
python機器學習庫xgboost——xgboost演算法
安裝
更新:現在已經可以通過pip install xgboost線上安裝庫了。
xgboost簡介
xgboost一般和sklearn一起使用,但是由於sklearn中沒有整合xgboost,所以才需要單獨下載安裝。
xgboost是在GBDT的基礎上進行改進,使之更強大,適用於更大範圍。
2. XGBoost的優點
2.1 正則化
XGBoost在代價函式里加入了正則項,用於控制模型的複雜度。正則項裡包含了樹的葉子節點個數、每個葉子節點上輸出的score的L2模的平方和。從Bias-variance tradeoff角度來講,正則項降低了模型的variance,使學習出來的模型更加簡單,防止過擬合,這也是xgboost優於傳統GBDT的一個特性。
2.2 並行處理
XGBoost工具支援並行。Boosting不是一種序列的結構嗎?怎麼並行的?注意XGBoost的並行不是tree粒度的並行,XGBoost也是一次迭代完才能進行下一次迭代的(第t次迭代的代價函式裡包含了前面t-1次迭代的預測值)。XGBoost的並行是在特徵粒度上的。
我們知道,決策樹的學習最耗時的一個步驟就是對特徵的值進行排序(因為要確定最佳分割點),XGBoost在訓練之前,預先對資料進行了排序,然後儲存為block結構,後面的迭代中重複地使用這個結構,大大減小計算量。這個block結構也使得並行成為了可能,在進行節點的分裂時,需要計算每個特徵的增益,最終選增益最大的那個特徵去做分裂,那麼各個特徵的增益計算就可以開多執行緒進行。
2.3 靈活性
XGBoost支援使用者自定義目標函式和評估函式,只要目標函式二階可導就行。
2.4 缺失值處理
對於特徵的值有缺失的樣本,xgboost可以自動學習出它的分裂方向
2.5 剪枝
XGBoost 先從頂到底建立所有可以建立的子樹,再從底到頂反向進行剪枝。比起GBM,這樣不容易陷入區域性最優解。
2.6 內建交叉驗證
XGBoost允許在每一輪boosting迭代中使用交叉驗證。因此,可以方便地獲得最優boosting迭代次數。而GBM使用網格搜尋,只能檢測有限個值。
3. XGBoost詳解
3.1 資料格式
XGBoost可以載入多種資料格式的訓練資料:
libsvm 格式的文字資料;
Numpy 的二維陣列;
XGBoost 的二進位制的快取檔案。載入的資料儲存在物件 DMatrix 中。
下面一一列舉:
載入libsvm格式的資料
dtrain1 = xgb.DMatrix('train.svm.txt')載入二進位制的快取檔案
dtrain2 = xgb.DMatrix('train.svm.buffer')載入numpy的陣列
data = np.random.rand(5,10) # 5行10列資料集
label = np.random.randint(2, size=5) # 2分類目標值
dtrain = xgb.DMatrix( data, label=label) # 組成訓練集將scipy.sparse格式的資料轉化為 DMatrix 格式
csr = scipy.sparse.csr_matrix( (dat, (row,col)) )
dtrain = xgb.DMatrix( csr )將 DMatrix 格式的資料儲存成XGBoost的二進位制格式,在下次載入時可以提高載入速度,使用方式如下
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary("train.buffer")可以用如下方式處理 DMatrix中的缺失值:
dtrain = xgb.DMatrix( data, label=label, missing = -999.0)當需要給樣本設定權重時,可以用如下方式
w = np.random.rand(5,1)
dtrain = xgb.DMatrix( data, label=label, missing = -999.0, weight=w)3.2 引數設定
XGBoost使用key-value字典的方式儲存引數:
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分類的問題
'num_class': 10, # 類別數,與 multisoftmax 並用
'gamma': 0.1, # 用於控制是否後剪枝的引數,越大越保守,一般0.1、0.2這樣子。
'max_depth': 12, # 構建樹的深度,越大越容易過擬合
'lambda': 2, # 控制模型複雜度的權重值的L2正則化項引數,引數越大,模型越不容易過擬合。
'subsample': 0.7, # 隨機取樣訓練樣本
'colsample_bytree': 0.7, # 生成樹時進行的列取樣
'min_child_weight': 3,
'silent': 1, # 設定成1則沒有執行資訊輸出,最好是設定為0.
