
python 繪圖及視覺化
除標準的圖表物件之外,你可能還希望繪製一些自定義的註釋(比如文字、箭頭或其他圖形等)。
註釋可以通過text、arrow和annotate等函式進行新增。text可以將文字繪製在圖表的指定座標(x, y),還可以加上一些自定義格式:
In [41]: ax.text(x, y, ‘Hello world!‘, family=‘monospace‘, fontsize=10)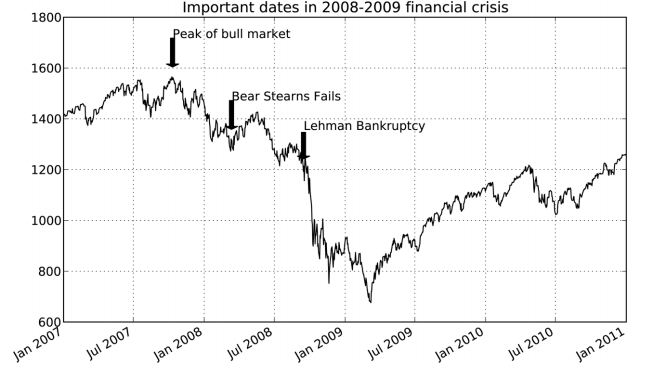
影象的繪製要麻煩一些。matplotlib有一些表示常見圖形的物件。這些物件被稱為塊(patch)。其中有些可以在matplotlib.pyplot中找到(如Rectangle和Circle),但完整集合位於matplotlib.patches。from datetime import datetime fig = plt.figure() ax = fig.add_subplot(1, 1, 1) data = pd.read_csv(‘ch08/spx.csv‘, index_col=0, parse_dates=True) spx = data[‘SPX‘] spx.plot(ax=ax, style=‘k-‘) crisis_data = [ (datetime(2007, 10, 11), ‘Peak of bull market‘), (datetime(2008, 3, 12), ‘Bear Stearns Fails‘), (datetime(2008, 9, 15), ‘Lehman Bankruptcy‘) ] for date, label in crisis_data: ax.annotate(label, xy=(date, spx.asof(date) + 50), xytext=(date, spx.asof(date) + 200), arrowprops=dict(facecolor=‘black‘), horizontalalignment=‘left‘, verticalalignment=‘top‘) # Zoom in on 2007-2010 ax.set_xlim([‘1/1/2007‘, ‘1/1/2011‘]) ax.set_ylim([600, 1800]) ax.set_title(‘Important dates in 2008-2009 financial crisis‘)
要在圖表中新增一個圖形,你需要建立一個塊物件shp,然後通過ax.add_patch(shp)將其新增到subplot中。
fig = plt.figure() ax = fig.add_subplot(1, 1, 1) rect = plt.Rectangle((0.2, 0.75), 0.4, 0.15, color=‘k‘, alpha=0.3) circ = plt.Circle((0.7, 0.2), 0.15, color=‘b‘, alpha=0.3) pgon = plt.Polygon([[0.15, 0.15], [0.35, 0.4], [0.2, 0.6]], color=‘g‘, alpha=0.5) ax.add_patch(rect) ax.add_patch(circ) ax.add_patch(pgon)
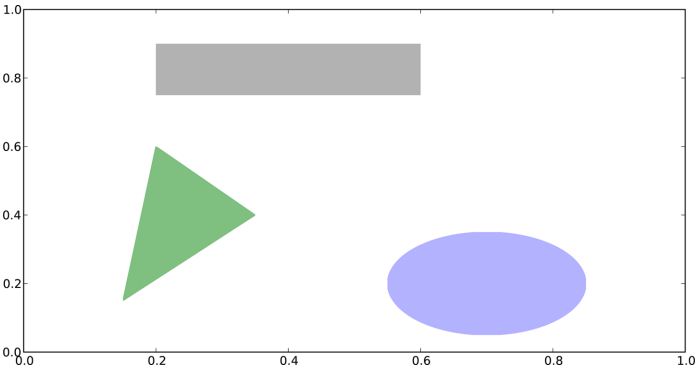
說明:
如果檢視許多常見圖表物件的具體實現程式碼,你就會發現它們其實就是由塊組裝而成的。
2、將圖表儲存到檔案
利用plt.savefig可以將當前圖表儲存到檔案。該方法相當於Figure物件的例項方法savefig。例如,要將圖表儲存為SVG檔案,你只需輸入:
