mysql的字符集和整理是怎麼一回事
在MySQL資料庫中,特別是建立表的時候,因為經常使用整合工具來建立,總是對一個詞特別困惑,整理(collation),字符集很容易理解,就是資料庫中的資料要用什麼編碼格式進行編碼,那整理呢?
今天查了一下MySQL的開發文件,文件中對這個東西做了一個很有意思的描述,我把大概意思表述一下:
什麼是整理
假如我們有一個字元的集合和對應的編碼集合(因為計算機只認識數字,所以只能識別編碼),集合如下:
A->0
B->1
a->2
b->3
OK,那A\B\a\b就稱為字符集,而0,1,2,3就稱為對應的編碼,計算機儲存的時候只儲存0,1,2,3,只是當顯示的時候才顯示出字元來。
那當我們在字符集上做比較、特別是排序時怎麼做?
1、一個很常見的思路是:比較編碼的大小,編碼大的認為字元值越大。於是如果對這四個字元排序,就是b,a,B,A
2、那如果我希望大小寫無關呢?這個時候相當於又多加了一條規則,就是A=a,B=b,然後再此前提下比較大小。
3、你還可以定義出各種各樣的規則
這個規則是必須的,是一種協議、或者說是一種約定。這個規則就是整理(collation)。
由此我們知道了,所謂整理就是定義在一組字符集上的規則。瞭解了這些,也就明白了下面這些結論:
- 兩個不同的字符集不可能有相同的整理
- 每種字符集都有一個預設的整理規則,具體可以通過show character set來讀取。(如下圖所示)
- 整理的命名有個規範:1)字元名_語言名_ci/cs(case insensetive\case sensetive)、如utf8-general_ci、2)字元名_bin,表示二進位制
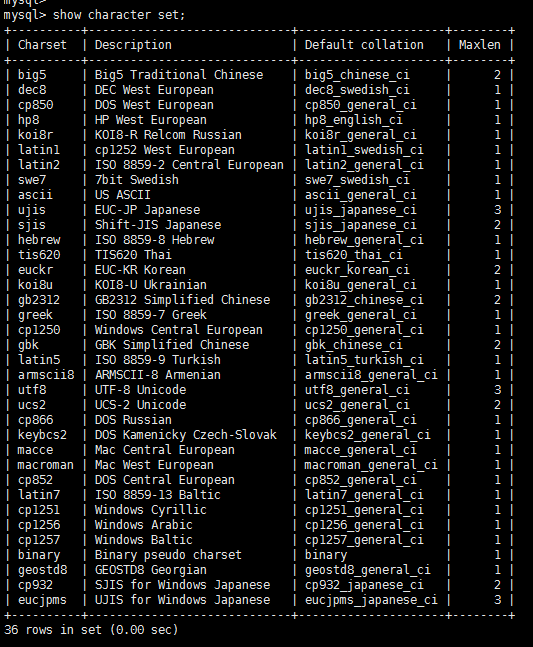
如何檢視MySQL伺服器支援的字符集
通過show character set命令,由下圖可見,MySQL伺服器支援36種字元編碼,在第三列顯示的是預設整理方案
檢視某資料庫的字符集
方法有二:
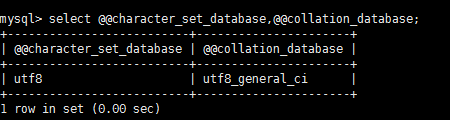
一是通過use dbname,進入某系統之後,通過如下命令:
select @@character_set_database,@@collation_database;
二:不需要進入db,直接儲存schema中的資料即可
SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = ‘db_name’;