
2017雙11技術揭祕—阿里資料庫進入全網秒級實時監控時代
前言
2017雙11再次創下了32.5萬筆/秒交易建立的紀錄,在這個數字後面,更是每秒多達幾千萬次的資料庫寫入,如何大規模進行自動化操作、保證資料庫的穩定性、快速發現問題是一個巨大的難題, 這也是資料庫管控平臺要完成的任務。
隨著阿里巴巴資料庫規模的不斷擴大,我們建設資料庫管控平臺也經歷了很多階段,從指令碼化、工具化、平臺化到目前的DBPaaS,DBPaaS在今年雙11中, 首次全面覆蓋集團、各子公司下的本地資料庫、公有云、混合雲等多種場景。今年雙11,資料庫已經全面實現容器化部署,彈性使用離線資源、公有云資源支援大促。全面優化的監控採集鏈路,實現了全網所有資料庫例項的秒級採集、監控、展現、診斷。每秒實時處理超過1000萬項監控指標,讓異常無所遁形。DBPaaS也持續在資料庫管理的自動化、規模化、數字化、智慧化等方向進行突破。
在這其中,關於資料庫監控系統建設比較典型。
在業務平時執行態,線上系統出現故障,在數萬資料庫中,如何發現異常、快速診斷亦是一件非常具有挑戰的事情。在雙十一全鏈路壓測中,系統吞吐量未達預期或業務出現了RT抖動,快速診斷定位資料庫問題是一個現實課題。此外,對於複雜資料庫故障事後排查故障根源、現場還原、歷史事件追蹤也迫使我們建設一個覆蓋線上所有環境、資料庫例項、事件的監控系統,做到:
- 覆蓋阿里全球子公司所有機房。
- 覆蓋阿里生態包含新零售、新金融、新制造、新技術、新能源所有業務。
- 覆蓋所有資料庫主機、作業系統、容器、資料庫、網路。
- 所有效能指標做到1秒級連續不間斷監控。
- 全天候持續穩定執行。
DBPaaS監控雙11執行概況
2017年雙11,DBPaaS平臺秒級監控系統每秒平均處理1000萬項效能指標,峰值處理1400萬項效能指標,為線上分佈在中國、美國、歐洲、東南亞的、所有資料庫例項健康執行保駕護航。做到了實時秒級監控,也就是說,任何時候,DBA同學可以看到任何資料庫例項一秒以前的所有效能趨勢。
DBPaaS監控系統僅使用0.5%的資料庫資源池的機器,支撐整個採集鏈路、計算鏈路、儲存、展現診斷系統。監控系統完美記錄今年每一次全鏈路壓測每個RT抖動現場,助力DBA快速診斷資料庫問題,併為後續系統優化提供建議。
在雙11大促保障期間,我們做到機器不擴容、服務不降級,讓DBA同學們喝茶度過雙11。在日常業務執行保障,我們也具備7*24服務能力。
我們是如何做到的
實現一個支援數萬資料庫例項的實時秒級監控系統,要解決許多技術挑戰。都說優秀的架構是演進過來,監控系統的建設也隨著規模和複雜性增加不斷迭代,到2017年,監控系統經歷了四個階段改進。
第一代監控系統
第一代監控系統架構非常簡單,採集Agent直接把效能資料寫入資料庫,監控系統直接查詢資料庫即可。
