
學習Redis第一課(Nosql入門和概述)
現在Redis越來越火,為了適應技術的發展,開始學習一下Redis,在學習Redis之前先學習一下Nosql。
第一部分:入門概述
1.1 網際網路時代背景下大機遇,為什麼用nosql
1.1.1 單機Mysql的美好年代(好幾年前)
當時的業務很相對簡單,就是JSP--->Action---->Service---->DAO----->資料庫,資料庫也就是一個例項而已,無論是Mysql還是Oracle。把這五層縮減為三層的話便是:應用層------>DAO層------>Mysql例項。

以前一個網站的訪問量一般不大,用單個數據庫可以輕鬆應付。但是隨著時代的發展,上述資料儲存遇到了儲存的瓶頸:
1) 資料量的總大小,一個機器放不下時(以Mysql為例,單表儲存大概三百多萬的資料的時候DBA就該進行預警並優化分割了)
2) 資料的索引(B+Tree),一個機器的記憶體放不下時(眾所周知,為表建立索引也是需要消耗記憶體的,當我們所建立的索引記憶體盛不下時)
3) 訪問量(讀寫混合)一個例項不能承受
1.1.2 Memcached(快取)+MySQL+垂直拆分
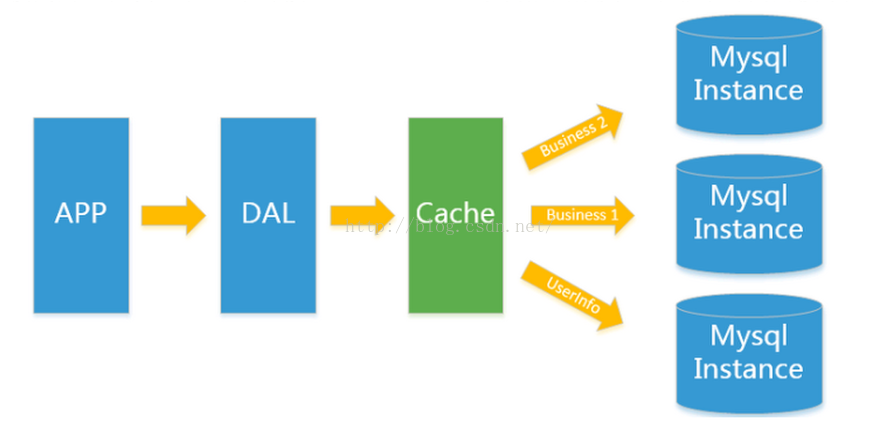
後來,隨著訪問量的上升,幾乎大部分使用MySQL架構的網站在資料庫上都開始出現了效能問題,web程式不再僅僅專注在功能上,同時也在追求效能。程式設計師們開始大量的使用快取技術來緩解資料庫的壓力,優化資料庫的結構和索引。開始比較流行的是通過檔案快取(MongoDB)來緩解資料庫的壓力,但是當訪問量繼續增大的時候,多 臺web機器通過檔案快取不能共享,大量的小檔案快取也帶來了比較高的IO壓力。在這個時候,Memcached就自然的成為一個非常時尚的技術產品。如下圖所示,我們所 說的Memcached及Redis其實都在Cache這一層。Memcached或Redis相當於在DAO層與資料庫例項之間擋了一層,眾所周知,對資料庫來說,壓力主要來自於大量頻繁的 查詢,我們把頻繁查詢並且固定的資料放到快取當中,這樣以後查詢的時候就會從快取中去讀取資料,從而減輕了資料庫的壓力。同時,Mysql資料庫的例項也由原來的一 個變成了多個,資料被分別儲存到不同的資料庫例項當中。
1.1.3 Mysql主從複製,讀寫分離
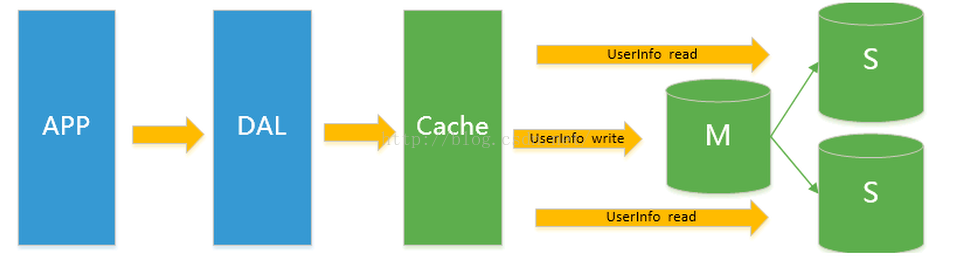
由於資料庫的寫入壓力增加,Memcached只能緩解資料庫的讀取壓力。讀寫集中在一個數據庫上讓資料庫不堪重負,大部分網站開始使用主從複製技術來達到讀寫分離以提高讀寫效能和讀庫的可擴充套件性。Mysql的master-slave成為這個時候的網站標配了。Mysql資料庫有多個例項,其中有一個主庫(M),有多個從庫(S),如果使用者在主庫插入一條資料,為了資料的安全,需要馬上向從庫也插入一條相同的資料(這就是主從複製),這樣當主庫出現問題的時候,就可以通過從庫進行資料恢復;讀寫分離是指,主庫只負責寫操作,從庫只負責讀操作,因為對於現實使用者的行為來說,讀寫的操作要遠遠少於查詢的操作,因此我們專門用一臺裝置來儲存使用者的寫操作,用多臺裝置來共同分擔查詢的壓力,這樣就比傳統的單資料庫的效能提升很多倍。如下圖所示:
