
MobileNet論文閱讀筆記
MobileNet
(1)文章介紹
- google 201704在archive上的論文。
- 採用depthwise separable卷積核,減少計算量和模型大小。
- 引入了兩個超引數,用於選擇合適大小的模型。
- 在imagenet, object dectection, face atrributes,分類等任務上驗證了效果。
(2)核心思想
將標準卷積層分解為depthwise conv和 pointwise conv(1*1)兩個卷積層。即一個depthwise separable卷積核包括depth wise卷積操作和pointwise卷積操作。
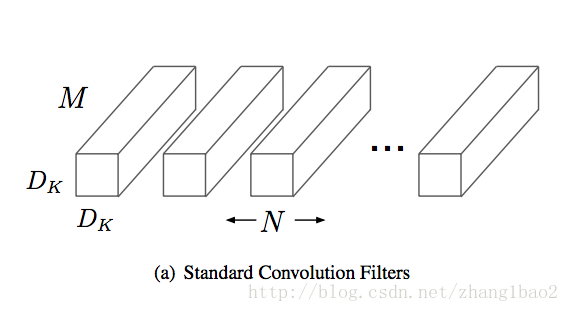
對於標準卷積,輸入大小為D_f*D_f*M,輸出大小為D_f *D_f *N,卷積核的大小為D_k*D_k*M*N。(這裡假設stride為 1,padding=0, 因此長寬不變)
標準卷積計算: F和G分別表示輸入和輸出特徵圖,(s=0, p=1, h_o = h_in -k + 1)
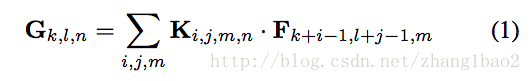
計算量分析:(要計算出D_f * D_f個值, 計算每個值需要對應的所有對應滑動視窗的值相乘,然後所有通道的值相加merge, 這裡加法的計算量忽略不計)
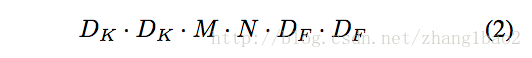
第一步為depth wise卷積
對於輸入的每一個通道分別用1個D_k * D_k*1的卷積核進行卷積,共使用了M個卷積核,操作M次,得到M個D_f * D_f * 1的特徵圖。這些特徵圖分別是從輸入的不同通道學習而來,彼此獨立。
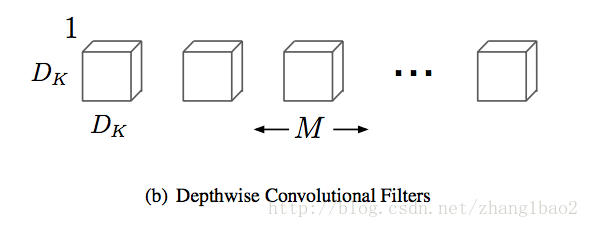
depth wise計算(注意與標準卷積對比,求和的下標裡面沒有m, 說明其實各個通道是獨立的,這裡將m次操作表達為一個公式,論文中也表述depth wise kernel大小為D_k * D_k * M, 但這個跟標準卷積核不一樣,M不代表卷積核的通道數)
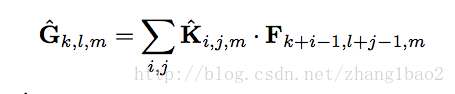
計算量分析: (需要計算出 D_f * D_ f個值,每次的計算量為 D_k * D_k, 迴圈M次)
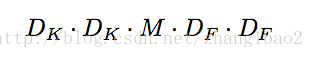
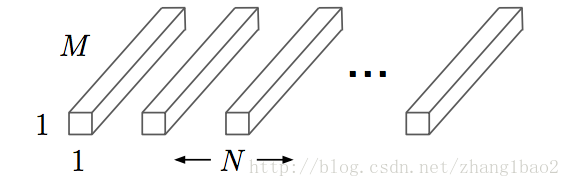
第二步為point wise卷積
對於上一步得到的M個特徵圖作為M個通道的輸入,用N個1*1*M的卷積核進行標準卷積,得到D_f * D_f * N的輸出。
計算量分析: 計算量按標準卷積的公式,其中D_k = 1, 計算量為1*1*M*N*D_f*D_f