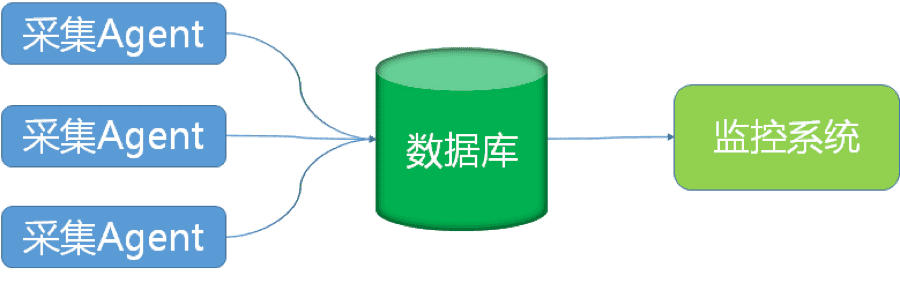
隨著資料庫叢集規模擴大,簡易架構的缺點也非常明顯。
首先,單機資料庫容量擴充套件性不足,隨著監控的資料庫規模擴大,日常效能指標寫入量非常大,資料庫容量捉襟見肘,長時間積累的監控歷史資料經常觸發磁碟空間預警,我們經常被迫刪除遠期資料。
其次,監控指標的擴充套件性不足。一開始資料庫監控項只有十幾項,但是很快就發現不夠用。因為經常有人拿著MySQL的文件說,我想看這個,我想看那個,能不能放到監控系統裡。效能指標展現的前提是儲存,在儲存層的擴充套件性缺陷讓我們頭痛不已。對於這種功能需求,無論是寬表還是窄表,都存在明顯的缺陷。如果用寬表,每新增一批效能指標,就要執行一次DDL,雖然預定義擴充套件欄位可以緩解,但終究約束了產品想象空間。窄表在結構上解決了任意個性能指標的儲存問題,但是它也帶來了寫入資料量放大和儲存空間膨脹的弊病。
最後,系統整體讀寫能力也不高,而且不具備水平擴充套件性。
以上所有原因催生了第二代監控系統的誕生。
第二代監控系統
第二代監控系統引入了DataHub模組和分散式文件資料庫。資料鏈路變成由採集Agent到DataHub到分散式文件資料庫,監控系統從分散式文件。
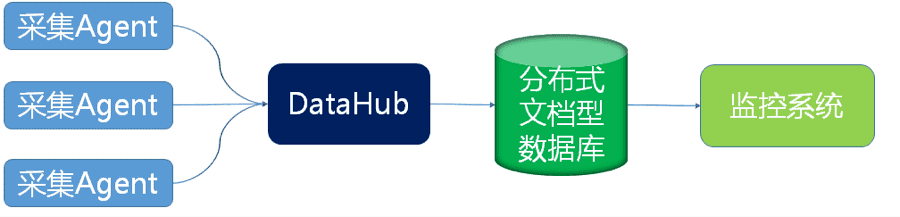
採集Agent專注於效能資料採集邏輯,構造統一資料格式,呼叫DataHub介面把資料傳輸到DataHub,採集Agent不需要關心效能資料存在哪裡。DataHub作為承上啟下的節點,實現了採集與儲存的解耦。第一,它對採集Agent遮蔽了資料儲存細節,僅暴露最簡單資料投遞介面;第二,DataHub收到根據儲存引擎特性使用最優寫入模型,比如使用批量寫入、壓縮等方式;第三,使用LVS、LSB技術可以實現DataHub水平擴充套件。分散式文件資料庫部分了解決擴充套件性問題,水平擴容用於解決儲存容量不足的問題,schema free的特性可以效能指標擴充套件性問題。
隨著監控系統持續執行,資料庫例項規模擴大,效能指標持續增加,監控系統使用者擴大,又遇到新的問題。第一,DBA同學常常需要檢視資料庫跨越數月的效能趨勢,以預估資料庫流量未來趨勢,這時系統查詢速度基本不可用。第二,儲存長達一年的全量效能資料,成本變得越來越不可承受,每年雙11壓測時,DBA同學總會問起去年雙11的效能趨勢。第三,DataHub存在丟失採集資料的隱患,由於採集原始資料是先buffer在DataHub記憶體中,只要程序重啟,記憶體中的採集資料就會丟失。
第三代監控系統
關於查詢速度慢的問題,文件型資料庫和關係型資料庫一樣,都是面向行的資料庫,即讀寫的基本資料,每一秒的效能資料儲存一行,一行N個性能指標,效能指標被儲存在以時間為key的一個表格中。雖然同一時刻的所有效能指標被存在同一行,但是它們的關係卻沒那麼緊密。因為典型的監控診斷需求是查同一個或幾個指標在一段時間的變化趨勢,而不是查同一時刻的指標(瞬時值),比如這樣的:

資料庫儲存引擎為了查出某個指標的效能趨勢,卻要掃描所有指標的資料,CPU和記憶體都開銷巨大,顯而易見,這些都是在浪費。雖然Column Family技術可以在一定程度上緩解上面說的問題,但是如何設定Column Family是個巨大挑戰,難道要儲存層的策略要和監控診斷層的需求耦合嗎?這看起來不是好辦法。
所以,我們把目光投向列式資料庫,監控效能指標讀寫特徵非常合適列式資料庫,以OpenTSDB為代表的時序資料庫,進入我們考察視野。OpenTSDB用時間線來描述每一個帶有時間序列的特定物件,時間線的讀寫都是獨立的。
毫無疑問,OpenTSDB成為第三代監控系統架構的一部分。
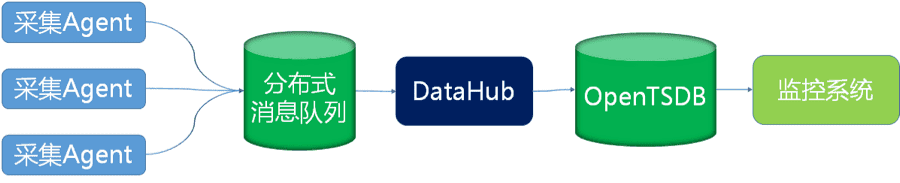
為了消除DataHub穩定性隱患,引入分散式訊息佇列,起到削峰填谷作用,即使DataHub全線崩潰,也可以採用重新消費訊息的方式解決。分散式訊息佇列,可以選擇Kafka 或 RocketMQ,這些分散式訊息佇列已經具備了高可用能力。
第三代架構相比過去有巨大的進步,在2016年雙11實現了全網資料庫10秒級監控,核心資料庫叢集1秒級監控。
隨著阿里生態擴大,全球化深入,各類全資子公司業務全面融合到阿里體系,除了中國大陸,還有美國、歐洲、俄羅斯、東南亞的業務。同時在阿里資料庫領域的新技術應用層出不窮,單元化部署已經成為常態,容器化排程正在覆蓋全網,儲存計算分離正在不斷推進,同一個業務資料庫叢集,在不同單元的部署策略可能也不同。與之對應的,DBA團隊的規模並沒有相應擴大,一個DBA同學支援多個子公司業務是常態,有的DBA還要兼任新技術推廣等工作。在資料庫效能診斷這個環節,必須為DBA爭效率,為DBA提供從巨集觀到微觀到診斷路徑顯得越來越迫切:從大盤到叢集、到單元、到例項、到主機、容器等一站式服務。
在這樣的診斷需求下,第三代監控架構有點力不從心了,主要表現在查詢:
- 高維度的效能診斷查詢速度慢,以叢集QPS為例,由於OpenTSDB裡儲存的每一個例項的QPS資料,當需要查詢叢集維度QPS就需要對掃描叢集每一個例項的QPS,再group by 時間戳 sum所有例項QPS。這需要掃描大量原始資料。
- OpenTSDB無法支援複雜的監控需求,比如檢視叢集平均RT趨勢,叢集平均RT並不是avg(所有例項的RT),而是sum(執行時間)/sum(執行次數)。為了實現目標只能查出2條時間線資料,在監控系統內部計算完後再展現在頁面中,使用者響應時間太長。
- 長時間跨度的效能診斷速度慢,比如1個月的效能趨勢,需要掃描原始的秒級2592000個數據點到瀏覽器中展現,考慮到瀏覽器展現效能,實際並不能也沒必要展現原始秒級資料。展示15分鐘時間精度的資料就夠了。
