
關聯容器----關聯容器概述,關聯容器操作,無序容器
關聯容器和順序容器有著根本的不同:關聯容器中的元素是按關鍵字來儲存和訪問的。與之相對,順序容器中的元素是按它們在容器中的位置來順序儲存和訪問的。
關聯容器支援高效的關鍵字查詢和訪問。兩個主要的關聯容器型別是map和set。map中的元素是一些關鍵字----值對:關鍵字起到索引的作用,值表示與索引相關聯的資料。set中每個元素只包含一個關鍵字;set支援高效的關鍵字查詢操作----檢查一個給定關鍵字是否在set中。
標準庫提供8個關聯容器:
| 型別 | 說明 |
| 按關鍵字有序儲存元素 | |
| map | 關聯陣列;儲存關鍵字---值對 |
| set | 關鍵字即值,即儲存關鍵字的容器 |
| multimap | 關鍵字可重複出現的map |
| multiset | 關鍵字可重複出現的set |
| 無序集合 | |
| unordered_map | 用雜湊函式組織的map |
| unordered_set | 用雜湊函式組織的set |
| unordered_multimap | 雜湊組織的map;關鍵字可以重複出現 |
| unordered_multiset | 雜湊組織的set;關鍵字可以重複出現 |
這8個容器間的不同體現在3個維度上:每個容器(1)或者是一個set,或者是一個map;(2)或者要求不重複的關鍵字,或者允許重複關鍵字;(3)按順序儲存元素,或無序儲存。允許重複關鍵字的容器的名字中都包含單詞multi;不保持關鍵字按順序儲存的容器的名字都以單詞unordered開頭。
型別map和multimap定義在標頭檔案map中;set和multiset定義在標頭檔案set中;無序容器則定義在標頭檔案unordered_map和unordered_set中。
二、關聯容器概述
關聯容器不支援順序容器的位置相關的操作,例如push_front或push_back。原因是關聯容器中元素是根據關鍵字儲存的,這些操作對關聯容器沒有意義。而且,關聯容器也不支援建構函式或插入操作這些接受一個元素值和一個數量值的操作。
除了與順序容器相同的操作之外,關聯容器還支援一些順序容器不支援的操作和類型別名。此外,無序容器還提供一些用來調整雜湊效能的操作。
關聯容器的迭代器時雙向的。
1、定義關聯容器
在新標準下,我們可以對關聯容器進行值初始化:


1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 12 13 int main() 14 { 15 std::map<std::string, std::size_t> word_count; // 空容器 16 std::set<std::string> exclude = { "aa", "bb", "cc" }; // 列表初始化 17 std::map<std::string, std::string> authors = { 18 { "aa", "bb" }, 19 { "cc", "dd" }, 20 { "ee", "ff" } 21 }; 22 return 0; 23 }View Code
2、關鍵字型別的要求
對於有序容器----map、set、multimap、multiset,關鍵字型別必須定義元素比較的方法。預設情況下,標準庫使用關鍵字型別的<運算子來比較兩個關鍵字。
1)有序容器的關鍵字型別
可以提供自己定義的操作來代替關鍵字上的<運算子。所提供的操作必須在關鍵字型別上定義一個嚴格弱序。可以將嚴格弱序看作“小於等於”,雖然實際定義的操作可能是一個複雜的函式。無論我們怎樣定義比較函式,它必須具備如下基本性質:
a、兩個關鍵字不能同時“小於等於”對方;如果k1“小於等於”k2,那麼k2絕不能“小於等於”k1。
b、如果k1“小於等於”k2,且k2“小於等於”k3,那麼k1必須“小於等於”k3。
c、如果存在兩個關鍵字,任何一個都不“小於等於”另一個,那麼我們稱這兩個關鍵字是“等價”的。如果k1“等價於”k2,且k2“等價於”k3,那麼k1必須“等價於”k3。
如果兩個關鍵字是等價的,那麼容器將它們視作相等來處理。
注意:如果一個型別定義了“行為正常”的<運算子,則它可以用作關鍵字型別。
2)使用關鍵字型別的比較操作
用來組織一個容器中元素的操作的型別也是該容器型別的一部分。為了指定使用自定義的操作,必須在定義關聯容器型別時提供此操作的型別。用尖括號指出要定義哪種型別的容器,自定義的操作型別(應該是一種函式指標型別)必須在尖括號中緊跟著元素型別給出。
在尖括號中出現的每個型別,就僅僅是一個型別而已。當我們建立一個容器(物件)時,才會以建構函式引數的形式提供真正的比較操作(其型別必須與尖括號中指定的型別相吻合),提供的是比較操作的指標。
