
pyspark 對RDD的相關api
1、aggregate,可以用來求平均值

如下示例
rdd2 = spark.sparkContext.parallelize([1,2,3,4,5,6,7,8,9,10]) seqop = (lambda x,y: (x[0]+ y, x[1]+ 1)) #0+1 0+1 1+2 1+1 3+3 2+1 cpmop= (lambda x,y: (x[0]+ y[0], x[1]+ y[1])) #用於分散式計算時的聚合 res = rdd2.aggregate((0,0), seqop, cpmop) #這樣可以求平均數 return float(res[0]) / res[1]
2、coalesce 聚合分割槽,glom視為可以方便看出有幾個分割槽

3、cogroup 取出一個key在自身存在,在另外一個也存在,則返回同一個key對應的所有的values,以touple的形式返回

4、collectAsMap 將元組形式的rdd返回為一個 字典形式,如果引數不是2個,這個方法則不適用,會報錯

報錯如下,需要長度為2的引數

5、combineByKey 對同一個rdd相同的key的value進行合併為一個list,並返回為一個新的RDD
理解:append針對key 因為append加入的是一個obj 相同的key只會存在一個
extend針對value 因為相同的key的value會進行重複新增,到我們的列表裡,不會因為存在而不追加
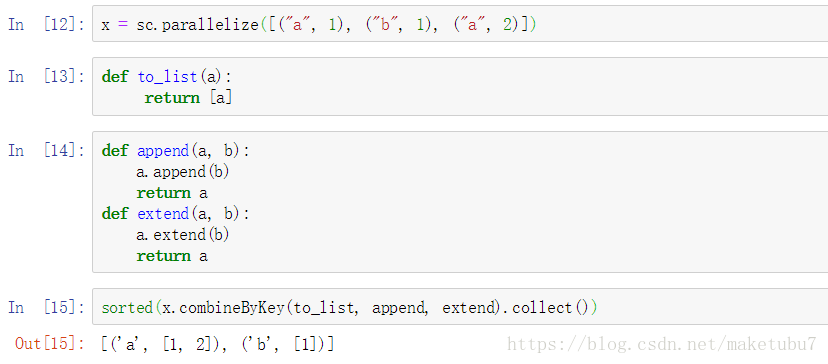
6、countByKey 和reduceByKey的用法一樣,但是countbykey是action運算元,reducebykey是tranformation,不會立即執行,通常用reducebykey這個操作, 等價於 data.reduceByKey(_+_).collectAsMap()

7、countbyvalue 如下返回每個value在 序列中出現的次數

8、distinct 去重,這個用過sql應該就知道的

9、filter 過濾,返回表示式為true的值

10、flatMap 這個記住,這是一個1對多的運算元,rdd的一個引數進來,根據表示式,會有多個返回值,相當於展開,如下
每個引數都會有不同的返回值,可以看最後一個flatmap的形式 等價於map(lambda x: (x, x)).collect()

11、fold 如下 rdd為[1,2,3,4,5] 給定一個初始值,按照cmp方式,對元素進行摺疊,這裡為add
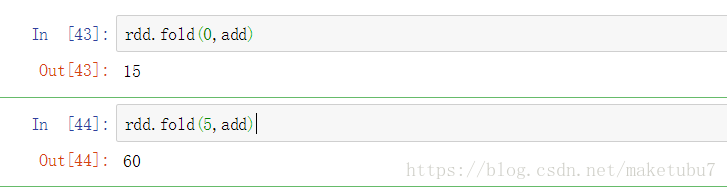
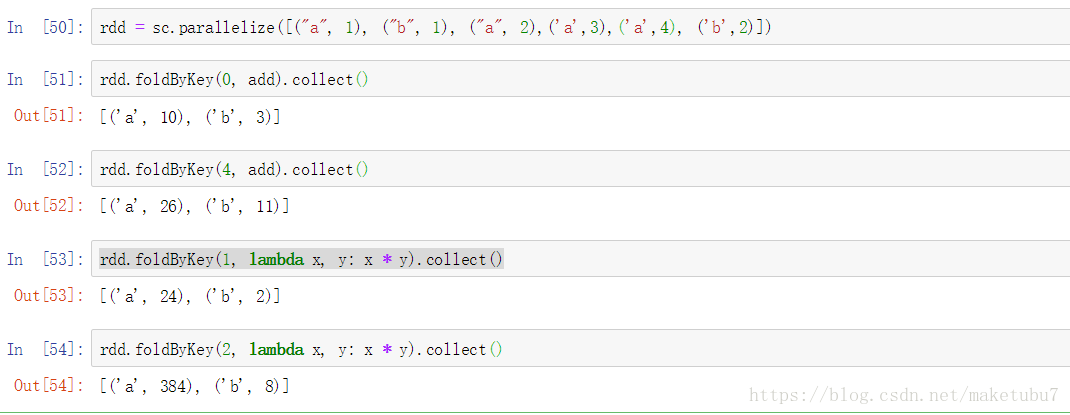
12、foldbykey 對相同的key的values進行相應的fold計算, 如下操作
13、foreach(f) 對rdd每個元素進行相應的函式操作
14、foreachpartition 對rdd每個分割槽的每個元素進行操作