上述提到的預計算問題,OpenTSDB也意識到,其2.4版本開始,具備了簡陋預計算能力,無論從功能靈活性還是系統穩定性、效能,OpenTSDB都無法滿足DBPaaS秒級監控需求。
DBPaaS新一代架構
新一代架構,我們把OpenTSDB升級為更強勁的HiTSDB,同時基於流式計算開發的實時預聚合引擎代替簡單的DataHub,讓秒級監控飛。
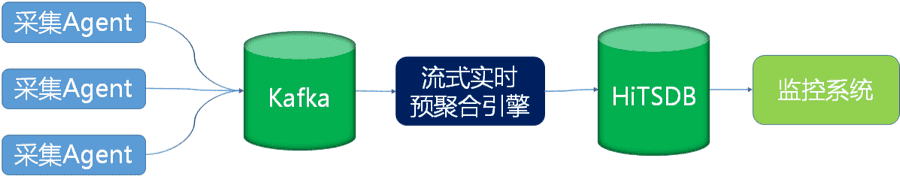
在職責界定上,監控診斷需求的複雜性留給實時預聚合引擎來解決,對時序資料庫的查詢需求都限定在一條時間線內。這要求時序資料庫必須把單一時間線效能做到極致,由兄弟團隊開發的阿里巴巴高效能序資料庫HiTSDB做到了極致壓縮和極致讀寫能力,利用時序資料等距時間戳和數值小幅變化的特徵,它做了大量壓縮。同時它全面相容OpenTSDB協議,已經在阿里雲公測。
新架構讓我們放開雙手專注思考監控與診斷需求,不再受儲存層的束縛。第一,為了高維度效能趨勢查詢效能,預聚合引擎做到了預先按業務資料庫叢集、單元、例項把效能指標計算好,寫入HiTSDB。第二,建立效能指標聚合計算函式庫,所有效能指標的聚合計算公式都是可以配置的,實現了自由的設定監控指標。第三,事先降時間精度,分為6個精度:1秒、5秒、15秒、1分鐘、5分鐘、15分鐘。不同時間精度的效能資料,才有不同的壓縮策略。
實時計算引擎
實時計算引擎實現了例項、單元、叢集三個維度逐級聚合,每一級聚合Bolt各自寫入HiTSDB。流式計算平臺的選擇是自由,目前我們的程式執行在JStorm計算平臺上,JStorm讓我們具備天生的高可用能力。
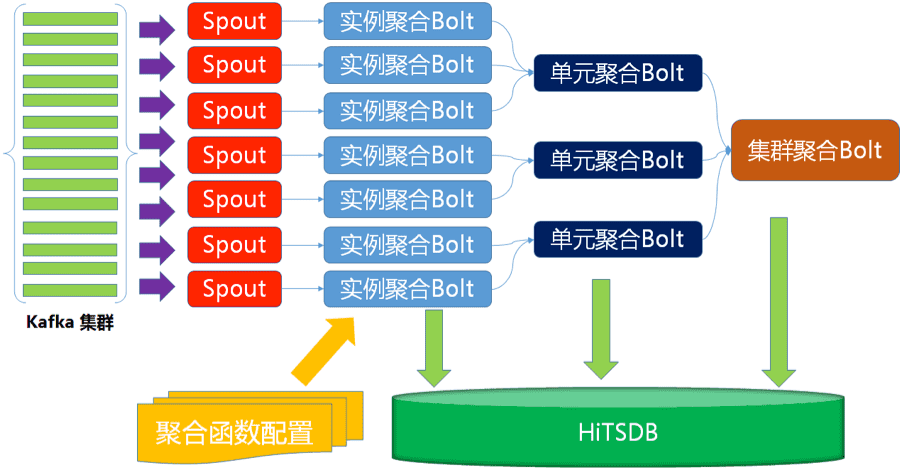
實時計算引擎效能
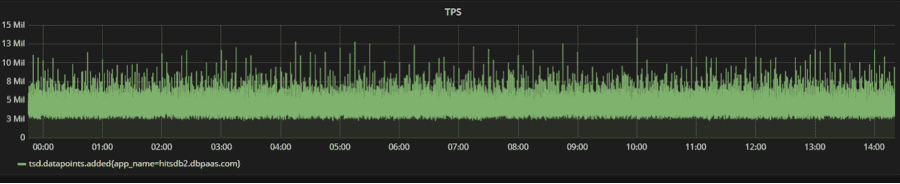
實時計算引擎使用了資料庫總機器規模0.1%的資源,實現了全網秒級監控資料的計算,平均每秒處理超過1000萬項效能指標,平均寫入TPS 600萬,峰值TPS 1400萬,下圖是雙11期間HiTSDB TPS趨勢曲線。
關鍵優化點
用這麼少的計算資源就實現了這麼高吞吐量,必然用上了許多黑科技。
- 在預計算中,我們使用增量迭代計算,無論是5秒精度的資料,還是15分鐘精度資料,我們不需要等時間視窗內所有的效能指標收集滿了,再開始計算,而是來多少效能資料,就算多少,僅保留中間結果,極大的節省記憶體。這項優化,相比常規計算方法至少節省95%記憶體。
- 採集端,針對性能資料報文進行合併,把相似和相鄰的報文合併在一起上報到kafka,這樣可以讓JStorm程式批量處理資料。
