
一文讀懂分散式資料庫Hbase
一、
1、什麼是Hbase。
是一個高可靠性、高效能、列儲存、可伸縮、實時讀寫的分散式資料庫系統。
適合於儲存非結構化資料,基於列的而不是基於行的模式
如圖:Hadoop生態中HBase與其他部分的關係。
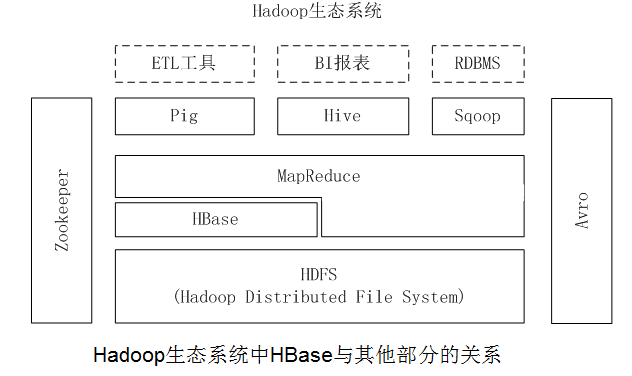
2、關係資料庫已經流行很多年,並且Hadoop已經有了HDFS和MapReduce,為什麼需要HBase?
Hadoop可以很好地解決大規模資料的離線批量處理問題,但是,受限於HadoopMapReduce程式設計框架的高延遲資料處理機制,使得Hadoop無法滿足大規模資料實時處理應用的需求 HDFS面向批量訪問模式,不是隨機訪問模式 傳統的通用關係型資料庫無法應對在資料規模劇增時導致的系統擴充套件性和效能問題(分庫分表也不能很好解決)(3)儲存模式:關係資料庫是基於行模式儲存的。HBase是基於列儲存的,每個列族都由幾個檔案儲存,不同列族的檔案是分離的 (4)資料索引:關係資料庫通常可以針對不同列構建複雜的多個索引,以提高資料訪問效能。HBase只有一個索引——行鍵,通過巧妙的設計,HBase中的所有訪問方法,或者通過行鍵訪問,或者通過行鍵掃描,從而使得整個系統不會慢下來 (5)資料維護:在關係資料庫中,更新操作會用最新的當前值去替換記錄中原來的舊值,舊值被覆蓋後就不會存在。而在HBase中執行更新操作時,並不會刪除資料舊的版本,而是生成一個新的版本,舊有的版本仍然保留
1、模型概述
HBase是一個稀疏、多維度、排序的對映表,這張表的索引是行鍵、列族、列限定符和時間戳 每個值是一個未經解釋的字串,沒有資料型別 使用者在表中儲存資料,每一行都有一個可排序的行鍵和任意多的列 表在水平方向由一個或者多個列族組成,一個列族中可以包含任意多個列,同一個列族裡面的資料儲存在一起 列族支援動態擴充套件,可以很輕鬆地新增一個列族或列,無需預先定義列的數量以及型別,所有列均以字串形式儲存,使用者需要自行進行資料型別轉換 HBase中執行更新操作時,並不會刪除資料舊的版本,而是生成一個新的版本,舊有的版本仍然保留(這是和HDFS只允許追加不允許修改的特性相關的)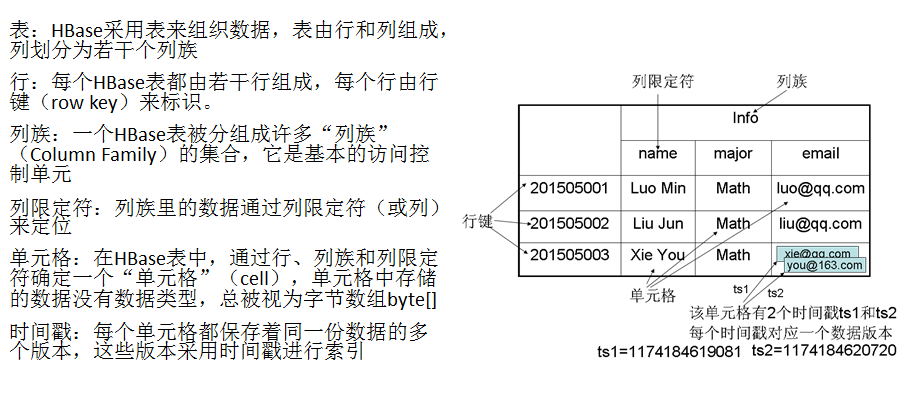
2、資料座標
HBase中需要根據行鍵、列族、列限定符和時間戳來確定一個單元格,因此,可以視為一個“四維座標”,即[行鍵,列族, 列限定符,時間戳]
|
鍵 |
值 |
|
[“201505003”,“Info”,“email”, 1174184619081] |
|
|
[“201505003”,“Info”,“email”, 1174184620720] |

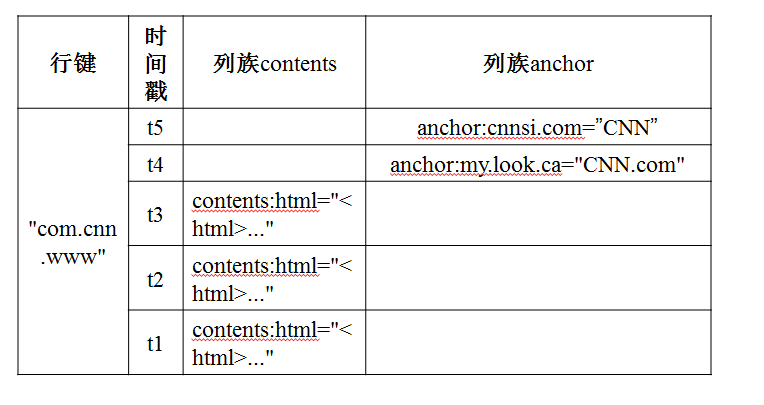
4、物理檢視
三、HBase實現原理