'eta': 0.007, # 如同學習率
'seed': 1000,
'nthread': 4, # cpu 執行緒數
}3.3 訓練模型
有了引數列表和資料就可以訓練模型了
num_round = 10
bst = xgb.train( plst, dtrain, num_round, evallist )3.4 模型預測
# X_test型別可以是二維List,也可以是numpy的陣列
dtest = DMatrix(X_test)
ans = model.predict(dtest)3.5 儲存模型
在訓練完成之後可以將模型儲存下來,也可以檢視模型內部的結構
bst.save_model('test.model')匯出模型和特徵對映(Map)
你可以匯出模型到txt檔案並瀏覽模型的含義:
# 匯出模型到檔案
bst.dump_model('dump.raw.txt')
# 匯出模型和特徵對映
bst.dump_model('dump.raw.txt','featmap.txt')3.6 載入模型
通過如下方式可以載入模型:
bst = xgb.Booster({'nthread':4}) # init model
bst.load_model("model.bin") # load dataXGBoost引數詳解
在執行XGboost之前,必須設定三種類型成熟:general parameters,booster parameters和task parameters:
通用引數 :該引數引數控制在提升(boosting)過程中使用哪種booster,常用的booster有樹模型(tree)和線性模型(linear model)。
Booster引數 :這取決於使用哪種booster。
學習目標引數 :控制學習的場景,例如在迴歸問題中會使用不同的引數控制排序。
4.1 通用引數
booster [default=gbtree]:有兩中模型可以選擇gbtree和gblinear。gbtree使用基於樹的模型進行提升計算,gblinear使用線性模型進行提升計算。預設值為gbtree
silent [default=0]:取0時表示打印出執行時資訊,取1時表示以緘默方式執行,不列印執行時資訊。預設值為0
nthread:XGBoost執行時的執行緒數。預設值是當前系統可以獲得的最大執行緒數
num_pbuffer:預測緩衝區大小,通常設定為訓練例項的數目。緩衝用於儲存最後一步提升的預測結果,無需人為設定。
num_feature:Boosting過程中用到的特徵維數,設定為特徵個數。XGBoost會自動設定,無需人為設定。
4.2 tree booster引數
eta [default=0.3] :為了防止過擬合,更新過程中用到的收縮步長。在每次提升計算之後,演算法會直接獲得新特徵的權重。 eta通過縮減特徵的權重使提升計算過程更加保守。預設值為0.3
取值範圍為:[0,1]。典型值為0.01-0.2。
gamma [default=0] :在節點分裂時,只有分裂後損失函式的值下降了,才會分裂這個節點。Gamma指定了節點分裂所需的最小損失函式下降值。
這個引數的值越大,演算法越保守。這個引數的值和損失函式息息相關,所以是需要調整的。
取值範圍為:[0,∞]
max_depth [default=6] :數的最大深度。預設值為6 。取值範圍為:[1,∞]。需要使用CV函式來進行調優。典型值:3-10
min_child_weight [default=1] :孩子節點中最小的樣本權重和。如果一個葉子節點的樣本權重和小於min_child_weight則拆分過程結束。在現行迴歸模型中,這個引數是指建立每個模型所需要的最小樣本數。這個引數用於避免過擬合。當它的值較大時,可以避免模型學習到區域性的特殊樣本。
但是如果這個值過高,會導致欠擬合。這個引數需要使用CV來調整。取值範圍為:[0,∞]
max_delta_step [default=0] :我們允許每個樹的權重被估計的值。如果它的值被設定為0,意味著沒有約束;如果它被設定為一個正值,它能夠使得更新的步驟更加保守。通常這個引數是沒有必要的,但是如果在邏輯迴歸中類極其不平衡這時候他有可能會起到幫助作用。把它範圍設定為1-10之間也許能控制更新。 取值範圍為:[0,∞]
subsample [default=1] :用於訓練模型的子樣本佔整個樣本集合的比例。如果設定為0.5則意味著XGBoost將隨機的從整個樣本集合中隨機的抽取出50%的子樣本建立樹模型,這能夠防止過擬合。 取值範圍為:(0,1]
colsample_bytree [default=1] :在建立樹時對特徵取樣的比例。預設值為1 。取值範圍為:(0,1]
4.3 Linear Booster引數
lambda [default=0] :L2 正則的懲罰係數
alpha [default=0] :L1 正則的懲罰係數
lambda_bias :在偏置上的L2正則。預設值為0(在L1上沒有偏置項的正則,因為L1時偏置不重要)
