
【本人禿頂程式設計師】Kafka 的 Lag 計算誤區及正確實現
←←←←←←←←←←←← 快,點關注!
前言
訊息堆積是訊息中介軟體的一大特色,訊息中介軟體的流量削峰、冗餘儲存等功能正是得益於訊息中介軟體的訊息堆積能力。然而訊息堆積其實是一把亦正亦邪的雙刃劍,如果應用場合不恰當反而會對上下游的業務造成不必要的麻煩,比如訊息堆積勢必會影響上下游整個呼叫鏈的時效性,有些中介軟體如RabbitMQ在發生訊息堆積時在某些情況下還會影響自身的效能。對於Kafka而言,雖然訊息堆積不會對其自身效能帶來多大的困擾,但難免不會影響上下游的業務,堆積過多有可能會造成磁碟爆滿,或者觸發日誌清除策略而造成訊息丟失的情況。如何利用好訊息堆積這把雙刃劍,監控是最為關鍵的一步。
正文
訊息堆積是消費滯後(Lag)的一種表現形式,訊息中介軟體服務端中所留存的訊息與消費掉的訊息之間的差值即為訊息堆積量,也稱之為消費滯後(Lag)量。對於Kafka而言,訊息被髮送至Topic中,而Topic又分成了多個分割槽(Partition),每一個Partition都有一個預寫式的日誌檔案,雖然Partition可以繼續細分為若干個段檔案(Segment),但是對於上層應用來說可以將Partition看成最小的儲存單元(一個由多個Segment檔案拼接的“巨型檔案”)。每個Partition都由一系列有序的、不可變的訊息組成,這些訊息被連續的追加到Partition中。我們來看下圖,其就是Partition的一個真實寫照:

上圖中有四個概念:
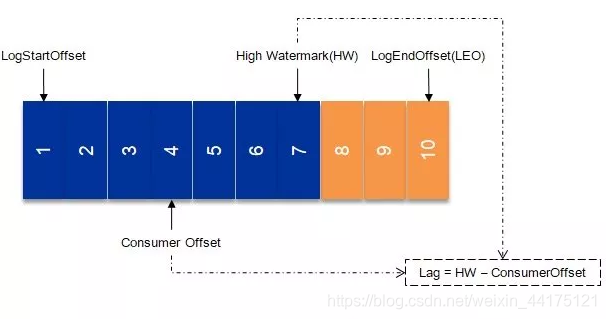
- LogStartOffset:表示一個Partition的起始位移,初始為0,雖然訊息的增加以及日誌清除策略的影響,這個值會階段性的增大。
- ConsumerOffset:消費位移,表示Partition的某個消費者消費到的位移位置。
- HighWatermark:簡稱HW,代表消費端所能“觀察”到的Partition的最高日誌位移,HW大於等於ConsumerOffset的值。
- LogEndOffset:簡稱LEO,
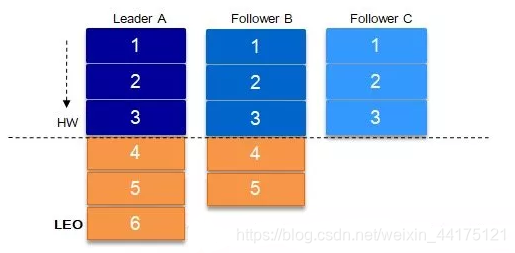
代表Partition的最高日誌位移,其值對消費者不可見。比如在ISR(In-Sync-Replicas)副本數等於3的情況下(如下圖所示),訊息傳送到Leader
A之後會更新LEO的值,Follower B和Follower C也會實時拉取Leader
A中的訊息來更新自己,HW就表示A、B、C三者同時達到的日誌位移,也就是A、B、C三者中LEO最小的那個值。由於B、C拉取A訊息之間延時問題,所以HW必然不會一直與Leader的LEO相等,即LEO>=HW。
要計算Kafka中某個消費者的滯後量很簡單,首先看看其消費了幾個Topic,然後針對每個Topic來計算其中每個Partition的Lag,每個Partition的Lag計算就顯得非常的簡單了,參考下圖:
由圖可知消費Lag=HW - ConsumerOffset。對於這裡大家有可能有個誤區,就是認為Lag應該是LEO與ConsumerOffset之間的差值,筆者在這之前也犯過這樣的錯誤認知,詳細可以參考《如何使用JMX監控Kafka》。LEO是對消費者不可見的,既然不可見何來消費滯後一說。
那麼這裡就引入了一個新的問題,HW和ConsumerOffset的值如何獲取呢?
