
C語言中關於char型別儲存的分析 以及signed與unsigned的區別
阿新 • • 發佈:2019-01-11
char型別儲存的分析
char和signed char
大家對char型別相信一定不會陌生的ANSI C 提供了3種字元型別,分別是char、signed char、unsigned charchar相當於signed char或者 unsigned char,但是這取決於編譯器!這三種字元型別都是按照1個位元組儲存的,可以儲存256個不同的值。signed char取值範圍是 -128 到 127 那麼問題來的為什麼signed char的取值範圍是從 -128到127呢首先大家應該知道原碼反碼補碼的概念以及他們之間的關係。 ------------------------------------------------------------負數將原碼先進行除符號位取反然後再加一就可以得到他的補碼 ------------------------------------------------------------ 現在繼續,首先上面提到char可以儲存256個不同的值,也就是說明他的二進位制編碼只能擁有8位有符號的char佔一個字節,最高位表示正負,其餘的七位表示數值,七位二進位制可以表示128個數(2^7 =128),即0~127;加上符號位後,就變成了-127~-0,0~127,但是我們實際上char的取值範圍為 -128~127,這時就會發現這個-0是什麼東西,聰明人一眼就能看出來-0 和 -128有關係。。(當然不能瞎猜,我們要用事實
這就是char和int的不同之處!
int==signed int,但是char不能簡單以為==signed char 以我的編譯器為例子
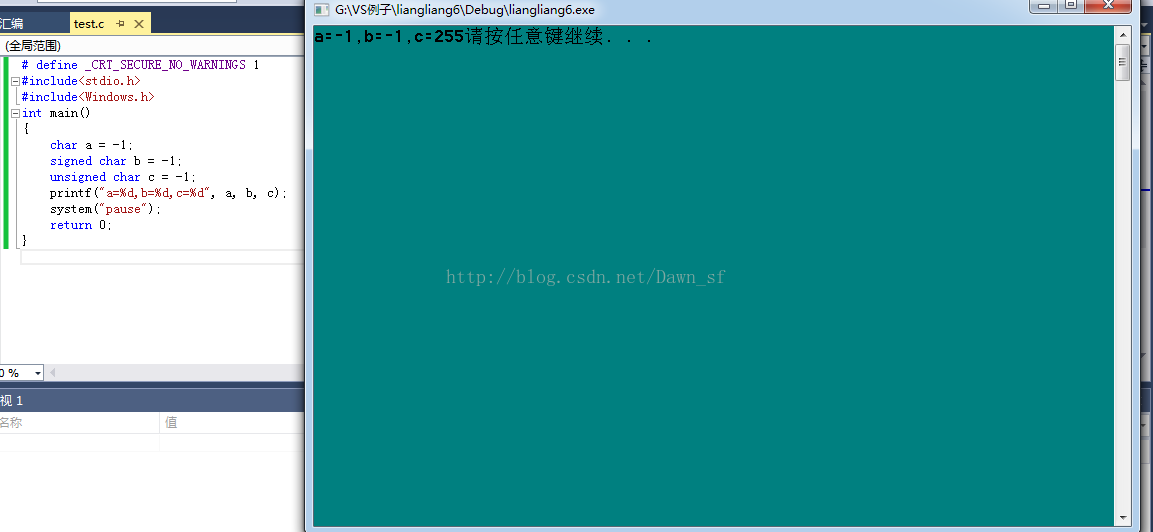
他們的值完全不同,但是為什麼呢。 首先列出-1的原碼反碼補碼 -1 原碼 1000 0001 反碼 1111 1110 補碼 1111 1111 當為signed時可以看出來值為-1,但是當它為unsigneds時計算機只識別補碼序列然後值就為255. 下面做兩個小練習 1==》
