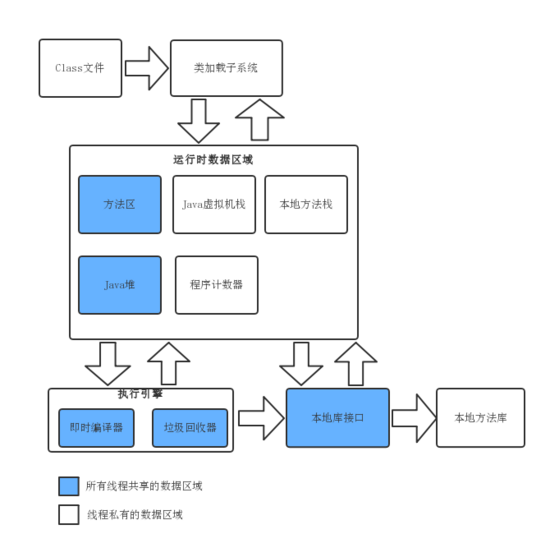
Java虛擬機器規範將實體記憶體(主記憶體和CPU中的快取、暫存器)劃分為 程式計數器 、 Java 虛擬機器棧 、 本地方法棧 、 Java 堆 、 方法區 五個區域,但並沒有規定這些區域的具體實現,在其他地方聽到的一些名詞(如永久代、元空間等,這些都是方法區的具體實現)可能都是這些區域具體的實現,這點要特別注意,別被這些概念搞暈。
各個區域的特點如下表:
| 區域 | 執行緒關係 | 記憶體異常 | 垃圾回收 | 作用 |
|---|---|---|---|---|
| 程式計數器 | 執行緒私有 | 無 | 無 | 記錄Java虛擬機器正在指向的位元組碼指令 |
| Java 虛擬機器棧 | 執行緒私有 | StackOverflowError、OutOfMemoryError | 無 | 描述 Java 方法執行時的記憶體模型,棧中棧幀儲存區域性變量表、運算元棧、動態連結、方法返回地址等資訊。 |
| 本地方法棧 | 執行緒私有 | StackOverflowError、OutOfMemoryError | 無 | 描述本地方法(非 Java 程式碼編寫)執行時的記憶體模型 |
| 方法區 | 執行緒共享 | OutOfMemoryError | 有 | 儲存虛擬機器載入過的類資訊、常量(常量池)、靜態變數、即時編譯器(JIT)生成的程式碼 |
| Java 堆 | 執行緒共享 | OutOfMemoryError | 有 | 存放 Java物件(例項) |
1、類載入器:
類載入器分為 Bootstrap 、 Extension ClassLoader (Java9 中是 Platform ClassLoader)、 Application ClassLoader
可以呼叫類載入器物件的 getParent() 方法查詢該級載入器的上一級載入器,也成為父類載入器。
| 類載入器 | 描述 | 是否為 Java 實現 |
|---|---|---|
| Bootstrap | JVM啟動時建立,通常由作業系統相關的原生代碼實現,是最根基的類載入器,負責裝載的是最核心的 Java 類,如 Object 類、System 類、String 類等 | 否 |
| Extension ClassLoader | 載入一些擴充套件的系統類,如 XML、加密、壓縮相關功能的類 | 是 |
| Application ClassLoader | 載入使用者定義的 CLASSPATH 路徑下的類 | 是 |
此處不翻譯了,翻譯後就變味了,尤其是下面的 Parents Delegation Model 翻譯為雙親委派模型很不恰當。
位元組碼檔案載入到記憶體中,才可以例項化出類,而類載入器就是負責載入 Java 類的。低級別的類載入器在載入一個類時會先詢問上一級的類載入器,直到詢問到頂級的類載入器(Bootstrap),如果頂級的類載入器可以載入就載入該類,否則向下嘗試是否可以載入該類,也即是如果上一級類載入器能載入的就用上一級載入(複用上一級的類載入器),用不了再用自身的類載入器載入,這也就是口口相傳卻是翻譯很不恰當的雙親委派模型。這樣做可以使類載入更加安全,避免載入和標準 Java 類同包同名的類破壞虛擬機器。