4.4 學習目標引數
objective [ default=reg:linear ] :定義學習任務及相應的學習目標,可選的目標函式如下:
- “reg:linear” —— 線性迴歸。
- “reg:logistic”—— 邏輯迴歸。
- “binary:logistic”—— 二分類的邏輯迴歸問題,輸出為概率。
- “binary:logitraw”—— 二分類的邏輯迴歸問題,輸出的結果為wTx。
- “count:poisson”—— 計數問題的poisson迴歸,輸出結果為poisson分佈。在poisson迴歸中,max_delta_step的預設值為0.7。(used to safeguard optimization)
- “multi:softmax” –讓XGBoost採用softmax目標函式處理多分類問題,同時需要設定引數num_class(類別個數)
- “multi:softprob” –和softmax一樣,但是輸出的是ndata * nclass的向量,可以將該向量reshape成ndata行nclass列的矩陣。沒行資料表示樣本所屬於每個類別的概率。
- “rank:pairwise” –set XGBoost to do ranking task by minimizing the pairwise loss
base_score [ default=0.5 ]
所有例項的初始化預測分數,全域性偏置;
當有足夠的迭代次數時,改變這個值將不會有太大的影響。
eval_metric [ default according to objective ]
校驗資料所需要的評價指標,不同的目標函式將會有預設的評價指標(rmse for regression, and error for classification, mean average precision for ranking)-
使用者可以新增多種評價指標,對於Python使用者要以list傳遞引數對給程式,而不是map引數list引數不會覆蓋’eval_metric’
可供的選擇如下:
- rmse 均方根誤差()
- mae 平均絕對誤差()
- logloss 負對數似然函式值
- error 二分類錯誤率(閾值為0.5)
- merror 多分類錯誤率
- mlogloss 多分類logloss損失函式
- auc 曲線下面積
seed [ default=0 ]
隨機數的種子。預設值為0
xgboost 基本方法和預設引數
函式原型:
xgboost.train(params,dtrain,num_boost_round=10,evals=(),obj=None,feval=None,maximize=False,early_stopping_rounds=None,evals_result=None,verbose_eval=True,learning_rates=None,xgb_model=None) params :這是一個字典,裡面包含著訓練中的引數關鍵字和對應的值,形式是params = {‘booster’:’gbtree’, ’eta’:0.1}
dtrain :訓練的資料
num_boost_round :這是指提升迭代的個數
evals :這是一個列表,用於對訓練過程中進行評估列表中的元素。形式是evals = [(dtrain,’train’), (dval,’val’)]或者是evals = [ (dtrain,’train’)], 對於第一種情況,它使得我們可以在訓練過程中觀察驗證集的效果。
obj:自定義目的函式
feval:自定義評估函式
maximize: 是否對評估函式進行最大化
early_stopping_rounds: 早期停止次數 ,假設為100,驗證集的誤差迭代到一定程度在100次內不能再繼續降低,就停止迭代。這要求evals 裡至少有一個元素,如果有多個,按最後一個去執行。返回的是最後的迭代次數(不是最好的)。如果early_stopping_rounds 存在,則模型會生成三個屬性,bst.best_score, bst.best_iteration, 和bst.best_ntree_limit
evals_result :字典,儲存在watchlist 中的元素的評估結果。
verbose_eval(可以輸入布林型或數值型):也要求evals 裡至少有 一個元素。如果為True, 則對evals中元素的評估結果會輸出在結果中;如果輸入數字,假設為5,則每隔5個迭代輸出一次。
learning_rates :每一次提升的學習率的列表,
xgb_model:在訓練之前用於載入的xgb model。
5. XGBoost實戰
XGBoost有兩大類介面:XGBoost原生介面 和 scikit-learn介面 ,並且XGBoost能夠實現 分類 和 迴歸 兩種任務。因此,本章節分四個小塊來介紹!
