
推薦演算法之協同過濾例項
接著上次的資料進行協同過濾演算法應用
應用的知識
python的surprise
k折交叉驗證
R資料構建
KNNBasic
KNNWithMeans
KNNWithZScore
資料處理與演算法
# 協同過濾演算法資料構建
user_artist_sum_weight <- sqldf::sqldf('select userID,artistID, sum(weight) as play_num from user_artists group by userID,artistID')
user_artist_sum_weight <- as.data.table(user_artist_sum_weight python 之演算法應用
# 可以使用上面提到的各種推薦系統演算法
from surprise import Dataset
from surprise import print_perf
from surprise import KNNBasic,KNNWithMeans,KNNWithZScore, KNNBaseline
import os
from surprise import Reader, Dataset
from surprise.model_selection import cross_validate
from pandas import DataFrame
import numpy as np
import pandas as pd
######################################## KNNBasic
#algo = KNNBasic(k=1,sim_options = {'name': 'pearson','user_based': True})# 皮爾遜基於使用者
## 指定檔案路徑
file_path = os.path.expanduser('./python_data.txt')
## 指定檔案格式\n",
reader = Reader(line_format='user item rating timestamp', sep=',')
## 從檔案讀取資料
data = Dataset.load_from_file(file_path, reader=reader)
algo1 = KNNBasic(k=1,sim_options = {'name': 'pearson','user_based': True})
algo2 = KNNBasic(k=3,sim_options = {'name': 'pearson','user_based': True})
algo3 = KNNBasic(k=5,sim_options = {'name': 'pearson','user_based': True})
algo4 = KNNBasic(k=7,sim_options = {'name': 'pearson','user_based': True})
algo5 = KNNBasic(k=9,sim_options = {'name': 'pearson','user_based': True})
algo6 = KNNBasic(k=11,sim_options = {'name': 'pearson','user_based': True})
algo7 = KNNBasic(k=13,sim_options = {'name': 'pearson','user_based': True})
algo8 = KNNBasic(k=15,sim_options = {'name': 'pearson','user_based': True})
algo9 = KNNBasic(k=17,sim_options = {'name': 'pearson','user_based': True})
algo10 = KNNBasic(k=19,sim_options = {'name': 'pearson','user_based': True})
algo11 = KNNBasic(k=21,sim_options = {'name': 'pearson','user_based': True})
algo12 = KNNBasic(k=23,sim_options = {'name': 'pearson','user_based': True})
algo13 = KNNBasic(k=25,sim_options = {'name': 'pearson','user_based': True})
algo14 = KNNBasic(k=27,sim_options = {'name': 'pearson','user_based': True})
algo15 = KNNBasic(k=29,sim_options = {'name': 'pearson','user_based': True})
# 在資料集上測試一下效果
perf_1 = cross_validate(algo1,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_2 = cross_validate(algo2,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_3 = cross_validate(algo3,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_4 = cross_validate(algo4,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_5 = cross_validate(algo5,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_6 = cross_validate(algo6,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_7 = cross_validate(algo7,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_8 = cross_validate(algo8,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_9 = cross_validate(algo9,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_10 = cross_validate(algo10,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_11 = cross_validate(algo11,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_12 = cross_validate(algo12,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_13 = cross_validate(algo13,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_14 = cross_validate(algo14,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_15 = cross_validate(algo15,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_result_1=[]
