
基於centos的Hadoop2.x環境搭建
hadoop2.0環境搭建
1.安裝vmware
這裡就不介紹如何安裝了,不清楚可在網上找一些教程
2.vmware安裝centos6
2.1centos系統安裝
開啟vmware 點選檔案 ,點選檔案 ->新建虛擬機器 新建虛擬機器
選擇“典型”點選“下一步”
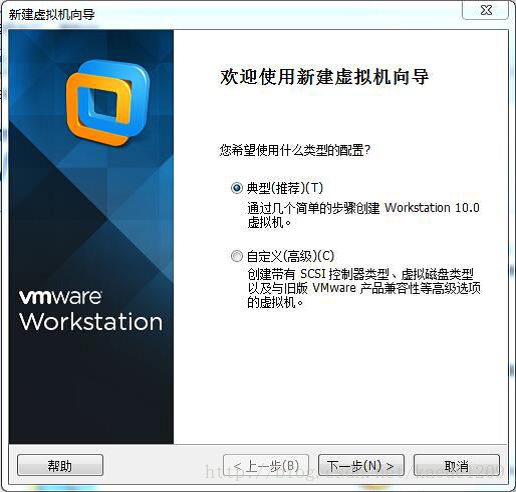
選擇“安裝程式光碟映像檔案”,選擇指定的centos系統的iso檔案,點選下一步
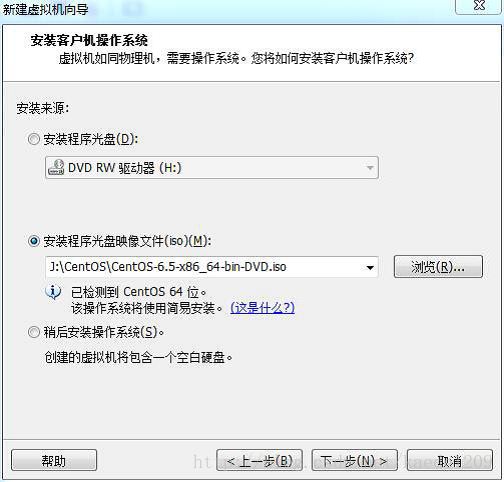
填寫一下資訊。點選下一步
例如 全名:zkpk 密碼:zkpk 確認:zkpk
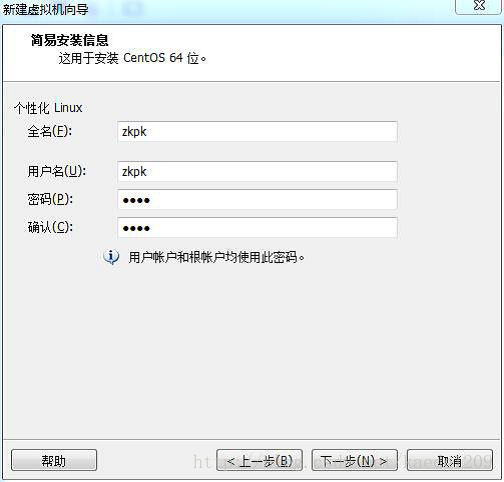
虛擬機器名稱:HadoopMaster 選擇安裝位置,點選下一步
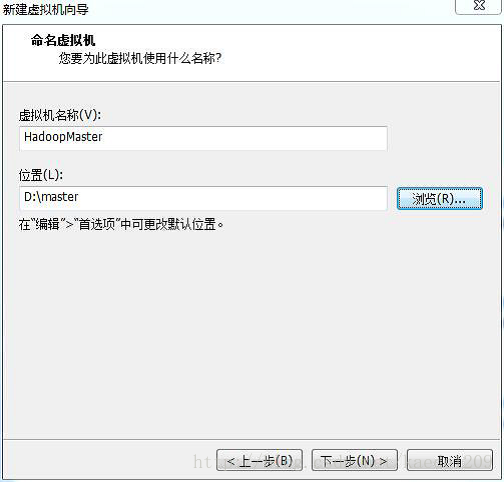
磁碟大小可選擇預設值也可以調大。
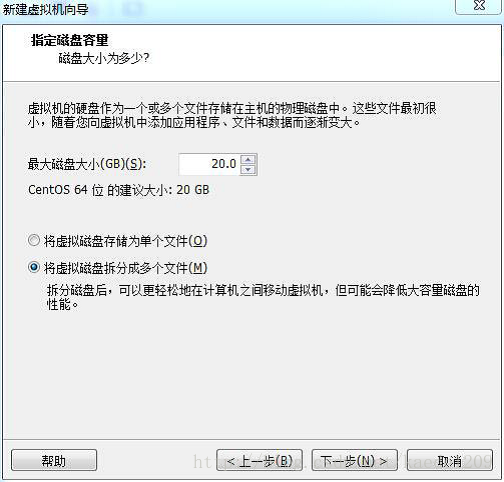
進入下面頁面:
等待安裝完成,系統自動重啟

輸入密碼登入系統

系統安裝完畢
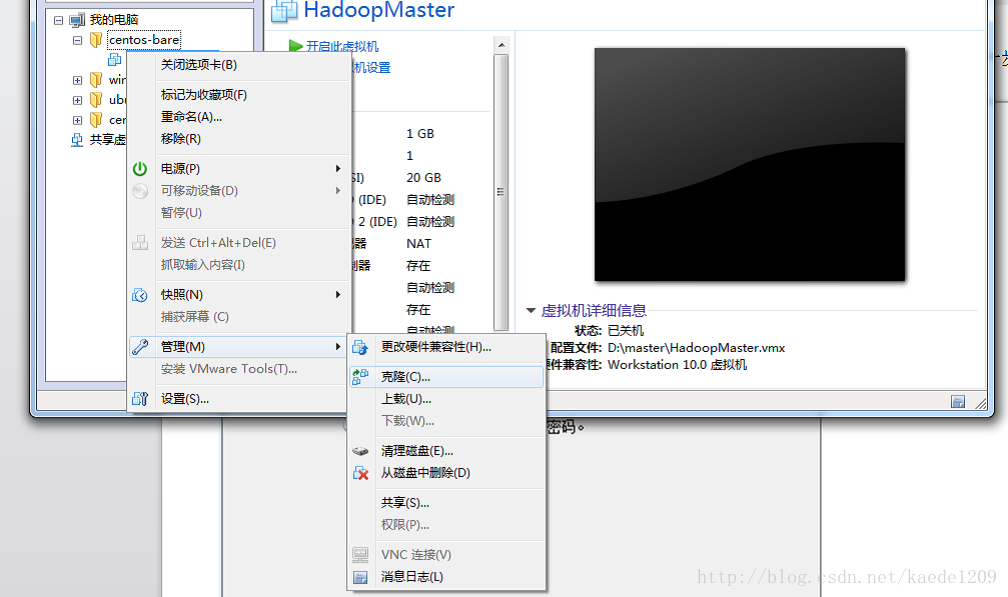
克隆HadoopSlave
點選下圖所示的“克隆”選項
點選下一步看到如下介面
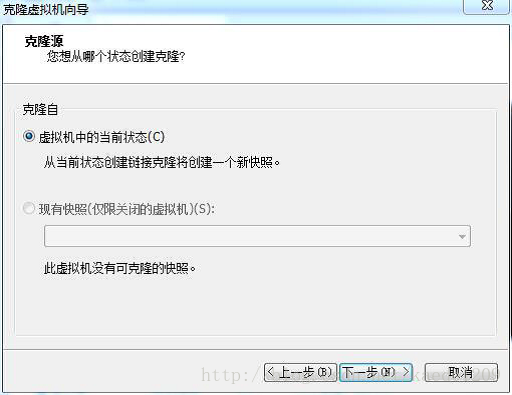
使用預設選項,點選下一步,選擇建立完整克隆,點選下一步,如圖所示
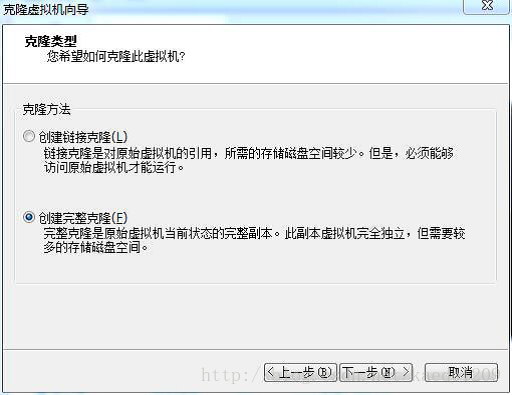
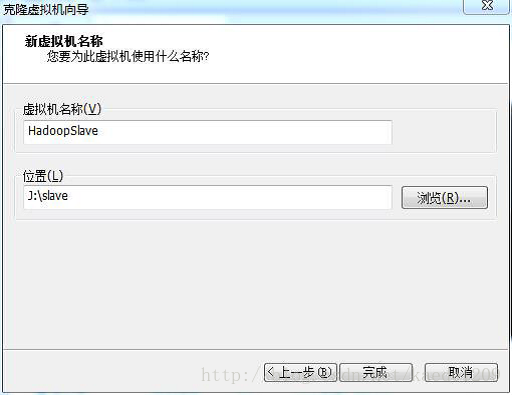
將虛擬機器重新命名為HadoopSlave,選擇一個儲存位置(10G)點選完成
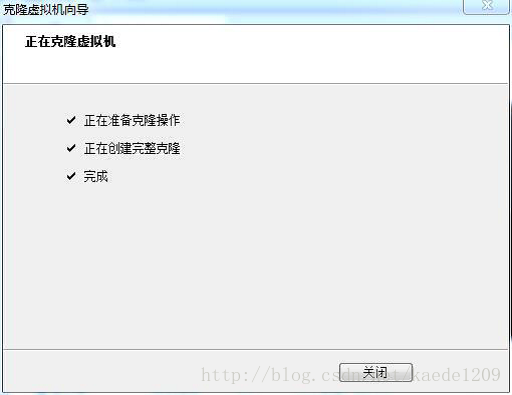
完成克隆
可以用xshell連線虛擬機器,xftp傳輸檔案到虛擬機器。
3 centos安裝Hadoop
3.1 Linux系統配置
一下操作步驟需要在HadoopMaster和HadoopSlave節點上分別完成操作,都使用root使用者,從當前切換root使用者的命令如下:
[[email protected] ~]$ su root
輸入密碼:zkpk
本節所有的命令都在終端環境,開啟終端的過程如下,或者使用xshell
3.2.1 軟體包和資料包說明
將完整的軟體包“/home/zkpk/resources”下的software是相關的安裝軟體包。
3.2.2配置主機名
1、HadoopMaster節點
使用vim編輯主機名
[[email protected] zkpk]$ vi /etc/sysconfig/network
或者使用gedit命令直接編輯。
配置資訊如下:
NETWORKING=yes #啟動網路 HOSTNAME=master #主機名
確定修改生效命令:
[[email protected] zkpk]$ hostname master
檢測主機名是否修改成功命令如下,在操作之前需要關閉當前終端,開啟新的終端:
[[email protected] zkpk]$ hostname
執行完命令,會看到如下的列印輸出:

2、HadoopSlave節點
使用gedit編輯主機名:
[[email protected] zkpk]$ gedit /etc/sysconfig/network
配置資訊如下:
NETWORKING=yes #啟動網路
HOSTNAME=slave #主機名
確定修改生效命令:
[[email protected] zkpk]$ hostname slave
檢測主機名是否修改如前面所示。
3.2.3使用setup 命令配置網路環境
以下操作也需要在slave階段進行
在終端執行命令:
[[email protected] ~]$ ifconfig
如果看到如下,即存在內網ip、廣播地址、子網掩碼,說明不需要配置網路
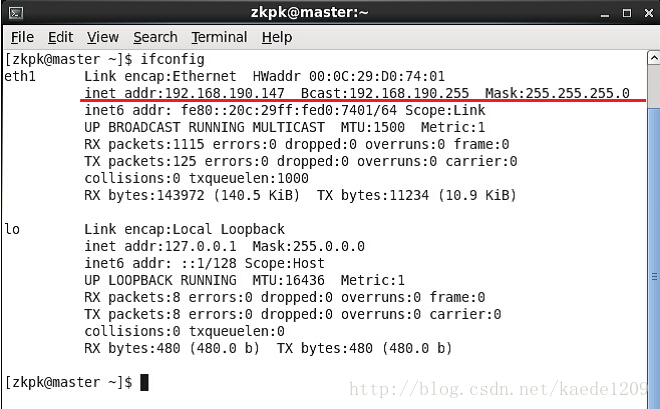
3.2.4 關閉防火牆
以下操作也需要在slave階段進行
輸入如下命令:
開啟: chkconfig iptables on
關閉: chkconfig iptables off
3.2.5 配置host列表
以下操作也需要在slave階段進行
需要在root使用者下,編輯主機名列表的命令:
[[email protected] zkpk]$ gedit /etc/hosts
將下面兩行新增到/etc/hosts檔案中:
192.168.1.100 master
192.168.1.101 slave
注意:這裡master節點的ip地址是192.168.1.100,slave對應的ip是192.168.1.101,而自己在做配置時,需要將兩個ip地址改為你的master和slave對應的ip地址。
驗證是否配置成功命令如下:
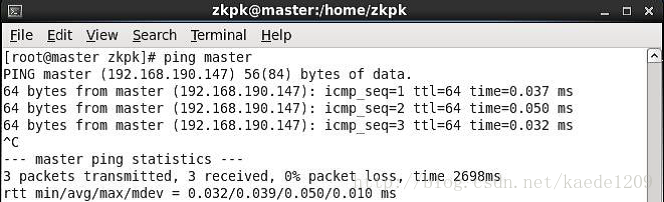
[[email protected] ~]$ ping master
[[email protected] ~]$ ping slave
ping通則表示配置成功如下:
如下則表示配置失敗:

3.2.6安裝JDK
以下操作也需要在slave階段進行
將JDK檔案解壓,放到/user/java目錄下
[[email protected] ~]$ cd /home/zkpk/resources/software/jdk
[[email protected] jdk]$ mkdir /usr/java
[[email protected] jdk]$ cd /usr/java
[[email protected] java]$ tar -xvf /usr/java/jdk-7u71-linux-x64.gz
使用gedit配置環境變數
[[email protected] java]$ gedit /home/zkpk/.bash_profile