- 利用流式計算的特性實現資料區域性性,同一個叢集單元的例項採集到的資料在同一個kafka分割槽。這樣可以減少計算過程的網路傳輸及java 序列化/反序列化。這一項可以減少50%的網路傳輸。有興趣的朋友可以想想為什麼不能按例項分割槽或按叢集分割槽,會有什麼問題呢?
- 使用JStorm自定義排程特性,讓具有資料相關性的計算Bolt排程在同一個JVM中,這個是為了配合上面第二步,實現資料流轉儘量發生在同一個JVM裡。
- 對於不得不發生的Map-Reduce資料傳輸,儘量使用批量傳輸,並對傳輸的資料結構進行復用、裁剪,少傳輸重複資料,減少序列化、反序列化壓力。
未來展望
阿里DBPaaS全網秒級監控讓資料庫管控實現了數字化,經過這一年,我們積累了許多有價值的結構化資料。隨著大資料技術、機器學習技術的發展,為資料庫管控進入智慧化提供了可能性。
- 智慧診斷,基於現有全方位無死角的監控,結合事件追蹤,智慧定位問題。
- 排程優化,通過分析每個資料庫例項的畫像特徵,讓資源互補性的幾個資料庫例項排程在一起,最終節省成本。
- 預算估計,通過分析資料庫歷史執行狀況,在每次大促前,根據業務交易量目標,確定每一個數據庫叢集容量需求,進而為自動化擴容提供依據。

相關推薦
2017雙11技術揭祕—阿里資料庫進入全網秒級實時監控時代
點選有驚喜 前言 2017雙11再次創下了32.5萬筆/秒交易建立的紀錄,在這個數字後面,更是每秒多達幾千萬次的資料庫寫入,如何大規模進行自動化操作、保證資料庫的穩定性、快速發現問題是一個巨大的難題, 這也是資料庫管控平臺要完成的任務。 隨著阿里巴巴資料庫規模的
阿里資料庫進入全網秒級實時監控時代
作者:吳必良(未立) 前言 2017雙11再次創下了32.5萬筆/秒交易建立的紀錄,在這個數字後面,更是每秒多達幾千萬次的資料庫寫入,如何大規模進行自動化操作、保證資料庫的穩定性、快速發現問題是一個巨大的難題, 這也是資料庫管控平臺要完成的任務。 隨著阿里巴巴資料庫
2017雙11技術揭祕—阿里資料庫計算儲存分離與離線上混布
作者:呂建樞(呂健) 背景隨著阿里集團電商、物流、大文娛等業務的蓬勃發展,資料庫例項以及資料儲存規模不斷增長,在傳統基於單機的運維以及管理模式下,遇到非常多的困難與挑戰,主要歸結為: 機型採購與預算問題在單機模式下計算資源(CPU和記憶體)與儲存資源(主要為磁碟或者SSD)存在著不可調和的衝突;計算與儲存
雙11超級工程—阿里巴巴資料庫技術架構演進與阿里雲技術
【阿里巴巴資料庫技術架構演進】 每年電商雙11大促對阿里技術人都是一次大考,對阿里資料庫團隊更是如此。經過9年的發展,雙11單日交易額從2009年的0.5億一路攀升到2017年的1682億,秒級交易建立峰值達到了32.5萬筆/秒。支撐這一切業務指標的背後,是底層技術體系的一次次迭代升級。 阿里巴巴資料
揭祕2017雙11背後的網路-雙11的網路產品和技術概覽