5.1 基於XGBoost原生介面的分類
# ================基於XGBoost原生介面的分類=============
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 準確率
# 載入樣本資料集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 資料集分割
# 演算法引數
params = {
'booster': 'gbtree',
'objective': 'multi:softmax',
'num_class': 3,
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
plst = params.items()
dtrain = xgb.DMatrix(X_train, y_train) # 生成資料集格式
num_rounds = 500
model = xgb.train(plst, dtrain, num_rounds) # xgboost模型訓練
# 對測試集進行預測
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 計算準確率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 顯示重要特徵
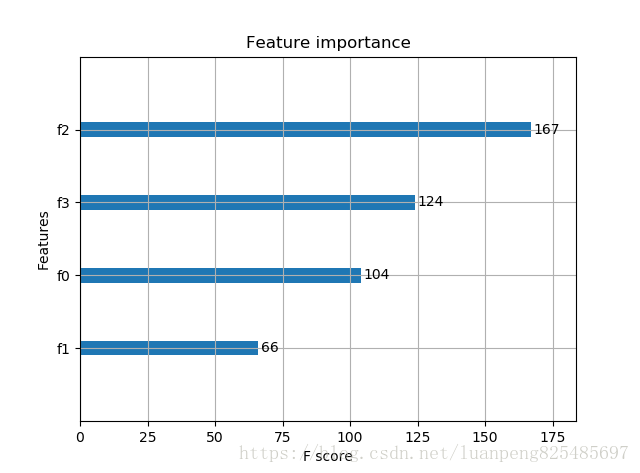
plot_importance(model)
plt.show()輸出預測正確率以及特徵重要性:
Accuracy: 96.67 %
5.2 基於XGBoost原生介面的迴歸
# ================基於XGBoost原生介面的迴歸=============
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 載入資料集
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost訓練過程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:gamma',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = params.items()
model = xgb.train(plst, dtrain, num_rounds)
# 對測試集進行預測
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 顯示重要特徵
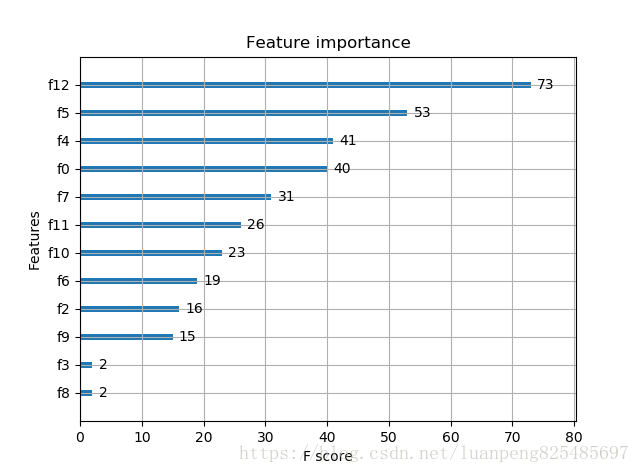
plot_importance(model)
plt.show()
重要特徵(值越大,說明該特徵越重要)顯示結果:
xgb使用sklearn介面(推薦)
XGBClassifier
from xgboost.sklearn import XGBClassifier
clf = XGBClassifier(
silent=0 ,#設定成1則沒有執行資訊輸出,最好是設定為0.是否在執行升級時列印訊息。
#nthread=4,# cpu 執行緒數 預設最大
learning_rate= 0.3, # 如同學習率
min_child_weight=1,
# 這個引數預設是 1,是每個葉子裡面 h 的和至少是多少,對正負樣本不均衡時的 0-1 分類而言
#,假設 h 在 0.01 附近,min_child_weight 為 1 意味著葉子節點中最少需要包含 100 個樣本。
#這個引數非常影響結果,控制葉子節點中二階導的和的最小值,該引數值越小,越容易 overfitting。
max_depth=6, # 構建樹的深度,越大越容易過擬合
gamma=0, # 樹的葉子節點上作進一步分割槽所需的最小損失減少,越大越保守,一般0.1、0.2這樣子。
subsample=1, # 隨機取樣訓練樣本 訓練例項的子取樣比
max_delta_step=0,#最大增量步長,我們允許每個樹的權重估計。
colsample_bytree=1, # 生成樹時進行的列取樣