for i in range(1,16):
perf_result_1.append('perf_'+ str(i))
MAE=[]
for perf in perf_result_1:
MAE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,1]),4))
RMSE=[]
for perf in perf_result_1:
RMSE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,2]),4))
FIT_TIME=[]
for perf in perf_result_1:
FIT_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,0]),4))
TEST_TIME=[]
for perf in perf_result_1:
TEST_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,3]),4))
MAE = DataFrame(MAE,columns=['MAE'])
RMSE = DataFrame(RMSE,columns=['RMSE'])
FIT_TIME = DataFrame(FIT_TIME,columns=['FIT_TIME'])
TEST_TIME = DataFrame(TEST_TIME,columns=['TEST_TIME'])
k = DataFrame([1,3,5,7,9,11,13,15,17,19,21,23,25,27,29],columns=['k'])
KNNBasic_result = pd.concat([k,MAE,RMSE,FIT_TIME,TEST_TIME],axis=1)
KNNBasic_result.to_csv('./result_data/KNNBasic_result1.csv',header=True,encoding='utf-8')
############################################# KNNWithMeans
#algo = KNNWithMeans(k=1,sim_options = {'name': 'pearson','user_based': True})# 皮爾遜基於使用者
## 指定檔案路徑
file_path = os.path.expanduser('./python_data.txt')
## 指定檔案格式\n",
reader = Reader(line_format='user item rating timestamp', sep=',')
## 從檔案讀取資料
data = Dataset.load_from_file(file_path, reader=reader)
algo1 = KNNWithMeans(k=1,sim_options = {'name': 'pearson','user_based': True})
algo2 = KNNWithMeans(k=3,sim_options = {'name': 'pearson','user_based': True})
algo3 = KNNWithMeans(k=5,sim_options = {'name': 'pearson','user_based': True})
algo4 = KNNWithMeans(k=7,sim_options = {'name': 'pearson','user_based': True})
algo5 = KNNWithMeans(k=9,sim_options = {'name': 'pearson','user_based': True})
algo6 = KNNWithMeans(k=11,sim_options = {'name': 'pearson','user_based': True})
algo7 = KNNWithMeans(k=13,sim_options = {'name': 'pearson','user_based': True})
algo8 = KNNWithMeans(k=15,sim_options = {'name': 'pearson','user_based': True})
algo9 = KNNWithMeans(k=17,sim_options = {'name': 'pearson','user_based': True})
algo10 = KNNWithMeans(k=19,sim_options = {'name': 'pearson','user_based': True})
algo11 = KNNWithMeans(k=21,sim_options = {'name': 'pearson','user_based': True})
algo12 = KNNWithMeans(k=23,sim_options = {'name': 'pearson','user_based': True})
algo13 = KNNWithMeans(k=25,sim_options = {'name': 'pearson','user_based': True})
algo14 = KNNWithMeans(k=27,sim_options = {'name': 'pearson','user_based': True})
algo15 = KNNWithMeans(k=29,sim_options = {'name': 'pearson','user_based': True})