In [42]: plt.savefig(‘figpath.svg‘)
檔案型別是通過副檔名推斷出來的。因此,如果你使用的是.gif,就會得到一個PDF檔案。我在釋出圖片時最常用到兩個重要的選項是dpi(控制“每英寸點數”解析度)和bbox_inches(可以翦除當前圖表周圍的空白部分)。要得到一張帶有最小白邊且解析度為400DPI的PNG圖片,你只需輸入:
In [43]: plt.savefig(‘figpath.svg‘, dpi=400, bbox_inches=‘tight‘)In [44]: from io import StringIO
In [45]: buffer = StringIO()
In [46]: plt.savefig(buffer)
In [47]: plot_data = buffer.getvalue()

3、matplotlib配置
matplotlib自帶一些配色方案,以及為生成出版質量的圖片而設定的預設配置資訊。幸運的是,幾乎所有預設行為都能通過一組全域性引數進行自定義,它們可以管理影象大小、subplot邊距、配色方案、字型大小、網格型別等。操作matplotlib配置系統的方式主要有兩種。第一種是Python程式設計方式,即利用rc方法。比如說,要將全域性的影象預設大小設定為1010,你可以執行:
In [45]: plt.rc(‘figure‘, figsize=(10, 10))
In [46]: font_options = {‘family‘ : ‘monospace‘, ‘weight‘ : ‘bold‘, ‘size‘ : ‘small‘}
In [47]: plt.rc(‘font‘, **font_options)
要了解全部的自定義選項,請查閱matplotlib的配置檔案matplotlibrc(位於matplotlib/mpl-data目錄中)。如果對該檔案進行了自定義,並將其放在你自己的.matplotlib目錄中,則每次使用matplotlib時就會載入該檔案。
4、pandas中的繪圖函式
不難看出,matplotlib實際上是一種比較低階的工具。要組裝一張圖表,你得用它的各種基礎元件才行:資料顯示(即圖表型別:線型圖、柱狀圖、盒形圖、散佈圖、等值線圖等)、圖例、標題、刻度標籤以及其他註解型資訊。這是因為要根據資料製作一張完整圖表通常都需要用到多個物件。在pandas中,我們有行標籤、列標籤以及分組資訊(可能有)。這也就是說,要製作一張完整的圖表,原本需要一大堆的matplotlib程式碼,現在只需要一兩條簡潔的語句就可以了。pandas有許多能夠利用DataFrame物件陣列組織特點來建立標準圖表的高階繪圖方法(這些函式的數量還在不斷增加)。
5、線型圖
Series和DataFrame都有一個用於生成各類圖表的plot方法。預設情況下,它們所生成的是線型圖:
In [47]: import pandas as pd
In [48]: s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
In [49]: s.plot()
Out[49]: <matplotlib.axes.AxesSubplot at 0xc8966ec>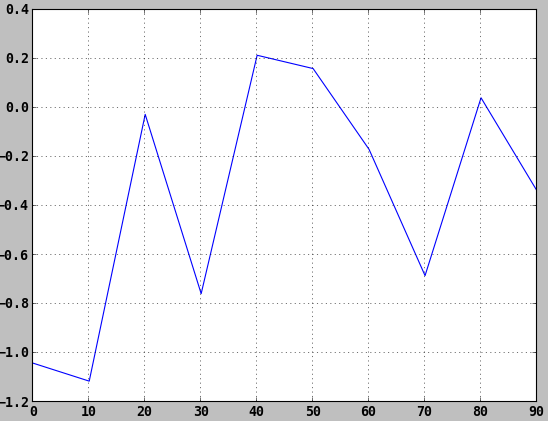
該Series物件的索引會被傳給matplotlib,並用以繪製X軸。可以通過use_index=False禁用該功能。X軸的刻度和界限可以通過xticks和xlim選項進行調節,Y軸就用yticks和ylim。plot引數的完整列表如下所示:


pandas的大部分繪圖方法都有一個可選的ax引數,它可以是一個matplotlib的subplot物件。這使你能夠在網格佈局中更為靈活地處理subplot的位置。
DataFrame的plot方法會在一個subplot中為各列繪製一條線,並自動建立圖例,如下所示:
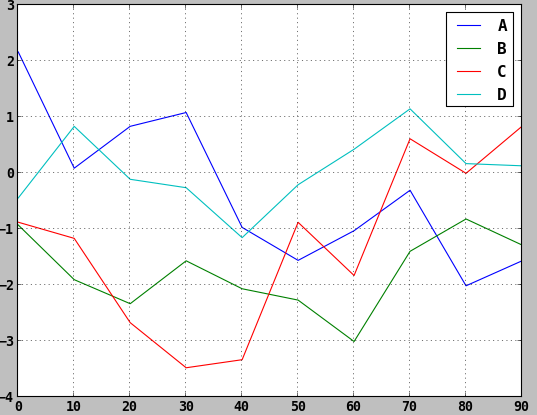
注意:
plot的其他關鍵字引數會被傳給相應的matplotlib繪圖函式,所以要更深入地自定義圖表,就必須學習更多有關matplotlib API的知識。
DataFrame還有一些用於對列進行靈活處理的選項,例如,是要將所有列都繪製到一個subplot中還是建立各自的subplot,詳細資訊如下所示:


6、柱狀圖
在生成線型圖的程式碼中加上kind=‘bar‘(垂直柱狀圖)或kind=‘barh‘(水平柱狀圖)即可生成柱狀圖。這時,Series和DataFrame的索引將會被用作X(bar)或Y(barh)刻度,如下所示:
In [55]: fig, axes = plt.subplots(2, 1)
In [56]: data = pd.Series(np.random.rand(16), index=list(‘abcdefghijklmnop‘))
In [57]: data.plot(kind=‘bar‘, ax=axes[0], color=‘k‘, alpha=0.7)
Out[57]: <matplotlib.axes.AxesSubplot at 0xcb6bb0c>
In [58]: data.plot(kind=‘barh‘, ax=axes[1], color=‘k‘, alpha=0.7)
Out[58]: <matplotlib.axes.AxesSubplot at 0xceeed0c>
對於DataFrame,柱狀圖會將每一行的值分為一組,如下所示:
In [60]: df = pd.DataFrame(np.random.rand(6, 4), index=[‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘five‘, ‘six‘], columns=pd.Index([‘A‘, ‘B‘, ‘C‘, ‘D‘], name=‘Genus‘))
In [61]: df.plot(kind=‘bar‘)
Out[61]: <matplotlib.axes.AxesSubplot at 0xb5ce6ac>
DataFrame各列的名稱“Genus”被用作了圖例的標題。設定stacked=True即可為DataFrame生成堆積柱狀圖,這樣每行的值就會被堆積在一起,如下所示:
In [62]: df.plot(kind=‘bar‘, stacked=True, alpla=0.5)柱狀圖有一個非常不錯的用法:利用value_counts圖形化顯示Series中各值的出現頻率,比如s.value_counts().plot(kind=‘bar‘)。
以小費資料集為例,假設我們想要做一張堆積柱狀圖以展示每天各種聚會規模的資料點的百分比。我用read_csv將資料載入進來,然後根據日期和聚會規模建立一張交叉表:
In [63]: tips = pd.read_csv(‘ch08/tips.csv‘)
In [64]: party_counts = pd.crosstab(tips.day, tips.size)
In [65]: party_counts
Out[65]:
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