複製貼上以下內容新增到上面gedit開啟的檔案中:
export JAVA_HOME=/usr/java/jdk1.7.0_71/
export PATH=$JAVA_HOME/bin:$PATH
使改動生效命令:
[[email protected] java]$ source /home/zkpk/.bash_profile
測試配置:
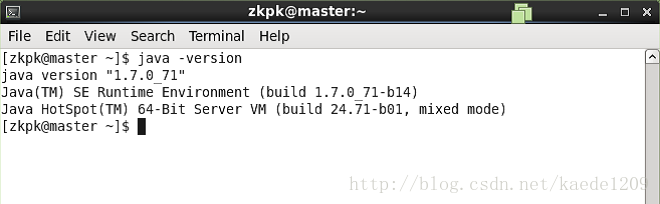
[[email protected] ~]$ java -version
出現如下表示jdk安裝成功:
3.2.7免金鑰登入配置
以下需要在普通使用者下完成
1、HadoopMaster節點
在終端生成金鑰,命令如下:
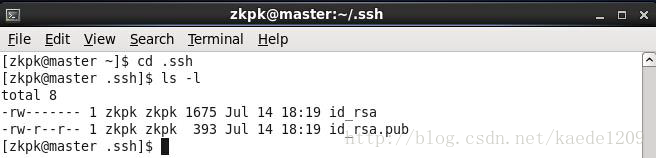
[[email protected] ~]$ ssh-keygen -t rsa
生成的金鑰在.ssh目錄下如下圖所示:
複製公鑰檔案
[[email protected] .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
執行ll命令可以看到如下圖所示

修改authorized_keys檔案的許可權,命令如下:
[[email protected] .ssh]$ chmod 600 ~/.ssh/authorized_keys
修改完許可權,檢視檔案列表如下:

將authorized_keys檔案複製到slave節點,命令如下:
[[email protected] .ssh]$ scp ~/.ssh/authorized_keys [email protected]:~/
如果有提示yes/no時,輸入yes,回車。
2、HadoopSlave節點
在終端生成金鑰,命令如下(一直點選回車生成金鑰)
[[email protected] ~]$ ssh-keygen -t rsa
將authorized_keys檔案移動到.ssh目錄
[[email protected] ~]$ mv authorized_keys ~/.ssh/
修改authorized_keys檔案的許可權,命令如下:
[[email protected] ~]$ cd ~/.ssh
[[email protected] .ssh]$ chmod 600 authorized_keys
3、驗證免金鑰登陸
在HadoopMaster機器上執行下面的命令:
[[email protected] ~]$ ssh slave
如果出現如下則表示成功:

3.3Hadoop配置部署
每個節點上的Hadoop配置基本相同,在HadoopMaster節點操作,然後完成複製到另一個節點。將Hadoop的安裝包放到Linux環境下
3.3.1 Hadoop安裝包解壓
進入Hadoop軟體包,命令如下:
[[email protected] ~]$ cd /home/zkpk/resources/software/hadoop/apache
