
faster rcnn 論文理解
reference link:
http://blog.csdn.net/u011534057/article/details/51247371
http://blog.csdn.net/shenxiaolu1984/article/details/51152614
http://blog.csdn.net/luopingfeng/article/details/51245694http://blog.csdn.net/xyy19920105/article/details/50817725
思想
從RCNN到fast RCNN,再到本文的faster RCNN,目標檢測的四個基本步驟(候選區域生成,特徵提取,分類,位置精修)終於被統一到一個深度網路框架之內。所有計算沒有重複,完全在GPU中完成,大大提高了執行速度。
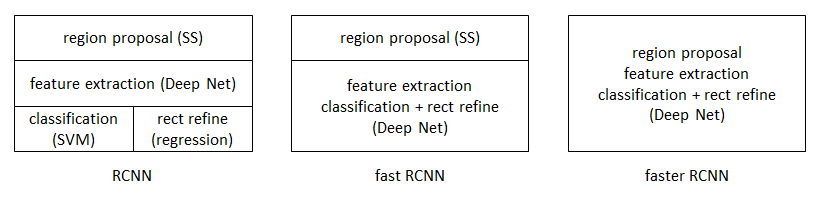
faster RCNN可以簡單地看做“區域生成網路+fast RCNN“的系統,用區域生成網路代替fast RCNN中的Selective Search方法。本篇論文著重解決了這個系統中的三個問題:
1. 如何設計區域生成網路
2. 如何訓練區域生成網路
3. 如何讓區域生成網路和fast RCNN網路共享特徵提取網路
區域生成網路:結構
基本設想是:在提取好的特徵圖上,對所有可能的候選框進行判別。由於後續還有位置精修步驟,所以候選框實際比較稀疏。
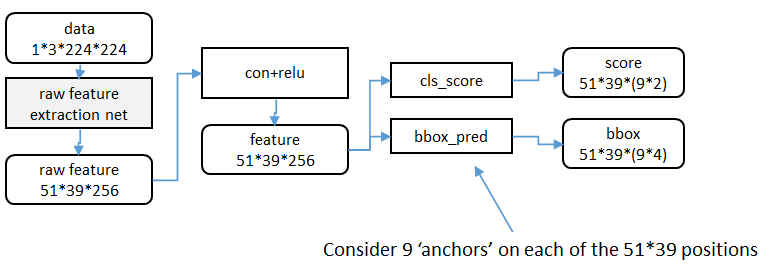
特徵提取
原始特徵提取(上圖灰色方框)包含若干層conv+relu,直接套用ImageNet上常見的分類網路即可。本文試驗了兩種網路:5層的ZF[
額外新增一個conv+relu層,輸出51*39*256維特徵(feature)。
Region Proposal Networks的設計和訓練思路
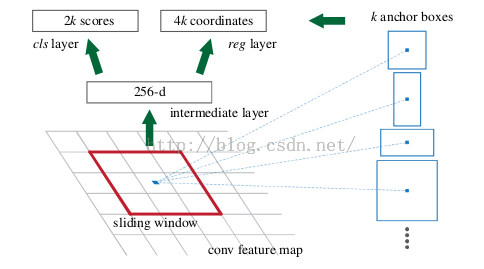
上圖是RPN的網路流程圖,即也是利用了SPP的對映機制,從conv5上進行滑窗來替代從原圖滑窗。
不過,要如何訓練出一個網路來替代selective search相類似的功能呢?
實際上思路很簡單,就是先通過SPP根據一一對應的點從conv5映射回原圖,根據設計不同的固定初始尺度訓練一個網路,就是給它大小不同(但設計固定)的region圖,然後根據與ground truth的覆蓋率給它正負標籤,讓它學習裡面是否有objec
這就又變成介紹RCNN之前提出的traditional method,訓練出一個能檢測物體的網路,然後對整張圖片進行滑窗判斷,不過這樣子的話由於無法判斷region的尺度和scale ratio,故需要多次放縮,這樣子測試,估計判斷一張圖片是否有物體就需要很久。(傳統hog+svm->dpm)
如何降低這一部分的複雜度?