引言 大家都知道,2017年雙11又創造了新紀錄,全天交易額1682億,交易峰值32.5萬筆/秒,支付峰值25.6W筆/秒,狂歡的背後是極其複雜龐大的技術系統,有興趣的同學可以參考 1682億背後的技術,其中就有大量阿里云云計算相關的產品和技術,而網路相關產品佔據了重要的位置,混合雲架構,專有網路V
12月12日-13日,12位阿里大咖解密2017阿里雙11技術支撐
技術成就輝煌,今年的雙11毫無懸念地再次重新整理了全球記錄——11秒交易額破億,28秒破10億,3分01秒破百億,40分12秒破500億,9小時破1000億……最終的交易額穩穩定格在了1682億,不僅創造了極高的交易峰值和支付峰值,同時刷爆紀錄的還有4200萬次/秒的資料庫處理峰值。 數字背後蘊藏著阿里
阿里技術分享:深度揭祕阿里資料庫技術方案的10年變遷史
本文原題“阿里資料庫十年變遷,那些你不知道的二三事”,來自阿里巴巴官方技術公號的分享。 1、引言 第十個雙11即將來臨之際,阿里技術推出《十年牧碼記》系列,邀請參與歷年雙11備戰的核心技術大牛,一起回顧阿里技術的變遷。 今天,阿里資料庫事業部研究員張瑞,將為你講述雙11資料庫技術不
2018天貓雙11|這就是阿里雲!不止有新技術,更有溫暖的社會力量
摘要: 雙11,全社會狂歡背後的新技術。 雙11快樂,該買的應該都已經買到了吧? 跟大家說個暖心事兒:今天,阿里雲以天貓雙11之子@派大星星星l的名義,在公安部打拐辦團圓專案、緣夢基金、寶貝回家等公益組織的鼎力支援下,將失蹤兒童的資訊放在這個網頁中,希望每一個看到的人都能把他們轉發
阿里2017雙11:常態化智慧化全鏈路壓測
我們面臨的挑戰 阿里的雙十一已經成為全球的超級工程了,在這個超級工程中,全鏈路壓測是很重要的一個環節。整個集團層面的全鏈路壓測,涉及到的BU和團隊非常多,對於這樣一個涉及多個團隊協作的事項,如何儘量的減少人員的投入,減少全鏈路壓測的次數,同時又能保證壓測能夠達到目標,成為一個必須要去突破的問題。 集團
11月10日雲棲精選夜讀:零點之戰!2017雙11關鍵技術全公開
點選有驚喜 在距離雙11已經不到10天的這個時刻,一場看不見硝煙的戰爭似乎已經打響。面對雙11期間極為嚴苛的技術壓力,阿里巴巴究竟是用怎樣的方式進行解決的呢?在接下來的文段中,就讓我們一起來對阿里巴巴在2017雙11背後的技術進行一次細緻的瞭解和探訪。 熱點熱議
護航Lazada雙11購物節 阿里雲CDN全球化火力全開
摘要: Lazada是東南亞最大B2C平臺,業務範圍覆蓋印度尼西亞、馬來西亞、菲律賓、新加坡、泰國和越南六個東南亞國家,覆蓋大約6億消費者。在雙11期間,阿里雲CDN為Lazada電商內容加速,並且通過獨家的直播解決方案,幫助Lazada把雙11晚會推送到泰國、馬來西亞,和東南亞人一起狂歡雙11。
阿里雙11狂歡如何承載大型系統的千萬級訪問?
