
【本人禿頂程式設計師】阿里P7淺析如何設計一個億級閘道器
←←←←←←←←←←←← 快,點關注!
一、背景
1.1 什麼是API閘道器
API閘道器可以看做系統與外界聯通的入口,我們可以在閘道器進行處理一些非業務邏輯的邏輯,比如許可權驗證,監控,快取,請求路由等等。
1.2 為什麼需要API閘道器
- RPC協議轉成HTTP。
由於在內部開發中我們都是以RPC協議(thrift or dubbo)去做開發,暴露給內部服務,當外部服務需要使用這個介面的時候往往需要將RPC協議轉換成HTTP協議。 - 請求路由
在我們的系統中由於同一個介面新老兩套系統都在使用,我們需要根據請求上下文將請求路由到對應的介面。 - 統一鑑權
對於鑑權操作不涉及到業務邏輯,那麼可以在閘道器層進行處理,不用下層到業務邏輯。 - 統一監控
由於閘道器是外部服務的入口,所以我們可以在這裡監控我們想要的資料,比如入參出參,鏈路時間。 - 流量控制,熔斷降級
對於流量控制,熔斷降級非業務邏輯可以統一放到閘道器層。
有很多業務都會自己去實現一層閘道器層,用來接入自己的服務,但是對於整個公司來說這還不夠。
1.3 統一API閘道器
統一的API閘道器不僅有API閘道器的所有的特點,還有下面幾個好處:
- 統一技術元件升級
在公司中如果有某個技術元件需要升級,那麼是需要和每個業務線溝通,通常幾個月都搞不定。舉個例子如果對於入口的安全鑑權有重大安全隱患需要升級,如果速度還是這麼慢肯定是不行,那麼有了統一的閘道器升級是很快的。 - 統一服務接入
對於某個服務的接入也比較困難,比如公司已經研發出了比較穩定的服務元件,正在公司大力推廣,這個週期肯定也特別漫長,由於有了統一閘道器,那麼只需要統一閘道器統一接入。 - 節約資源
不同業務不同部門如果按照我們上面的做法應該會都自己搞一個閘道器層,用來做這個事,可以想象如果一個公司有100個這種業務,每個業務配備4臺機器,那麼就需要400臺機器。並且每個業務的開發RD都需要去開發這個閘道器層,去隨時去維護,增加人力。如果有了統一閘道器層,那麼也許只需要50臺機器就可以做這100個業務的閘道器層的事,並且業務RD不需要隨時關注開發,上線的步驟。
歡迎大家加入粉絲群:963944895,群內免費分享Spring框架、Mybatis框架SpringBoot框架、SpringMVC框架、SpringCloud微服務、Dubbo框架、Redis快取、RabbitMq訊息、JVM調優、Tomcat容器、MySQL資料庫教學視訊及架構學習思維導圖