1.1.4 分表分庫+水平拆分+mysql叢集
在Memcached的快取記憶體,MySQL的主從複製,讀寫分離的基礎之上,這時MySQL主庫的寫壓力開始出現瓶頸,而資料量的持續猛增,由於MyISAM使用表鎖,在高併發 下會出現嚴重的鎖問題,大量的高併發MySQL應用開始使用InnoDB(行鎖)引擎代替MyISAM。
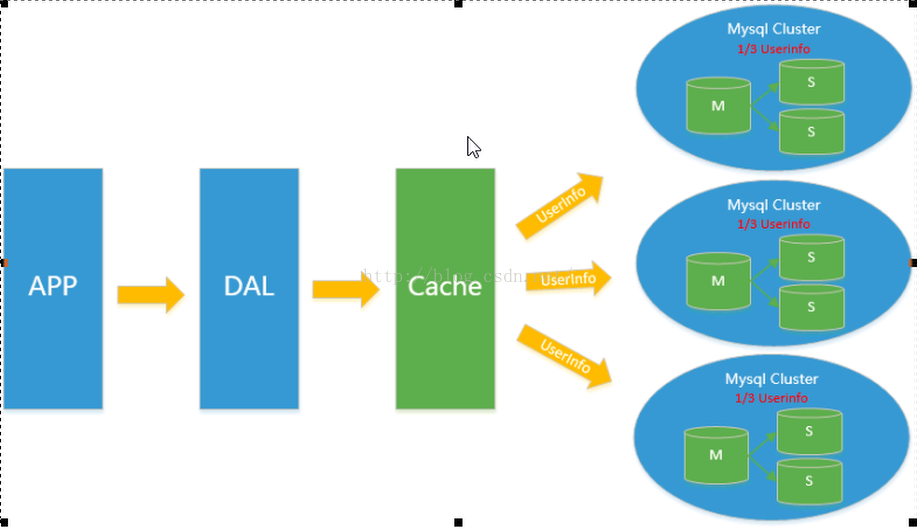
同時,開始流行使用分表分庫來緩解寫壓力和資料增長的擴充套件問題。這個時候,分表分庫成了一個熱門技術,是面試的熱門問題也是業界討論的熱門技術問題。也就在這個時候,MySQL推出了還不太穩定的表分割槽,這也給技術實力一般的公司帶來了希望。雖然MySQL推出了MySQL Cluster叢集,但效能也不能很好滿足網際網路的要求,只是在高可靠性上提供了非常大的保證。如下圖所示。假如有九千萬條的資料,如果都存到一個數據庫,肯定受不了,但是如果把這九千萬條資料分成三部分,頭三千萬存到1號庫,中間三千萬條存到2號庫,後三千萬條存到3號庫,這樣每個資料庫的例項的壓力就會小很多,查詢的時候只需到相應的庫中去查詢即可。
1.1.5 MySQL的擴充套件性瓶頸
MySQL資料庫也經常儲存一些大文字欄位,導致資料庫表非常的大,在做資料庫恢復的時候就導致非常的慢,不容易快速恢復資料庫。比如1000萬4KB大小的文字就 接近40GB的大小,如果能把這些資料從MySQL省去,MySQL將變得非常的小。關係資料庫很強大,但是它並不能很好的應付所有的應用場景。MySQL的擴充套件性差(需要 複雜的技術來實現),大資料IO壓力大,表結構更改困難,正是當前使用MySQL的開發人員面臨的問題。
1.1.6 今天
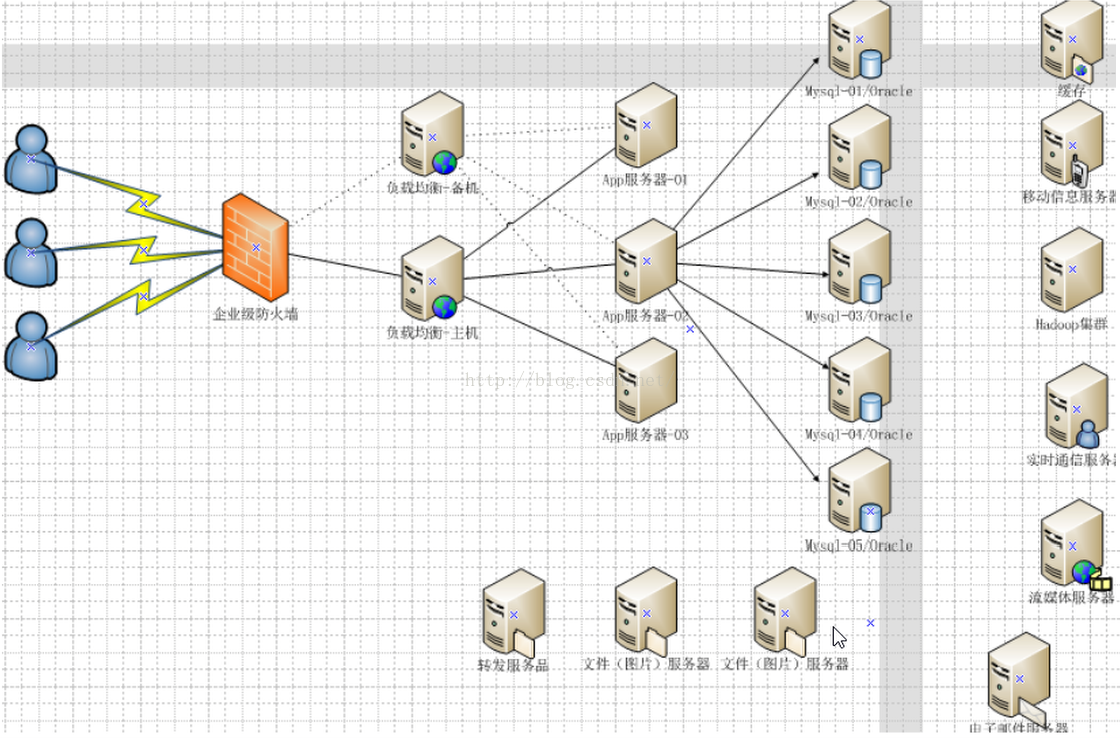
今天的架構如下所示,負載均衡用的是Nginx,App伺服器叢集(Tomcat叢集),資料庫叢集,再加上分散式快取等,組成了一個強大的組網圖。
1.1.7 為什麼用NoSql
今天我們可以通過第三方平臺(如:Google,Facebook等)可以很容易的訪問和抓取資料。使用者的個人資訊,社交網路,地理位置,使用者生成的資料和使用者操作日誌 已經成倍的增加。我們如果要對這些使用者資料進行挖掘,那SQL資料庫已經不適合這些應用了,NoSQL資料庫的發展也卻能很好的處理這些大資料。從下面這張圖中可以 看到,近幾年Web資料成幾何倍數增加,我們傳統的關係型資料庫已經無法滿足要求了。
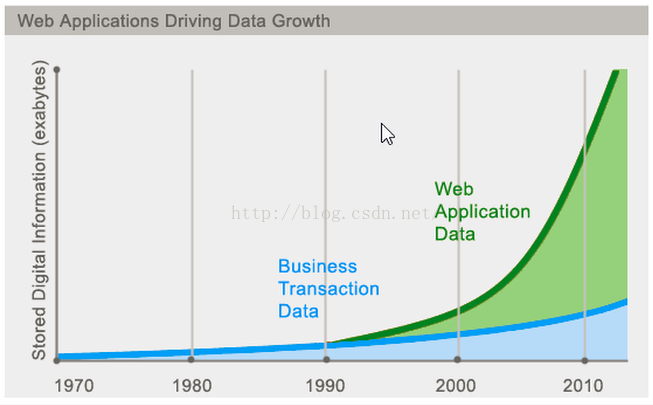
1.2 什麼是NoSQL?