# 在資料集上測試一下效果
perf_01 = cross_validate(algo1,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_02 = cross_validate(algo2,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_03 = cross_validate(algo3,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_04 = cross_validate(algo4,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_05 = cross_validate(algo5,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_06 = cross_validate(algo6,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_07 = cross_validate(algo7,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_08 = cross_validate(algo8,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_09 = cross_validate(algo9,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_010 = cross_validate(algo10,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_011 = cross_validate(algo11,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_012 = cross_validate(algo12,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_013 = cross_validate(algo13,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_014 = cross_validate(algo14,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_015 = cross_validate(algo15,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_result_1=[]
for i in range(1,16):
perf_result_1.append('perf_0'+ str(i))
MAE=[]
for perf in perf_result_1:
MAE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,1]),4))
RMSE=[]
for perf in perf_result_1:
RMSE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,2]),4))
FIT_TIME=[]
for perf in perf_result_1:
FIT_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,0]),4))
TEST_TIME=[]
for perf in perf_result_1:
TEST_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,3]),4))
MAE = DataFrame(MAE,columns=['MAE'])
RMSE = DataFrame(RMSE,columns=['RMSE'])
FIT_TIME = DataFrame(FIT_TIME,columns=['FIT_TIME'])
TEST_TIME = DataFrame(TEST_TIME,columns=['TEST_TIME'])
k = DataFrame([1,3,5,7,9,11,13,15,17,19,21,23,25,27,29],columns=['k'])
KNNWithMeans_result = pd.concat([k,MAE,RMSE,FIT_TIME,TEST_TIME],axis=1)
KNNWithMeans_result.to_csv('./result_data/KNNWithMeans_result1.csv',header=True,encoding='utf-8')
############################################## KNNWithZScore
#algo = KNNWithZScore(k=1,sim_options = {'name': 'pearson','user_based': True})# 皮爾遜基於使用者
## 指定檔案路徑
file_path = os.path.expanduser('./python_data.txt')
## 指定檔案格式\n",
reader = Reader(line_format='user item rating timestamp', sep=',')
## 從檔案讀取資料
data = Dataset.load_from_file(file_path, reader=reader)
algo1 = KNNWithZScore(k=1,sim_options = {'name': 'pearson','user_based': True})
algo2 = KNNWithZScore(k=3,sim_options = {'name': 'pearson','user_based': True})
algo3 = KNNWithZScore(k=5,sim_options = {'name': 'pearson','user_based': True})
algo4 = KNNWithZScore(k=7,sim_options = {'name': 'pearson','user_based': True})
algo5 = KNNWithZScore(k=9,sim_options = {'name': 'pearson','user_based': True})
algo6 = KNNWithZScore(k=11,sim_options = {'name': 'pearson','user_based': True})
algo7 = KNNWithZScore(k=13,sim_options = {'name': 'pearson','user_based': True})
algo8 = KNNWithZScore(k=15,sim_options = {'name': 'pearson','user_based': True})
algo9 = KNNWithZScore(k=17,sim_options = {'name': 'pearson','user_based': True})
algo10 = KNNWithZScore(k=19,sim_options = {'name': 'pearson','user_based': True})
algo11 = KNNWithZScore(k=21,sim_options = {'name': 'pearson','user_based': True})