要知道我們只需要找出大致的地方,無論是精確定位位置還是尺寸,後面的工作都可以完成,這樣子的話,與其說用小網路,簡單的學習(這樣子估計和蒙差不多了,反正有無物體也就50%的概率),還不如用深的網路,固定尺度變化,固定scale ratio變化,固定取樣方式(反正後面的工作能進行調整,更何況它本身就可以對box的位置進行調整)這樣子來降低任務複雜度呢。
這裡有個很不錯的地方就是在前面可以共享卷積計算結果,這也算是用深度網路的另一個原因吧。而這三個固定,我估計也就是為什麼文章叫這些proposal為anchor的原因了。這個網路的結果就是卷積層的每個點都有有關於k個achor boxes的輸出,包括是不是物體,調整box相應的位置。這相當於給了比較死的初始位置(三個固定),然後來大致判斷是否是物體以及所對應的位置.
這樣子的話RPN所要做的也就完成了,這個網路也就完成了它應該完成的使命,剩下的交給其他部分完成。
候選區域(anchor)
特徵可以看做一個尺度51*39的256通道影象,對於該影象的每一個位置,考慮9個可能的候選視窗:三種面積{1282,2562,5122}×
三種比例{1:1,1:2,2:1}
。
這些候選視窗稱為anchors。
下圖示出51*39個anchor中心,以及9種anchor示例。
關於anchor的問題:
這裡在詳細解釋一下:(1)首先按照尺度和長寬比生成9種anchor,這9個anchor的意思是conv5 feature map
3x3的滑窗對應原圖區域的大小.這9個anchor對於任意輸入的影象都是一樣的,所以只需要計算一次. 既然大小對應關係有了,下一步就是中心點對應關係,接下來(2)對於每張輸入影象,根據影象大小計算conv5 3x3滑窗對應原圖的中心點. 有了中心點對應關係和大小對應關係,對映就顯而易見了.

在整個faster RCNN演算法中,有三種尺度。
原圖尺度:原始輸入的大小。不受任何限制,不影響效能。
歸一化尺度:輸入特徵提取網路的大小,在測試時設定,原始碼中opts.test_scale=600。anchor在這個尺度上設定。這個引數和anchor的相對大小決定了想要檢測的目標範圍。
網路輸入尺度:輸入特徵檢測網路的大小,在訓練時設定,原始碼中為224*224。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region Proposal Networks
RPN的目的是實現"attention"機制,告訴後續的扮演檢測\識別\分類角色的Fast-RCNN應該注意哪些區域,它從任意尺寸的圖片中得到一系列的帶有
objectness score 的 object proposals。
具體流程是:使用一個小的網路在已經進行通過卷積計算得到的feature map上進行滑動掃描,這個小的網路每次在一個feature map上的一個視窗進行滑動(這個視窗大小為n*n----在這裡,再次看到神經網路中用於縮減網路訓練引數的區域性感知策略receptive
field,通常n=228在VGG-16,而作者論文使用n=3),滑動操作後對映到一個低維向量(例如256D或512D,這裡說256或512是低維,Q:n=3,n*n=9,為什麼256是低維呢?那麼解釋一下:低維相對不是指視窗大小,視窗是用來滑動的!256相對的是a
convolutional feature map of a size W × H (typically ∼2,400),而2400這個特徵數很大,所以說256是低維.另外需要明白的是:這裡的256維裡的每一個數都是一個Anchor(由2400的特徵數滑動後操作後,再進行壓縮))最後將這個低維向量送入到兩個獨立\平行的全連線層:box迴歸層(a
box-regression layer (reg))和box分類層(a box-classification layer (cls))
Translation-Invariant Anchors
在計算機視覺中的一個挑戰就是平移不變性:比如人臉識別任務中,小的人臉(24*24的解析度)和大的人臉(1080*720)如何在同一個訓練好權值的網路中都能正確識別. 傳統有兩種主流的解決方式:
第一:對影象或feature map層進行尺度\寬高的取樣;
第二,對濾波器進行尺度\寬高的取樣(或可以認為是滑動視窗).