NoSQL(NoSQL = Not Only SQL),意即“不僅僅是SQL”,泛指非關係型資料庫。隨著網際網路web2.0網站的興起,傳統的關係型資料庫在應付web2.0網站,特別是超大規模 和高併發的SNS型別的web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關係型的資料庫則由於其本身的特點得到了非常迅速的發展。NoSQL資料庫 的產生就是為了解決大規模資料集合多重資料種類帶來的挑戰,尤其是大資料應用難題,包括超大規模資料的儲存。
(例如谷歌或Facebook每天為他們的使用者收集萬億位元的資料),這些型別的資料的儲存不需要固定的模式,無需多餘操作就可以橫向擴充套件。
1.3 NoSQL能幹嘛?
1.3.1 易擴充套件
NoSQL資料庫種類繁多,但是一個共同的特點都是去掉關係資料庫的關係型特性。資料之間無關係,這就非常容易擴充套件。也無形之間,在架構的層面上帶來了可擴充套件的 能力。對於傳統關係型資料庫來說,對於一張橫向或縱向的表,擴充套件終有限,而且資料型別也就那麼幾種(比如varchar、int、date、blob、long等),隨著業務的發展尤其 是社交網路的發展,親情之間的關係我們很難用傳統資料庫去描述(比如:他姑姑家的女兒的大伯父家的兒子的鄰居的爸爸的大表舅...這樣複雜的人際關係網,我們很難想 象通過傳統的關係型資料庫去描述),取而代之的是用圖來描述。對NoSQL而言,其實就是一大堆key-value鍵值對,value我們可以隨意存放,這就給我們帶來了非常大的 靈活性。
1.3.2 大資料量高效能
NoSQL資料庫都具有非常高的讀寫效能(讀,一秒鐘11萬;寫,一秒鐘8萬),尤其在大資料量下,同樣表現優秀。這得益於它的無關係型性,資料庫的結果簡單。
一般MySQL使用Query Cache,每次表的更新Cache就失敗,是一種大粒度的Cache,在針對web2.0的互動頻繁的應用,Cache效能不高。而NoSQL的Cache是記錄級 的,是一種細粒度的Cache,所以NoSQL在這個層面上來說就要效能高很多了。
1.3.3 多樣靈活的資料模型
NoSQL無需事先為要儲存的資料建立欄位,隨時可以儲存自定義的資料格式。而在關係資料庫裡,增刪欄位是一件非常麻煩的事情。如果是非常大的資料量的表,增加 欄位就是一個噩夢。
1.3.4 RDBMS(關係型資料庫)VS NoSQL(泛指非關係型資料庫)
RDBMS
- 高度組織化結構化資料
- 結構化查詢語言(SQL)
- 資料和關係都儲存在單獨的表中
- 資料操縱的語言,資料定義語言
- 嚴格的一致性
- 基礎事務
NoSQL
- 代表著不僅僅是SQL
- 沒有宣告性查詢語言
- 沒有預定義的模式
- 鍵 - 值對儲存,列儲存,文件儲存,圖形資料庫
- 最終一致性,而非ACID屬性
- 非結構化和不可預知的資料
- CAP定理
- 高效能,高可用性和可伸縮性
1.4 去哪下
NoSQL目前比較流行的有Mongoodb、Memcache、Redis三種,其中Mongodb是最像關係型資料庫的一種了,主要處理文件,單論快取的處理能力,Memcache是目前最 牛逼的技術,不過,要處理多樣化的資料的話,Redis更強悍。我們下載去官網下載即可。
1.5 怎麼玩
NoSQL說白了就是KV鍵值對、Cache快取、持久化這三部分(後續會有詳解)。
第二部分:3V+3高
2.1 大資料時代的3V
3V分別指海量(Volume)、多樣(Variety)、實時(Velocity)
