
生成方法vs判別方法+生成模型vs判別模型
監督學習的方法可以分為2類,生成方法(generative approach)和判別方法(discriminative approach),所學到的模型分別為生成模型(generative model)和判別模型(discriminative model)。
生成方法:
由資料首先學習聯合概率分佈P(X,Y),然後求出條件概率分佈P(Y|X)。即通過學習先驗分佈來推導後驗分佈而進行分類
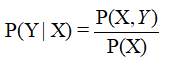
生成模型:
生成方法學習到的模型。包括,樸素貝葉斯(naive bayes),隱馬爾可夫(HMM),混合高斯(GMM),線性判別分析(LDA)
判別方法:
由資料直接學習決策函式f(x)或者條件概率分佈P(Y|X)。即直接學習後驗分佈來進行分類
判別模型:
判別方法學習到的模型。包括,K近鄰(KNN),感知機(perceptron),決策樹(decision tree),邏輯斯蒂迴歸(logistic regression),最大熵(MaxEnt),支援向量機(SVM),提升方法(AdaBoost),條件隨機場(CRF)。
區別:

生成方法特點:
- 從統計的角度表示資料的分佈情況,能夠反映同類資料本身的相似度
- 可以還原出聯合概率分佈P(X,Y),判別方法不能
- 隨著樣本容量的增加,學習收斂速度也加快
- 存在隱變數時還可以用生成方法,比如混合高斯模型,判別方法則不行
判別方法特點:
- 尋找不同類別之間的最優分類面,反映的是異類資料之間的差異
- 節省計算資源,需要的樣本數量少於生成方法
- 由於直接學習決策函式f(x)或者條件概率分佈P(Y|X),直接面對預測,準確性往往更高
- 可以對資料進行各種程式的抽象(降維,構造),定義並使用特徵,從而簡化學習問題
聯絡:

舉例:
判別式模型舉例:要確定一個羊是山羊還是綿羊,用判別模型的方法是從歷史資料中學習到模型,然後通過提取這隻羊的特徵來預測出這隻羊是山羊的概率,是綿羊的概率。
生成式模型舉例:利用生成模型是根據山羊的特徵首先學習出一個山羊的模型,然後根據綿羊的特徵學習出一個綿羊的模型,然後從這隻羊中提取特徵,放到山羊模型中看概率是多少,在放到綿羊模型中看概率是多少,哪個大就是哪個。
細細品味上面的例子,判別式模型是根據一隻羊的特徵可以直接給出這隻羊的概率(比如logistic regression,這概率大於0.5時則為正例,否則為反例),而生成式模型是要都試一試,最大的概率的那個就是最後結果。
References:
https://www.zhihu.com/question/20446337