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 12 bool comp(const std::string &s1, const std::string &s2) 13 { 14 return s1.size() < s2.size(); 15 } 16 int main() 17 { 18 std::map<std::string, int, decltype(comp)*> mp(comp); 19 mp["abc"] = 1; 20 mp["a"] = 2; 21 mp["qaq"] = 3; 22 mp["bb"] = 4; 23 for (auto iter = mp.begin(); iter != mp.end(); ++iter) 24 { 25 std::cout << iter->first << " " << iter->second << std::endl; 26 } 27 return 0; 28 }View Code
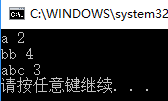
3、pair型別
pair定義在標頭檔案utility中。一個pair儲存兩個資料成員,分別命名為first和second。類似容器,pair是一個用來生成特定型別的模板。當建立一個pair時,我們必須提供兩個型別名,pair的資料成員將具有的型別。兩個型別不要求一樣。
pair上的操作:
| 操作 | 說明 |
| pair<T1, T2> p; | p是一個pair,兩個型別分別為T1和T2的成員都進行了值初始化 |
| pair<T1, T2> p(v1, v2); | p是一個成員型別為T1和T2的pair;first和second分別用v1和v2進行初始化 |
| pair<T1, T2> p = {v1, v2}; | 等價於p(v1, v2) |
| make_pair(v1, v2) | 返回一個用v1和v2初始化的pair。pair的型別從v1和v2的型別推斷出來 |
| p.first | 返回p的名為first的公有資料成員 |
| p.second | 返回p的名為second的公有資料成員 |
| p1 relop p2 | 關係運算符(<、>、<=、>=)按字典序定義:例如,當p1.first<p2.first或!(p2.first<p1.first)&&p1.second<p2.second成立時,p1<p2為true。 關係運算符利用元素的<運算子來實現 |
| p1==p2 | 當first和second成員分別相等時,兩個pair分別相等。相等性利用元素的==運算子實現 |
| p1!=p2 |
1)建立pair物件的函式
在新標準下,我們可以對返回值進行列表初始化:
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 #include <utility> 12 13 std::pair<std::string, int> func() 14 { 15 return{ "QAQ", 233 }; 16 } 17 int main() 18 { 19 auto p = func(); 20 std::cout << p.first << ", " << p.second << std::endl; 21 return 0; 22 }View Code
三、關聯容器操作
關聯容器額外的類型別名:
| 類型別名 | 說明 |
| key_type | 此容器型別的關鍵字型別 |
| mapped_type | 每個關鍵字關聯的型別:只適用於map型別(各種map) |
| value_type | 對於set,與key_type相同。 對於map,為pair<const key_type, mapped_type> |
對於set型別,key_type和value_type是一樣的;set中儲存的值就是關鍵字。在一個map中,元素是關鍵字----值對。即,每個元素是一個pair物件,包含一個關鍵字和一個關聯的值。由於我們不能改變一個元素的關鍵字,因此這些pair的關鍵字部分是const的。我們使用作用域運算子提取一個型別的成員。
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 #include <utility> 12 13 int main() 14 { 15 std::set<std::string>::value_type v1; // v1是一個string 16 std::set<std::string>::key_type v2; // v2是一個string 17 std::map<std::string, int>::value_type v3; // v3是一個pair<const string, int> 18 std::map<std::string, int>::key_type v4; // v4是一個string 19 std::map<std::string, int>::mapped_type v5; // v5是一個int 20 return 0; 21 }View Code
1、關聯容器迭代器
當解引用一個關聯容器迭代器時,我們會得到一個型別為容器的value_type的值的引用。對於map而言,value_type是一個pair型別,其first成員儲存const的關鍵字,second成員儲存值。我們可以改變pair的值,但是不能改變關鍵字成員的值。