2.2 網際網路需求的3高
3高分別是指高併發(高併發不用多說了,就是同一時間的訪問量非常大)、高可擴(主要針對的是橫向擴充套件,因為縱向擴充套件終有瓶頸,比如一臺裝置一個記憶體條不夠用,我們插兩條,一個硬碟不夠用,我們再加固態硬碟,但這種方式終究是有限度的,橫向擴充套件是把原來的一臺伺服器變成一個叢集,多臺伺服器同時提供服務,這種擴充套件性就很強了,5臺不行8臺,8臺不行10臺,而且叢集都有負載均衡,從而分配到每臺伺服器上的請求相對就少了)、高效能(比如單點故障、資料庫容災備份等都要求有很高的效能)
第三部分:當下的NoSQL經典應用
3.1 當下的應用是sql和nosql一起使用
我們不能陷入一個誤區,就是認為redis既然很強大,是不是要把oracle、mysql給幹掉了,其實不是這樣的,現實應用中肯定是兩者都用的,它們現在負責的內容不一樣,不存在誰幹掉誰的問題。
3.2 阿里巴巴中文站商品資訊如何存放
3.2.1 阿里巴巴框架的演變,如下所示。
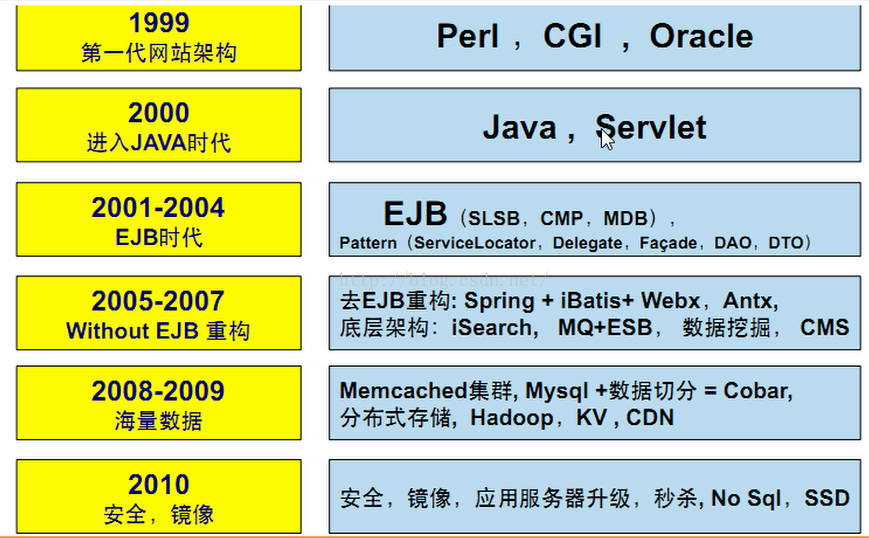
現在阿里巴巴的架構到了第五代,第五代架構的特點是:
1) 敏捷
業務快速增長,每天都要上線大量的小需求;
應用系統日益膨脹,耦合惡化,架構越來越複雜,會帶來更高的開發成本,如何保持業務開發敏捷性?
2) 開放
Facebook和AppStore帶來的啟示,如何提升網站的開放性,吸引第三方開發者加入到網站的共建中來
3) 體驗
網站的併發壓力快速增長,使用者卻對體驗提出了更高的要求

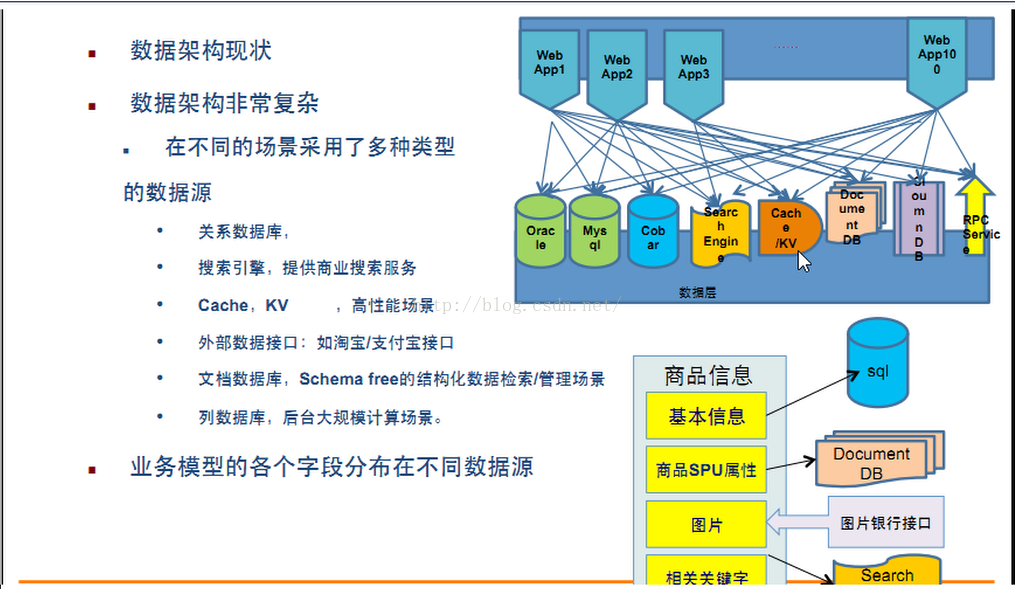
3.2.2 和我們相關的,多資料來源、多資料型別的儲存問題
多資料來源是指我們看到的淘寶商品的文字、圖片、視訊等內容不是來自於同一源頭,而是來自於不同的源頭,多資料型別,也就很明顯了,就是我們要儲存的內容不僅有文字,還有圖片還有聲音還有視訊,不同的資料型別我們往往要儲存到不同的地方。下面是淘寶架構圖,可見是非常複雜的。
3.3 商品基本資訊
包括名稱、價格、出廠日期、生產廠商等,這些資訊我們稱為冷資料,就是一般情況下不會發生改變,像這樣的資料我們一般把它們存放到關係型資料庫當中。目前淘寶已經逐漸去掉Oracle資料庫了,關係型資料庫用的主要是MySQL,不過他們用的MySQL是經過改造的,與我們所用的MySQL已經不是同一個東西了。淘寶主張去“IOE”(在IT建設過程中,去除IBM小型機、Oracle資料庫及EMC儲存裝置),阿里巴巴集團首席架構師王堅這樣概括“去IOE”運動和阿里雲之間的關係:“去IOE”徹底改變了阿里集團IT架構師的基礎,是阿里擁抱雲端計算,產出計算服務的基礎。“去IOE”的本質是分佈化,讓隨處可以買到的Commodity PC架構成為可能,使雲端計算能夠落地的首要條件。眾所周知,Oracle資料庫是非常昂貴的,一般的公司根本買不起,去掉Oracle,讓更多的公司通過使用廉價的資料庫就能滿足自己的需求,這將是改變中國IT界的一件大事。
3.4 商品描述、詳情、評價資訊(多文字類)
多文字資訊描述類,IO讀寫效能變差,把它們儲存到文件資料庫MongoDB當中
3.5 商品的圖片
商品圖片的展現類儲存在分散式的檔案系統當中,比如淘寶自己的TFS,Google的GFS,Hadoop的HDFS。
3.6 商品的關鍵字(搜尋框)
淘寶用的是他們自己開發的ISearch
3.7 商品的波段性的熱點高頻資訊
比如情人節,玫瑰花和巧克力肯定是搜尋量很大的,淘寶將可以預測到的熱搜的內容提前存放到了記憶體資料庫(Tair、Redis、Memcache)