二、統一閘道器的設計
2.1 非同步化請求
對於我們自己實現的閘道器層,由於只有我們自己使用,對於吞吐量的要求並不高所以,我們一般同步請求呼叫即可。
對於我們統一的閘道器層,如何用少量的機器接入更多的服務,這就需要我們的非同步,用來提高更多的吞吐量。對於非同步化一般有下面兩種策略:
- Tomcat/Jetty+NIO+servlet3
這種策略使用的比較普遍,京東,有贊,Zuul,都選取的是這個策略,這種策略比較適合HTTP。在Servlet3中可以開啟非同步。 - Netty+NIO
Netty為高併發而生,目前唯品會的閘道器使用這個策略,在唯品會的技術文章中在相同的情況下Netty是每秒30w+的吞吐量,Tomcat是13w+,可以看出是有一定的差距的,但是Netty需要自己處理HTTP協議,這一塊比較麻煩。
對於閘道器是HTTP請求場景比較多的情況可以採用Servlet,畢竟有更加成熟的處理HTTP協議。如果更加重視吞吐量那麼可以採用Netty。
2.1.1 全鏈路非同步
對於來的請求我們已經使用非同步了,為了達到全鏈路非同步所以我們需要對去的請求也進行非同步處理,對於去的請求我們可以利用我們rpc的非同步支援進行非同步請求所以基本可以達到下圖:
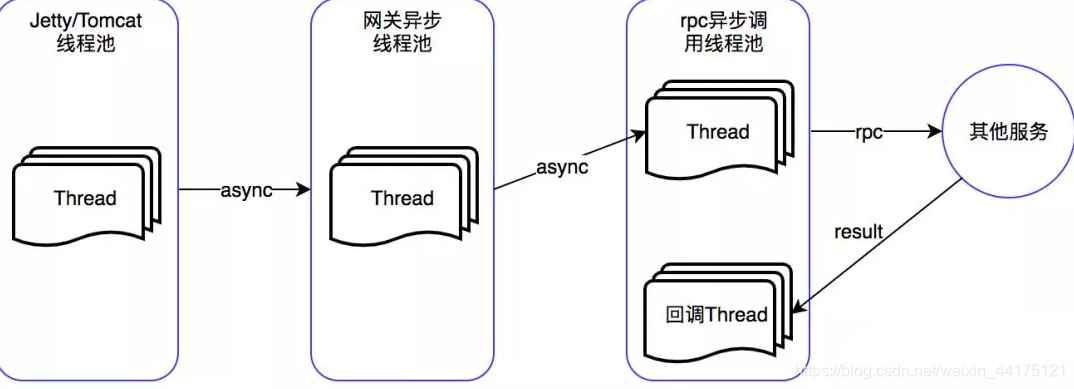
由在web容器中開啟servlet非同步,然後進入到閘道器的業務執行緒池中進行業務處理,然後進行rpc的非同步呼叫並註冊需要回調的業務,最後在回撥執行緒池中進行回撥處理。
2.2 鏈式處理
在設計模式中有一個模式叫責任鏈模式,他的作用是避免請求傳送者與接收者耦合在一起,讓多個物件都有可能接收請求,將這些物件連線成一條鏈,並且沿著這條鏈傳遞請求,直到有物件處理它為止。通過這種模式將請求的傳送者和請求的處理者解耦了。在我們的各個框架中對此模式都有實現,比如servlet裡面的filter,springmvc裡面的Interceptor。
在Netflix Zuul中也應用了這種模式,如下圖所示:
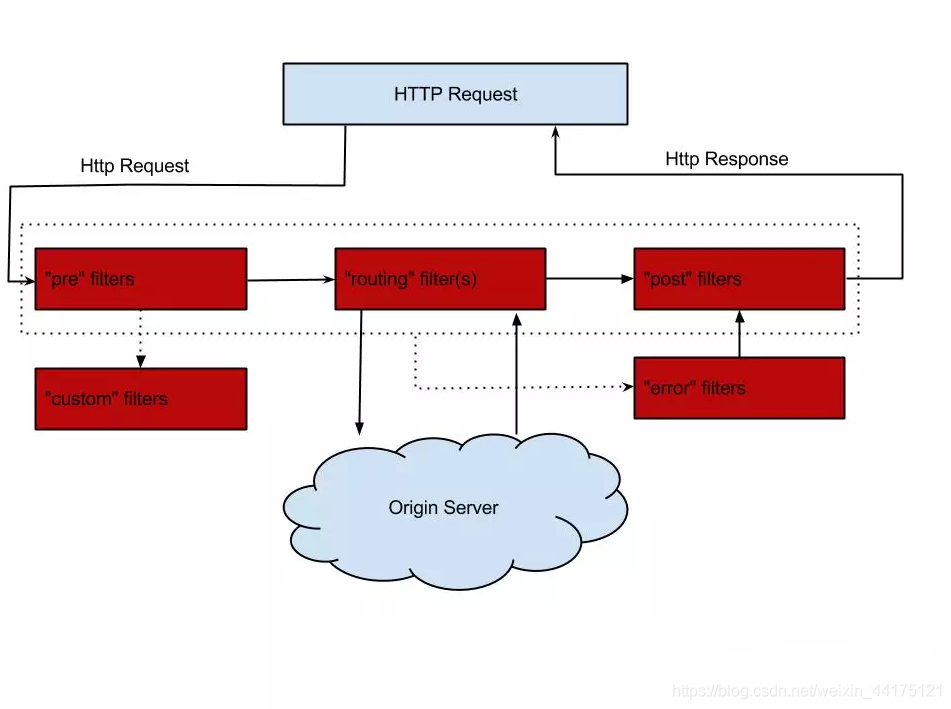
這種模式在閘道器的設計中我們可以借鑑到自己的閘道器設計:
- preFilters:前置過濾器,用來處理一些公共的業務,比如統一鑑權,統一限流,熔斷降級,快取處理等,並且提供業務方擴充套件。