首先來說說ConsumerOffset,Kafka中有兩處可以儲存,一個是Zookeeper,而另一個是”__consumer_offsets這個內部topic中,前者是0.8.x版本中的使用方式,但是隨著版本的迭代更新,現在越來越趨向於後者。就拿1.0.0版本來說,雖然預設是儲存在”__consumer_offsets”中,但是保不齊用於就將其儲存在了Zookeeper中了。這個問題倒也不難解決,針對兩種方式都去拉取,然後哪個有值的取哪個。不過這裡還有一個問題,對於消費位移來說,其一般不會實時的更新,而更多的是定時更新,這樣可以提高整體的效能。那麼這個定時的時間間隔就是ConsumerOffset的誤差區間之一。
再來說說HW,其也是Kafka中Partition的一個狀態。有可能你會察覺到在Kafka的JMX中可以看到“kafka.log:type=Log,name=LogEndOffset,topic=[topic_name],partition=[partition_num]”這樣一個屬性,但是這個值不是LEO而是HW。
那麼怎樣正確的計算消費的Lag呢?對Kafka熟悉的同學可能會想到Kafka中自帶的kafka-consumer_groups.sh指令碼中就有Lag的資訊,示例如下:
1[[email protected] kafka_2.12-1.0.0]# bin/kafka-consumer-groups.sh --describe --bootstrap-server localhost:9092 --group CONSUMER_GROUP_ID
2TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
3topic-test1 0 1648 1648 0 CLIENT_ID-e2d41f8d-dbd2-4f0e-9239-efacb55c6261 /192.168.92.1 CLIENT_ID
4topic-test1 1 1648 1648 0 CLIENT_ID-e2d41f8d-dbd2-4f0e-9239-efacb55c6261 /192.168.92.1 CLIENT_ID
5topic-test1 2 1648 1648 0 CLIENT_ID-e2d41f8d-dbd2-4f0e-9239-efacb55c6261 /192.168.92.1 CLIENT_ID
6topic-test1 3 1648 1648 0 CLIENT_ID-e2d41f8d-dbd2-4f0e-9239-efacb55c6261 /192.168.92.1 CLIENT_ID
71
我們深究一下kafka-consumer_groups.sh指令碼,發現只有一句程式碼:
1exec $(dirname $0)/kafka-run-class.sh kafka.admin.ConsumerGroupCommand "[email protected]"
其含義就是執行kafka.admin.ConsumerGroupCommand而已。進一步深究,在ConsumerGroupCommand內部抓住了2句關鍵程式碼:
1val consumerGroupService = new KafkaConsumerGroupService(opts)
2val (state, assignments) = consumerGroupService.describeGroup()
程式碼詳解:consumerGroupService的型別是ConsumerGroupServicesealed trait型別),而KafkaConsumerGroupService只是ConsumerGroupService的一種實現,還有一種實現是ZkConsumerGroupService,分別對應新版的消費方式(消費位移儲存在__consumer_offsets中)和舊版的消費方式(消費位移儲存在zk中),詳細計算步驟參考下一段落的內容。opt引數是指“ –describe –bootstrap-server localhost:9092 –group CONSUMER_GROUP_ID”等引數。第2句程式碼是呼叫describeGroup()方法來獲取具體的資訊,即二元組中的assignments,這個assignments中儲存了上面列印資訊中的所有內容。
Scala小知識:
在Scala中trait(特徵)相當於Java的介面,實際上它比介面更大強大。與Java中的介面不同的是,它還可以定義屬性和方法的實現(JDK8起的介面預設方法)。一般情況下Scala中的類只能繼承單一父類,但是如果是trait的話就可以繼承多個,從結果來看是實現了多重繼承。被sealed宣告的trait僅能被同一檔案的類繼承。
ZkConsumerGroupService中計算消費lag的步驟如下:
通過zk獲取一些基本資訊,對應上面列印資訊中的:TOPIC、PARTITION、CONSUMER-ID等,不過不會有HOST和CLIENT-ID。
1、通過OffsetFetchRequest請求獲取消費位移(offset),如果獲取失敗則在通過zk獲取。
2、通過OffsetReuqest請求獲取分割槽的LogEndOffset(簡稱為LEO,可見的LEO)。
3、計算LogEndOffset與消費位移的差值來獲取lag。
4、KafkaConsumerGroupService中計算消費lag的步驟如下:
通過DescibeGroupsRequest請求獲取一些基本資訊,不僅包括TOPIC、PARTITION、CONSUMER-ID,還有HOST和CLIENT-ID。其實還有通過
1、FindCoordinatorRequest請求來獲取coordinator資訊,如果不瞭解coordinator在這裡也沒影響。
2、通過OffsetFetchRequest請求獲取消費位移。
3、通過OffsetReuqest請求獲取分割槽的LogEndOffset(簡稱為LEO)。
4、計算LogEndOffset與消費位移的差值來獲取lag。
