
小白快速部署vmware11下centos7虛擬機器的Spark 2.2.0叢集(附通俗解釋)
最近想要學習一下spark,買了本書來學習,但未曾想到是如此不靠譜,作者非常不負責任,於是在查閱大量前輩記錄的文件結合我自己的實踐後形成了這篇部落格。
歡迎各位童鞋交流和指教!
注:本文部署的standalone模式的Spark
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
系統軟體環境:
Win10(64),vmware11,centos7(64),jdk1.8,hadoop2.6(或更高),scala2.12.4,spark2.2.0
叢集網路環境:
|
IP地址 |
機器名 |
型別 |
使用者名稱 |
|
192.168.254.128 |
master |
NameNode/Master |
liu |
|
192.168.254.129 |
slave1 |
DataNode/Worker |
liu |
|
192.168.254.130 |
slave2 |
DataNode/Worker |
liu |
1. vmware11自定義安裝,全選,設定安裝和共享虛擬機器路徑,
2. Centos7安裝,首先在電腦bios設定intel-vtx有效,點開vmware建立新的虛擬機器,典型,選擇安裝的iso檔案,使用者名稱liu,密碼ndsc,設定安裝路徑,分配40g記憶體,選擇自定義元件配置如圖1所示,安裝即可。
(注意虛擬機器的安裝路徑不要和vmware11的安裝路徑在一起,否則會無法建立新虛擬機器)
圖1
安裝完後可以設定終端的快捷鍵,applications→system tool→setting找到鍵盤,新增,命名Terminal,命令/usr/bin/gnome-terminal,快捷鍵edit然後按你要的快捷鍵(我的是
如果系統的介面語言和輸入法想設定為中文,system tool→setting→region and language(第一欄的一面小旗子),輸入法選擇中文(pingyin)然後自動重啟就好。
開啟firefox設定首頁為www.baidu.com。
安裝jdk,先看下有沒有預裝好的java,java -version,
rpm -qa | grep java 看系統自帶的openjdk
然後通過 rpm -e --nodeps 後面跟系統自帶的jdk名這個命令來刪除系統自帶的jdk,
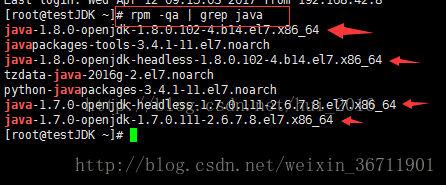
圖2
圖2中帶箭頭的刪掉。
root許可權下
mkdir /usr/java
mv /home/liu/文件/jdk...... /usr/java/
tar -zxvf jdk.....
配置環境變數
gedit /etc/profile
(注:/etc/profile是全域性性的環境變數,~/.bash_profile是每個使用者下的環境變數設定