一、問題起源 Spring Cloud微服務架構體系中,Eureka是一個至關重要的元件,它扮演著微服務註冊中心的角色,所有的服務註冊與服務發現,都是依賴Eureka的。 不少初學Spring Cloud的朋友在落地公司生產環境部署時,經常會問: Eureka Server
首次公開!2018雙11技術數字全記錄
2018雙11已圓滿落幕,但技術的探索,仍未止步。我們感謝:每一位參與雙11的技術人,所有給予關
大資料、人工智慧、VR、Docker、前端,雙11技術視訊、講義、文章一鍵get
誠然,每屆雙11對阿里來說都是一次大考,然而,1207億的背後,考校的絕不僅是阿里的系統支撐能力,比如:17.5萬筆/秒的交易訂單數峰值,2015年是14.05萬筆;12萬筆/秒的支付峰值,2015年是8.59萬筆 無線交易額佔比83.72%;100%的服務能力
Mongodb 學習筆記 (7)通過純mongo語句,將資料庫中的秒級時間戳,轉換成Date型別,並且裝換成任意時間格式
背景:在公司專案中,我們使用了秒級時間戳,作為時間資訊。但是mongodb自支援的多種時間處理函式,只針對date型別的欄位,於是我嘗試使用了mongo語句,將整型數的時間戳,通過mongo語句,轉換成date型別。 這裡使用的是aggregate(聚合),如下: db.t_merchant
阿里雲資料庫11月刊:揭祕雙11狂歡背後的阿里雲資料庫產品和技術
重點事件 1、2018資料技術嘉年華11月16日,由雲和恩墨和中國Oracle使用者組主辦的2018資料技術嘉年華在北京舉行。阿里雲研究員呂漫漪在16日上午主論壇分享了《下一代企業級雲資料庫POLARDB架構設計》,現場反響熱烈,千人會場座無虛席。會議時間恰在網際網路狂歡的“雙11”之後,從網際網路到企業級
【雲週刊】第145期:2017天貓雙11總交易額1682億,背後阿里絕密50+技術揭祕!
本期頭條 2017天貓雙11總交易額1682億,背後阿里絕密50+技術揭祕! 2017年天貓雙11全球狂歡節28秒破10億,3分01秒破百億,40分12秒破500億,9小時破1000億,交易峰值32.5萬/秒,支付峰值25.6萬/秒,再次重新整理全球紀錄,在這
2135億!2018 雙11阿里資料庫技術戰報新鮮出爐
00:02:05 成交額超100億00:57:56 成交額超666億01:47:26 成交額超1000億15:49:39 成交額超1682億22:28:37 成交額超2000億 2018新紀錄2135億 在年度大考面前阿里資料庫技術的小哥哥和小姐姐們又一次為大眾遞交了誠意滿滿的答卷 讓我
免費報名 | 十年沉澱 阿里雙11資料庫技術峰會北京站邀您同行
雙11十週年拾年牧碼在全球網際網路頂尖技術的演練場上阿里巴巴資料庫一路相伴 2018年12月16日,阿里巴巴雙11資料庫技術峰會將來到北京,與您分享雙11資料庫最新實戰經驗,誠邀各領域的企業CTO、資料庫技術負責人和架構師參會。 本次峰會承載了我們一直以來的初心,議題將從阿里巴巴雙11資料庫技術揭
怎樣進入阿里雲雙11一折拼團
入團連結:https://m.aliyun.com/act/team1111/#/share?params=N.EN2hxhpNQG.fx1zwsu4 2018年11月8日 19:13最新戰況 趕緊入No1團一起瓜分近50萬的獎金,新使用者可以下單購買最低折扣折上五折的阿里雲伺服器套餐 入團連結