- routingFilters: 用來處理一些泛化呼叫,主要是做協議的轉換,請求的路由工作。
- postFilters: 後置過濾器,主要用來做結果的處理,日誌打點,記錄時間等等。
- errorFilters: 錯誤過濾器,用來處理呼叫異常的情況。
這種設計在有讚的閘道器也有應用。
2.3 業務隔離
上面在全鏈路非同步的情況下不同業務之間的影響很小,但是如果在提供的自定義FiIlter中進行了某些同步呼叫,一旦超時頻繁那麼就會對其他業務產生影響。所以我們需要採用隔離之術,降低業務之間的互相影響。
2.3.1 訊號量隔離
訊號量隔離只是限制了總的併發數,服務還是主執行緒進行同步呼叫。這個隔離如果遠端呼叫超時依然會影響主執行緒,從而會影響其他業務。因此,如果只是想限制某個服務的總併發呼叫量或者呼叫的服務不涉及遠端呼叫的話,可以使用輕量級的訊號量來實現。有讚的閘道器由於沒有自定義filter所以選取的是訊號量隔離。
2.3.2 執行緒池隔離
最簡單的就是不同業務之間通過不同的執行緒池進行隔離,就算業務接口出現了問題由於執行緒池已經進行了隔離那麼也不會影響其他業務。在京東的閘道器實現之中就是採用的執行緒池隔離,比較重要的業務比如商品或者訂單 都是單獨的通過執行緒池去處理。但是由於是統一閘道器平臺,如果業務線眾多,大家都覺得自己的業務比較重要需要單獨的執行緒池隔離,如果使用的是Java語言開發的話那麼,在Java中執行緒是比較重的資源比較受限,如果需要隔離的執行緒池過多不是很適用。如果使用一些其他語言比如Golang進行開發閘道器的話,執行緒是比較輕的資源,所以比較適合使用執行緒池隔離。
2.3.3 叢集隔離
如果有某些業務就需要使用隔離但是統一閘道器又沒有執行緒池隔離那麼應該怎麼辦呢?那麼可以使用叢集隔離,如果你的某些業務真的很重要那麼可以為這一系列業務單獨申請一個叢集或者多個叢集,通過機器之間進行隔離。
2.4 請求限流
流量控制可以採用很多開源的實現,比如阿里最近開源的Sentinel和比較成熟的Hystrix。
一般限流分為叢集限流和單機限流:
- 利用統一儲存儲存當前流量的情況,一般可以採用Redis,這個一般會有一些效能損耗。
- 單機限流:限流每臺機器我們可以直接利用Guava的令牌桶去做,由於沒有遠端呼叫效能消耗較小。
2.5 熔斷降級
這一塊也可以參照開源的實現Sentinel和Hystrix,這裡不是重點就不多提了。