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 #include <utility> 12 13 int main() 14 { 15 std::map<std::string, int> mp = { { "QAQ", 233 } }; 16 auto iter = mp.begin(); 17 ++iter->second; // 改變元素的值 18 // iter->first = "hello"; // 錯誤:關鍵字是const的 19 std::cout << iter->first << ", " << iter->second << std::endl; 20 return 0; 21 }View Code

1)set的迭代器是const
雖然set型別同時定義了iterator和const_iterator型別,但兩種型別都只允許訪問set中的元素。與不能改變一個map元素的關鍵字一樣,一個set中的關鍵字也是const的。可以用一個set迭代器來讀取元素的值,但是不能修改。
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 #include <utility> 12 13 int main() 14 { 15 std::set<int> s = { 5, 3, 4 }; 16 auto iter = s.begin(); 17 //*iter = 10; // 錯誤:set中的關鍵字是隻讀的 18 for (auto iter = s.begin(); iter != s.end(); ++iter) 19 { 20 std::cout << *iter << std::endl; 21 } 22 return 0; 23 }View Code

2)遍歷關聯容器
當使用以迭代器遍歷一個map、set、multimap、multiset時,迭代器按關鍵字升序遍歷元素。
3)關聯容器和演算法
我們通常不對關聯容器使用泛型演算法。關鍵字const這一特性意味著不能講關聯容器傳遞給修改或重排元素的演算法,因為這類演算法向元素寫入值,而set型別中的元素是const的,map中的元素是pair,其第一個成員是const的。
關聯容器可用於只讀取元素的演算法。但是,很多演算法都要搜尋序列。由於關聯容器中的元素不能通過它們的關鍵字進行查詢,因此對其使用泛型搜尋演算法幾乎是個壞主意。
在實際程式設計中,如果我們真要對一個關聯容器使用演算法,要麼是將它當作一個源序列,要麼當作一個目的位置。
2、新增元素
關聯容器的insert成員向容器中新增一個元素或一個元素範圍。由於map和set(以及對應的無序型別)包含不重複的關鍵字,因此插入一個已存在的元素對容器沒有任何影響。
關聯容器的insert操作:
| 操作 | 說明 |
| c.insert(v) | v是value_type型別物件;args用來構造一個元素。 對於map和set,只有當元素的關鍵字不在c中時才插入(或構造)元素。 函式返回一個pair,包含一個迭代器,指向具有指定關鍵字的元素,以及一個指示插入是否成功的bool值。 對於multimap和multiset,總會插入(或構造)給定元素,並返回一個指向新元素的迭代器 |
| c.emplace(args) | |
| c.insert(b, e) | b和e是迭代器,表示一個c::value_type型別值的範圍;items是這種值的花括號列表。函式返回void。 對於map和set,只會插入關鍵字不在c中的元素。對於multimap和multiset,則會插入範圍中的每個元素 |
| c.insert(items) | |
| c.insert(p, v) | 類似insert(v)(或emplace(args)),但將迭代器p作為一個指示,指出從哪裡開始搜尋新元素應該儲存的位置。返回一個迭代器,指向具有給定關鍵字的元素 |
| c.emplace(p, args) |
1)向map新增元素
對一個map進行insert操作時,必須記住元素型別是pair。
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 #include <utility> 12 13 int main() 14 { 15 std::map<std::string, int> words; 16 words.insert({ "a", 1 }); 17 words.insert(std::make_pair("b", 2)); 18 words.insert(std::pair<std::string, int>("c", 3)); 19 words.insert(std::map<std::string, int>::value_type("d", 4)); 20 return 0; 21 }View Code
2)檢測insert的返回值
insert(或emplace)返回的值依賴於容器型別和引數。對於不包含重複關鍵字的容器,新增單一的insert和emplace版本返回一個pair,告訴我們插入操作是否成功。pair的first成員是一個迭代器,指向具有給定關鍵字的元素;second成員是一個bool值,指出元素是插入成功還是已經存在於容器中。如果關鍵字已在容器中,則insert什麼事情也不做,且返回值中的bool部分為false。如果關鍵字不存在,元素被插入容器中,且bool值為true。
