
檢測率,召回率,mAP,ROC
在資訊檢索、分類體系中,有一系列的指標,搞清楚這些指標對於評價檢索和分類效能非常重要,因此最近根據網友的部落格做了一個彙總。
準確率、召回率、F1
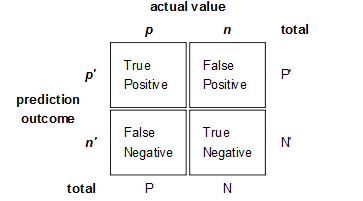
資訊檢索、分類、識別、翻譯等領域兩個最基本指標是召回率(Recall Rate)和準確率(Precision Rate),召回率也叫查全率,準確率也叫查準率,概念公式:
召回率(Recall) = 系統檢索到的相關檔案 / 系統所有相關的檔案總數
準確率(Precision) = 系統檢索到的相關檔案 / 系統所有檢索到的檔案總數
圖示表示如下:
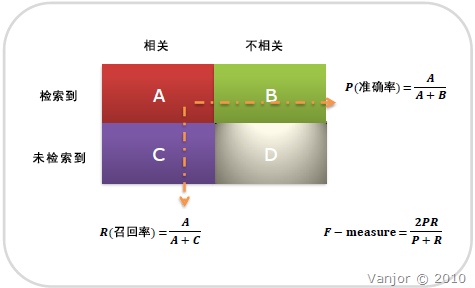
注意:準確率和召回率是互相影響的,理想情況下肯定是做到兩者都高,但是一般情況下準確率高、召回率就低,召回率低、準確率高,當然如果兩者都低,那是什麼地方出問題了
如果是做搜尋,那就是保證召回的情況下提升準確率;如果做疾病監測、反垃圾,則是保準確率的條件下,提升召回。
所以,在兩者都要求高的情況下,可以用F1來衡量。
- F1 = 2 * P * R / (P + R)
公式基本上就是這樣,但是如何算圖1中的A、B、C、D呢?這需要人工標註,人工標註資料需要較多時間且枯燥,如果僅僅是做實驗可以用用現成的語料。當然,還有一個辦法,找個一個比較成熟的演算法作為基準,用該演算法的結果作為樣本來進行比照,這個方法也有點問題,如果有現成的很好的演算法,就不用再研究了。
AP和mAP(mean Average Precision)
mAP是為解決P,R,F-measure的單點值侷限性的。為了得到 一個能夠反映全域性效能的指標,可以看考察下圖,其中兩條曲線(方塊點與圓點)分佈對應了兩個檢索系統的準確率-召回率曲線
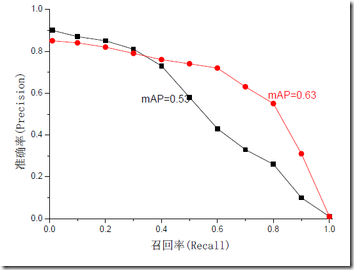
可以看出,雖然兩個系統的效能曲線有所交疊但是以圓點標示的系統的效能在絕大多數情況下要遠好於用方塊標示的系統。
從中我們可以 發現一點,如果一個系統的效能較好,其曲線應當儘可能的向上突出。
更加具體的,曲線與座標軸之間的面積應當越大。
最理想的系統, 其包含的面積應當是1,而所有系統的包含的面積都應當大於0。這就是用以評價資訊檢索系統的最常用效能指標,平均準確率mAP其規範的定義如下:(其中P,R分別為準確率與召回率)
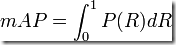
ROC和AUC
ROC和AUC是評價分類器的指標,上面第一個圖的ABCD仍然使用,只是需要稍微變換。
回到ROC上來,ROC的全名叫做Receiver Operating Characteristic。
ROC關注兩個指標
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能將正例分對的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表將負例錯分為正例的概率
在ROC 空間中,每個點的橫座標是FPR,縱座標是TPR,這也就描繪了分類器在TP(真正的正例)和FP(錯誤的正例)間的trade-off。ROC的主要分析工具是一個畫在ROC空間的曲線——ROC curve。我們知道,對於二值分類問題,例項的值往往是連續值,我們通過設定一個閾值,將例項分類到正類或者負類(比如大於閾值劃分為正類)。因此我們可以變化閾值,根據不同的閾值進行分類,根據分類結果計算得到ROC空間中相應的點,連線這些點就形成ROC curve。ROC curve經過(0,0)(1,1),實際上(0, 0)和(1, 1)連線形成的ROC curve實際上代表的是一個隨機分類器。一般情況下,這個曲線都應該處於(0, 0)和(1, 1)連線的上方。如圖所示。

用ROC curve來表示分類器的performance很直觀好用。可是,人們總是希望能有一個數值來標誌分類器的好壞。
於是Area Under roc Curve(AUC)就出現了。顧名思義,AUC的值就是處於ROC curve下方的那部分面積的大小。通常,AUC的值介於0.5到1.0之間,較大的AUC代表了較好的Performance。