1、HBase的實現包括三個主要的功能元件:
(1)庫函式:連結到每個客戶端 (2)一個Master主伺服器 (3)許多個Region伺服器主伺服器Master負責管理和維護HBase表的分割槽資訊,維護Region伺服器列表,分配Region,負載均衡 Region伺服器負責儲存和維護分配給自己的Region,處理來自客戶端的讀寫請求 客戶端並不是直接從Master主伺服器上讀取資料,而是在獲得Region的儲存位置資訊後,直接從Region伺服器上讀取資料 客戶端並不依賴Master,而是通過Zookeeper來獲得Region位置資訊,大多數客戶端甚至從來不和Master通訊,這種設計方式使得Master負載很小
2、Region
開始只有一個Region,後來不斷分裂 Region拆分操作非常快,接近瞬間,因為拆分之後的Region讀取的仍然是原儲存檔案,直到“合併”過程把儲存檔案非同步地寫到獨立的檔案之後,才會讀取新檔案 同一個Region不會被分拆到多個Region伺服器
每個Region伺服器儲存10-1000個Region
元資料表,又名.META.表,儲存了Region和Region伺服器的對映關係 當HBase表很大時, .META.表也會被分裂成多個Region 根資料表,又名-ROOT-表,記錄所有元資料的具體位置 -ROOT-表只有唯一一個Region,名字是在程式中被寫死的 Zookeeper檔案記錄了-ROOT-表的位置
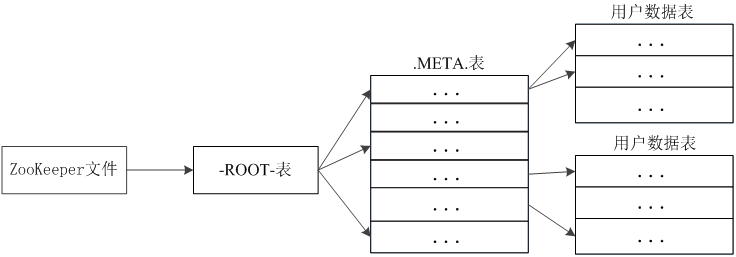
客戶端訪問資料時的“三級定址”
為了加速定址,客戶端會快取位置資訊,同時,需要解決快取失效問題
定址過程客戶端只需要詢問Zookeeper伺服器,不需要連線Master伺服器3、HBase的三層結構中各層次的名稱和作用
|
層次 |
名稱 |
作用 |
|
第一層 |
Zookeper檔案 |
記錄了-ROOT-表的位置資訊 |
|
第二層 |
-ROOT-表 |
記錄了.META.表的Region位置資訊 -ROOT-表只能有一個Region。通過-ROOT-表,就可以訪問.META.表中的資料 |
|
第三層 |
.META.表 |
記錄了使用者資料表的Region位置資訊,.META.表可以有多個Region,儲存了HBase中所有使用者資料表的Region位置資訊 |
1、HBase系統架構
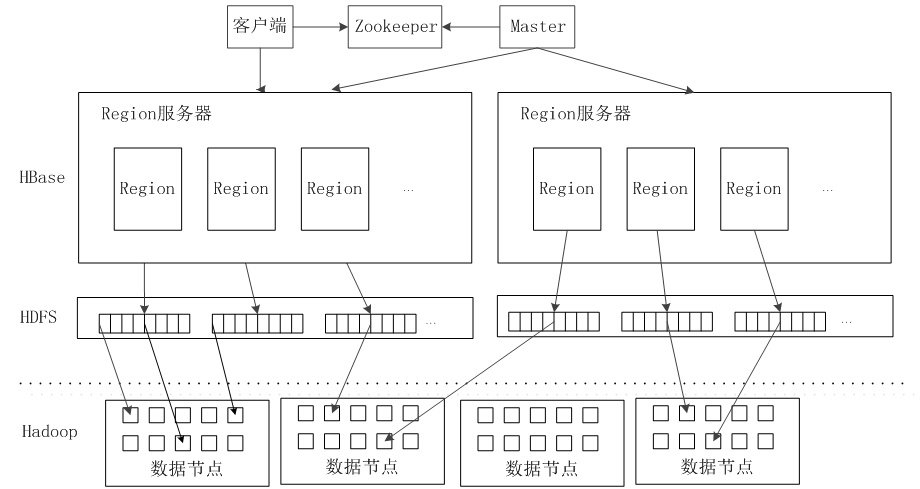
(1、客戶端包含訪問HBase的介面,同時在快取中維護著已經訪問過的Region位置資訊,用來加快後續資料訪問過程
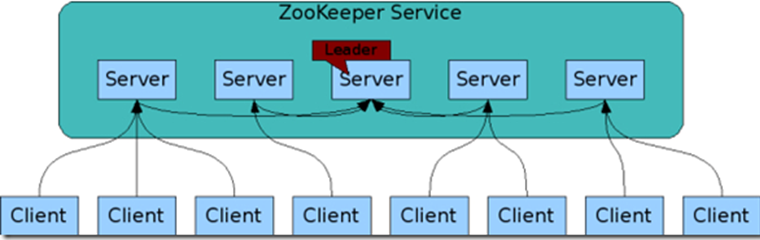