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 #include <utility> 12 13 int main() 14 { 15 std::vector<std::string> words = { "a", "a", "b", "c", "c", "c" }; 16 std::map<std::string, int> word_count; 17 for (auto word: words) 18 { 19 auto ret = word_count.insert({ word, 1 }); 20 if (!ret.second) // word已在map中 21 ++ret.first->second; 22 } 23 for (auto iter = word_count.begin(); iter != word_count.end(); ++iter) 24 { 25 std::cout << iter->first << " " << iter->second << std::endl; 26 } 27 return 0; 28 }View Code

3)向multimap或multiset新增元素
對允許重複關鍵字的容器,接受單個元素的insert操作返回一個指向新元素的迭代器。這裡無須返回一個bool值,因為insert總是向這類容器中加入一個新元素。
3、刪除元素
關聯容器定義了3個版本的erase:
| 操作 | 說明 |
| c.erase(k) | 從c中刪除每個關鍵字為k的元素。返回一個size_type值,指出刪除的元素的數量 |
| c.erase(p) | 從c中刪除迭代器p指定的元素。p必須指向c中一個真實元素,不能等於c.end()。返回一個指向p之後元素的迭代器,若p指向c中的尾元素,則返回c.end() |
| c.erase(b, e) | 刪除迭代器b和e所表示的範圍中的元素。返回e |
4、map的下標操作
map和unordered_map容器提供了下標運算子和一個對應的at函式。set型別不支援下標,因為set中沒有與關鍵字相關聯的“值”。元素本身就是關鍵字,因此“獲取一個與關鍵字相關聯的值”的操作就沒有意義了。我們不能對一個multimap或一個unordered_multimap進行下標操作,因為這些容器中可能有多個值與一個關鍵字相關聯。
map和unordered_map的下標操作:
| 操作 | 說明 |
| c[k] | 返回關鍵字為k的元素;如果k不在c中,新增一個關鍵字為k的元素,對其進行值初始化 |
| c.at(k) | 訪問關鍵字為k的元素,帶引數檢查;若k不在c中,丟擲一個out_of_range異常 |
由於下標運算子可能插入一個新元素,我們只可以對非const的map使用下標操作。
當對一個map進行下標操作時,會獲得一個mapped_type物件。map的下標運算子返回一個左值,因此我們既可以讀也可以寫元素。
有時只是想知道一個元素是否已在map中,但在不存在時並不想新增元素。在這種情況下,就不能使用下標運算子。
5、訪問元素
在一個關聯容器中查詢元素的操作:
lower_bound和upper_bound不適用於無序容器。
下標和at操作只適用於非const的的map和unordered_map。
| 操作 | 說明 |
| c.find(k) | 返回一個迭代器,指向一個關鍵字為k的元素,若k不在容器中,則返回尾後迭代器 |
| c.count(k) | 返回關鍵字等於k的元素的數量。對於不允許重複關鍵字的容器,返回值永遠是0或1 |
| c.lower_bound(k) | 返回一個迭代器,指向第一個關鍵字不小於k的元素 |
| c.upper_bound(k) | 返回一個迭代器,指向第一個關鍵字大於k的元素 |
| c.equal_range(k) | 返回一個迭代器pair,表示關鍵字等於k的元素的範圍。若k不存在,pair的兩個成員均等於c.end() |
有序容器的迭代器通過關鍵字有序訪問容器中的元素。無論在有序容器中還是在無序容器中,具有相同關鍵字的元素都是相鄰儲存的。
四、無序容器
新標準定義了4個無序關聯容器。這些容器不是使用比較運算子來組織元素,而是使用一個雜湊函式和關鍵字型別的==運算子。在關鍵字型別的元素沒有明顯的有序關係的情況下,無序容器時非常有用的。在某些應用中,維護元素的序代價非常高,此時無序容器也很有用。
1、使用無序容器
除了雜湊管理操作之外,無序容器還提供了與有序容器相同的操作(find、insert等)。這意味著我們曾用於map和set的操作也能用於unordered_map和unordered_set。類似的,無序容器也允許重複關鍵字的版本。
因此,通常可以用一個無序容器替換對應的有序容器,反之亦然。但是,由於元素未按順序儲存,一個使用無序容器的程式的輸出通常會與使用有序容器的版本不同。
2、管理桶