AUC計算工具:
P/R和ROC是兩個不同的評價指標和計算方式,一般情況下,檢索用前者,分類、識別等用後者。
轉自:http://blog.csdn.net/wangzhiqing3/article/details/9058523
參考連結:
相關推薦
檢測率,召回率,mAP,ROC
在資訊檢索、分類體系中,有一系列的指標,搞清楚這些指標對於評價檢索和分類效能非常重要,因此最近根據網友的部落格做了一個彙總。 準確率、召回率、F1 資訊檢索、分類、識別、翻譯等領域兩個最基本指標是召回率(Recall Rate)和準確率(Precision Rate)
幾個易混淆的概念(準確率-召回率,擊中率-虛警率,PR曲線和mAP,ROC曲線和AUC)
準確率、召回率、F1 資訊檢索、分類、識別、翻譯等領域兩個最基本指標是召回率(Recall Rate)和準確率(Precision Rate),召回率也叫查全率,準確率也叫查準率,概念公式: 召回率(Recall) = 系統檢索到的相關檔案 / 系統所有相關的檔
R語言︱分類器的效能表現評價(混淆矩陣,準確率,召回率,F1,mAP、ROC曲線)
筆者寄語:分類器演算法最後都會有一個預測精度,而預測精度都會寫一個混淆矩陣,所有的訓練資料都會落入這個矩陣中,而對角線上的數字代表了預測正確的數目,即True Positive+True Nagetive。——————————————————————————相關內容:————
mAP,召回率(Recall),精確率(Precision)
如果一個學習器的P-R曲線被另一個學習器的P-R曲線完全包住,則可斷言後者的效能優於前者,例如上面的A和B優於學習器C,但是A和B的效能無法直接判斷,但我們往往仍希望把學習器A和學習器B進行一個比較,我們可以根據曲線下方的面積大小來進行比較,但更常用的是平衡點或者是F1值。平衡點(BEP)是查準率=查全率時的
準確率,召回率,mAP(mean average precision)解釋
準確率Precision 召回率Recall 其實這個翻譯相當蛋疼。。。 recall最合理的翻譯應該是 查全率 而Precision的最合理的翻譯應該是查準率 這樣就很容易理解了,假設一個班級有10個學生,5男5女 你用機器找女生,機器返回了一下結
[機器學習]模型評價參數,準確率,召回率,F1-score
就是 ddl .com gpo sci 擔心 height 數據 -s 很久很久以前,我還是有個建築夢的大二少年,有一天,講圖的老師看了眼我的設計圖,說:“我覺得你這個設計做得很緊張”,當時我就崩潰,對緊張不緊張這樣的評價標準理解無能。多年後我終於明白老師當年的意思,然鵝已
機器學習模型準確率,精確率,召回率,F-1指標及ROC曲線
01準確率,精確率,召回率,F-1指標及ROC曲線 假設原樣本有兩類,正樣本True和負樣本False 正樣本 -------------------------------True 負樣本 --------------------------------False 真 正樣本 True P
CS229 7.2 應用機器學習方法的技巧,準確率,召回率與 F值
建立模型 當使用機器學習的方法來解決問題時,比如垃圾郵件分類等,一般的步驟是這樣的: 1)從一個簡單的演算法入手這樣可以很快的實現這個演算法,並且可以在交叉驗證集上進行測試; 2)畫學習曲線以決定是否更多的資料,更多的特徵或者其他方式會有所幫助; 3)人工檢查那些演算法預測錯誤的例子(在交叉驗證集上)
(轉載)準確率(accuracy),精確率(Precision),召回率(Recall)和綜合評價指標(F1-Measure )-絕對讓你完全搞懂這些概念
自然語言處理(ML),機器學習(NLP),資訊檢索(IR)等領域,評估(evaluation)是一個必要的工作,而其評價指標往往有如下幾點:準確率(accuracy),精確率(Precision),召回率(Recall)和F1-Measure。 本文將簡單介紹其中幾個概念。中文中這幾個評價指標翻譯各有不同,