(2、Zookeeper可以幫助選舉出一個Master作為叢集的總管,並保證在任何時刻總有唯一一個Master在執行,這就避免了Master的“單點失效”問題 (Zookeeper是一個很好的叢集管理工具,被大量用於分散式計算,提供配置維護、域名服務、分散式同步、組服務等。)
(3. Master 主伺服器Master主要負責表和Region的管理工作: 管理使用者對錶的增加、刪除、修改、查詢等操作 實現不同Region伺服器之間的負載均衡 在Region分裂或合併後,負責重新調整Region的分佈 對發生故障失效的Region伺服器上的Region進行遷移
(4. Region伺服器 Region伺服器是HBase中最核心的模組,負責維護分配給自己的Region,並響應使用者的讀寫請求 2、Region
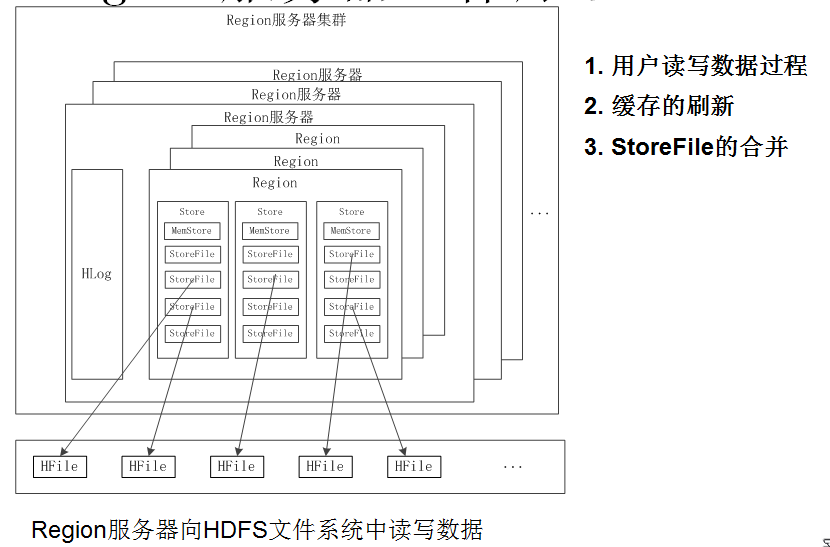
(1、使用者讀寫資料過程
使用者寫入資料時,被分配到相應Region伺服器去執行 使用者資料首先被寫入到MemStore和Hlog中 只有當操作寫入Hlog之後,commit()呼叫才會將其返回給客戶端 當用戶讀取資料時,Region伺服器會首先訪問MemStore快取,如果找不到,再去磁碟上面的StoreFile中尋找 (2、快取的重新整理
系統會週期性地把MemStore快取裡的內容刷寫到磁碟的StoreFile檔案中,清空快取,並在Hlog裡面寫入一個標記、
每次刷寫都生成一個新的StoreFile檔案,因此,每個Store包含多個StoreFile檔案 每個Region伺服器都有一個自己的HLog檔案,每次啟動都檢查該檔案,確認最近一次執行快取重新整理操作之後是否發生新的寫入操作;如果發現更新,則先寫入MemStore,再刷寫到StoreFile,最後刪除舊的Hlog檔案,開始為使用者提供服務
(3、StroreFile的合併 每次刷寫都生成一個新的StoreFile,數量太多,影響查詢速度 呼叫Store.compact()把多個合併成一個 合併操作比較耗費資源,只有數量達到一個閾值才啟動合併 3、Store工作原理
Store是Region伺服器的核心 多個StoreFile合併成一個
觸發分裂操作,1個父Region被分裂成兩個子Region
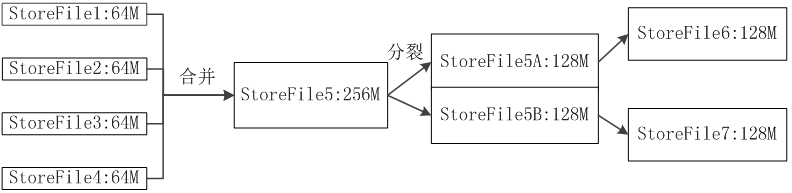 單個StoreFile過大時,又
4、HLog工作原理
單個StoreFile過大時,又
4、HLog工作原理分散式環境必須要考慮系統出錯。HBase採用HLog保證系統恢復 HBase系統為每個Region伺服器配置了一個HLog檔案,它是一種預寫式日誌(WriteAhead Log) 使用者更新資料必須首先寫入日誌後,才能寫入MemStore快取,並且,直到MemStore快取內容對應的日誌已經寫入磁碟,該快取內容才能被刷寫到磁碟