algo12 = KNNWithZScore(k=23,sim_options = {'name': 'pearson','user_based': True})
algo13 = KNNWithZScore(k=25,sim_options = {'name': 'pearson','user_based': True})
algo14 = KNNWithZScore(k=27,sim_options = {'name': 'pearson','user_based': True})
algo15 = KNNWithZScore(k=29,sim_options = {'name': 'pearson','user_based': True})
# 在資料集上測試一下效果
perf_001 = cross_validate(algo1,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_002 = cross_validate(algo2,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_003 = cross_validate(algo3,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_004 = cross_validate(algo4,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_005 = cross_validate(algo5,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_006 = cross_validate(algo6,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_007 = cross_validate(algo7,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_008 = cross_validate(algo8,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_009 = cross_validate(algo9,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_0010 = cross_validate(algo10,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_0011 = cross_validate(algo11,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_0012 = cross_validate(algo12,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_0013 = cross_validate(algo13,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_0014 = cross_validate(algo14,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_0015 = cross_validate(algo15,data, measures=['RMSE', 'MAE'],cv=5,verbose=True)
perf_result_1=[]
for i in range(1,16):
perf_result_1.append('perf_00'+ str(i))
MAE=[]
for perf in perf_result_1:
MAE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,1]),4))
RMSE=[]
for perf in perf_result_1:
RMSE.append(round(np.mean(DataFrame(eval(perf)).iloc[:,2]),4))
FIT_TIME=[]
for perf in perf_result_1:
FIT_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,0]),4))
TEST_TIME=[]
for perf in perf_result_1:
TEST_TIME.append(round(np.mean(DataFrame(eval(perf)).iloc[:,3]),4))
MAE = DataFrame(MAE,columns=['MAE'])
RMSE = DataFrame(RMSE,columns=['RMSE'])
FIT_TIME = DataFrame(FIT_TIME,columns=['FIT_TIME'])
TEST_TIME = DataFrame(TEST_TIME,columns=['TEST_TIME'])
k = DataFrame([1,3,5,7,9,11,13,15,17,19,21,23,25,27,29],columns=['k'])
KNNWithZScore_result = pd.concat([k,MAE,RMSE,FIT_TIME,TEST_TIME],axis=1)
KNNWithZScore_result.to_csv('./result_data/KNNWithZScore_result1.csv',header=True,encoding='utf-8')
R之資料視覺化
##############協同過濾結果視覺化
library(ggplot2)
library(ggthemr)
library(easyGgplot2)
KNNBasic_result <- read.csv('KNNBasic_result1.csv',encoding = 'utf-8')
KNNWithMeans_result <- read.csv('KNNWithMeans_result1.csv',encoding = 'utf-8')
KNNWithZScore_result <- read.csv('KNNWithZScore_result1.csv',encoding = 'utf-8')
KNNBasic_result <- as.data.table(KNNBasic_result)
KNNWithMeans_result <- as.data.table(KNNWithMeans_result)
KNNWithZScore_result <- as.data.table(KNNWithZScore_result)
KNNBasic_result <- KNNBasic_result[,KNN_class:='KNNBasic']