可以看到KafkaConsumerGroupService與ZkConsumerGroupService的計算Lag的方式都差不多,但是KafkaConsumerGroupService能獲取更多消費詳情,並且ZkConsumerGroupService也被標註為@Deprecated的了,後面內容都針對KafkaConsumerGroupService來做說明。既然Kafka已經為我們提供了執行緒的方法來獲取Lag,那麼我們有何必再重複造輪子,這裡筆者寫了一個呼叫的KafkaConsumerGroupService的示例(KafkaConsumerGroupService是使用Scala語言編寫的,在Java的程式裡使用類似scala.collection.Seq這樣的全名稱以防止混淆):
1String[] agrs = {"--describe", "--bootstrap-server", brokers, "--group", groupId};
2ConsumerGroupCommand.ConsumerGroupCommandOptions opts =
3 new ConsumerGroupCommand.ConsumerGroupCommandOptions(agrs);
4ConsumerGroupCommand.KafkaConsumerGroupService kafkaConsumerGroupService =
5 new ConsumerGroupCommand.KafkaConsumerGroupService(opts);
6scala.Tuple2<scala.Option<String>, scala.Option<scala.collection.Seq<ConsumerGroupCommand
7 .PartitionAssignmentState>>> res = kafkaConsumerGroupService.describeGroup();
8scala.collection.Seq<ConsumerGroupCommand.PartitionAssignmentState> pasSeq = res._2.get();
9scala.collection.Iterator<ConsumerGroupCommand.PartitionAssignmentState> iterable = pasSeq.iterator();
10while (iterable.hasNext()) {
11 ConsumerGroupCommand.PartitionAssignmentState pas = iterable.next();
12 System.out.println(String.format("\n%-30s %-10s %-15s %-15s %-10s %-50s%-30s %s",
13 pas.topic().get(), pas.partition().get(), pas.offset().get(),
14 pas.logEndOffset().get(), pas.lag().get(), pas.consumerId().get(),
15 pas.host().get(), pas.clientId().get()));
16}
在使用時,你可以封裝一下這段程式碼然後返回一個類似List<consumergroupcommand.partitionassignmentstate style=“box-sizing: border-box;”>的東西給上層業務程式碼做進一步的使用。ConsumerGroupCommand.PartitionAssignmentState的程式碼如下:</consumergroupcommand.partitionassignmentstate>
1case class PartitionAssignmentState(
2 group: String, coordinator: Option[Node], topic: Option[String],
3 partition: Option[Int], offset: Option[Long], lag: Option[Long],
4 consumerId: Option[String], host: Option[String],
5 clientId: Option[String], logEndOffset: Option[Long])
Scala小知識:
對於case class, 在這裡你可以簡單的把它看成是一個JavaBean,但是它遠比JavaBean強大,比如它會自動生成equals、hashCode、toString、copy、伴生物件、apply、unapply等等東西。在 scala 中,對保護(Protected)成員的訪問比 java 更嚴格一些。因為它只允許保護成員在定義了該成員的的類的子類中被訪問。而在java中,用protected關鍵字修飾的成員,除了定義了該成員的類的子類可以訪問,同一個包裡的其他類也可以進行訪問。Scala中,如果沒有指定任何的修飾符,則預設為 public。這樣的成員在任何地方都可以被訪問。
如果你正在試著執行上面一段程式,你會發現編譯失敗,報錯:cannot access ‘kafka.admin.ConsumerGroupCommand.PartitionAssignmentState’ in ‘kafka.admin.ConsumerGroupCommand‘。這時候需要將所引入的kafka.core包中的kafka.admin.ConsumerGroupCommand中的PartitionAssignmentState類前面的protected修飾符去掉才能編譯通過。
歡迎大家加入粉絲群:963944895,群內免費分享Spring框架、Mybatis框架SpringBoot框架、SpringMVC框架、SpringCloud微服務、Dubbo框架、Redis快取、RabbitMq訊息、JVM調優、Tomcat容器、MySQL資料庫教學視訊及架構學習思維導圖