Zookeeper會實時監測每個Region伺服器的狀態,當某個Region伺服器發生故障時,Zookeeper會通知Master Master首先會處理該故障Region伺服器上面遺留的HLog檔案,這個遺留的HLog檔案中包含了來自多個Region物件的日誌記錄 系統會根據每條日誌記錄所屬的Region物件對HLog資料進行拆分,分別放到相應Region物件的目錄下,然後,再將失效的Region重新分配到可用的Region伺服器中,並把與該Region物件相關的HLog日誌記錄也傳送給相應的Region伺服器 Region伺服器領取到分配給自己的Region物件以及與之相關的HLog日誌記錄以後,會重新做一遍日誌記錄中的各種操作,把日誌記錄中的資料寫入到MemStore快取中,然後,重新整理到磁碟的StoreFile檔案中,完成資料恢復 共用日誌優點:提高對錶的寫操作效能;缺點:恢復時需要分拆日誌 五、HBase效能
1、行鍵(RowKey)
行鍵是按照字典序儲存,因此,設計行鍵時,要充分利用這個排序特點,將經常一起讀取的資料儲存到一塊,將最近可能會被訪問的資料放在一塊。
舉個例子:如果最近寫入HBase表中的資料是最可能被訪問的,可以考慮將時間戳作為行鍵的一部分,由於是字典序排序,所以可以使用Long.MAX_VALUE- timestamp作為行鍵,這樣能保證新寫入的資料在讀取時可以被快速命中。
InMemory:建立表的時候,可以通過HColumnDescriptor.setInMemory(true)將表放到Region伺服器的快取中,保證在讀取的時候被cache命中。
Max Version:建立表的時候,可以通過HColumnDescriptor.setMaxVersions(int maxVersions)設定表中資料的最大版本,如果只需要儲存最新版本的資料,那麼可以設定setMaxVersions(1)。
Time To Live建立表的時候,可以通過HColumnDescriptor.setTimeToLive(inttimeToLive)設定表中資料的儲存生命期,過期資料將自動被刪除,例如如果只需要儲存最近兩天的資料,那麼可以設定setTimeToLive(2* 24 * 60 * 60)。
2、HBaseMaster預設基於Web的UI服務埠為60010,HBase region伺服器預設基於Web的UI服務埠為60030.如果master執行在名為master.foo.com的主機中,mater的主頁地址就是http://master.foo.com:60010,使用者可以通過Web瀏覽器輸入這個地址檢視該頁面 可以檢視HBase叢集的當前狀態 3、NoSQL區別於關係型資料庫的一點就是NoSQL不使用SQL作為查詢語言,至於為何在NoSQL資料儲存HBase上提供SQL介面易使用,減少編碼
4、HBase只有一個針對行健的索引
訪問HBase表中的行,只有三種方式:
通過單個行健訪問 通過一個行健的區間來訪問 全表掃描總結:
1、HBase資料庫是BigTable的開源實現,和BigTable一樣,支援大規模海量資料,分散式併發資料處理效率極高,易於擴充套件且支援動態伸縮,適用於廉價裝置 2、HBase可以支援NativeJava API、HBaseShell、ThriftGateway、Hive等多種訪問介面,可以根據具體應用場合選擇相應訪問方式 3、HBase實際上就是一個稀疏、多維、持久化儲存的對映表,它採用行鍵、列鍵和時間戳進行索引,每個值都是未經解釋的字串。 4、HBase採用分割槽儲存,一個大的表會被分拆許多個Region,這些Region會被分發到不同的伺服器上實現分散式儲存 5、HBase的系統架構包括客戶端、Zookeeper伺服器、Master主伺服器、Region伺服器。客戶端包含訪問HBase的介面;Zookeeper伺服器負責提供穩定可靠的協同服務;Master主伺服器主要負責表和Region的管理工作;Region伺服器負責維護分配給自己的Region,並響應使用者的讀寫請求
相關推薦
一文讀懂分散式資料庫Hbase
一、 1、什麼是Hbase。 是一個高可靠性、高效能、列儲存、可伸縮、實時讀寫的分散式資料庫系統。 適合於儲存非結構化資料,基於列的而不是基於行的模式 如圖:Hadoop生態中HBase與其他部分的關係。 2、關係資料庫已經流行很多年,並且Hadoop已經有了HDFS和M
一文讀懂資料庫原理
如果有人問你資料庫的原理,叫他看這篇文章 2016/05/03 · IT技術 · 48 評論 · 資料庫 一提到關係型資料庫,我禁不住想:有些東西被忽視了。關係型資料庫無處不在,而且種類繁多,從小巧實用的 SQLite 到強大的 Teradata 。但很少有文章講解資
服務端技術進階(四)一篇文讀懂分散式系統本質:高吞吐、高可用、可擴充套件
服務端技術進階( 四)一篇文讀懂分散式系統本質:高吞吐、高可用、可擴充套件 承載量是分散式系統存在的原因 當一個網際網路業務獲得大眾歡迎的時候,最顯著碰到的技術問題,就是伺服器非常繁忙。當每天有1000萬個使用者訪問你的網站時,無論你使用什麼樣的伺服
一文讀懂微服務監控之分散式追蹤
現在越來越多的應用遷移到基於微服務的雲原生的架構之上,微服務架構很強大,但是同時也帶來了很多的挑戰,尤其是如何對應用進行除錯,如何
一文讀懂 Redis 分散式部署方案
為什麼要分散式 Redis是一款開源的基於記憶體的K-V型資料庫,因為記憶體訪問速度快,一般被用來做系統的快取。 Redis作為單機部署能夠支援業務簡單,資料量不大的系統需求,但在實際應用中,一旦系統規模上來,單機的Redis就會遇到下面的挑戰: 伸縮性。系統隨著長期執行與業務增長,對Redi
一文讀懂 SuperEdge 分散式健康檢查(雲端)