試一下都用全域性環境變數)
在最後加入以下環境變數:
export JAVA_HOME=/usr/java/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
使配置檔案生效:
source /etc/profile
然後使用java -version檢視java是否安裝成功,如圖2。

圖3
3. 叢集網路環境配置,右鍵master,管理→克隆,虛擬機器當前狀態,完整克隆,設定名稱slave,路徑。在每臺機子上進行如下配置:
網路基本配置,su - root切換root使用者(登入到使用者root的根目錄,su root僅登入root許可權呼叫一些指令;sudo是臨時的使用root許可權),
使用hostnamectl指令,hostnamectl status檢視主機名,hostnamectl set-hostname <hostname>設定永久主機名
Ifconfig檢視ip地址。
關閉防火牆,setup 選擇system services,Tab切換選擇run tool,用空格關閉firewall。
配置hosts檔案,gedit /etc/hosts將如下程式碼新增到檔案中:(ip地址是真實查到的ip地址)
192.168.254.128 master
192.168.254.129 slave1
192.168.254.130 slave2
(其意思是每個ip地址對應每個名稱,這個在後面scp拷貝檔案會用到)
使用ping命令測試ip地址能否ping通:
ping 192.168.254.129
ping slave1
配置時鐘同步:
在每個節點的root下crontab -e該命令為vi指令,輸入i進行插入,
0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
按Esc退出編輯,:wq儲存退出,輸入以下指令手動同步時間:
/usr/sbin/ntpdate cn.pool.ntp.org
4. 免祕鑰登入設定,在liu使用者下,在master節點上執行:ssh-keygen -t rsa,然後一直回車,生成祕鑰檔案,該檔案在~/.ssh中。可cd ~/.ssh檢視(ll或ls均可)。
複製公鑰,cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod修改authorized_keys的許可權,
chmod 600 ~/.ssh/authorized_keys
將authorized_keys檔案複製到slave節點中,
scp ~/.ssh/authorized_keys [email protected]:~/
(如果出現port22的錯誤有可能是虛擬機器沒有連線到網路)
在slave1和slave2中分別執行如下指令生成ssh祕鑰:
ssh-keygen -t rsa
mv authorized_keys ~/.ssh/
cd ~/.ssh
