
spark基於使用者的協同過濾演算法與坑點,提交job
承接上文:
http://blog.csdn.net/wangqi880/article/details/52875524
對了,每臺機子的防火牆要關閉哈,不然spark叢集啟動不起來
前一次,已經把spark的分散式叢集佈置好了,今天寫一個簡單的案例來執行。會寫一些關於spark的推薦的東西,這裡主要有4點,1基於使用者協同過濾,2基於物品協同過濾,3基於模型的協同過濾,4基於關聯規則的推薦(fp_growth),只寫核心程式碼啊。
基於spark使用者協同過濾演算法的實現
1使用者協同過濾演算法
1.1含義
它是統計計算搜尋目標使用者的相似使用者,並根據相似使用者對物品的打分來預測目標使用者對指定物品的評分,一般選擇topn選擇相似度較高的相似使用者做推薦結果。
從這句話,我們可以看出UserBase推薦演算法主要有3個工作要做:1使用者相似度量,2最近鄰居查詢,3預測評分。
具體百度查
1.2相似性距離
這裡直接使用cos距離了,cos距離是通過向量間的cos夾角來度量相似性,如果是在同一個方向增長,那麼相似性是不會變得。公式如下:
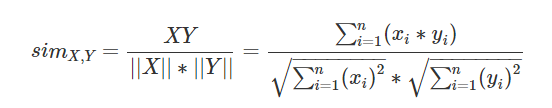
1.3樣本資料如下:
1,1,5.0
1,2,1.0
1,3,5.0
1,4,1.0
2,1,5.0
2,2,1.0
2,3,5.0
2,4,1.0
3,1,1.0
3,2,5.0
3,3,1.0
3,4,5.0
4,1,1.0
4,2,5.0
4,3,1.02Spark程式碼如下:
package org.wq.scala.ml
import org.apache.spark.mllib.linalg.distributed._
import 程式碼有註釋哈,應該都可以看得懂,主要就是計算相似讀,計算使用者1給item1的評分,這裡評分的計算為:使用者均值+topn使用者的加權平均值,權重為相似性。
3坑點
1測試了300w多w記錄,使用者估計20w,物品大500,windows單機環境16g記憶體,配置2g的xxm,跑了1個小時都沒有出來,速度太慢了,當然也跟機子配置有關,直接停了。
2中間的轉成行矩陣的方法噁心,toRowMatrix(),就是這個方法。因為,使用這個方法之後,矩陣的使用者的標號順序都變了,不知道怎麼判斷,標號和使用者號都不一樣了。舉個例子大家就知道了,都可以試試:
//下面程式的結果,這個結果是ok的。
//使用者_物品_打分
val ratings = new CoordinateMatrix(parseData)
ratings.entries.collect().map(x=>{
println("ratings=>"+x.i+"->"+x.j+"->"+x.value)
})
執行的結果,和原始的樣本一樣的:
0,0,5.0
0,1,1.0
0,2,5.0
0,3,1.0
1,0,5.0
1,1,1.0
1,2,5.0
1,3,1.0
2,0,1.0
2,1,5.0
2,2,1.0
2,3,5.0
3,0,1.0
3,1,5.0
3,2,1.0但是做了下面的轉換成行矩陣的做法之後:
下面是做了transpose().toRowRamtrix的結果
ratings.toRowMatrix().rows.collect().map(x=>{
println()
x.toArray.map(t=>{
println(t+",")
})
})
5.0,5.0,1.0,1.0,
1.0,1.0,5.0,5.0,
1.0,1.0,5.0,0.0,
5.0,5.0,1.0,1.0,
matrix的遍歷方式為map,還不能輸入使用者id查詢,噁心,使用者2的打分使用者3的打分反了,人工對比上下兩個資料就知道了。
但是隻能使用遍歷方式,遍歷matrix,我怎麼知道這條記錄是哪個使用者的。
不過我人工計算了和程式計算的相似度是差不多的,相似度應該是OK的,這裡也跪求大神指點疑問?
//程式計算相似度
2->3->0.7205766921228921
0->1->1.0000000000000002
1->2->0.3846153846153847
0->3->0.4003203845127179
1->3->0.4003203845127179
0->2->0.38461538461538474把jar提交到spark叢集執行
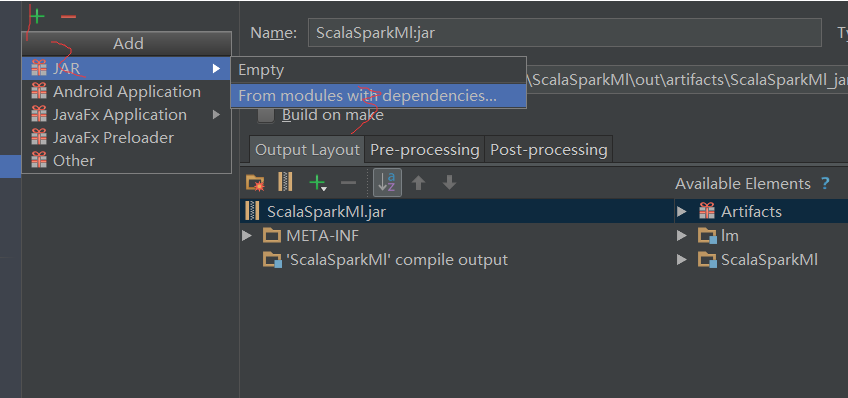
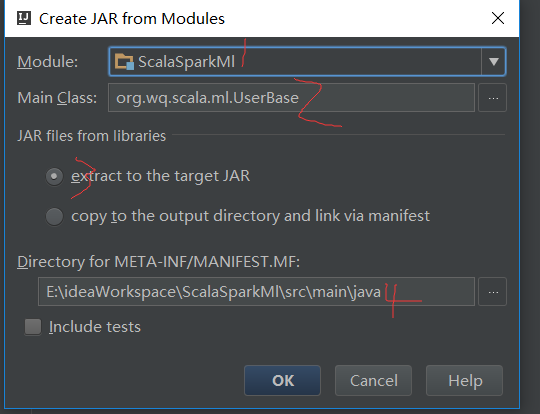
4.1打包方式
我使用的是idea,使用ctrl+alt+shift+s,
4.2執行jar與注意事項
使用rz上傳到centos中,shh工具或者其他工具都是可以,自己喜歡就好,
注意要保證資料檔案在每個節點上都有哈
我的目錄結構為(三臺機器都要一樣哈):
執行jar目錄:/home/jar/

執行jar的資料目錄為:/home/jar/data
jar與資料都好了之後,保證spark叢集執行哈,然後輸入命令執行我們的jar.