#include<stdio.h>
int main()
{
char a = -128;
printf("%u\n",a);
return 0;
}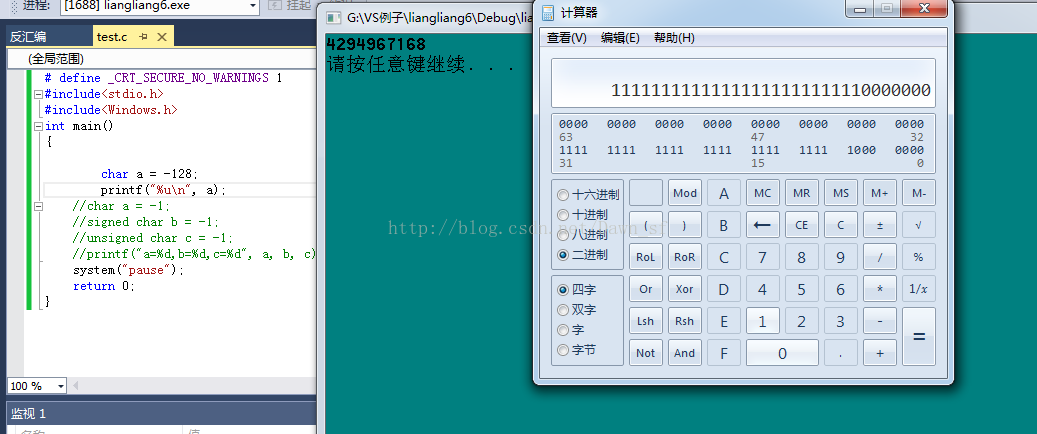
其實第一次我看到這個心情也是日了狗了。。。。 完全解釋不通。。。。。 我簡單說一下我的理解,如果錯了指出來,我們已經知道了-128的補碼序列,現在把它提出來(1000 0000 ),但是你是 希望計算機以%u的形式打印出來,所以你要對-128的補碼形式進行擴充套件(整形提升),把它擴充套件成32位,由於擴充套件是根據你 自身的符號位擴展,所以你往它的前面加上24個1。然後%u他只是拿到你的序列將它打印出來,所以他就打印出來我們剛 剛擴展出來的2進位制序列,也就是上面的值。 -128 整形提升後補碼形式: 1111 1111 1111 1111 1111 1111 1000 0000 還有這裡的%u,我們都應該知道資料在記憶體中是以補碼形式儲存的,現在%u輸出也就是認為你就是無符號數,所以在%u的 角度來講,它直接從你的記憶體中拿出來的就是原碼,直接輸出記憶體中拿出來的資料. 2==》 我們再來看一個題
#include<stdio.h>
intmain()
{
char a = 128;
printf("%d\n",a);
return 0;
}
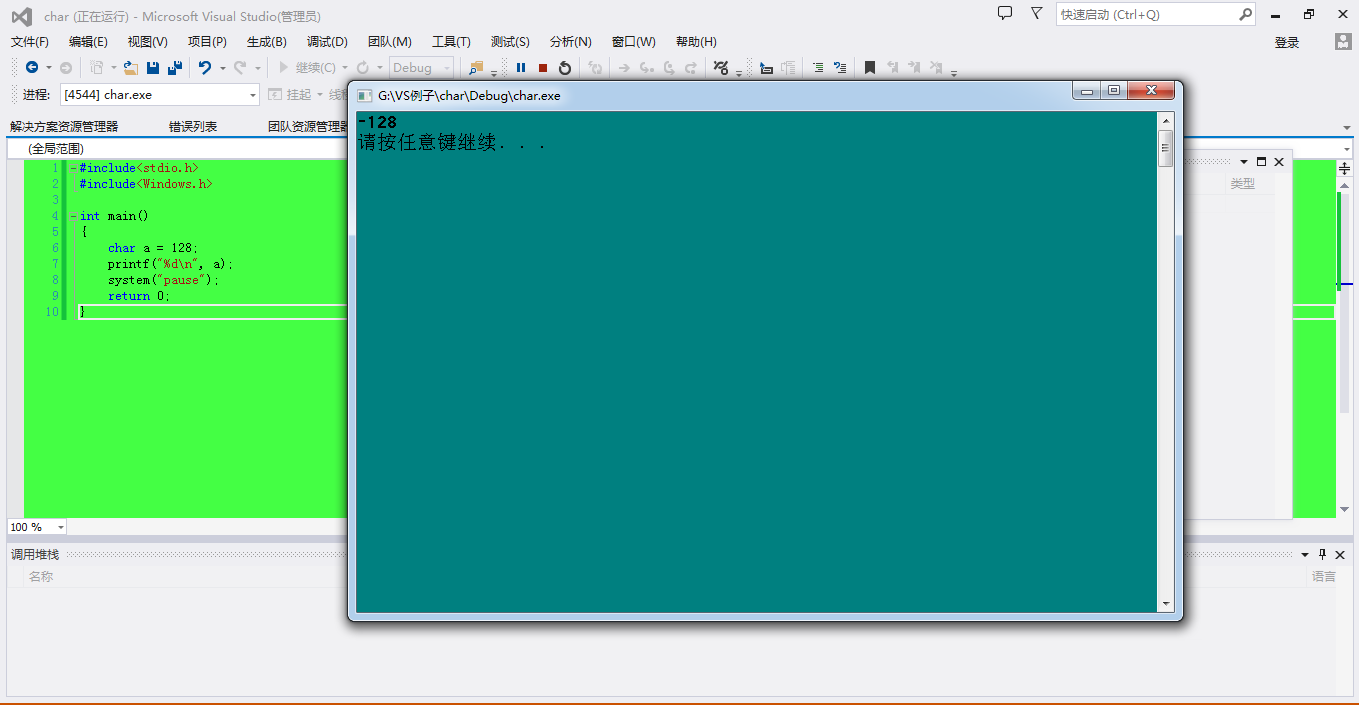
這裡我明明要%d要列印的是128,為什麼打印出來-128.編譯器壞掉了?其實這裡當你使用了%d還是發生了整形提升了,128的補碼序列(1000 0000) 對它進行整形提升後是這樣的 補碼: 1111 1111 1111 1111 1111 1111 1000 0000 反碼: 1111 1111 1111 1111 1111 1111 0111 1111 原碼: 0000 0000 0000 0000 0000 0000 1000 0000 那麼這個序列認識麼? 前面不用看它的型別時char型別,所以在char中128是不存在的,然後char的取值範圍是127 ~ -128,所以這裡直接跳到 char取值範圍最小的-128去。