chmod 600 authorized_keys
驗證免祕鑰登入,在master:
ssh slave1
圖4
5. hadoop配置,將hadoop2.6.5解壓至使用者主目錄下。(2.7.x以上的版本也可以)
tar -xvf hadoop-2.6.5.tar.gz
cd hadoop-2.6.5
配置hadoop-env.sh。
gedit etc/hadoop/hadoop-env.sh
在檔案靠前的位置將JAVA_HOME改為:
export JAVA_HOME=/usr/java/jdk1.8.0_151
配置yarn-env.sh。
gedit etc/hadoop/yarn-env.sh
將JAVA_HOME改為實際路徑並去掉#。
配置core-site.xml。
分別在幾個節點上建立hadoopdata目錄:(只有該操作在每個節點進行)
mkdir ~/hadoopdata
gedit etc/hadoop/core-site.xml
用以下程式碼覆蓋檔案內容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/liu/hadoopdata</value>
</property>
</configuration>
配置hdfs-site.xml
gedit etc/hadoop/hdfs-site.xml
用以下程式碼覆蓋檔案內容:
<?xml version=”1.0” encoding=”UTF-8”?>
<?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置yarn-site.xml
gedit etc/hadoop/yarn-site.xml
用以下程式碼覆蓋內容:
<?xml version=”1.0”?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
配置mapred-site.xml
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
(將前者複製並另存為後者)
gedit etc/hadoop/mapred-site.xml
用下面程式碼覆蓋:
<?xml version=”1.0”?>
<?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(注意:如果直接從word文件中拷貝過去後面hdfs格式化的時候會報錯,所以要把裡面version等後面的字串的引號重新寫一下)
配置slaves檔案
gedit etc/hadoop/slaves
用下面的程式碼替換內容
slave1
slave2
6. 配置從節點。
scp -r hadoop-2.6.5 [email protected]:~/
(-r是scp複製資料夾)
7. 配置系統檔案。分別在節點上以liu執行以下步驟:
gedit ~/.bash_profile