KNNWithMeans_result <- KNNWithMeans_result[,KNN_class:='KNNWithMeans']
KNNWithZScore_result <- KNNWithZScore_result[,KNN_class:='KNNWithZScore']
merge_KNN_result <- rbind(KNNBasic_result,KNNWithMeans_result,KNNWithZScore_result)
merge_KNN_result <- merge_KNN_result[,-1]
# plot result
colour <- c('#34495e','#3498db','#2ecc71','#f1c40f','#e74c3c','#9b59b6','#1abc9c')
mycol <- define_palette(swatch = colour,gradient = c(lower=colour[1L],upper=colour[2L]))
ggthemr(mycol)
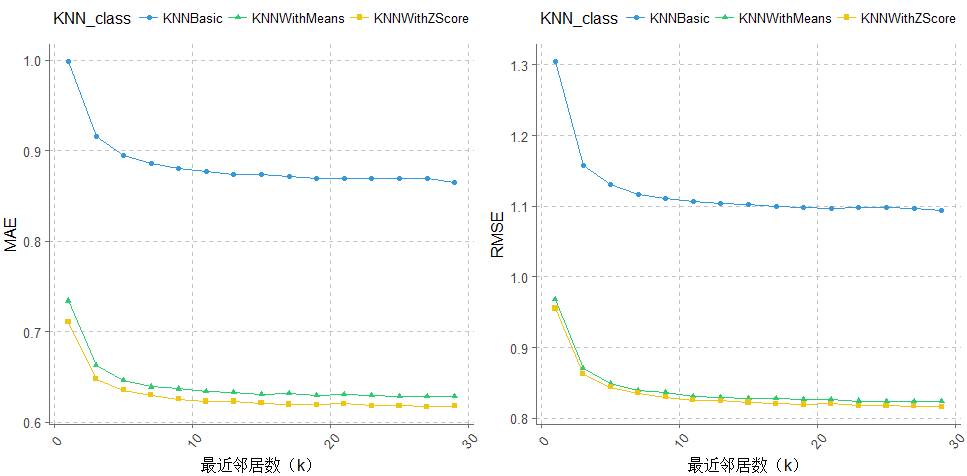
p001 <- ggplot(data= merge_KNN_result, aes(x=k, y= MAE,group=KNN_class, shape=KNN_class, color=KNN_class)) +
geom_line()+
geom_point()+
xlab('最近鄰居數(k)')+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
p002 <- ggplot(data= merge_KNN_result, aes(x=k, y= RMSE,group=KNN_class, shape=KNN_class, color=KNN_class)) +
geom_line()+
geom_point()+
xlab('最近鄰居數(k)')+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
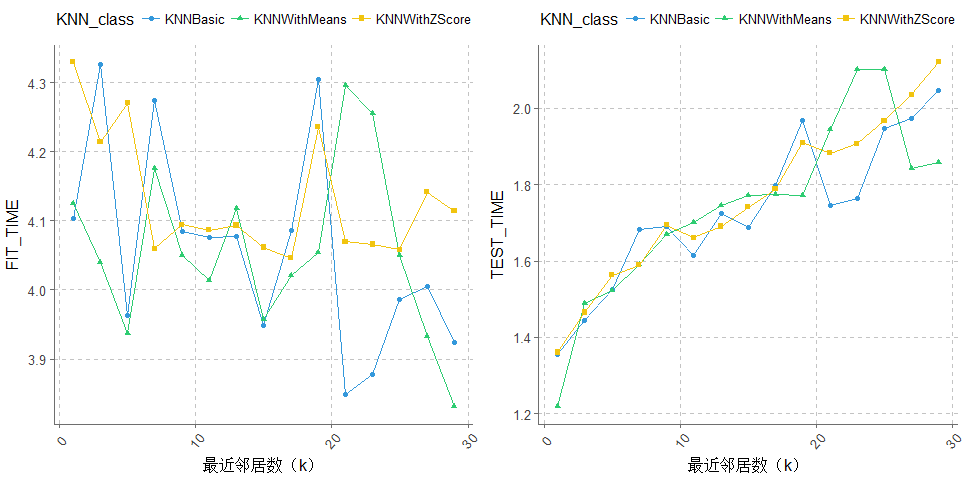
p0001 <- ggplot(data= merge_KNN_result, aes(x=k, y= FIT_TIME,group=KNN_class, shape=KNN_class, color=KNN_class)) +
geom_line()+
geom_point()+
xlab('最近鄰居數(k)')+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
p0002 <- ggplot(data= merge_KNN_result, aes(x=k, y= TEST_TIME,group=KNN_class, shape=KNN_class, color=KNN_class)) +
geom_line()+
geom_point()+
xlab('最近鄰居數(k)')+
theme(legend.position="top",axis.text.x = element_text(angle = 50, hjust = 0.5, vjust = 0.5),
text = element_text(color = "black", size = 12))
x11()
ggplot2.multiplot(p001,p002,cols = 2)
x11()
ggplot2.multiplot(p0001,p0002,cols = 2)演算法結果比較
相關推薦
推薦演算法之協同過濾例項
接著上次的資料進行協同過濾演算法應用 應用的知識 python的surprise k折交叉驗證 R資料構建 KNNBasic KNNWithMeans KNNWithZScore 資料處理與演算法 # 協同過濾演算法資料構建 user
[機器學習]推薦系統之協同過濾演算法
在現今的推薦技術和演算法中,最被大家廣泛認可和採用的就是基於協同過濾的推薦方法。本文將帶你深入瞭解協同過濾的祕密。下面直接進入正題. 1. 什麼是推薦演算法 推薦演算法最早在1992年就提出來了,但是火起來實際上是最近這些年的事情,因為網際網路的爆發,有了更大的資料量可以供我們使用,推薦演算法才有了很大的用武
推薦系統之協同過濾(CF)演算法
一,集體智慧(社會計算): 集體智慧 (Collective Intelligence) 並不是 Web2.0 時代特有的,只是在Web2.0 時代,大家在 Web 應用中,利用集體智慧構建了更加有趣的應用或者得到更好的使用者體驗。集體智慧是指在大量
【推薦演算法】協同過濾演算法——基於使用者 Java實現
基本概念就不過多介紹了,相信能看明白的都瞭解。如果想了解相關推薦先做好知識儲備: 1.什麼事推薦演算法 2.什麼是基於鄰域的推薦演算法 筆者選用的是GroupLens的MoviesLens資料 傳送門GroupLens 資料集處理 此處擷取資
推薦演算法概述:基於內容的推薦演算法、協同過濾推薦演算法和基於知識的推薦演算法
所謂推薦演算法就是利用使用者的一些行為,通過一些數學演算法,推測出使用者可能喜歡的東西。推薦演算法主要分為兩種 1. 基於內容的推薦 基於內容的資訊推薦方法的理論依據主要來自於資訊檢索和
推薦演算法之關聯規則例項
利用的知識 深度分箱 Apriori演算法 資料連線、聚合等處理 資料說明 本資料來源於last.fm的資料 資料包含: 1892 users 17632 artists 12717 bi-directional user frien
機器學習演算法(推薦演算法)—協同過濾推薦演算法(2)
一、基於協同過濾的推薦系統 協同過濾(Collaborative Filtering)的推薦系統的原理是通過將使用者和其他使用者的資料進行比對來實現推薦的。比對的具體方法就是通過計算兩個使用者
協同過濾推薦演算法之Slope One的介紹
Slope One 之一 : 簡單高效的協同過濾演算法(轉)( 原文地址:http://blog.sina.com.cn/s/blog_4d9a06000100am1d.html 現在做的一個專案中需要用到推薦演算法, 在網上查了一下. Beyo
hadoop2.5.2學習14--MR之協同過濾天貓推薦演算法實現01
一、程式碼步驟: 1、 去重 2、 獲取所有使用者的喜歡矩陣: 3、 獲得所有物品之間的同現矩陣 4、 兩個矩陣相乘得到三維矩陣 5、 三維矩陣的資料相加獲得所有使用者對所有物品的推薦值(二維矩陣) 6、 按照推薦值降序排序。
推薦演算法之基於物品的協同過濾
基於物品的協同過濾( item-based collaborative filtering )演算法是此前業界應用較多的演算法。無論是亞馬遜網,還是Netflix 、Hulu 、 YouTube ,其推薦演算法的基礎都是該演算法。為行文方便,下文以英文簡稱ItemCF表示。本文將從其基礎演算法講起,一步步進行
推薦系統中協同過濾演算法實現分析(重要兩個圖!!)