15、fullOuterJoin 返回兩個RDD 相同的key,和對應的value組成的touple(key,(value1,value2)),沒有則返回None
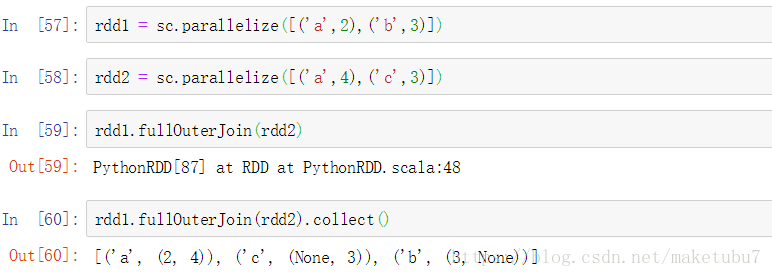
16、getCheckpointFile(filepath) 得到checkpoint下來的資料,並返回rdd
17、getNumPartitions() getStorageLevel() 得到一個rdd的分割槽,和快取的級別
18、groupby 對一個RDD的每一個value,做一個函式操作,根據對應的返回值,對其進行分組,並返回新的RDD
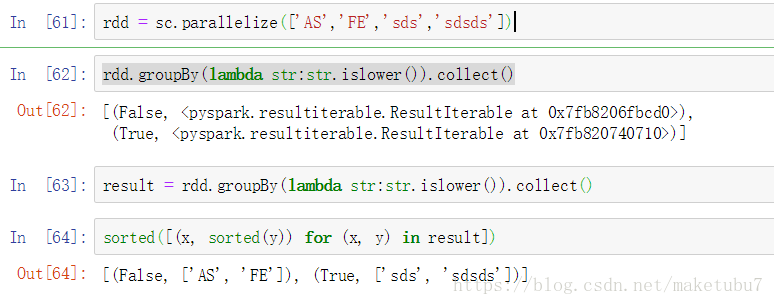
19、groupByKey 對touple形式的rdd按key值進行聚合 返回為(key,[value1,value2]),然後對value的list求長度,就可以做到和wordcount一樣的效果、但是如果是做聚合操作儘量用reducebykey和aggregatebykey
mapvalues(f) 對每個touple形式的元素的value進行f(value) => (key,f(value))
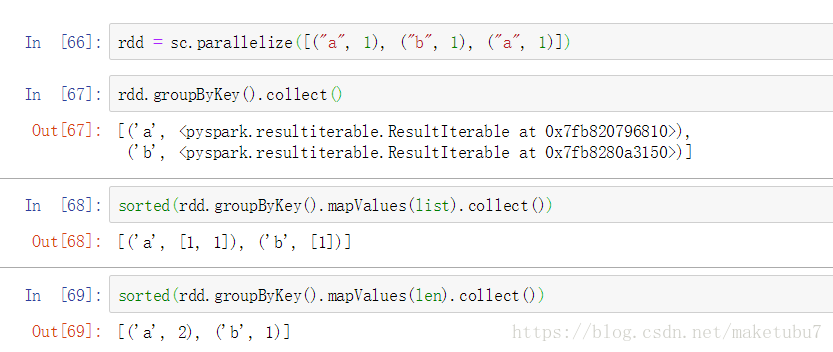
20、intersection(other) 兩個rdd取交集,同樣適用於dataframe,取表中完全相同的行
21、isEmpty() 判斷RDD是否為空,常用於 第一次unionall的時候對dataframe進行判斷,選擇相應的操作
22、leftOuterJoin(other),rightOuterJoin(other), 跟fullOuterJoin一樣,這裡left以左表為驅動表沒有join上則換回none,right一樣
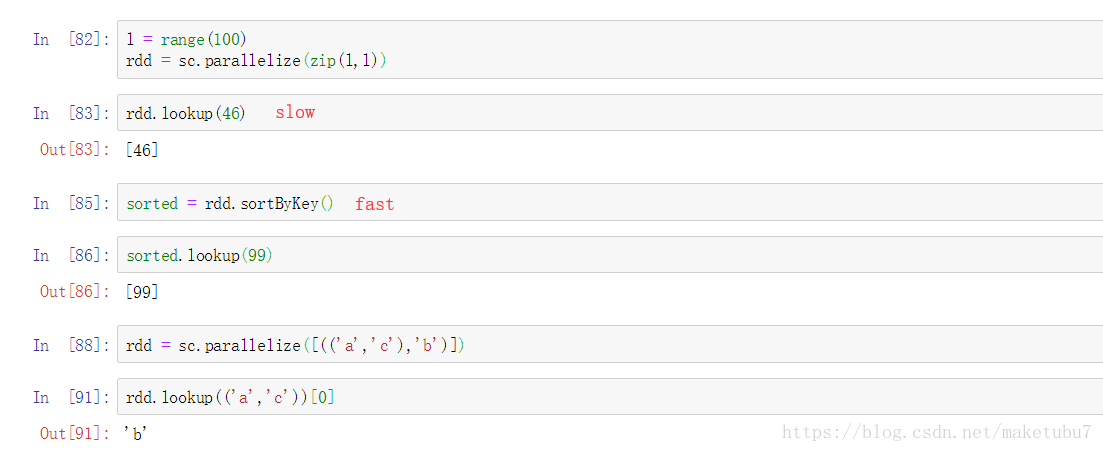
23、lookup(key) 根據對應的key 返回對應的value, 如下所示,如果是有序的key,找起來會更快
24、map(f) map返回的是一對一的關係,一個元素返回f(x) 常用於轉換我們的資料格式
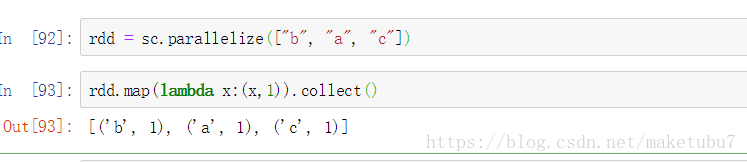
25、mapPartitions(f) 對每個分割槽的元素驚醒 f(values)操作 yield用法 參考http://python.jobbole.com/87613/