【機器學習筆記】:一文讓你徹底理解準確率,精準率,召回率,真正率,假正率,ROC/AUC
作者:xiaoyu 微信公眾號:Python資料科學 非經作者允許,禁止任何商業轉載。 ROC/AUC作為機器學習的評估指標非常重要,也是面試中經常出現的問題(80%都會問到)。其實,理解它並不是非常難,但是好多朋友都遇到了一個相同的問題,那就是:每次看書的時候
精確率,查準率,召回率
精確率(Precision),又稱為“查準率”。 召回率(Recall),又稱為“查全率”。 召回率和精確率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中召回率是是檢索出的相關文件數和文件庫中所有的相關文件數的比率,衡量的是檢索系統的查全率。精確率是檢索出的相關文件數與檢索
準確率(accuracy),精確率(Precision),召回率(Recall)和綜合評價指標(F1-Measure )
自然語言處理(ML),機器學習(NLP),資訊檢索(IR)等領域,評估(evaluation)是一個必要的工作,而其評價指標往往有如下幾點:準確率(accuracy),精確率(Precision),召回率(Recall)和F1-Measure。 本文將簡單介紹其中幾個概念。
精確度,準確率,召回率,漏警概率,虛警概率
一組樣本,個數為M,正例有P個,負例有N個, 判斷為正例的正例有TP個,判斷為負例的正例有FN個(假的負例)P=TP+FN 判斷為負例的負例為TN個,判斷為正例的負例有FP個(假的正例)N=TN+FP 精確度(Precision)P=所有判斷為正例的例子中,真正為正例的所佔
準確率,召回率,F1 值、ROC,AUC、mse,mape評價指標
在機器學習、資料探勘領域,工業界往往會根據實際的業務場景擬定相應的業務指標。本文旨在一起學習比較經典的三大類評價指標,其中第一、二類主要用於分類場景、第三類主要用於迴歸預測場景,基本思路是從概念公式,到
準確率,召回率,F1 值、ROC,AUC、mse,mape 評價指標
在機器學習、資料探勘領域,工業界往往會根據實際的業務場景擬定相應的業務指標。本文旨在一起學習比較經典的三大類評價指標,其中第一、二類主要用於分類場景、第三類主要用於迴歸預測場景,基本思路是從概念公式,到優缺點,再到具體應用(分類問題,本文以二分類為例)。 1.準確率P、召回
詳解Precision(查準率,精確率),Recall(查全率,召回率),Accuracy(準確率)
中文的翻譯有點亂,大致是這樣的:Precision(查準率,精確率),Recall(查全率,召回率),Accuracy(準確率)。下面提到這三個名詞都用英文表示。 從一個例子入手:我們訓練了一個識貓模型,送一張圖片給模型,模型就能告訴你該圖片是否有貓。目標是找出所有有貓圖片。
混淆矩陣confusion matrix, 準確率,召回率
混淆矩陣 . 預測正確(接受) 預測錯誤(拒絕) 真 TPTP TNTN(第一類分類錯誤,去真) PP 假 FPFP(第二類分類錯誤,存偽)
準確率,召回率和F1值
正確率、召回率和F值是在魚龍混雜的環境中,選出目標的重要評價指標。 不妨看看這些指標的定義先: 正確率 = 正確識別的個體總數 / 識別出的個體總數 召回率 = 正確識別的個體總數 / 測試集中存在的個體總數 F值 = 正確
精確率與召回率,RoC曲線與PR曲線
在機器學習的演算法評估中,尤其是分類演算法評估中,我們經常聽到精確率(precision)與召回率(recall),RoC曲線與PR曲線這些概念,那這些概念到底有什麼用處呢? 首先,我們需要搞清楚幾個拗口的概念: 1. TP, FP, TN, F
準確率(Accuracy), 精確率(Precision), 召回率(Recall)和F1-Measure,confusion matrix
自然語言處理(ML),機器學習(NLP),資訊檢索(IR)等領域,評估(Evaluation)是一個必要的工作,而其評價指標往往有如下幾點:準確率(Accuracy),精確率(Precision),召回率(Recall)和F1-Measure。 本文將簡單介紹其中幾個概