
hive jdbc 呼叫
HIVE學習總結
Hive只需要裝載一臺機器上,可以通過webui,console,thrift介面訪問(jdbc,odbc),僅適合離線資料分析,降低資料分析成本(不用編寫mapreduce)。
Hive優勢
1. 簡單易上手,類sql的hql、
2. 有大資料集的計算和擴充套件能力,mr作為計算引擎,hdfs作為儲存系統
3. 統一的元資料管理(可與pig。presto)等共享
Hive缺點
1. Hive表達能力有限。迭代和複雜運算不易表達
2. Hive效率較低,mr作業不夠智慧,hql調優困難,可控性差
Hive
1. 提供jdbc、odbc訪問方式。
2. 採用開源軟體thrift實現C/S模型,支援任何語言。
3. WebUI的方式
4. 控制檯方式
Hive WEBUI使用
在HIVE_HOME/conf目錄hive-site.xml檔案中新增如下檔案
修改配置檔案:hive-site.xml增加如下三個引數項:
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-0.13.1.war</value>
</property>
其中lib/hive-hwi-0.13.1.war為hive頁面對應的war包,0.13.1版本沒有對應的war包需要自己打包,步驟如下:
wgethttp://apache.fayea.com/apache-mirror/hive/hive-0.13.1/apache-hive-0.13.1-src.tar.gz
tar-zxvf apache-hive-0.13.1-src.tar.gz
cdapache-hive-0.13.1-src
cdhwi/web
ziphive-hwi-0.13.1.zip ./* //打包成.zip檔案。
scphive-hwi-0.13.1.war db96:/usr/local/hive/lib/ //放到hive的安裝目錄的lib目錄下。
啟動hwi:
hive --service hwi
如有下報錯:
Problem accessing /hwi/. Reason:
Unable to find a javac compiler;
com.sun.tools.javac.Main is not on theclasspath.
Perhaps JAVA_HOME does not point to the JDK.
Itis currently set to "/usr/java/jdk1.7.0_55/jre"
解決辦法:
cp/usr/java/jdk1.7.0_55/lib/tools.jar /usr/local/hive/lib/
hive --service hwi 重啟即可。
典型部署:採用主備結構mysql儲存元資料資訊。
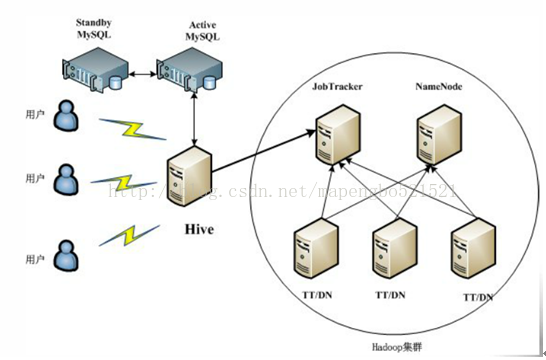
Java通過jdbc呼叫hive
使用jdbc連線hive必須啟動hiveserver,預設埠為10000,也可以指定。
bin/hive --service hiveserver -p 10002
顯示Starting Hive Thrift Server說明啟動成功。
建立eclipse建立java工程,匯入hive/lib下的所有jar,及hadoop的一下三個jar
hadoop-2.5.0/share/hadoop/common/hadoop-common-2.5.0.jar
hadoop-2.5.0/share/hadoop/common/lib/slf4j-api-1.7.5.jar
hadoop-2.5.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar
理論上只用匯入hive下面的jar,
$HIVE_HOME/lib/hive-exec-0.13.1.jar
$HIVE_HOME/lib/hive-jdbc-0.13.1.jar
$HIVE_HOME/lib/hive-metastore-0.13.1.jar
$HIVE_HOME/lib/hive-service-0.13.1.jar
$HIVE_HOME/lib/libfb303-0.9.0.jar
$HIVE_HOME/lib/commons-logging-1.1.3.jar
測試資料/home/hadoop01/data 內容如下(中間用tab鍵隔開):
1 abd
2 2sdf
3 Fdd
Java程式碼如下:
package org.apache.hadoop.hive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import org.apache.log4j.Logger;
public class HiveJdbcCli {
private static String driverName ="org.apache.hadoop.hive.jdbc.HiveDriver";
private static String url ="jdbc:hive://hadoop3:10000/default";
private static String user ="";
private static String password ="";
private static String sql = "";
private static ResultSet res;
private static final Logger log =Logger.getLogger(HiveJdbcCli.class);
public static void main(String[] args){
Connection conn = null;
Statement stmt = null;
try {
conn = getConn();
stmt =conn.createStatement();
// 第一步:存在就先刪除
String tableName =dropTable(stmt);
// 第二步:不存在就建立
createTable(stmt, tableName);
// 第三步:檢視建立的表
showTables(stmt, tableName);
// 執行describe table操作
describeTables(stmt,tableName);
// 執行load data intotable操作
loadData(stmt, tableName);
// 執行 select * query 操作
selectData(stmt, tableName);
// 執行 regular hive query統計操作
countData(stmt, tableName);
} catch (ClassNotFoundException e){
e.printStackTrace();
log.error(driverName + " notfound!", e);
System.exit(1);
} catch (SQLException e) {
e.printStackTrace();
log.error("Connectionerror!", e);
System.exit(1);
} finally {
try {
if (conn != null) {
conn.close();
conn = null;
}
if (stmt != null) {
stmt.close();
stmt = null;
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
private static void countData(Statementstmt, String tableName)
throws SQLException {
sql = "select count(1) from" + tableName;
System.out.println("Running:" + sql);
res = stmt.executeQuery(sql);
System.out.println("執行“regularhive query”執行結果:");
while (res.next()) {
System.out.println("count------>" + res.getString(1));
}
}
private static void selectData(Statementstmt, String tableName)
throws SQLException {
sql = "select * from " +tableName;
System.out.println("Running:" + sql);
res = stmt.executeQuery(sql);
System.out.println("執行 select *query執行結果:");
while (res.next()) {
System.out.println(res.getInt(1) +"\t" + res.getString(2));
}
}
private static void loadData(Statementstmt, String tableName)
throws SQLException {
String filepath ="/home/hadoop01/data";
sql = "load data local inpath'" + filepath + "' into table "
+ tableName;
System.out.println("Running:" + sql);
res = stmt.executeQuery(sql);
}
private static voiddescribeTables(Statement stmt, String tableName)
throws SQLException {
sql = "describe " +tableName;
System.out.println("Running:"+ sql);
res = stmt.executeQuery(sql);
System.out.println("執行 describetable執行結果:");
while (res.next()) {
System.out.println(res.getString(1) + "\t" +res.getString(2));
}
}
private static void showTables(Statementstmt, String tableName)
throws SQLException {
sql = "show tables '" +tableName + "'";
System.out.println("Running:" + sql);
res = stmt.executeQuery(sql);
System.out.println("執行 showtables執行結果:");
if (res.next()) {
System.out.println(res.getString(1));
}
}
private static void createTable(Statementstmt, String tableName)
throws SQLException {
sql = "create table "
+ tableName
+ " (key int, valuestring) row format delimited fieldsterminated by '\t'";
stmt.executeQuery(sql);
}
private static String dropTable(Statementstmt) throws SQLException {
// 建立的表名
String tableName ="testHive";
sql = "drop table " +tableName;
stmt.executeQuery(sql);
return tableName;
}
private static Connection getConn() throwsClassNotFoundException,
SQLException {
Class.forName(driverName);
Connection conn =DriverManager.getConnection(url, user, password);
return conn;
}
}