“協”,指許多人協力合作。 “協同”,就是指協調兩個或者兩個以上的不同資源或者個體,協同一致地完成某一目標的過程。 “協同過濾”,簡單來說,就是利用興趣相投或擁有共同經驗的群體的喜好來給使用者推薦感興趣的資訊,記錄下來個人對於資訊相當程度的迴應(如評分),以達到過濾的目的,進而幫助別人篩
基於譜聚類SM演算法的協同過濾推薦演算法研究——清華師兄畢業論文學習
一、個性化推薦演算法 1.相似度的比較 兩個商品或者商品之間相似的的計算方法,量化屬性為非數值型資料的商品或者使用者之間的接近程度。通常我們計算使用者或者專案間相似度的主要方法有餘弦相似度(Cosime Similarity)、Jaccard係數和pearson相關(pearson Corr
推薦系統:協同過濾 之 Item-based Collaborative Filtering
說起 Item-based collaborative filtering,還有一段有意思的爭論,是關於它的起源的。 GroupLens 研究小組的 Sarwar 教授等人,於2001年5月在香港召開的第 10 屆 WWW 大會上,發表了題為《Item-based Collaborative Filteri
推薦之協同過濾(思路簡單梳理)
用途 是什麼 找一群跟我品味相近的人,去看看他們經常瀏覽的商品,並且我沒有瀏覽的推薦給我。 基於使用者的協同過濾怎麼做 第一步就是要收集每個人的偏好 以電影為例,如果我有一份資料清單,有每個人對一些電影的評分,通過這些評分,我們
推薦演算法之用矩陣分解做協調過濾——LFM模型
隱語義模型(Latent factor model,以下簡稱LFM),是推薦系統領域上廣泛使用的演算法。它將矩陣分解應用於推薦演算法推到了新的高度,在推薦演算法歷史上留下了光輝燦爛的一筆。本文將對 LFM原理進行詳細闡述,給出其基本演算法原理。此外,還將介紹使得隱語義模型聲名大噪的演算法FunkSVD和在其基
基於內容的推薦演算法的實現程式碼例項
本次例項需要三個資料檔案 分別為節目及其所屬標籤型別的01矩陣;使用者--節目評分矩陣;使用者收視了的節目--標籤01矩陣。 可以直接下載下來使用https://download.csdn.net/download/qq_38281438/10757266 具體程式碼如下: #
Python之協同過濾(尋找相近的使用者)
資料內容是人們對不同電影的評價:我們通過計算人與人之間評價電影的相關度來找到口味相同的人,根據口味相同的人來推薦可能喜歡的電影。 資料如下: critics={'lisa rose':{'lady in the Water':2.5,'snakes
推薦演算法之相似性推薦
前文介紹了協同過濾演算法和基於內容的推薦演算法 協同過濾演算法要求要有很多使用者,使用者有很多操作 基於內容的推薦演算法使用者可以不用很多,但是使用者的操作也要有很多 但是,如果要推薦給新使用者(使用者的操作不多),應該要怎樣推薦呢?這裡就要用到相似性推薦了 相似性推薦定
推薦演算法之-皮爾遜相關係數計算兩個使用者喜好相似度
<?php /** * 餘玄相似度計算出3個使用者的相似度 * 通過7件產品分析使用者喜好相似度 * 相似度使用函式 sim(user1,user2) =cos∂ * * 設A、B為多維
推薦演算法之Jaccard相似度與Consine相似度
0-- 前言:對於個性化推薦來說,最核心、重要的演算法是相關性度量演算法。相關性從網站物件來分,可以針對商品、使用者、旺鋪、資訊、類目等等,從計算方式看可以分為文字相關性計算和行為相關性計算,具體的實現方法有很多種,最常用的方法有餘弦夾角(Cosine)方法、傑卡德(Jacc