# Not many 1- and 6-person parties
In [66]: party_counts = party_counts.ix[:, 2:5]
然後進行規格化,使得各行的和為1(必須轉換成浮點數,以避免Python 2.7中的整數除法問題),並生成圖表,如下所示:
# Normalize to sum to 1
In [68]: party_pcts = party_counts.div(party_counts.sum(1).astype(float), axis=0)
In [69]: party_pcts
Out[69]:
size 2 3 4 5
day
Fri 0.888889 0.055556 0.055556 0.000000
Sat 0.623529 0.211765 0.152941 0.011765
Sun 0.520000 0.200000 0.240000 0.040000
Thur 0.827586 0.068966 0.086207 0.017241
In [70]: party_pcts.plot(kind=‘bar‘, stacked=True)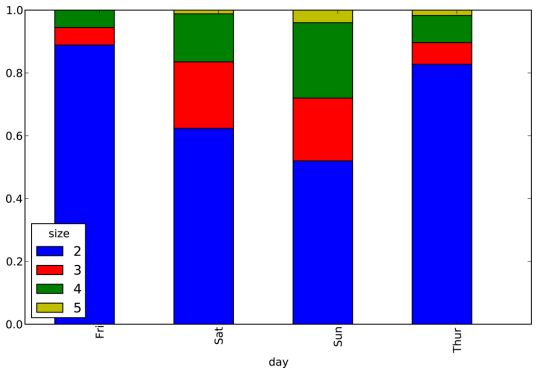
說明:
通過該資料集可以看出,聚會規模在週末就會變大。
7、直方圖和密度圖
直方圖(histogram)是一種可以對值頻率進行離散化顯示的柱狀圖。資料點被拆分到離散的、間隔均勻的面元中,繪製的是各面元中資料點的數量。再以前面那個小費資料為例,通過Series的hist方法,我們可以生成一張“小費佔消費總額百分比”的直方圖。
In [71]: tips[‘tip_pct‘] = tips[‘tip‘] / tips[‘total_bill‘]
In [72]: tips[‘tip_pct‘].hist(bins=50)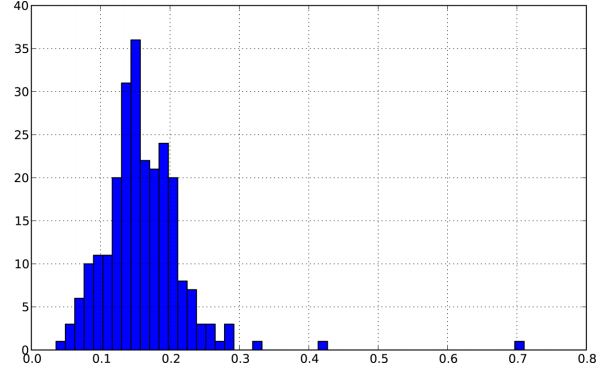
與此相關的一種圖表型別是密度圖,它是通過計算“可能會產生觀測資料的連續概率分佈的估計”而產生的。一般的過程是將該分佈近似為一組核(即諸如正態(高斯)分佈之類的較為簡單的分佈)。因此,密度圖也被稱作KDE(Kernel Density Estimate,核密度估計),如下所示:
In [73]: tips[‘tip_pct‘].plot(kind=‘kde‘)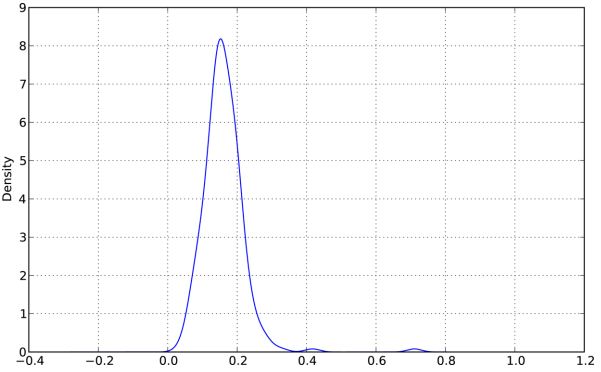
這兩種圖表常常會被畫在一起。直方圖以規格化形式給出(以便給出面元化密度),然後再在其上繪製核密度估計。接下來來看一個由兩個不同的標準正態分佈組成的雙峰分佈,如下所示:
In [74]: comp1 = np.random.normal(0, 1, size=200) # N(0, 1)
In [75]: comp2 = np.random.normal(10, 2, size=200) # N(10, 4)
In [76]: values = pd.Series(np.concatenate([comp1, comp2]))
In [77]: values.hist(bins=100, alpha=0.3, color=‘k‘, normed=True)
Out[77]: <matplotlib.axes.AxesSubplot at 0x5cd2350>
In [78]: values.plot(kind=‘kde‘, style=‘k--‘)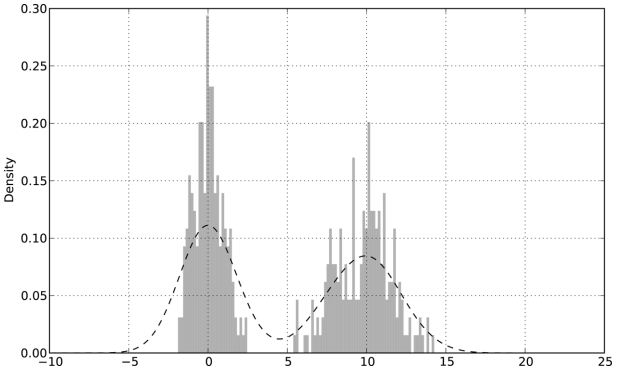
8、散佈圖
散佈圖(scatter plot)是觀察兩個一維陣列序列之間的關係的有效手段。matplotlib的scatter方法是繪製散佈圖的主要方法。在下面這個例子中,我載入了來自statsmodels專案的macrodata資料集,選擇其中幾列,然後計算對數差:
In [79]: macro = pd.read_csv(‘ch08/macrodata.csv‘)
In [80]: data = macro[[‘cpi‘, ‘m1‘, ‘tbilrate‘, ‘unemp‘]]
In [81]: trans_data = np.log(data).diff().dropna()
In [82]: trans_data[-5:]
Out[82]:
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560In [83]: plt.scatter(trans_data[‘m1‘], trans_data[‘unemp‘])
Out[83]: <matplotlib.collections.PathCollection at 0x43c31d0>
In [84]: plt.title(‘Changes in log %s vs. log %s‘ % (‘m1‘, ‘unemp‘))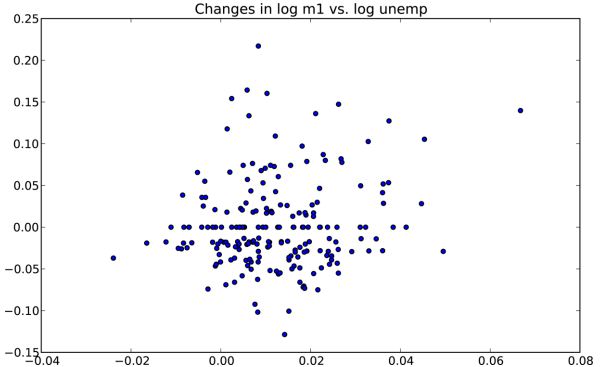
在探索式資料分析中,同時觀察一組變數的散佈圖是很有意義的,這也被稱為散佈圖矩陣(scatter plot matrix)。純手工建立這樣的圖表很費工夫,所以pandas提供了一個能從DataFrame建立散佈圖矩陣的scatter_matrix函式。它還支援在對角線上放置各變數的直方圖或密度圖。如下所示:
In [85]: scatter_matrix(trans_data, diagonal=‘kde‘, color=‘k‘, alpha=0.3)9、Python圖形化工具生態系統
(1)Chaco
Chaco(http://code.enthought.com/chaco/)是由Enthought開發的一個繪圖工具包,它既可以繪製靜態圖又可以生成互動式圖形。它非常適合用複雜的圖形化方式表達資料的內部關係。跟matplotlib相比,Chaco對互動的支援要好得多,而且渲染速度很快。如果要建立互動式的GUI應用程式,它確實是個不錯的選擇。
(2)mayavi
mayavi專案是一個基於開源C++圖形庫VKT的3D圖形工具包。跟matplotlib一樣,mayavi也能整合到IPython以實現互動式使用。通過滑鼠和鍵盤進行操作,圖形可以被平移、旋轉、縮放。我相信它能成為WebGL(以及相關產品)的替代品,雖然其生成的圖形很難以互動的形式共享。
(3)其他庫
當然,Python領域中還有許多其他的圖形化庫和應用程式:PyQwt、Veusz、gnuplotpy、biggles等。我就曾經見過PyQwt被用在基於Qt框架(PyQt)的GUI應用程式中。許多庫都還在不斷地發展(有些已經被用在大型應用程式當中了)。近幾年來,我發現了一個總體趨勢:大部分庫都在向基於Web的技術發展,並逐漸遠離桌面圖形技術。
(4)basemap工具集(http://matplotlib.github.com/basemap,matplotlib的一個外掛)使得我們能夠用Python在地圖上繪製2D資料。basemap提供了許多不同的地球投影以及一種將地球上的經緯度座標投影轉換為二維matplotlib圖的方式。
(5)圖形化工具的未來
基於Web技術(比如JavaScript)的圖形化是必然的發展趨勢。毫無疑問,許多基於Flash或JavaScript的靜態或互動式圖形化工具已經出現了很多年,而且類似的新工具包(如d3.js及其分支專案)一直都在不斷湧現。相比之下,非Web式的圖形化開發工作在近幾年中減慢了許多。Python以及其他資料分析和統計計算環境(如R)都是如此。於是,開發方向就變成了實現資料分析和準備工具(如pandas)與Web瀏覽器之間更為緊密的整合。