可以根據需要繼承 Application ClassLoader 實現自定義類載入器,隔離載入器、修改類的載入方式、擴充套件載入源、防止原始碼洩露。
2、類載入的過程:
類載入是將位元組碼檔案例項化成 Class 物件並進行相關初始化的過程。類載入包括類的 載入(Load)、類的 連結 (Link)、類的 初始化 (init)三個步驟。
類的載入是將位元組碼檔案以二進位制流的方式讀取到記憶體中並轉化為特定的資料結構,檢查 cafe baby 這個魔法數(是不是Java檔案的標誌),是否有父類等,建立類對應的 Class 物件。
類的連結又分為 驗證 、 準備 、 解析 三個階段,驗證階段是進行更加詳細的校驗,如型別是否正確,靜態變數是否合理等;準備階段是為類的靜態變數分配記憶體空間,並設定預設值;解析階段是保證類和類之間相互引用的正確性,完成類在記憶體中的結構佈局。
類的初始化並不是初始化物件,而是根據程式碼中的值初始化類的靜態變數值,類的靜態變數的初始化方式也有直接在宣告時指定值和在靜態程式碼塊中指定值兩種方式。
3、訪問物件的兩種方式:
Java虛擬機器棧中的區域性變量表存放的資料除了基本的資料型別外,還有物件的引用型別(reference),這關係到如何訪問一個物件。
在不同的虛擬機器中,物件的訪問方式也是不同的,主流的訪問方式有 使用控制代碼 和 直接指標 兩種。
- 使用控制代碼:

使用控制代碼是在 Java 堆中劃分出一塊區域作為控制代碼池,控制代碼池中存放物件的例項資料和型別資料(類相關的資訊),reference 中存放的是物件在控制代碼中的地址,這是一種間接訪問物件方式。
- 直接指標:

直接指標是reference中直接存放物件的地址,但 Java 堆需要考慮如何存放訪問物件型別的指標。
兩種方式其實各有優劣,如下表:
| 方式 | 優勢 | 特點 |
|---|---|---|
| 使用控制代碼 | reference 中存放的是穩定的控制代碼地址,物件在移動時只改變控制代碼池中物件的地址,而reference中的地址不需要改變。 | 間接訪問 |
| 直接指標 | 節省了一次指標定位的時間開銷,訪問速度相對更快。 | 直接訪問 |
4、判斷物件是否可以回收的演算法:
垃圾回收之前需要判斷物件是否可以回收,常見的判斷演算法有引用計數演算法和可達性分析演算法。
引用計數演算法:
每個物件都有對應的引用計數器,當有一個地方引用該物件時,就將引用計數器的值加1,當引用失效時,就將引用計數器的值減1,當計數器的值為0時,表示物件沒有引用,可以被回收了。
缺點:看起來簡單高效,但是有迴圈引用問題。如果兩個物件中包含對方的引用就會產生迴圈引用問題,導致垃圾收集器不能回收物件。
可達性分析演算法:
如果物件與GC Roots 之間沒有直接或間接的應用關係,就可以被回收了。常見的 GC Roots 物件包括虛擬機器棧(棧幀本地變量表)中引用的物件、方法區中靜態屬性引用的物件、方法區常量引用的物件、本地方法棧中(Native 方法)引用的物件。GC Roots,是一個特殊的物件,且絕對不能被其他物件引用,不然也會像引用計數演算法那樣有迴圈引用的問題。
注:歡迎工作1到6年的Java工程師朋友們加入Java架構交流裙:834962734。群內提供免費的Java架構學習資料(有Spring,MyBatis,Netty原始碼分析,高併發、高效能、分散式、微服務架構的原理,JVM效能優化等...)這些成為架構師必備的知識體系,以及Java進階學習路線圖。
5、常見的垃圾回收演算法:
- 標記-清除演算法
最基本的垃圾回收演算法,後續的演算法都是對它的改進。
首先標記出需要回收的物件,再將標記出的區域內容清除。
缺點是:標記時的查詢效率,清除時產生記憶體碎片。