複製並解壓Hadoop安裝包命令如下:
[[email protected] apache]$ cp ~//resources/software/hadoop/apache/hadoop-2.5.2.tar.gz ~/
[[email protected] apache]$ cd
[[email protected] ~]$ tar -xvf ~/hadoop-2.5.2.tar.gz
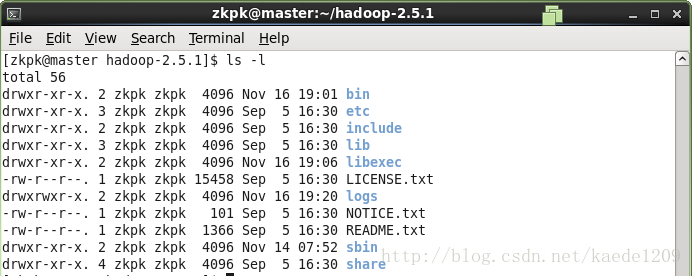
[[email protected] ~]$ cd ~/hadoop-2.5.2
ls -檢視如下內容,表示解壓成功
3.3.2配置環境變數hadoop-env.sh
環境變數檔案中,只需要配置JDK的路徑
[[email protected] hadoop-2.5.2]$ gedit /home/zkpk/hadoop-2.5.2/etc/hadoop/hadoop-env.sh
在檔案的靠前的部分找到下面的一行程式碼:
export JAVA_HOME=${JAVA_HOME}
將這行程式碼修改為下面的程式碼:
export JAVA_HOME=/usr/java/jdk1.7.0_71/
3.3.3配置環境變數yarn-env.sh
環境變數檔案中,只需要配置jdk的路徑。
[[email protected] hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/yarn-env.sh
在檔案的靠前的部分找到下面的一行程式碼:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
將這行程式碼修改為下面的程式碼:
export JAVA_HOME=/usr/java/jdk1.7.0_71/
3.3.4配置核心元件core-site.xml
使用gedit編輯:
[[email protected] hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/core-site.xml
用下面的程式碼替換core-site.xml中的內容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zkpk/hadoopdata</value>
</property>
</configuration>
3.3.5配置檔案系統hdfs-site.xml
使用gedit編輯:
[[email protected] hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/hdfs-site.xml
用下面的程式碼替換:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.3.6配置檔案系統yarn-site.xml
使用gedit編輯:
[[email protected] hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/yarn-site.xml
用一下內容替換:
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property> <name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property> <name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property> <name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property> <name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
3.3.7配置計算框架mapred-site.xml
將/mapred-site.xml.template檔案改名為/mapred-site.xml
[[email protected] ~]$mv /mapred-site.xml.template /mapred-site.xml
用以下內容代替:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property> <name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.3.8 在master節點配置slaves檔案
使用gedit命令:
[[email protected] hadoop-2.5.2]$ gedit ~/hadoop-2.5.2/etc/hadoop/slaves
用如下內容代替:
slave
3.3.9 複製到從節點
使用以下命令將已經配置完成的Hadoop複製到從節點HadoopSlave上:
[[email protected] hadoop-2.5.2]$ cd
[[email protected] ~]$ scp -r hadoop-2.5.2 [email protected]:~/
注意:因為之前配置了免金鑰登入,所以可以直接遠端複製。
3.4 啟動Hadoop叢集
3.4.1 配置Hadoop啟動的系統環境變數
需要同時在兩個節點上進行操作,命令如下:
[[email protected] hadoop-2.5.2]$ cd
[[email protected] ~]$ gedit ~/.bash_profile
在末尾新增如下內容:
#HADOOP
export HADOOP_HOME=/home/zkpk/hadoop-2.5.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然後執行命令:
[[email protected] ~]$ source ~/.bash_profile