相關推薦
python 繪圖及視覺化
除標準的圖表物件之外,你可能還希望繪製一些自定義的註釋(比如文字、箭頭或其他圖形等)。 註釋可以通過text、arrow和annotate等函式進行新增。text可以將文字繪製在圖表的指定座標(x, y),還可以加上一些自定義格式: In [41]: ax.text(
利用Python進行資料分析——第8章繪圖及視覺化——學習筆記Python3 5.0.0
matplotlib API 入門 matplotlib API 函式(如plot和close)都位於matplotlib.pyplot模組中,通常的引入方式如下: import matplotlib.pyplot as plt Figure和Subplot matplot
python繪圖與視覺化--matplotlib
主要用來記錄《利用python進行資料分析》一書第8章 繪圖與視覺化 matplotlib繪圖 1. 載入模組: %matplotlib inline import numpy as np import matplotlib.pyplot as plt 在jupy
利用Python進行資料分析——繪圖和視覺化(八)(2)
1、註釋以及在Subplot上繪圖 除標準的圖表物件之外,你可能還希望繪製一些自定義的註釋(比如文字、箭頭或其他圖形等)。 註釋可以通過text、arrow和annotate等函式進行新增。text可以將文字繪製在圖表的指定座標(x, y),還可以加上一些自定義格式: In [41]: ax.t
【利用python進行資料分析】繪圖和視覺化
通常的引入約定是: import matplotlib.pyplot as plt fig,axes=plt.subplots(2,3) 這種用法,可以一下子產生2x3個子視窗,並且以numpy陣列的方式儲存在axes中,而fig仍然是整個影象物件,這樣我們可以通過對a
智聯Python相關職位的資料分析及視覺化-Pandas&Matplotlib篇 python
Numpy(Numerical Python的簡稱)是Python科學計算的基礎包。它提供了以下功能: 快速高效的多維陣列物件ndarray。 用於對陣列執行元素級計算以及直接對陣列執行數學運算的函式。 用於讀寫硬碟上基於陣列的資料集的工具。 線性代數運算、傅立
python資料分析07--matplotlib繪圖和視覺化
python資料分析07–matplotlib繪圖和視覺化 一、簡介 資訊視覺化(也叫繪圖)是資料分析中最重要的工作之一。它可能是探索過程的一部分,例 如,幫助我們找出異常值、必要的資料轉換、得出有關模型的idea等。另外,做一個可互動的 資料視覺化也許是工作的最終目標。 m
Python資料分析及視覺化的基本環境
首先搭建基本環境,假設已經有Python執行環境。然後需要裝上一些通用的基本庫,如numpy, scipy用以數值計算,pandas用以資料分析,matplotlib/Bokeh/Seaborn用來資料視覺化。再按需裝上資料獲取的庫,如Tushare(http://pyth
利用python進行資料分析之繪圖和視覺化
matplotlib API入門 使用matplotlib的辦法最常用的方式是pylab的ipython,pylab模式還會向ipython引入一大堆模組和函式提供一種更接近與matlab的介面,matplotlib API函式位於matplotlib.pyplot模組中,其通常的引入約定是:import