3.8 商品的交易、價格計算、積分累計
外部系統,外部第3方支付介面或支付寶
3.9 總結大型網際網路應用(大資料、高併發、多樣資料型別)的難點和解決方案
3.9.1 難點:
1) 資料型別多樣化
2) 資料來源多樣性和變化重構
3) 資料來源改造而資料服務平臺不需要大面積重構
3.9.2 解決辦法
淘寶的做法是實現了一套統一資料平臺服務UDSL
第四部分:NoSQL資料模型簡介
4.1 以一個電商客戶、訂單、訂購、地址模型來對比下關係型資料庫和非關係型資料庫
4.1.1 傳統的關係型資料庫你如何設計?主要通過ER圖(1:1/1:N/N:N,主外來鍵等常見),一個顧客與訂單Order顯然是一對多的關係,同理,一個顧客也可以有多個收件地址(最常見的莫過於公司一個地址還有住的地方一個地址),一個Order可能對應多個Order Item(比如飲品類、書類、衣服類)同理,Product(商品)與Order Item也是一對多的關係。訂單與支付也是一對多的關係(支付的方式多種多樣嘛)
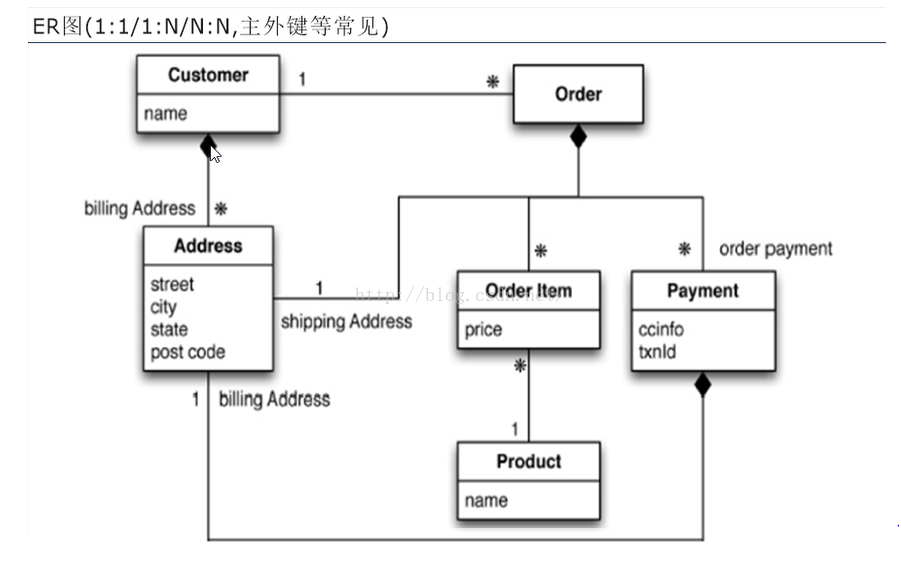
4.1.2 NoSQL 你如何設計
4.1.2.1 什麼是BSON,BSON()是一種類似json的一種二進位制形式的儲存格式,簡稱Binary JSON,它和JSON一樣,支援內嵌的文件物件和陣列物件
4.1.2.2 用BSON來表示上面ER圖所示的關係,可以看出用BSON來表示ER關係圖明顯是比ER關係圖靈活很多,我們可以單獨把裡面的json字串拿出來。
{
"customer":{
"id":1136,
"name":"Z3",
"billingAddress":[{"city":"beijing"}],
"orders":[
"id":17,
"customerId":1136,
"orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}],
"shippingAddress":[{"city":"beijing"}],
"orderPayment":[{"cciinfo":"111-222-333","tenid":"asdfadcd334","billingAddress":{"city":"beijing"}}],
}
]
}
}
高併發的操作是不太建議有關聯查詢的,網際網路公司用冗餘資料來避免關聯查詢。
分散式事務是支援不了太多的併發的。
我們傳統的關係型資料庫如果要查詢出來ER圖的關係的話,需要多次進行join操作,既複雜又容易出錯,但是用BSON來儲存的話,我們只需要一個customerId便可以得到一個完整的json字串,所有的資訊都在裡面,從而避免進行表關聯。
4.2 聚合模型
4.2.1 KV值
4.2.2 BSON
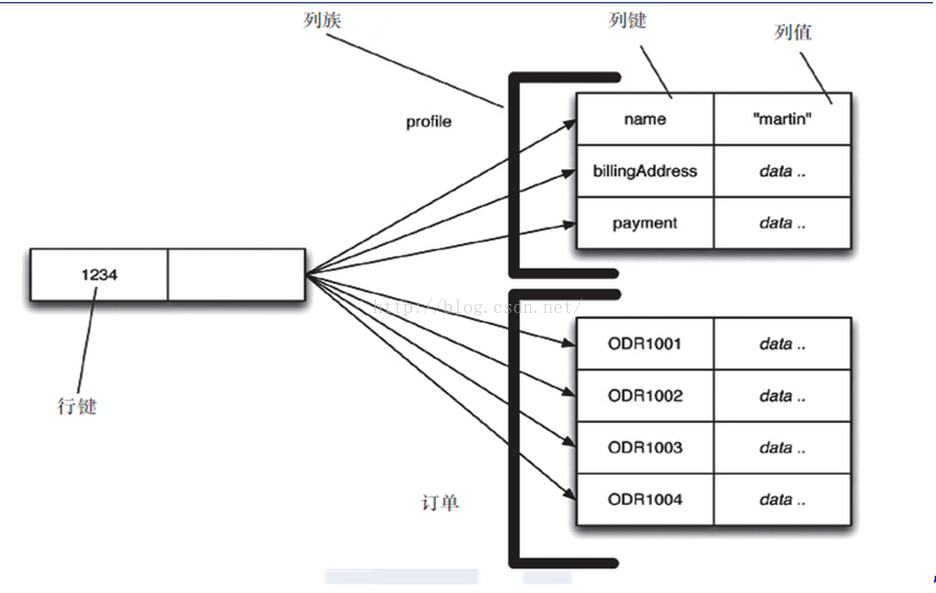
4.2.3 列族
顧名思義,是按列儲存資料的,最大的特點是方便儲存結構化和半結構化資料,方便做資料壓縮,對針對某一列或者某幾列的查詢有非常大的IO優勢。
4.2.4 圖表
第五部分:NoSQL資料庫的四大分類
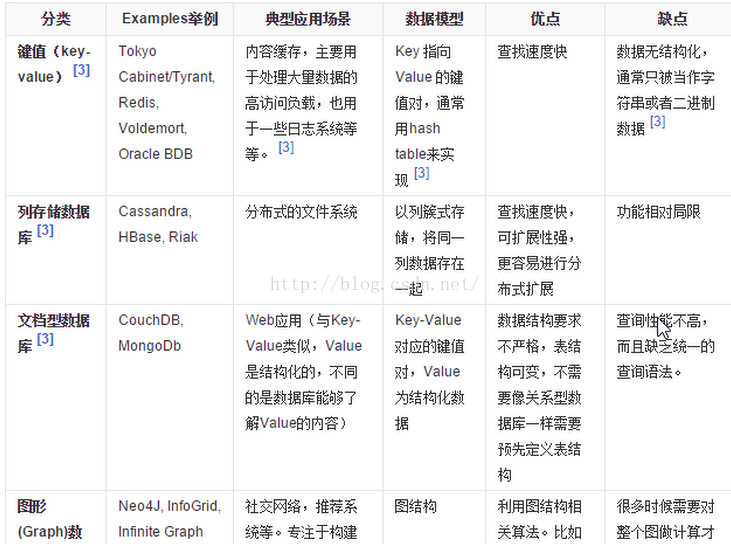
5.1 KV鍵值:典型介紹
目前,新浪:BerkeleyDB+redis
美團:redis+tair
阿里、百度:memcache+redis
5.2 文件型資料庫(bson格式比較多):典型介紹