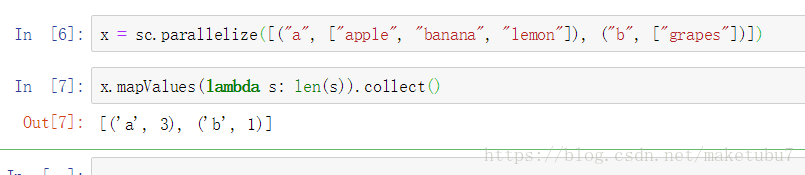
26、mapValues(f) 對value進行f(value) => (key,f(value))的形式
27、reduce(f) 對元素做相應的摺疊操作 2 for _ in range(10) 這裡就相當於取10次2

28、reduceByKey(f) 對同一個key的values 進行f(value)操作 (key,values) => (key,f(value1,value2)) => 下一次迭代

29、repartition(num) 對rdd的重新分割槽,分為num個分割槽

30、repartitionAndSortWithinPartitions(num,function) 對一個RDD進行重分割槽num 分割槽內部有排序,分割槽規則為function的返回結果為分割槽個數,如果分割槽個數大於,function的返回結果個數,則會存在空的元素 => []

31、sortedBy(index) 對RDD內部進行升序排序 ,按照我們給定的規則

32、sortByKey(ascending=True, numPartitions=None, keyfunc=<function RDD),第一個引數預設為true,num為分割槽個數,keyfunc按照對key處理後的結果進行排序,如下圖 為對key全部小寫後再進行排序

33、subtract(other, numPartitions=None), 按照元素的全部內容進行去重,保留自身存在 other不存在的元素,同樣適用於dataframe的相關行的去重

34、subtractByKey(other, numPartitions=None), 按照key值取反集

35、union(rdd) 只適用於同一種資料格式的rdd,不然後面的rdd轉換操作,不好進行,找不到合適的方法,對RDD進行有效的處理

36、values 返回touple的values

37、zip 拉鍊操作, 對兩個rdd進行壓縮,但是元素個數要一致,和list的壓縮一致

38、zipWithIndex 根據value => (value,index)