2.6 泛化呼叫
泛化呼叫指的是一些通訊協議的轉換,比如將HTTP轉換成Thrift。在一些開源的閘道器中比如Zuul是沒有實現的,因為各個公司的內部服務通訊協議都不同。比如在唯品會中支援HTTP1,HTTP2,以及二進位制的協議,然後轉化成內部的協議,淘寶的支援HTTPS,HTTP1,HTTP2這些協議都可以轉換成,HTTP,HSF,Dubbo等協議。
2.6.1泛化呼叫
如何去實現泛化呼叫呢?由於協議很難自動轉換,那麼其實每個協議對應的介面需要提供一種對映。簡單來說就是把兩個協議都能轉換成共同語言,從而互相轉換。
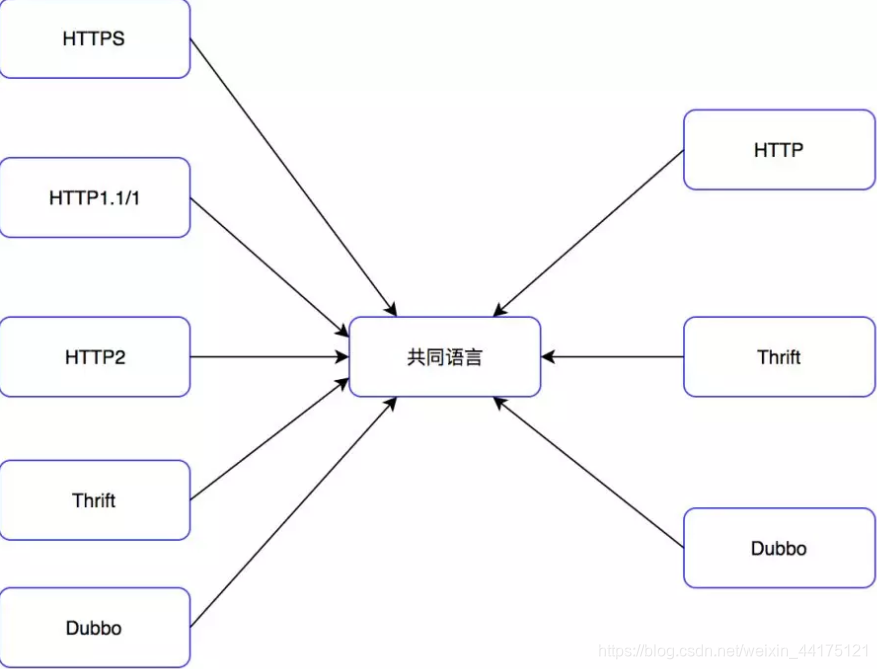
一般來說共同語言有三種方式指定:
- json:json資料格式比較簡單,解析速度快,較輕量級。在Dubbo的生態中有一個HTTP轉Dubbo的專案是用JsonRpc做的,將HTTP轉化成JsonRpc再轉化成Dubbo。
比如可以將一個 www.baidu.com/id = 1 GET 可以對映為json:
程式碼塊
{
“method”: "getBaidu"
"param" : {
"id" : 1
}
}
- xml:xml資料比較重,解析比較困難,這裡不過多討論。
- 自定義描述語言:一般來說這個成本比較高需要自己定義語言來進行描述並進行解析,但是其擴充套件性,自定義個性化性都是最高。例:spring自定義了一套自己的SPEL表示式語言
對於泛化呼叫如果要自己設計的話JSON基本可以滿足,如果對於個性化的需要特別多的話倒是可以自己定義一套語言。
2.7 管理平臺
上面介紹的都是如何實現一個閘道器的技術關鍵。這裡需要介紹閘道器的一個業務關鍵。有了閘道器之後,需要一個管理平臺如何去對我們上面所描述的技術關鍵進行配置,包括但不限於下面這些配置:
- 限流
- 熔斷
- 快取
- 日誌
- 自定義filter
- 泛化呼叫
3.總結
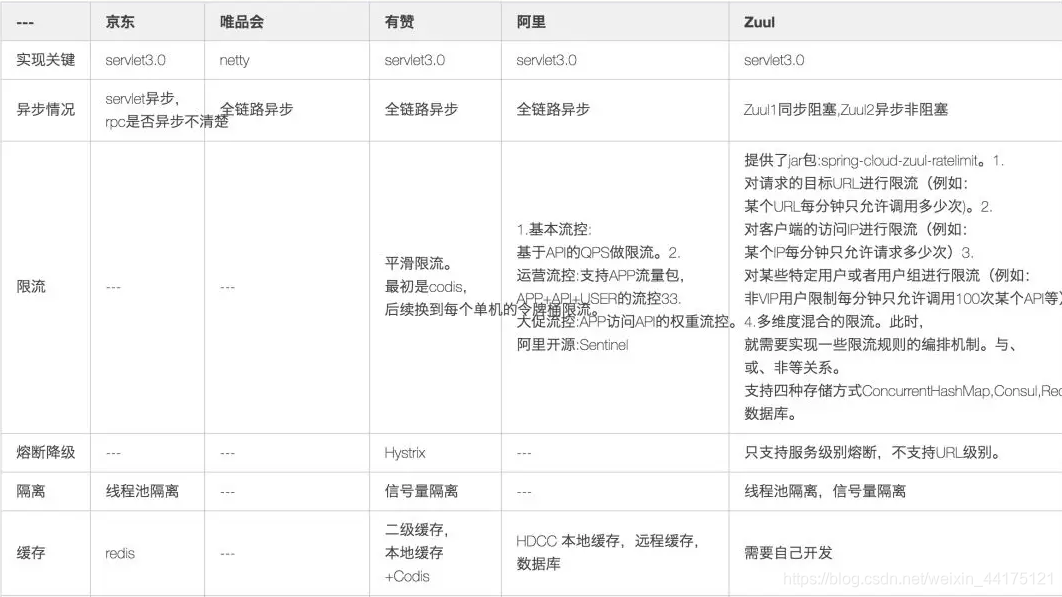
最後一個合理的標準閘道器應該按照如下去實現:

歡迎大家加入粉絲群:963944895,群內免費分享Spring框架、Mybatis框架SpringBoot框架、SpringMVC框架、SpringCloud微服務、Dubbo框架、Redis快取、RabbitMq訊息、JVM調優、Tomcat容器、MySQL資料庫教學視訊及架構學習思維導圖