CouchDB
MongoDB:是一個基於分散式檔案儲存的資料庫。由C++語言編寫。旨在為WEB應用提供可擴充套件的高效能資料儲存解決方案。
MongoDB是一個介於關係資料庫和非關係型資料庫之間的產品,是非關係資料庫當中功能最豐富,最像關係資料庫的。
5.3 列儲存資料庫
Cassandra,HBase
分散式檔案系統
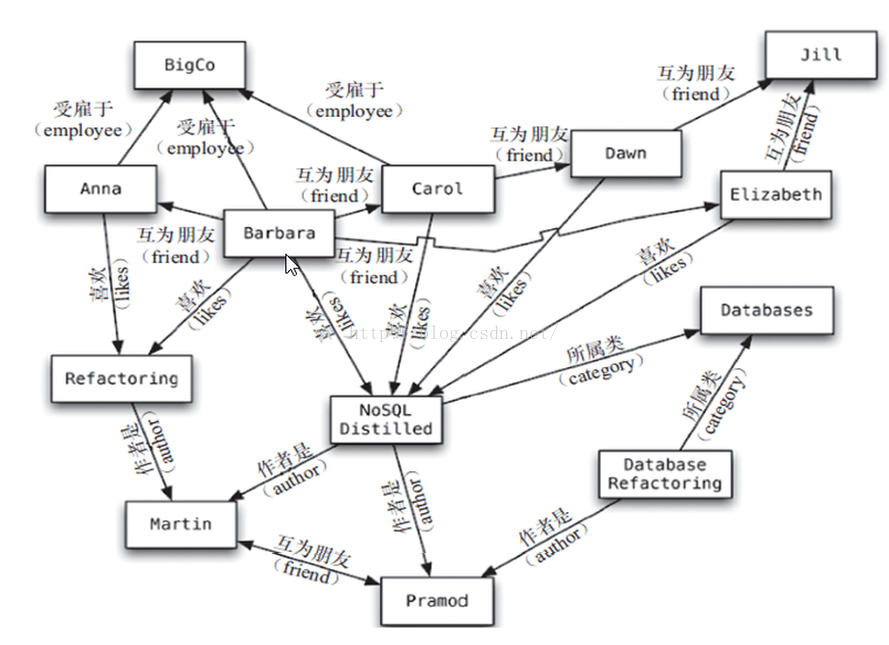
5.4 圖關係資料庫
它不是放圖形的,放的是關係比如:朋友圈社交網路、廣告推薦系統
社交網路,推薦系統等。專注於構建關係圖譜
Neo4J,InfoGrid
5.5 四者對比
第六部分:在分散式資料庫中CAP原理CAP+BASE
6.1 傳統的ACID分別是什麼
A(Atomicity)原子性
C(Consistency)一致性
I(Isolation)獨立性
D(Durability)永續性

6.2 CAP
C:Consistency(強一致性)
A:Availability(可用性)
P:Partition tolerance(分割槽容錯性)
6.3 CAP只能三選二
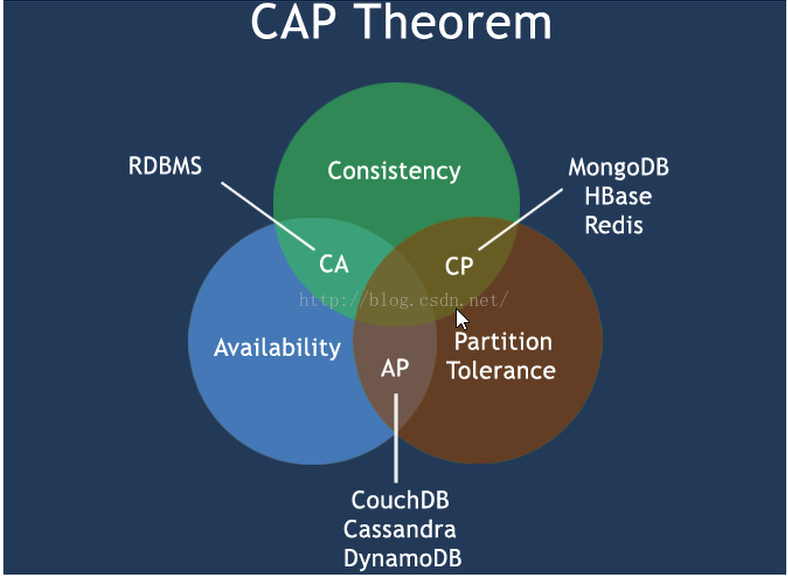
CAP理論的核心是:一個分散式系統不可能同時很好的滿足一致性,可用性和分割槽容錯性這三個需求,最多隻能同時較好的滿足兩個。因此,根據CAP原理將NoSQL資料庫分成了滿足CA原則、滿足CP原則和滿足AP原則三大類:
CA - 單點叢集,滿足一致性,可用性的系統,通常在可擴充套件性上不太強大。
CP - 滿足一致性,分割槽容錯性的系統,通常效能不是特別高。
AP - 滿足可用性,分割槽容忍性的系統,通常可能對一致性要求低一些。
CAP理論就是說在分散式儲存系統中,最多隻能實現上面的亮點。而由於當前的網路硬體肯定會出現延遲對包等問題,所以分割槽容忍性是我們必須要實現的。所以我們只能在一致性和可用性之間進行權衡,沒有NoSQL系統能同時保證這三點。
CA的代表是傳統Oracle資料庫,AP的代表是大多數網站架構的選擇,CP的代表是Redis、Mongodb
注意:分散式架構的時候必須做出取捨。
那麼,為什麼說現在大多數網站的架構師AP呢?我們舉天貓雙十一為例,在這一天顧客的點選如潮水般湧來,這時作為顧客來說,某商品這一秒的點贊數等資訊並不是顧客所關心的,換句話說,這時的點贊數可以弱一致性,不必做到實時準確。如果天貓網站這天崩潰了,這肯定是我們所不能忍受的,因此兩害相權取其輕,我們會選擇高可用性,雖然不能馬上做到強一致性,但是雙十一過後,我們依然有時間來做到最終的強一致性。
6.4 BASE
BASE就是為了解決資料庫強一致性引起的問題而引起的可用性降低而提出的解決方案。
BASE其實是下面三個術語的縮寫:
基本可用(Basically Available)
軟狀態(Soft state)
最終一致(Eventually consistent)
它的思想是通過讓系統放鬆對某一時刻資料一致性的要求來換取系統整體伸縮性和效能上改觀。為什麼這麼說呢,緣由就在於大型系統往往由於地域分佈和極高效能的要求,不可能採用分散式事務來完成這些指標,要想獲得這些指標,我們必須採用另外一種方式來完成,這裡BASE就是解決這個問題的辦法。
6.5 分散式系統和叢集


好,入門概述我們便一起學習到這裡。
相關推薦
學習Redis第一課(Nosql入門和概述)