- 標記-複製演算法
將記憶體區域劃分為兩塊,每次只使用一塊,垃圾回收時,標記正在使用的記憶體區域,將存活的物件複製到另一塊記憶體區域,再將原來的那一塊記憶體區域一次性清除。避免了記憶體碎片的產生,但不適合存活時間長的物件。
缺點:浪費了一半的記憶體空間,當物件存活率高時,進行大量的複製操作,效率不高。

- 標記-整理演算法
標記過程和標記-除演算法相同,垃圾回收時,是將存活的物件向同一端移動,再清除這之外的記憶體區域,這樣就使得物件佔用的記憶體區域連續,避免了記憶體碎片的產生。

- 分代收集演算法
根據物件存活時間的長短,將堆記憶體分為新生代和老生代,存活時間短的物件放在新生代區域,存活時間長的大物件(如物件陣列)放在老生代區域。新生代和老生代的比例是 1 : 2,新生代又分為一個 Eden 區和兩個 Survivor 區。新生代使用標記-複製演算法,老生代使用標記-清除演算法或標記-整理演算法,這樣最大發揮各自演算法的優勢。

6、常見的垃圾回收器:
- Serial 回收器
Serial 採取 “複製演算法” 實現,如果是在單 CPU 環境下,Serial 收集器沒有執行緒互動的開銷,理論上是可以獲得最高的單執行緒執行效率,STW 的時間也可以控制在幾十到幾百毫秒內,這個時間是完全可以接受的。
- Serial Old (PS MarkSweep)回收器
Serial Old 收集器 是 Serial 收集器的老年代版本,同樣也是一個單執行緒收集器,使用了 “標記-整理演算法”。
- ParNew 回收器
ParNew 收集器實際上就是 Serial 收集器的多執行緒版本,收集演算法、STW、物件分配的規則、回收策略等都與 Serial 收集器完全一樣,兩者相同的程式碼很多。ParNew 收集器雖然有多執行緒優勢,但在單 CPU 和多 CPU 環境下,效果並不一定會比 Serial 好,至少在單 CPU 環境下是肯定不如的 Serial 的。
- Parallel Scavenge 回收器
Parallel Scavenge收集器和 ParNew 收集器很像,也是一個新生代收集器,也是使用複製演算法,並且還是並行的多執行緒的收集器。相比於 ParNew 收集器,Parallel Scavenge收集器可以更加精準的控制 CPU 的吞吐量和 STW 的時間,對於互動不多的任務可以更快地完成。
- Parallel Old 回收器
Parallel Old 收集器是 Parallel Scavenge 收集器的老年代版本,使用多執行緒和 “標記-整理演算法”。在 Parallel Old 收集器出現之間,選擇了 Parallel Scavenge 收集器作為新生代的收集器,就只能選擇 Serial Old 收集器作為老生代收集器,這樣肯定就是對多 CPU 的浪費,所以 Parallel Scavenge收集器 + Parallel Old 收集器,對於多 CPU 環境吞吐量要求高的環境,算是強強聯合。
- CMS 回收器
CMS (Concurrent Mark Sweep)收集器從英文名字上看就是基於 “標記-清除演算法” 實現的,並且還有併發的特點,它是一種以縮短 STW 的時間為目標的收集器,對於一些重視服務響應速度的網站,肯定是 STW 越短,使用者體驗越好,但是缺點是會在垃圾收集結束後產生大量的空間碎片。
通過初始標記(Initial Mark)、併發標記(Concurrent Mark)、重新標記(Remark)、併發清除(Concurrent Sweep)四個步驟完成垃圾回收。
- G1 回收器
G1 收集器是目前最先進的收集器,也是 JDK7 之後預設的垃圾回收器,它是基於 “標記-複製演算法” 實現的,所以不會產生記憶體碎片,並且也可以精準地控制 STW 的時間。G1 收集器對於新生代和老年代都是適用的,優先回收垃圾最多的區域。