reg_lambda=1, # 控制模型複雜度的權重值的L2正則化項引數,引數越大,模型越不容易過擬合。
#reg_alpha=0, # L1 正則項引數
#scale_pos_weight=1, #如果取值大於0的話,在類別樣本不平衡的情況下有助於快速收斂。平衡正負權重
#objective= 'multi:softmax', #多分類的問題 指定學習任務和相應的學習目標
#num_class=10, # 類別數,多分類與 multisoftmax 並用
n_estimators=100, #樹的個數
seed=1000 #隨機種子
#eval_metric= 'auc'
)
clf.fit(X_train,y_train,eval_metric='auc')5.3 基於Scikit-learn介面的分類
# ==============基於Scikit-learn介面的分類================
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 載入樣本資料集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 資料集分割
# 訓練模型
model = xgb.XGBClassifier(max_depth=5, learning_rate=0.1, n_estimators=160, silent=True, objective='multi:softmax')
model.fit(X_train, y_train)
# 對測試集進行預測
y_pred = model.predict(X_test)
# 計算準確率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 顯示重要特徵
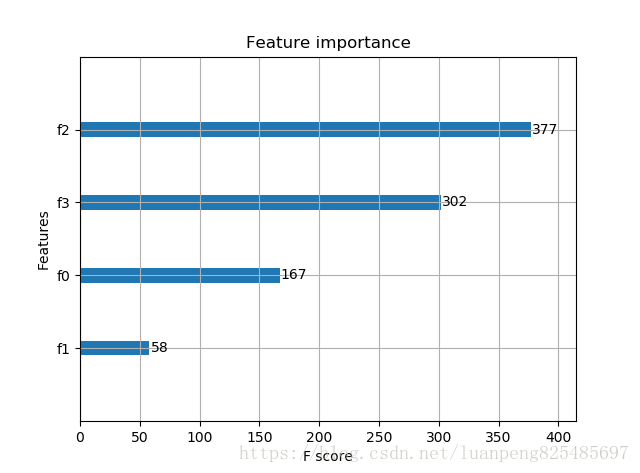
plot_importance(model)
plt.show()
輸出結果:Accuracy: 96.67 %
基於Scikit-learn介面的迴歸
# ================基於Scikit-learn介面的迴歸================
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost訓練過程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
model = xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=160, silent=True, objective='reg:gamma')
model.fit(X_train, y_train)
# 對測試集進行預測
ans = model.predict(X_test)
# 顯示重要特徵
plot_importance(model)
plt.show()
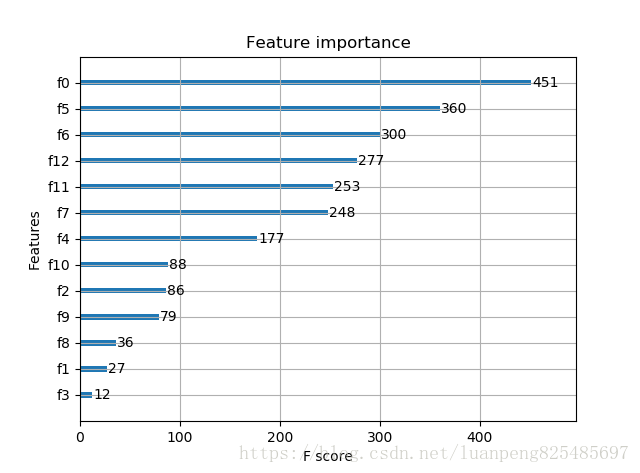
引數調優的一般方法
我們會使用和GBM中相似的方法。需要進行如下步驟:
1. 選擇較高的學習速率(learning rate)。一般情況下,學習速率的值為0.1。但是,對於不同的問題,理想的學習速率有時候會在0.05到0.3之間波動。選擇對應於此學習速率的理想決策樹數量。XGBoost有一個很有用的函式“cv”,這個函式可以在每一次迭代中使用交叉驗證,並返回理想的決策樹數量。
2. 對於給定的學習速率和決策樹數量,進行決策樹特定引數調優(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。在確定一棵樹的過程中,我們可以選擇不同的引數,待會兒我會舉例說明。
3. xgboost的正則化引數的調優。(lambda, alpha)。這些引數可以降低模型的複雜度,從而提高模型的表現。
4. 降低學習速率,確定理想引數。
咱們一起詳細地一步步進行這些操作。
第一步:確定學習速率和tree_based 引數調優的估計器數目。
為了確定boosting 引數,我們要先給其它引數一個初始值。咱們先按如下方法取值:
1、max_depth = 5 :這個引數的取值最好在3-10之間。我選的起始值為5,但是你也可以選擇其它的值。起始值在4-6之間都是不錯的選擇。
2、min_child_weight = 1:在這裡選了一個比較小的值,因為這是一個極不平衡的分類問題。因此,某些葉子節點下的值會比較小。
3、gamma = 0: 起始值也可以選其它比較小的值,在0.1到0.2之間就可以。這個引數後繼也是要調整的。
4、subsample,colsample_bytree = 0.8: 這個是最常見的初始值了。典型值的範圍在0.5-0.9之間。
5、scale_pos_weight = 1: 這個值是因為類別十分不平衡。
注意哦,上面這些引數的值只是一個初始的估計值,後繼需要調優。這裡把學習速率就設成預設的0.1。然後用xgboost中的cv函式來確定最佳的決策樹數量。
第二步: max_depth 和 min_weight 引數調優
我們先對這兩個引數調優,是因為它們對最終結果有很大的影響。首先,我們先大範圍地粗調引數,然後再小範圍地微調。
注意:在這一節我會進行高負荷的柵格搜尋(grid search),這個過程大約需要15-30分鐘甚至更久,具體取決於你係統的效能。你也可以根據自己系統的效能選擇不同的值。
第三步:gamma引數調優
第四步:調整subsample 和 colsample_bytree 引數
第五步:正則化引數調優。
第6步:降低學習速率
最後,我們使用較低的學習速率,以及使用更多的決策樹。我們可以用XGBoost中的CV函式來進行這一步工作。
相關推薦
python機器學習庫xgboost——xgboost演算法
安裝 更新:現在已經可以通過pip install xgboost線上安裝庫了。 xgboost簡介 xgboost一般和sklearn一起使用,但是由於sklearn中沒有整合xgboost,所以才需要單獨下載安裝。 xgboost是在GB
python機器學習庫scikit-learn簡明教程之:AdaBoost演算法
1.AdaBoost簡介及原理 Adaboost是一種迭代演算法,其核心思想是針對同一個訓練集訓練不同的分類器(弱分類器),然後把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。 Adab
Python機器學習庫sklearn幾種迴歸演算法建模及分析(實驗)
最簡單的迴歸模型就是線性迴歸 資料匯入與視覺化分析 from IPython.display import Image %matplotlib inline # Added version che
Python機器學習庫scikit-learn實踐
.get new 安裝 gis 支持 兩個 clas mod 神經網絡 一、概述 機器學習算法在近幾年大數據點燃的熱火熏陶下已經變得被人所“熟知”,就算不懂得其中各算法理論,叫你喊上一兩個著名算法的名字,你也能昂首挺胸脫口而出。當然了,算法之林雖大,但能者還是
2018年最受歡迎Python機器學習庫介紹
Python Python開發 Python全棧 機器學習庫 Python是一種面向對象的解釋型計算機程序設計語言,具有豐富和強大的庫,再加上其簡單、易學、速度快、開源免費、可移植性、可擴展性以及面向對象的特點,Python成為2017年最受歡迎的最受歡迎的編程語言! 人工智能是當前最
分享《Python機器學習—預測分析核心演算法》高清中文版PDF+高清英文版PDF+原始碼
下載:https://pan.baidu.com/s/1sfaOZmuRj14FWNumGQ5ahw 更多資料分享:http://blog.51cto.com/3215120 《Python機器學習—預測分析核心演算法》高清中文版PDF+高清英文版PDF+原始碼高清中文版,338頁,帶目錄和書籤,文字能夠
Python機器學習——預測分析核心演算法 pdf 下載
機器學習關注於預測,其核心是一種基於數學和演算法的技術,要掌握該技術,需要對數學及統計概念有深入理解,能夠熟練使用R 語言或者其他程式語言。 本書通過集中介紹兩類可以進行有效預測的機器學習演算法,展示瞭如何使用Python 程式語言完成機器學習任務,從而降低機器學習難度,使機器
比較好的Python機器學習庫有哪些?