3.4.2啟動Hadoop叢集
1、格式化檔案系統
在HadoopMaster節點上操作:
[[email protected] ~]$ hdfs namenode -format
如下圖表示成功:
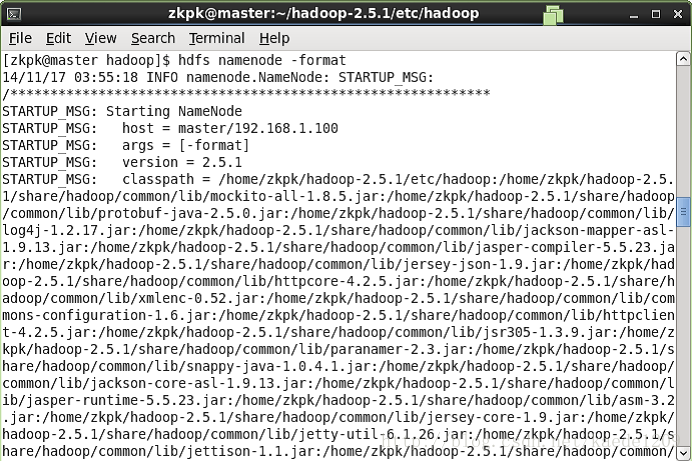
2、啟動Hadoop
使用如下命令啟動Hadoop
[[email protected] ~]$ cd ~/hadoop-2.5.2
[[email protected] hadoop-2.5.2]$ sbin/start-all.sh
此命令顯示已經過時,也可用其他方式啟動Hadoop
3、檢視程序是否啟動
在HadoopMaster上面執行命令jps會看到四個程序如下圖:
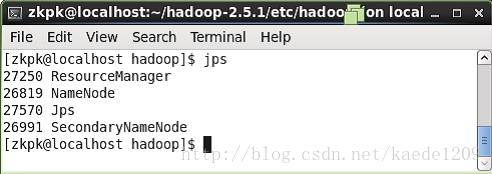
在HadoopSlave節點上執行jps會看到上三個程序如下:
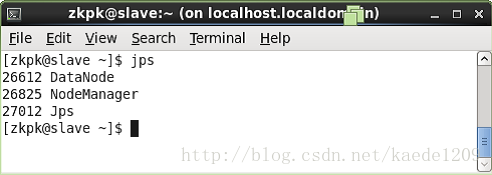
4、Web UI檢視叢集是否成功啟動
開啟瀏覽器,輸入網址http://master:50070/ 進入如下頁面
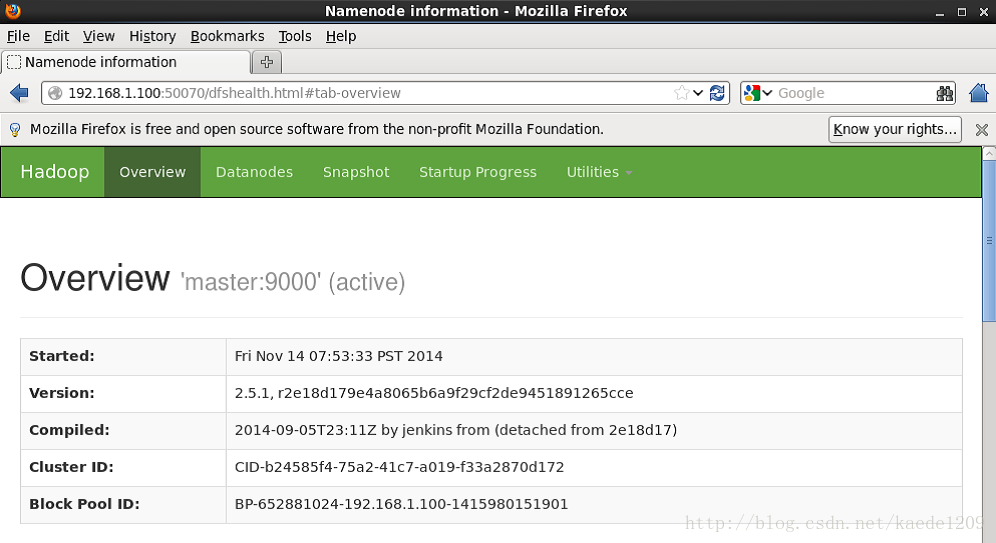
輸入網址http://master:18088/ ,檢查yarn是否正常,以及MapReduce程式執行情況等,頁面如下:
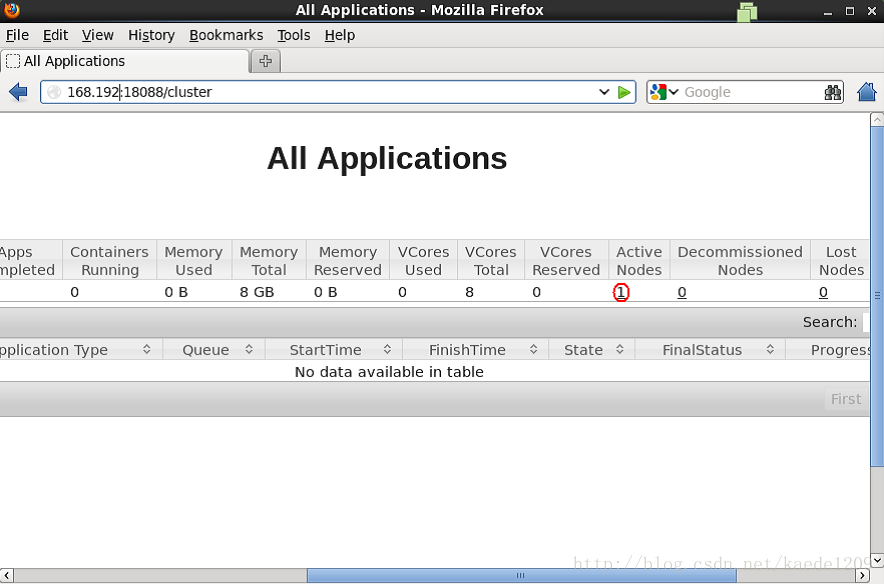
5、執行PI例項檢查叢集是否成功
進入Hadoop安裝的目錄,以下命令:
[[email protected] ~]$ cd ~/hadoop-2.5.2/share/hadoop/mapreduce/
會看到如下結果:
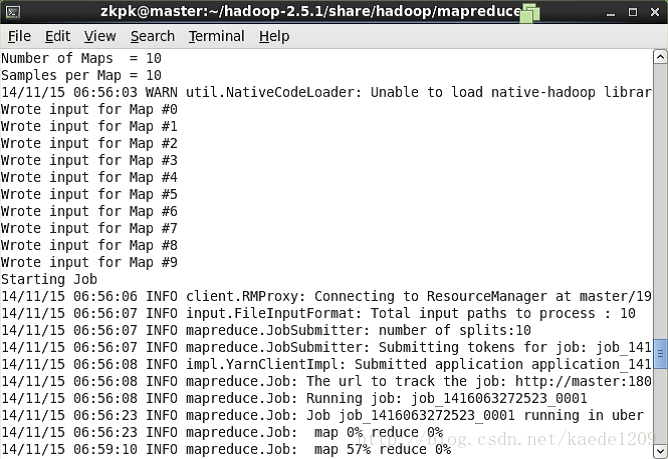
最後輸出:
Estimated value of pi is 3.20000000000000
說明叢集正常啟動
Hadoop安裝完成
相關推薦
基於centos6.x環境下GRE隧道的搭建及分析
gre GRE一、網絡拓撲二、環境介紹所有服務器系統均是centos6.5,內核:2.6.32-431.el6.x86_64centos1:一張網卡eth1:192.168.10.10,gw:192.168.10.1,僅主機vmnet1R:兩張網卡eth0:192.168.20.1,僅主機vmnet2
基於centos的Hadoop2.x環境搭建
hadoop2.0環境搭建 1.安裝vmware 這裡就不介紹如何安裝了,不清楚可在網上找一些教程 2.vmware安裝centos6 2.1centos系統安裝 開啟vmware 點選檔案 ,點選檔案 ->新建虛擬機器 新建虛擬機器
elk5.x環境搭建與常用插件安裝
elk ELK 5.X 環境搭建與常用插件安裝環境介紹:ip: 192.168.250.131os: CentOS 7.1.1503 (Core)內存不要給的太低,至少4G吧,否則elasticsearch啟動會報錯。軟件及其版本 這裏軟件包都解壓在了/opt下,註意!logstash-