spark-submit --class org.wq.scala.ml.UserBase --master spark://master:7077 --executor-memory 1g --num-executors 1 /home/jar/UserBaseSpark.jar /home/jar/data/test.data
執行成功如圖:
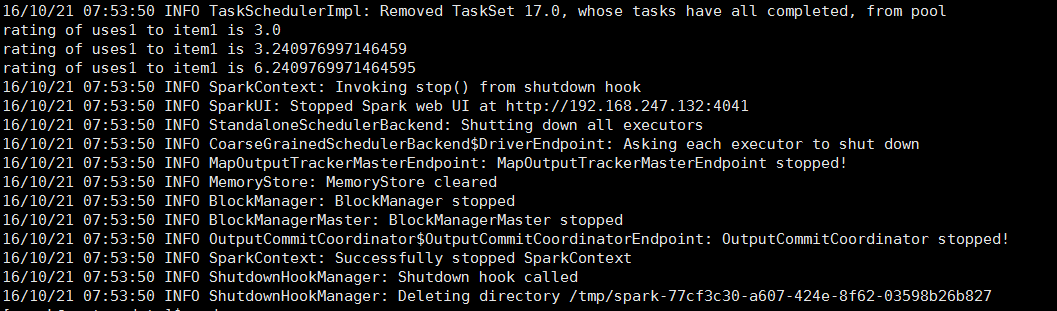
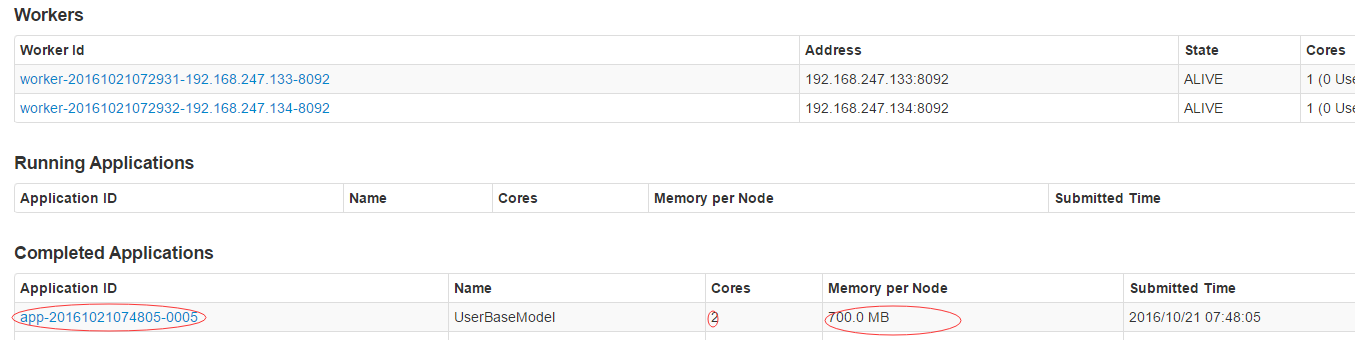
4.3注意事項
1保證你的資料檔案在節點中都有,不然彙報錯誤:
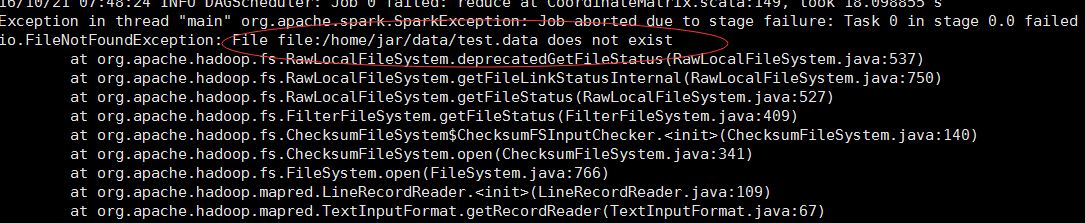
2保證你提交的job,設定的執行記憶體沒有超過你自己在spark-env.sh中的記憶體,不然要報如下警告,資源不足,程式掛起,不能執行下去:

關於toRowMatrix()方法的疑問,求解大神解析。
有時間也會看原始碼研究下,
下一篇文章會寫基於物品的協同過濾。
如果想做真實基於Spark的推薦,個人建議使用基於模型的與預計關聯規則的推薦