Python是一種面向物件的解釋型計算機程式設計語言,具有豐富和強大的庫,再加上其簡單、易學、速度快、開源免費、可移植性、可擴充套件性以及面向物件的特點,Python成為2017年最受歡迎的最受歡迎的程式語言! 人工智慧是當前最熱門話題之一,機器學習技術是人工智慧實現必備技能,Python程式語
python機器學習庫——結巴中文分詞
結巴中文分詞 安裝: pip install jieba1 特點: 支援三種分詞模式: 精確模式,試圖將句子最精確地切開,適合文字分析; 全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義; 搜尋引擎模式,在精確
python機器學習庫的使用
常見機器學習演算法名單 1.線性迴歸 線性迴歸通常用於根據連續變數估計實際數值(房價、呼叫次數、總銷售額等)。我們通過擬合最佳直線來建立自變數和因變數的關係。這條最佳直線叫做迴歸線,並且用 Y= a *X + b 這條線性等式來表示。 理解線性迴歸的最好辦法是回顧一下童年。
Python機器學習庫sklearn裡利用感知機進行三分類(多分類)的原理
from IPython.display import Image %matplotlib inline # Added version check for recent scikit-learn 0.18 checks from distutils.vers
Python機器學習庫scikit-learn
概述 scikit-learn 是機器學習領域非常熱門的一個開源庫,基於Python 語言寫成。可以免費使用。 而且使用非常的簡單,文件感人,非常值得去學習。 下面是一張scikit-learn的圖譜: 我們可以看到,機器學習分為四大塊,分別是 cla
python機器學習庫sklearn——Lasso迴歸(L1正則化)
Lasso The Lasso 是估計稀疏係數的線性模型。 它在一些情況下是有用的,因為它傾向於使用具有較少引數值的情況,有效地減少給定解決方案所依賴變數的數量。 因此,Lasso 及其變體是壓縮感知領域的基礎。 在一定條件下,它可以恢復一組非零權重的
python機器學習庫sklearn——樸素貝葉斯分類器
在scikit-learn中,一共有3個樸素貝葉斯的分類演算法類。分別是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先驗為高斯分佈的樸素貝葉斯,MultinomialNB就是先驗為多項式分佈的樸素
python機器學習庫scikit-learn簡明教程之:SVM支援向量機
1.獲得樣例資料 scikit-learn庫有一些標準的資料集,例如分類的數字集,波士頓房價迴歸資料集。 在下面,我們啟動Python直譯器,然後載入資料集。我們可以認為,美元符號後輸入python然
python機器學習庫scikit-learn簡明教程之:隨機森林
1.scikit-learn中的隨機森林 sklearn.ensemble模組中包含兩種基於隨機決策樹的平均演算法:隨機森林演算法和ExtraTrees的方法。這兩種演算法都是專為決策樹設計的包含混合
python機器學習庫sklearn——K最近鄰、K最近鄰分類、K最近鄰迴歸
這裡只講述sklearn中如何使用KNN演算法。 無監督最近鄰 NearestNeighbors (最近鄰)實現了 unsupervised nearest neighbors learning(無監督的最近鄰學習)。 它為三種不同的最近鄰演算法
Python機器學習庫SKLearn:資料集轉換之預處理資料
資料集轉換之預處理資料: 將輸入的資料轉化成機器學習演算法可以使用的資料。包含特徵提取和標準化。 原因:資料集的標準化(服從均值為0方差為1的標準正態分佈(高斯分佈))是大多數機器學習演算法的常見要求。 如果原始資料不服從高斯分佈,在預測時
Python機器學習實戰kNN分類演算法
自學《機器學習實戰》一書,書中的程式碼親自敲一遍,努力搞懂每句程式碼的含義: 今天將第一章kNN分類演算法的筆記總結一下。 # -*- coding: utf-8 -*- """ k-近鄰演算法小結: k-近鄰演算法是基於例項的學習,k-近鄰演算法必須儲存全部資料集,
Python機器學習庫sklearn網格搜尋與交叉驗證
網格搜尋一般是針對引數進行尋優,交叉驗證是為了驗證訓練模型擬合程度。sklearn中的相關API如下: (1)交叉驗證的首要工作:切分資料集train/validation/test A.)沒指定資料切分方式,直接選用cross_val_scor