[原創]基於Zynq Linux環境搭建(二)
alt boa per inux class arch can 解壓 arc 在此篇,我們編譯UBOOT 解壓: [#17#17:26:56 FPGADeveloper@ubuntu ~/Zybo_Demo]$tar zxvf *.tar.gz 在
[原創]基於Zynq Linux環境搭建(一)
ans develop sharp ftw load 生效 bubuko hive path 安裝VMWare版本12 Ubuntu版本 12.04.5 64bit 系統安裝完成後,登陸系統,在sotfware中心安裝konsole、gvim、softwa
[原創]基於Zynq Linux環境搭建(三)
linux ubuntu 完成後 light 重啟 dtc defcon man ubun 此篇編譯Kernel 解壓: [#17#17:26:56 FPGADeveloper@ubuntu ~/Zybo_Demo]$tar zxvf *.tar.gz
nexus3.X環境搭建
好的 分享圖片 code blog 進制 sonatype alt nat prop nexus3比以前的版本相比 多支持了管理不同的格式 比如Docker npm NuGet maven …等 下載編譯好的二進制安裝 wget https://sonatype-down
初探AngularJS6.x---環境搭建
目的 完成 verify tex nodejs src 568B ase fse 初探AngularJS6.x---環境搭建 *近期做項目,正好用到了AngularJS,所以就想著趕快整理成博文,避免回頭給忘了.第一次接觸AngularJS是兩年前,那會兒公司用的是Boot
SpringMVC 4.X環境搭建
Spring MVC 提供了一個DispatcherServlet來開發Web應用。在Servlet2.5及以下的時候,只要在web.xml下配置<Servlet>元素即可。但現在我們可以使用Servlet3.0+無web.xml的配置方式,在Spring MVC裡實現WebApplic
Visual Studio基於QT介面 環境搭建
以Visual Studio2013和Qt5.6.0 32位為例 步驟: 安裝Visual Studio 2013; 安裝Qt5.6.0 安裝QTVS Tools VS配置Qt版本 測試環境 操作 第一步 安裝Visual Studio 2013 下載Vis
基於Zynq Linux環境搭建(四)
https://www.cnblogs.com/ifpga/p/8182036.html 此篇編譯根檔案系統 下載busybox和dropbear, 1 2 3 4 5 6 7 8 9 10 11 12 13 [#73#13:04
基於Zynq Linux環境搭建(三)