加入以下環境變數
export HADOOP_HOME=/home/liu/hadoop-2.6.5
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
source ~/.bash_profile
8. master節點下執行格式化命令:
hdfs namenode -format
沒有報error的話就是格式化成功了,有的話最好到stackoverflow等上面查下。
啟動hadoop,先cd ~/hadoop-2.6.5/,然後sbin/start-all.sh,提示輸入yes/no,輸入yes。
最後成功的話如圖5所示。
分別jps指令檢視程序,master有4個,slave有3個。正常啟動的話效果如圖5-7所示。
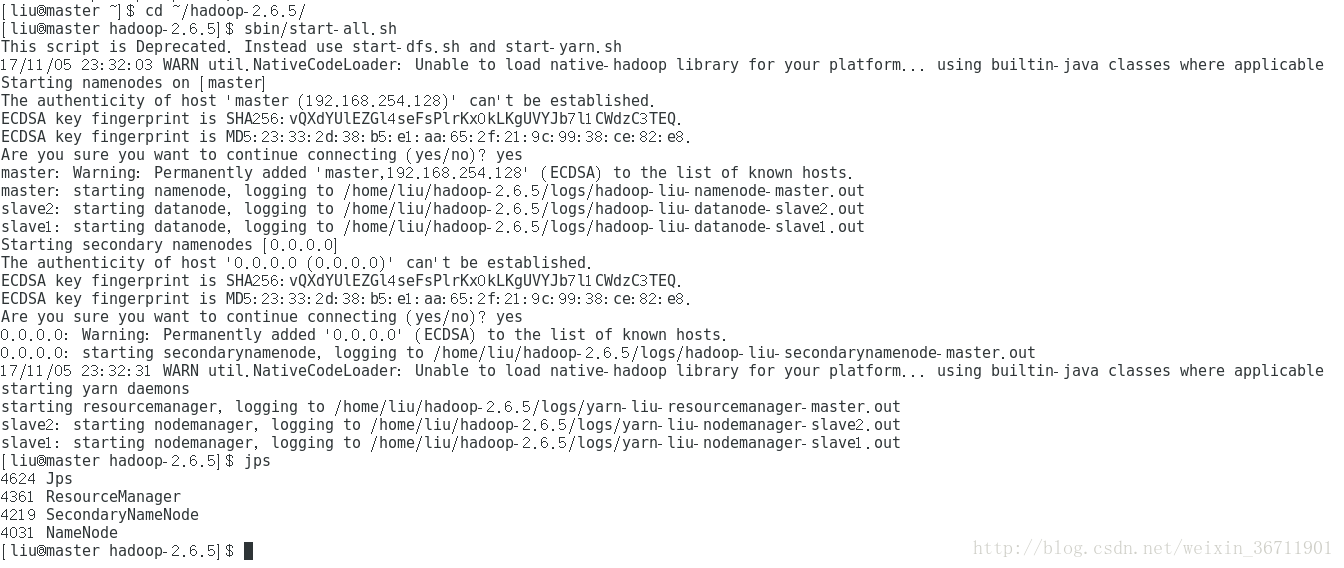
圖5

圖6

圖7
也可以通過web ui檢視叢集是否啟動,在master的firefox瀏覽器輸入
http://master:50070/,如圖8所示,namenode、datanode正常啟動。
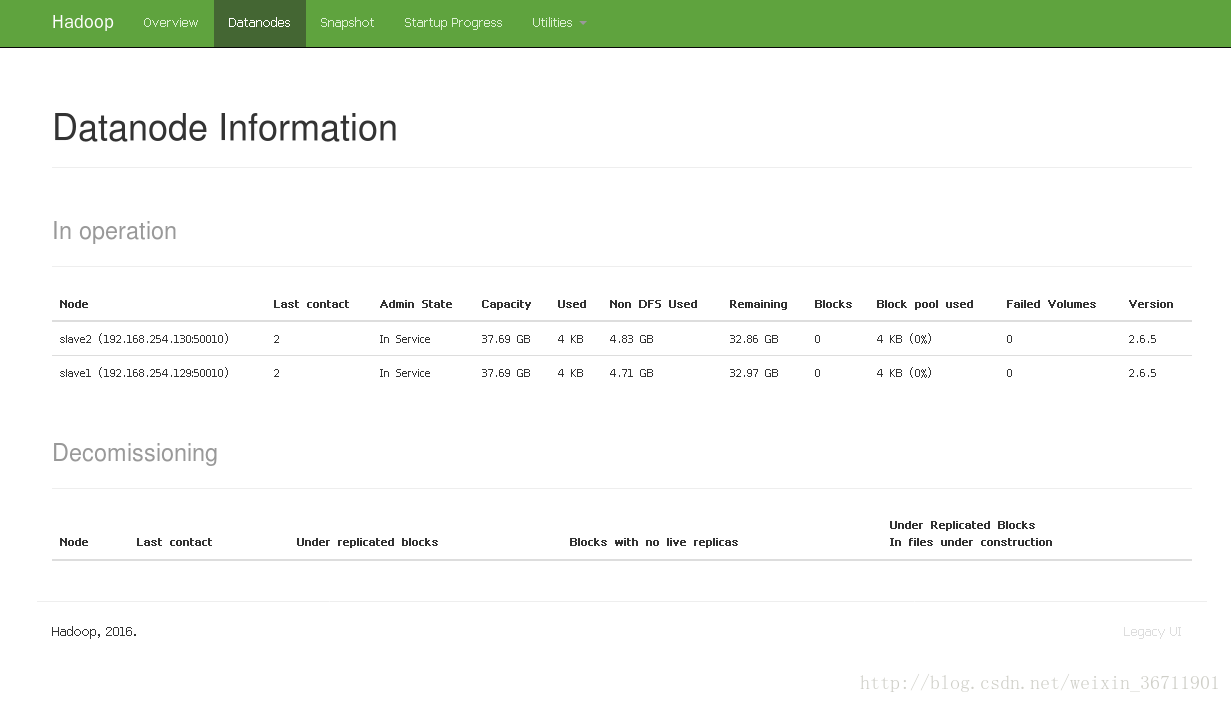
圖8
在master的firefox中輸入http://master:18088/檢查yarn是否正常啟動。

圖9
9. 安裝scala,在master節點tar -zxvf scala-2.12.4.tgz然後編輯環境變數。
gedit /home/liu/.bash_profile
新增下述語句:
export SCALA_HOME=/home/liu/scala-2.12.4
export PATH=$PATH:$SCALA_HOME/bin
使配置生效:
scource /home/liu/.bash_profile
將scala傳送至slave節點。
scp -r /home/liu/scala-2.12.4 slave1:/home/liu/
scp -r /home/liu/scala-2.12.4 slave2:/home/liu/
然後在slave節點上分別配置環境變數如前幾步所述。
配置完後驗證:


圖10
10. 安裝spark。Master的主目錄下tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz,然後
cd spark-2.2.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
gedit spark-env.sh
將以下程式碼加入到後面:
export SCALA_HOME=/home/liu/scala-2.12.4
export JAVA_HOME=//usr/java/jdk1.8.0_151
export HADOOP_HOME=/home/liu/hadoop-2.6.5