現在Redis越來越火,為了適應技術的發展,開始學習一下Redis,在學習Redis之前先學習一下Nosql。 第一部分:入門概述 1.1 網際網路時代背景下大機遇,為什麼用nosql 1.1.1 單機Mysql的美好
Oracle學習第一課(登入oracle和建立使用者)
部落格10:housen1987 housen1987.iteye.com/blog/1345496 【學習是螺旋上升的過程,由易到難,由少到多,由點到面,每一個步驟,每一個腳印,每一個見聞,每一個錯誤都是學習階段所必須的,學習最大的捷徑就是不著急、有耐心。】 給使
Redis-NoSQL入門和概述(一)
NoSQL簡史及定義 NoSQL 這個術語最早是在 1998 年被Carlo Strozzi命名在他的輕量的,開源的關係型資料庫上的,但是該資料庫沒有提供標準的SQL介面;在2009 年再次被Eric Evans提起,討論分散式開源資料庫的問題,這是的NoSQL主要指
Redis 1.NoSql入門和概述
Redis @Author:hanguixian @Email:[email protected] 一 NoSql入門和概述 1 . 入門概述 1.1 網際網路時代背景下大機遇,為什麼用nosql 1.1.1 單機mysql 在90年代,一個
1.NoSQL入門和概述
第三方 推薦 自然 穩定 外部 計算 grid 日誌 數據庫 入門概述: 1.為什麽要用到NoSQL a) 單機MySQL的美好年代,在90年代,一個網站的訪問量一般都不大,用單個數據庫完全可以輕松應付。在那個時候,更多的都是靜態網頁,動態交互類型的網站不多。 上
構建自己計算機的知識體系,是自己進入編程學習的第一步(寫給自己的話)
表單 網頁設計 數據結構 windows 體系 嘗試 感謝 使用 計算 我個人認為不管我去學習什麽新的東西,我肯定先去了解這個新事物的大體輪廓,需要知道的是:這個東西是圓的還是方的?是走的還是爬的?...然後嘗試尋找他的一些內在聯系。之後再選擇這個事物的一方面去深入了解
一周第一課(3月19日)
虛擬機下安裝Linux7.41.1 學習之初1.2 約定1.3 認識Linux1.4 安裝虛擬機1.5 安裝centos7 1.3認識linux 1、什麽是linux 2、linux的起源 我們現在比較常用的linux版本是RedHat的分支CentOS 1.4創建虛擬機 創建新的虛擬機註意事項系統版本要選擇
redis 進階(配置檔案和持久化)
一、redis.conf 配置詳解 Redis預設不是以守護程序的方式執行,可以通過該配置項修改,使用yes啟用守護程序 daemonize no 當Redis以守護程序方式執行時,Redis預設會把pid寫入/var/run/redis.pid檔案,可
Cookie學習總結-登陸案例(記住使用者名稱和密碼)
LoginServlet.java package blank.servlet; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet
聽課筆記(第五講): 學習的可行性分析(一些概念和思想) (臺灣國立大學機器學習基石)
Training versus Testing1,回顧:學習的可行性?最重要的是公式: (1) 假設空間H有限(M),且訓練資料足夠大,則可以保證測試錯誤率Eout 約等於訓練錯誤率Ein;(2)如果能得到Ein 接近於零,根據(1),Eout 趨向於零。以上兩條保證的學習的可能性。可知,假設空間H 的
【筆記】C++入門學習第一課(Hello World!)