https://www.cnblogs.com/ifpga/p/8182029.html 此篇編譯Kernel 解壓: 1 [#17#17:26:56 [email protected] ~/Zybo_Demo]$tar
基於Zynq Linux環境搭建(二)
https://www.cnblogs.com/ifpga/p/8182025.html 在此篇,我們編譯UBOOT 解壓: 1 [#17#17:26:56 [email protected] ~/Zybo_Demo]$tar zxvf
基於Zynq Linux環境搭建(一)
https://www.cnblogs.com/ifpga/p/8182021.html 安裝VMWare的版本12 Ubuntu版本12.04.5 64bit 系統安裝完成後,登陸系統,在sotfware中心安裝konsole,gvim,軟體源等基本軟體
Redis叢集:Redis3.X環境搭建、查詢叢集資訊
redis叢集 ruby環境 redis叢集管理工具redis-trib.rb依賴ruby環境,首先需要安裝ruby環境: 安裝ruby yum install ruby yum install rubyg
JavaEE開發之基於Eclipse的環境搭建以及Maven Web App的建立
本篇部落格就完整的來聊一下如何在Eclipse中建立的Maven Project。本篇部落格是JavaEE開發的開篇,也是基礎。本篇部落格的內容乾貨還是比較多的,而且比較實用,並且都是採用目前最新版本的工具來配置的環境。下方內容主要包括了JDK1.8的安裝、JavaEE版本的Eclipse的安裝、Maven的
【linux學習筆記--第一篇】基於nanopim2a的環境搭建,uboot編譯及下載
接觸一個星期,搭建了虛擬機器,雙系統,行動硬碟ubuntu , 總結下來, 行動硬碟的系統最方便,硬碟可以分為2個分割槽,一個裝系統, 一個放檔案(windows也可以識別),感覺還是挺爽的。 以下是這幾天折騰u-boot的一
Hadoop學習筆記—22.Hadoop2.x環境搭建與配置
自從2015年花了2個多月時間把Hadoop1.x的學習教程學習了一遍,對Hadoop這個神奇的小象有了一個初步的瞭解,還對每次學習的內容進行了總結,也形成了我的一個博文系列《Hadoop學習筆記系列》。其實,早在2014年Hadoop2.x版本就已經開始流行了起來,並且已經成為了現在的主流。當然,還有一些非
OpenGL學習01_Mac OS X環境搭建
Mac上搭建OpenGL環境比較簡單,我使用的是作業系統是Mac OS X 10.10版本,OpenGL版本是3.0/3.1,開發環境XCode6.1,參考的書籍《OpenGL程式設計指南》中文第七版。 一、使用XCode建立OpenGL專案 1.使用XCode建立專案,依
Hadoop 2.x環境搭建之單機執行模式配置
Hadoop的單機執行模式配置 目錄 1、linux 中的配置 a) Linux中修改主機名 b) 更改主機對映 (