相關推薦
pyspark 對RDD的相關api
1、aggregate,可以用來求平均值 如下示例 rdd2 = spark.sparkContext.parallelize([1,2,3,4,5,6,7,8,9,10]) seqop = (lambda x,y: (x[0]+ y, x[1]+ 1))
HotSpot虛擬機對象相關內容
線程 內存布局 運行 字節對齊 back thread 自身 操作 目前 一.對象的創建1.類加載檢查 普通對象的創建過程:虛擬機遇到一條new指令時,首先將去檢查這個指令的參數是否能在常量池中定位到一個類的符號引用,並且檢查這個符號引用代表的類是否已被加載、解析和初
spark2.x由淺入深深到底系列六之RDD java api詳解二
spark 大數據 javaapi 老湯 rdd package com.twq.javaapi.java7; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.
spark2.x由淺入深深到底系列六之RDD java api調用scala api的原理
spark 大數據 javaapi 老湯 rdd RDD java api其實底層是調用了scala的api來實現的,所以我們有必要對java api是怎麽樣去調用scala api,我們先自己簡單的實現一個scala版本和java版本的RDD和SparkContext一、簡單實現scal
spark2.x由淺入深深到底系列六之RDD java api詳解三
老湯 spark 大數據 javaapi rdd 學習任何spark知識點之前請先正確理解spark,可以參考:正確理解spark本文詳細介紹了spark key-value類型的rdd java api一、key-value類型的RDD的創建方式1、sparkContext.parall
spark2.x由淺入深深到底系列六之RDD java api詳解四
spark 大數據 javaapi 老湯 rdd 學習spark任何的知識點之前,先對spark要有一個正確的理解,可以參考:正確理解spark本文對join相關的api做了一個解釋SparkConf conf = new SparkConf().setAppName("appName")
TensorFlow — 相關 API
平均值 狀態 例如 完成 print 允許 ext 數列 數據格式 TensorFlow — 相關 API TensorFlow 相關函數理解 任務時間:時間未知 tf.truncated_normal truncated_normal( shape,
spark2.x由淺入深深到底系列六之RDD java api用JdbcRDD讀取關系型數據庫
spark 大數據 javaapi rdd jdbcrdd 學習任何的spark技術之前,請先正確理解spark,可以參考:正確理解spark以下是用spark RDD java api實現從關系型數據庫中讀取數據,這裏使用的是derby本地數據庫,當然可以是mysql或者oracle等關
對RDD分區的理解
blog cat success ica sim contex mil ont eight 舉個例子: val logFile = "file:///home/soyo/桌面/6.txt" val conf = new SparkConf().setAppNam
java9新特性-16-Deprecated的相關API
port cms ide warnings mov tar 啟動應用 collector ons 1.官方Feature 211: Elide Deprecation Warnings on Import Statements 214: Remove GC Combina
假期(面向對象相關)
運行 三種 類名 ati foo 創建對象 color 控制 ... """ 一、isinstance(obj,cls) 和 issubclass(sub,super) isinstance(obj,cls) 檢查obj是否是類cls的對象
Python心得基礎篇【7】面向對象相關
相關 sin 輸入 foo exc 其他 span iss input 其他相關 一、isinstance(obj, cls) 檢查是否obj是否是類 cls 的對象 1 class Foo(object): 2 pass 3 4 obj = Foo() 5
TensorFlow - 相關 API
再計算 通道數 erro ali ural 現在 thead post false 來自:https://cloud.tencent.com/developer/labs/lab/10324 TensorFlow - 相關 API TensorFlow 相關函數理解 任
2、FreeRTOS任務相關API函數
ret get 相關 main eat 定時器 ref ati 安全 1.任務相關的API函數 函數存在於task.c中,主要的函數有: xTaskCreate():使用動態的方法創建一個任務; xTaskCreatStatic():使用靜態的方法創建一個任務(用
HBase 相關API操練(二):Java API
auto 高性能 ++ getc public form 過濾 類型 version 一、HBase Java編程 (1)HBase是用Java語言編寫的,它支持Java編程; (2)HBase支持CRUD操作:Create,Read,Update和Delete; (
app自動化測試中的相關api
hello 輸入 app send round image IT end http 這個說的api即python自動化測試中經常會使用到的一些api,具體如下: 1、find_element_by_id/find_elements_by_id 定位元素api,使用方法如
再和“面向對象”談戀愛 - 對象相關概念(二)
是個 DG 證件 就是 原型對象 了無 結果 弟弟 IV 上一篇文章把對象的概念講解了一下,這篇文章要重點解釋最讓大家犯迷糊的一些概念,包括 構造函數 實例 繼承 構造函數的屬性與方法(私有屬性與方法) 實例的屬性與方法(共享屬性與方法) prototype(原型) _
第二十七篇 類和對象相關知識
執行函數 自動 示例 需要 實例 __main__ 傳參 房子 類的定義 類和對象 1. 什麽叫類:類是一種數據結構,就好比一個模型,該模型用來表述一類食物(食物即數據和動作的結合體),用它來生產真是的物體(實例) 2. 什麽叫對象:睜開眼,你看到的一切事物都是一個個的對象
Python 面向對象相關
png self string lis pre 處理 father field ril 1. 類基本定義 默認構造器為只有一個self參數,內容只有一行pass。 方法: 實例方法:以實例本身self作為第一個參數。 類方法:以類對象本身cls作為第一個參數,以@cl
(2)pyspark建立RDD以及讀取文件成dataframe
wid tro 轉換 ram span afr ati alt csv 1、啟動spark 2、建立RDD: 3、從text中讀取,read.text 4、從csv中讀取:read.csv 5、從json中讀取:read.json 7、RDD與Datafr