export HADOOP_CONF_DIR=/home/liu/hadoop-2.6.5/etc/hadoop
export SPARK_MASTER_IP=192.168.254.128
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
SPARK_WORKER_CORES:每個worker節點佔用的cpu核數目;SPARK_WORKER_INSTANCES:每臺機器或者ip節點開啟的worker節點數目;SPARK_WORKER_MEMORY:每個worker節點佔用的最大記憶體。
然後:
cp spark-defaults.conf.template spark-defaults.conf
gedit spark-defaults.conf
在後面新增程式碼:
spark.master=spark://192.168.254.128:7077
然後配置slaves
cp slaves.template slaves
gedit slaves
在salves後面將localhost改為slave節點的ip地址:
192.168.254.129
192.168.254.130
將spark資料夾分發至slave節點:
scp -r ~/spark-2.2.0-bin-hadoop2.7 slave1:~/
scp -r ~/spark-2.2.0-bin-hadoop2.7 slave2:~/
(每次scp傳送不成就要看看你的網路連線是不是斷了。。。)
最後在每臺機器上配置環境變數:
gedit /home/liu/.bash_profile
後面新增:
export SPARK_HOME=/home/liu/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
然後生效:
source /home/liu/.bash_profile
11. 啟動spark叢集。
cd spark-2.2.0-bin-hadoop2.7/sbin
start-all.sh
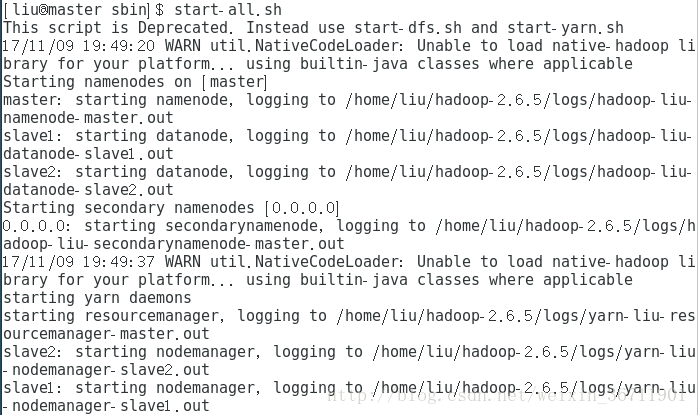
圖11
圖11即為啟動成功截圖。
同樣我們用jps來檢視程序。

圖12
如圖12所示。
也可以用spark-shell進一步檢視叢集的安裝情況。在bin下用spark-shell。

圖13
也可在web上檢視各節點狀況。如圖14-16所示。

圖14
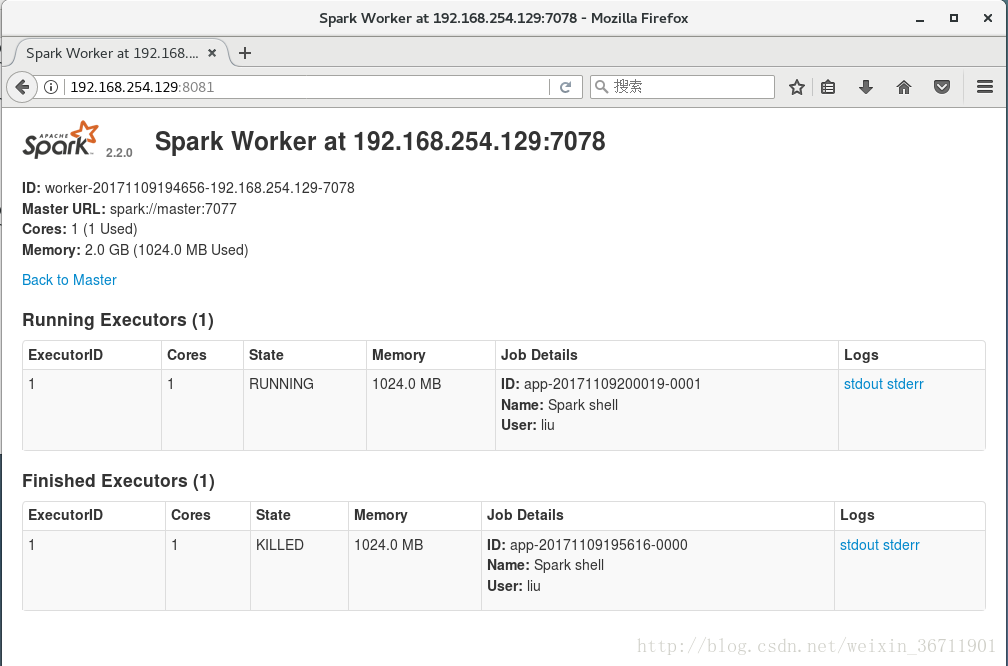
圖15
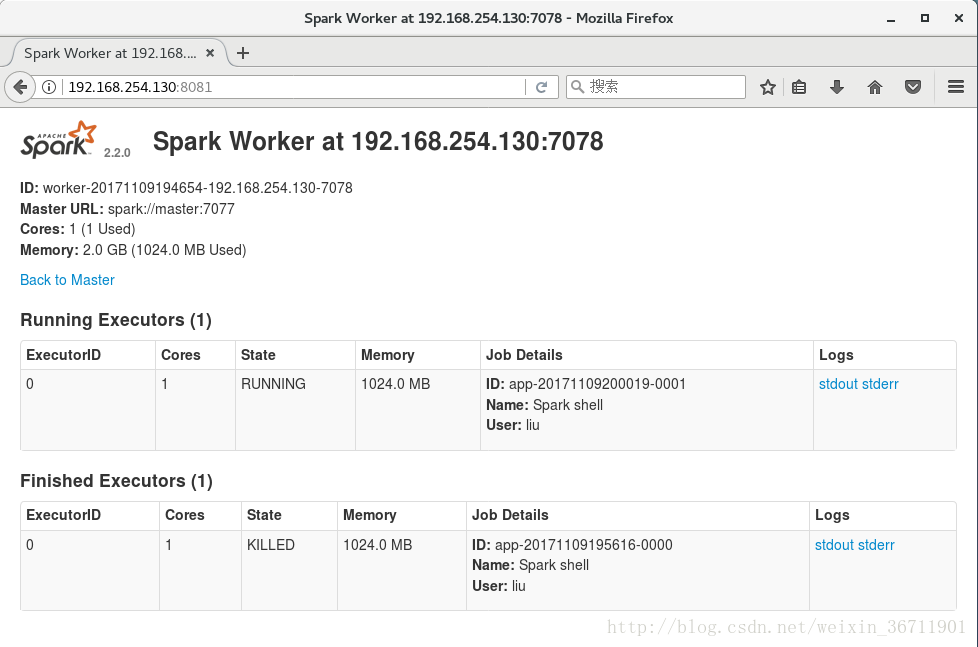
圖16
至此,standalone模式的spark叢集搭建完畢。
(如若發生網路介面卡啟動不起來,虛擬機器連不了網,是和NetworkManager服務有衝突按照以下步驟進行:service NetworkManager off,然後chkconfig NetworManager off,之後重啟即可。)