ubun names 鏈接 簡介 sudo ont 大小 ostream 編寫 學習環境:Ubuntu14.04、gcc version 4.8.4 、Notepad++ 在Linux下安裝g++命令:sudo apt-get install g++(需要輸入登錄密碼獲得
電腦小白學習第一課---IP地址查詢和設置
信息 獲得 一個 mage ges 網絡連接 連接 回車 學習 IP地址網絡的身.份.證信息 (唯一性,不可重復,同一個區域不可以設置相同的IP地址)IP分為分為IPv4和IPv6目前我們一般使用IPv4設置方法:電腦右下角網絡連接圖標右擊--->打開網絡和共享中心-
Linux學習第一周第二次課(1月23日)
type system fault 網卡配置文件 com ask config gif 網卡名稱 1.6/1.7 配置IP(1)DHCP自動分配IP地址(前提是網絡中有DHCP服務器) 自動獲取IP: # dhclient (2)設置靜態IP
Linux學習筆記第一周第五次課(1月26日)
大小 配置 nbsp tree usr man 文件目錄 字符串 -i 2.1/2.2 系統目錄結構tree樹結構,顯示目錄結構;安裝tree命令#yum install -y tree;2層顯示樹結構#tree -L 2;tree常用選項#tree --hap;tree的
Linux學習筆記第五周第一次課(3月5日)
rpm -ivh yum install yum remove yum update rpm -e 7.1 安裝軟件包的三種方法三種方法rpm工具,安裝會提示依賴其他包,要一個包一個包安裝;yum工具,自動下載安裝依賴包,最容易安裝;源碼包,源代碼,需要編譯器編譯再安裝,最難安裝;7.2
Linux學習筆記第六周第一次課(3月12日)
grep egrep grep -E grep -v grep -n 9.1 正則介紹_grep上egrep是grep的擴展,具有所有grep功能;grep是用來過濾關鍵詞的;-r遍歷所有子目錄-v取反,意思是除了關鍵詞所在行,其他行顯示出來;9.2 grep中'【0-9】'
跟著學之網路學習第一課(筆記)
一 WAN:廣域網 LAN: 區域網 MAN: 都會網路 WLAN:無線區域網 扁平化:小型,不易擴張 層次化:核心層,匯聚層,接入層 二 IP網路三大網:接入網 都會網路 廣域網 都會網路包含核心層 匯聚層 接入層 傳輸介質:兩個終端,用一條能
《機器學習》學習第一天(緒論入門)
一、機器學習目的尋找一個函式:這個函式可以完成的常見功能如圖 step1:定義一系列有一定功能的函式 step2:驗證這一系列函式的 優劣性 step3:尋找一個最優的函式 (二)、學習課表 (三)報名達觀杯並做一些準備 達觀公司組織
Android原生第一課-瞭解目錄結構和其用處(史上最詳細)
學的東西,很久沒用就會忘記,所以寫個東西記錄一下。 這是我之前用Android Studio 建的專案。 目錄檔案 作用 .gradle gradle專案產生資料夾(自動編譯工具產生的檔案) .idea IDEA專案資料夾(開發工具產生的檔案) app
【學習日記】吳恩達深度學習工程師微專業第一課:神經網路和深度學習
以下內容是我聽吳恩達深度學習微專業第一課做的學習筆記,主要是按自己的理解回答一些問題,並非全部出自課程內容。1. 什麼是神經網路?神經網路是諸多機器學習方法中的一種,受人類大腦工作方式的啟發而發明的。人類大腦的一個神經元通過多個樹突來接收來自不同神經元的訊號,接著細胞核處理訊