杜楊浩,騰訊雲高階工程師,熱衷於開源、容器和Kubernetes。目前主要從事映象倉庫、Kubernetes叢集高可用&備份還原,以及邊緣計算相關研發工作。 ## 前言 SuperEdge分散式健康檢查功能由邊端的edge-health-daemon以及雲端的edge-health-admissi
一文讀懂大數據計算框架與平臺
ddr 不同 失敗 克服 可定制 同時 數據庫引擎 後處理 alc 1.前言 計算機的基本工作就是處理數據,包括磁盤文件中的數據,通過網絡傳輸的數據流或數據包,數據庫中的結構化數據等。隨著互聯網、物聯網等技術得到越來越廣泛的應用,數據規模不斷增加,TB、PB量級成為常
一文讀懂 超簡單的 structured stream 源碼解讀
ket exec res exce bus sin imp += work 為了讓大家理解structured stream的運行流程,我將根據一個代碼例子,講述structured stream的基本運行流程和原理。 下面是一段簡單的代碼: 1 val spark =
一文讀懂Spring Boot、微服務架構和大數據治理之間的故事
Springboot微服務架構 微服務的誕生並非偶然,它是在互聯網高速發展,技術日新月異的變化以及傳統架構無法適應快速變化等多重因素的推動下誕生的產物。互聯網時代的產品通常有兩類特點:需求變化快和用戶群體龐大,在這種情況下,如何從系統架構的角度出發,構建靈活、易擴展的系統,快速應對需求的變化;同時,隨著用戶的
一文讀懂阻塞、非阻塞、同步、異步IO
UC max register class 掃描 基本 角度 cloud 問題: 介紹 在談及網絡IO的時候總避不開阻塞、非阻塞、同步、異步、IO多路復用、select、poll、epoll等這幾個詞語。在面試的時候也會被經常問到這幾個的區別。本文就來講一下這幾個詞
一文讀懂架構師都不知道的isinstance檢查機制
Python起步通過內建方法 isinstance(object, classinfo) 可以判斷一個對象是否是某個類的實例。但你是否想過關於鴨子協議的對象是如何進行判斷的呢? 比如 list 類的父類是繼 object 類的,但通過 isinstance([], typing.Iterable) 返回的卻是
【深度學習】一文讀懂機器學習常用損失函數(Loss Function)
back and 們的 wiki 導出 歐氏距離 classes 自變量 關於 最近太忙已經好久沒有寫博客了,今天整理分享一篇關於損失函數的文章吧,以前對損失函數的理解不夠深入,沒有真正理解每個損失函數的特點以及應用範圍,如果文中有任何錯誤,請各位朋友指教,謝謝~
從HTTP/0.9到HTTP/2:一文讀懂HTTP協議的歷史演變和設計思路