無序容器在儲存組織為一組桶,每個桶儲存零個或多個元素。無序容器使用一個雜湊函式將元素對映到桶。為了訪問一個元素,容器首先計算元素的雜湊值,它指出應該搜尋哪個桶。容器將具有一個特定雜湊值的所有元素都儲存在相同的桶中。如果容器允許重複關鍵字,所有具有相同關鍵字的元素也都會在同一個桶中。因此,無序容器的效能依賴於雜湊函式的質量和桶的數量和大小。
對於相同的引數,雜湊函式必須總是產生相同的結果。理想情況下,雜湊函式還能降每個特定的值對映到唯一的桶。但是,將不同關鍵字的元素對映到相同的桶也是允許的。當一個個桶儲存多個元素時,需要順序搜尋這些元素來查詢我們想要的那個。計算一個元素的雜湊值和在桶中搜索通常都是很快的操作。但是,如果一個桶中儲存了很多元素,那麼查詢一個特定元素就需要大量比較操作。
無序容器管理操作:
| 操作 | 說明 |
| 桶介面 | |
| c.bucket_count() | 正在使用的桶數目 |
| c.max_bucket_count() | 容器能容納的最多的桶的數量 |
| c.bucket_size(n) | 第n個桶中有多少個元素 |
| c.bucket(k) | 關鍵字為k的元素在哪個桶中 |
| 桶迭代 | |
| local_iterator | 可以用來訪問桶中元素的迭代器型別 |
| const_local_iterator | 桶迭代器的const版本 |
| c.begin(n), c.end(n) | 桶n的首元素迭代器和尾後迭代器 |
| c.cbegin(n), c.cend(n) | 與前兩個函式類似,但返回const_local_iterator |
| 雜湊策略 | |
| c.load_factor() | 每個桶的平均元素數量,返回float值 |
| c.max_load_factor() | c試圖維護的平均桶大小,返回float值。c會在需要時新增新的桶,以使得load_factor<=max_load_factor |
| c.rehash(n) | 重組儲存,使得bucket_count>=n且bucket_count>size/max_load_factor |
| c.reserve(n) | 重組儲存,使得c可以儲存n個元素且不必rehash |
3、無序容器對關鍵字型別的要求
預設情況下,無序容器使用關鍵字型別的==運算子來比較元素,它還使用一個hash<key_type>型別的物件來生成每個元素的雜湊值。標準庫為內建型別(包括指標)提供了hash模板。還有一些標準庫型別,包括string和智慧指標型別定義了hash。因此我們可以直接定義關鍵字是內建型別、string還是智慧指標型別的無序容器。
但是,我們不能直接定義關鍵字型別為自定義型別的無序容器。與容器不同,不能直接使用雜湊模板,而必須提供我們自己的hash模板版本。
我們不使用預設的hash,而是使用另外一種方法,類似為有序容器過載關鍵字型別的比較操作。為了能降自定義型別用作關鍵字,我們需要提供函式來替代==運算子和雜湊值計算函式。
1 #include <iostream> 2 #include <string> 3 #include <algorithm> 4 #include <numeric> 5 #include <iterator> 6 #include <functional> 7 #include <map> 8 #include <set> 9 #include <unordered_map> 10 #include <unordered_set> 11 #include <utility> 12 13 class Sale_data 14 { 15 public: 16 Sale_data() = default; 17 Sale_data(std::string _id) :id(_id){} 18 std::string id; 19 }; 20 21 std::size_t hasher(const Sale_data &sd) 22 { 23 return std::hash<std::string>()(sd.id); 24 } 25 26 bool eqop(const Sale_data &sd1, const Sale_data &sd2) 27 { 28 return sd1.id == sd2.id; 29 } 30 31 int main() 32 { 33 // 引數分別指桶大小、雜湊函式指標、相等性判斷函式指標 34 std::unordered_map<Sale_data, int, decltype(hasher)*, decltype(eqop)*> book(42, hasher, eqop); 35 // 如果類定義了==運算子,則可以只過載雜湊函式 36 book.insert({ Sale_data("a"), 1 }); 37 book.insert({ Sale_data("b"), 233 }); 38 for (auto iter = book.begin(); iter != book.end(); ++iter) 39 { 40 std::cout << iter->first.id << " " << iter->second << std::endl; 41 } 42 return 0; 43 }View Code