但作者的解決該問題的具體實現是:通過卷積核中心(用來生成推薦視窗的Anchor)進行尺度、寬高比的取樣。如上圖右邊,文中使用了3 scales and 3 aspect ratios (1:1,1:2,2:1), 就產生了 k = 9 anchors at each sliding position.
視窗分類和位置精修
分類層(cls_score)輸出每一個位置上,9個anchor屬於前景和背景的概率;視窗迴歸層(bbox_pred)輸出每一個位置上,9個anchor對應視窗應該平移縮放的引數。
對於每一個位置來說,分類層從256維特徵中輸出屬於前景和背景的概率;視窗迴歸層從256維特徵中輸出4個平移縮放參數。
就區域性來說,這兩層是全連線網路;就全域性來說,由於網路在所有位置(共51*39個)的引數相同,所以實際用尺寸為1×1的卷積網路實現。
需要注意的是:並沒有顯式地提取任何候選視窗,完全使用網路自身完成判斷和修正。
區域生成網路:訓練
樣本
考察訓練集中的每張影象:
a. 對每個標定的真值候選區域,與其重疊比例最大的anchor記為前景樣本
b. 對a)剩餘的anchor,如果其與某個標定重疊比例大於0.7,記為前景樣本;如果其與任意一個標定的重疊比例都小於0.3,記為背景樣本
c. 對a),b)剩餘的anchor,棄去不用。
d. 跨越影象邊界的anchor棄去不用
代價函式
同時最小化兩種代價:
a. 分類誤差
b. 前景樣本的視窗位置偏差
超引數
原始特徵提取網路使用ImageNet的分類樣本初始化,其餘新增層隨機初始化。
每個mini-batch包含從一張影象中提取的256個anchor,前景背景樣本1:1.
前60K迭代,學習率0.001,後20K迭代,學習率0.0001。
momentum設定為0.9,weight decay設定為0.0005。[5]
共享特徵
區域生成網路(RPN)和fast RCNN都需要一個原始特徵提取網路(下圖灰色方框)。這個網路使用ImageNet的分類庫得到初始引數W0,但要如何精調引數,使其同時滿足兩方的需求呢?本文講解了三種方法。
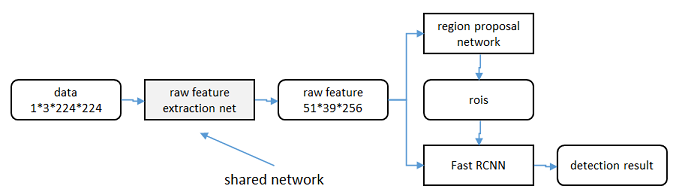
輪流訓練
a. 從W0開始,訓練RPN。用RPN提取訓練集上的候選區域
b. 從W0開始,用候選區域訓練Fast
RCNN,引數記為W1
c. 從W1開始,訓練RPN…
具體操作時,僅執行兩次迭代,並在訓練時凍結了部分層。論文中的實驗使用此方法。
如Ross Girshick在ICCV 15年的講座Training R-CNNs of various velocities中所述,採用此方法沒有什麼根本原因,主要是因為”實現問題,以及截稿日期“。
近似聯合訓練
直接在上圖結構上訓練。在backward計算梯度時,把提取的ROI區域當做固定值看待;在backward更新引數時,來自RPN和來自Fast RCNN的增量合併輸入原始特徵提取層。
此方法和前方法效果類似,但能將訓練時間減少20%-25%。公佈的python程式碼中包含此方法。
聯合訓練
直接在上圖結構上訓練。但在backward計算梯度時,要考慮ROI區域的變化的影響。推導超出本文範疇,請參看15年NIP論文[6]。
實驗
除了開篇提到的基本效能外,還有一些值得注意的結論
-
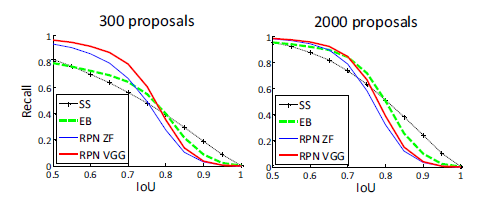
與Selective Search方法(黑)相比,當每張圖生成的候選區域從2000減少到300時,本文RPN方法(紅藍)的召回率下降不大。說明RPN方法的目的性更明確。
-
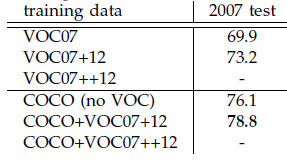
使用更大的Microsoft COCO庫[7]訓練,直接在PASCAL VOC上測試,準確率提升6%。說明faster RCNN遷移性良好,沒有over fitting。
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩
- M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional neural networks,” in European Conference on Computer Vision (ECCV), 2014. ↩
- K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations (ICLR), 2015. ↩
- learning rate-控制增量和梯度之間的關係;momentum-保持前次迭代的增量;weight decay-每次迭代縮小引數,相當於正則化。 ↩
- Jaderberg et al. “Spatial Transformer Networks”
NIPS 2015 ↩
相關推薦
faster rcnn 論文理解
reference link: http://blog.csdn.net/u011534057/article/details/51247371http://blog.csdn.net/shenxiaolu1984/article/details/51152614 http://blog.csdn.n
faster rcnn原始碼理解imdb,roidb,blob很關鍵
原 faster rcnn原始碼理解 2016年12月12日 23:07:19 zbxzc 閱讀數:15173 &
tensorflow+faster rcnn程式碼理解(四)boundingbox迴歸
1.為什麼要做Bounding-box regression? 如圖所示,綠色的框為飛機的Ground Truth,紅色的框是提取的Region Proposal。那麼即便紅色的框被分類器識別為飛機,但是由於紅色的框定位不準(IoU<0.5),那麼這張圖相當於沒有正確的檢測出飛機。如
tensorflow+faster rcnn程式碼理解(三):損失函式構建
前面兩篇部落格已經敘述了基於vgg模型構建faster rcnn的過程: tensorflow+faster rcnn程式碼理解(一):構建vgg前端和RPN網路 tensorflow+faster rcnn程式碼解析(二):anchor_target_layer、proposal_targ
tensorflow+faster rcnn程式碼理解(一):構建vgg前端和RPN網路
0.前言 該程式碼執行首先就是呼叫vgg類建立一個網路物件self.net if cfg.FLAGS.network == 'vgg16': self.net = vgg16(batch_size=cfg.FLAGS.ims_per_batch) 該類位於vgg.py中,如下:
Faster-RCNN論文詳解
Faster-RCNN 提出了Region Proposal Network(RPN)一個全連線的卷積層可以同時預測目標邊界和目標分數(物體) 把RPN和Fast-RCNN合併為一個網路通過共享他們的卷積特徵——使用帶有"attention"機制的神經網路 聯合網路un
Faster rcnn原始碼理解(4)
上一篇我們說完了AnchorTargetLayer層,然後我將Faster rcnn中的其他層看了,這裡把ROIPoolingLayer層說一下; 我先說一下它的實現原理:RPN生成的roi區域大小是對應與輸入影象大小(而且每一個roi大小都不同,因為先是禪城九種anchors,又經過迴歸,所以大
Faster rcnn原始碼理解(3)
緊接著之前的部落格,我們繼續來看faster rcnn中的AnchorTargetLayer層: 該層定義在lib>rpn>中,見該層定義: 首先說一下這一層的目的是輸出在特徵圖上所有點的anchors(經過二分類和迴歸); (1)輸入blob:bottom[0]儲存特徵圖資訊
Faster rcnn原始碼理解(2)
接著上篇的部落格,咱們繼續看一下Faster RCNN的程式碼~ 上次大致講完了Faster rcnn在訓練時是如何獲取imdb和roidb檔案的,主要都在train_rpn()的get_roidb()函式中,train_rpn()函式後面的部分基本沒什麼需要講的了,那我們再回到訓練流程中來:
Faster RCNN程式碼理解(Python) ---訓練過程
最近開始學習深度學習,看了下Faster RCNN的程式碼,在學習的過程中也查閱了很多其他人寫的部落格,得到了很大的幫助,所以也打算把自己一些粗淺的理解記錄下來,一是記錄下自己的菜鳥學習之路,方便自己過後查閱,二來可以回饋網路。目前程式設計能力有限,且是第一次寫部落格,中間可能會有一些錯誤。 目錄 第一步
Faster rcnn程式碼理解(2)
接著上篇的部落格,咱們繼續看一下Faster RCNN的程式碼~ 上次大致講完了Faster rcnn在訓練時是如何獲取imdb和roidb檔案的,主要都在train_rpn()的get_roidb()函式中,train_rpn()函式後面的部分基本沒什麼需要講的了,那我們再回到訓練流程中來: 這一步
Faster RCNN程式碼理解詳細(Python)
最近開始學習深度學習,看了下Faster RCNN的程式碼,在學習的過程中也查閱了很多其他人寫的部落格,得到了很大的幫助,所以也打算把自己一些粗淺的理解記錄下來: 一是記錄下自己的菜鳥學習之路,方便自己過後查閱; 二來可以回饋網路。目前程式設計能力有限,且是第一次寫部落格
Faster rcnn程式碼理解
這段時間看了不少論文,回頭看看,感覺還是有必要將Faster rcnn的原始碼理解一下,畢竟後來很多方法都和它有相近之處,同時理解該框架也有助於以後自己修改和編寫自己的框架。好的開始吧~ 這裡我們跟著Faster rcnn的訓練流程來一步一步梳理,進入tools\tr
Faster Rcnn論文總結
論文:《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》 一、 概述 此論文是由業界大牛何凱明在2015年發表的一篇經典論文,目前最先進的目
Faster rcnn原始碼理解(1)
這段時間看了不少論文,回頭看看,感覺還是有必要將Faster rcnn的原始碼理解一下,畢竟後來很多方法都和它有相近之處,同時理解該框架也有助於以後自己修改和編寫自己的框架。好的開始吧~這裡我們跟著Faster rcnn的訓練流程來一步一步梳理,進入tools\train_f
Faster rcnn代碼理解(1)
感覺 組織 等我 ont 包含 還要 定義 fig 訓練數據 這段時間看了不少論文,回頭看看,感覺還是有必要將Faster rcnn的源碼理解一下,畢竟後來很多方法都和它有相近之處,同時理解該框架也有助於以後自己修改和編寫自己的框架。好的開始吧~ 這裏我們跟著Faster
對faster rcnn 中rpn層的理解
height 圖片 http 預測 解決辦法 tar mat proposal 而是 1.介紹 圖為faster rcnn的rpn層,接自conv5-3 圖為faster rcnn 論文中關於RPN層的結構示意圖 2 關於anchor: 一般是在最末層
pytoch faster rcnn復現系列(一) RPN層輸入輸出維度理解
目錄 1. 1*1 FC層 2. anchor_target_layer_>rpn_data &nbs
faster rcnn generate_anchors 原始碼理解
這裡比較trick的就是_ratio_enum了,這裡是要生成面積一樣下,高寬比=0.5, 1, 2的所有矩形。 x是寬,x * x * 0.5 = area => x * x = area * 2 def _ratio_enum(anchor, ratios): "
(原)faster rcnn的tensorflow程式碼的理解
轉載請註明出處: 參考網址: 論文:https://arxiv.org/abs/1506.01497 tf的第三方faster rcnn:https://github.com/endernewton/tf-faster-rcnn IOU:https://www.cnblogs.com/