eight 結果 key 視頻 this sso單點登陸 會有 研究 patch 本文原作者阮一峰,作者博客:ruanyifeng.com。 1、引言 HTTP 協議是最重要的互聯網基礎協議之一,它從最初的僅為瀏覽網頁的目的進化到現在,已經是短連接通信的事實工業標準,最新版
一文讀懂以太坊代幣合約
規則 sta ini class 2015年 交易 存在 部分 生活 本文首發自 https://www.secpulse.com/archives/73696.html ,轉載請註明出處。 工欲善其事,必先利其器。要想挖掘和分析智能合約的漏洞,你必須要先學會看
什麽是音視頻直播雲服務 ? 一文讀懂
type 限制 推流 數據 優缺點 視頻通訊系統 最終 通訊 地理 說到音視頻雲服務,大多數人可能聯想到的是網絡直播應用場景,實際上,硬件對音視頻雲服務的需求也在逐漸提升。而這樣的市場需求也推動了整個行業的發展,目前,阿裏雲、騰訊雲和網易雲等巨頭都已入局,除此之外還有即構科
一文讀懂機器學習大殺器XGBoost原理
結構 近似算法 機器 form con gin fff .cn tran http://blog.itpub.net/31542119/viewspace-2199549/ XGBoost是boosting算法的其中一種。Boosting算法的思想是將許多弱分類器集成在
一文讀懂什麽是Java中的自動拆裝箱
.com 空指針異常 http har 三目運算 容器 ava eof 關系 基本數據類型 基本類型,或者叫做內置類型,是Java中不同於類(Class)的特殊類型。它們是我們編程中使用最頻繁的類型。 Java是一種強類型語言,第一次申明變量必須說明數據類型,第一次變量
一文讀懂高性能網絡編程中的I/O模型
好的 min tcp 輸入 其中 那些事 follow hand 實現 1、前言 隨著互聯網的發展,面對海量用戶高並發業務,傳統的阻塞式的服務端架構模式已經無能為力。本文(和下篇《高性能網絡編程(六):一文讀懂高性能網絡編程中的線程模型》)旨在為大家提供有用的高性能網絡編程
一文讀懂充電寶usb接口電路及制作原理詳細
合規 其它 註意 pan 排列 ron 充電寶 需要 資料 轉自:http://www.elecfans.com/dianlutu/dianyuandianlu/20180511675801.html USB充電器套件,又名MP3/MP4充電器,輸入AC160-240V,5
一文讀懂AI網路結構:LeNet-5 AlexNet VGG Inception ResNet MobileNet
1 引言 當前深度學習十分火熱,深度學習網路模型對於降低錯誤率的重要作用不言而喻。深度學習應用場景主要分為三類:物體識別與分類,物體檢測,自然語言處理。在物體識別與分類領域,隨著AlexNet在2012年一炮走紅,深度學習重新燃起了一片熱情。從Lenet5第一次使用卷積開始,經歷了AlexNet