python之matplotlib實現繪圖和視覺化
繪圖是資料分析工作中最重要的任務之一,是探索過程的一部分。python為我們提供了許多視覺化工具,最常用的的是matplotlib。matplotlib是一種用於創建出版質量圖示的桌面繪圖包(主要是2D方面),它為python構建了一個MATLAB式的繪圖介面。它不僅支援各種
轉載]利用Python進行資料分析——繪圖和視覺化 xticks-學習筆記
matplotlib是一個用於創建出版質量圖表的桌面繪圖包(主要是2D方面)。該專案是由John Hunter於2002年啟動的,其目的是為Python構建一個MATLAB式的繪圖介面。如果結合使用一種GUI工具包(如IPython),matplotlib還具有諸如縮放和平移等互動功能。它不僅支援各種作業系
《利用Python進行資料分析·第2版》第9章 繪圖和視覺化
資訊視覺化(也叫繪圖)是資料分析中最重要的工作之一。它可能是探索過程的一部分,例如,幫助我們找出異常值、必要的資料轉換、得出有關模型的 idea 等。另外,做一個可互動的資料視覺化也許是工作的最終目標。Python 有許多庫進行靜態或動態的資料視覺化,但我這裡重要關注於 ma
利用python進行資料分析-繪圖和視覺化1
matplotlib AIP入門 1.Figure和Subplot matplotlib的影象都位於Figure物件中。你可以用plt.figure建立一個新的Figure: fig=plt.figu
Python及視覺化工具PyCharm 的安裝
Python的介紹 是一種計算機程式設計語言。是一種面向物件的動態型別語言 。 可以應用於以下領域: Web 和 Internet
Zoookeeper及視覺化UI的部署
首先介紹一下Zookeeper,Zookeeper作為一個分散式的服務框架,主要用來解決分散式叢集中應用系統的一致性問題,它能提供基於類似於檔案系統的目錄節點樹方式的資料儲存. Zookeeper的安裝 ①Zookeeper下載 選擇合適的版本進行下載即可 [root@node-
caffe Python API 之視覺化
一、顯示各層 # params顯示:layer名,w,b for layer_name, param in net.params.items(): print layer_name + '\t' + str(param[0].data.shape), str(param[1].data.sha
pandas 繪圖和視覺化
1. matplotlib api 入門 matplotlib api 函式都位於maptplotlib.pyplot模組中 畫圖的各種方法: Figure:畫圖視窗 Subplot/add_Subplot: 建立一個或多個子圖 Subplots_adjust:調整
空間相互作用資料探勘及視覺化分析相關文章綜述
祝曦在“海量空間相互作用資料探勘及視覺化”中提出了 一種從大規模空間相互作用資料中提煉地理特徵資訊的方法,主要步驟包括:將空間點聚合成類,計算統計量度,然後視覺化統計量度來發現時空模式。文中將該方法作用在一組計程車資料上,這一組計程車資料描述中國深圳市的 2331
python之資料視覺化
各種圖形簡介 線性圖:plt.plot(x,y,*argv) 條形圖:plt.bar(x,y)x和y的長度應相等 水平條形圖:plt.barh(x,y)x軸成垂直,y軸水平而已 條形圖高度表示某專案內的資料個數,由於分組資料具有連續性,直方圖的各矩形通常是連續排列,而條形圖則是分開排
【機器學習】決策樹剪枝優化及視覺化
前言 \quad\quad 前面,我們介紹了分類決策樹的實現,以及用 sklearn 庫中的 DecisionTre