節約計算量分析:
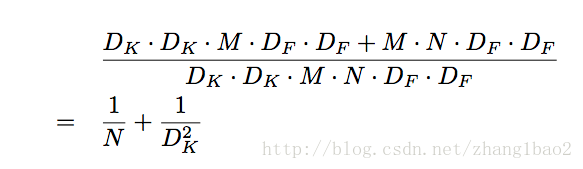
一般卷積核為3*3,計算量能節省9倍左右。
(3)網路結構設計
- 區域性結構
- 輸入第一層不用deptwise separable convolution
- 每一層後面接bn與relu.(除了最後一層全連線層不接非線性直接接入softmax)
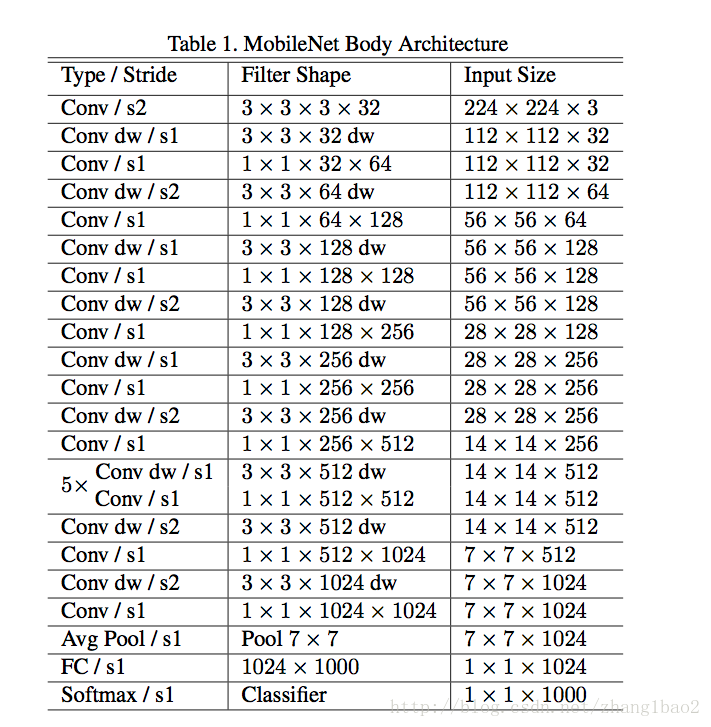
總的網路結構
- 下采樣部分通過第一層卷積以及某些 depth wise convolution的stride =2實現。
- 最後一層的average pooling是為了把輸出解析度壓縮到1*1
- Mobile Net共28層

(3)實驗經驗
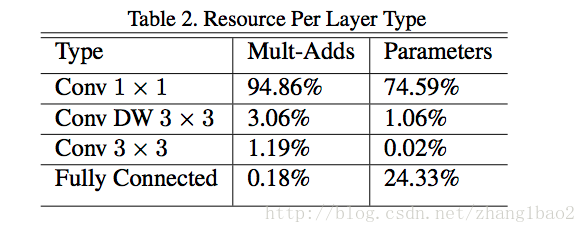
- 基本上所有的計算量均集中在1*1的conv操作上, GEMM的方法中有im2col的步驟,1*1conv不需要這個recording步驟。
- 對於depth wise filters採用很小或沒有的weight decay(L2 regularization)
(4)新的超引數
width multiplier: thinner models
將某個層的將輸入和輸出的channel 均壓縮
α 倍, 引數取值為1,0.75,0.5,0.25. 可以將計算量和引數量減少α2 倍resolution multiplier:Reduced Representation
因子
ρ 將網路輸入的大小降至224,192,160,128,可以將計算量減少ρ2 倍將網路變瘦比將網路變淺的效果要好,說明網路深度的重要性。
相關推薦
MobileNet論文閱讀筆記
MobileNet (1)文章介紹 google 201704在archive上的論文。 採用depthwise separable卷積核,減少計算量和模型大小。 引入了兩個超引數,用於選擇合適大小的模型。 在imagenet, object dectec
關鍵字抽取論文閱讀筆記
三種 度量 gin 提高 簡單 類模型 分類問題 同時 權重 劉知遠老師博士論文-基於文檔主題結構的關鍵詞抽取方法研究 一、研究背景和論文工作介紹 關鍵詞抽取分為兩步:選取候選關鍵詞和從候選集合中推薦關鍵詞。 1.1. 選取候選關鍵詞 關鍵詞:單個詞或者多個單詞組成的短
《The challenge of realistic music generation: modelling raw audio at scale》論文閱讀筆記
mes esc color del strac argmax bst repr 幫助 The challenge of realistic music generation: modelling raw audio at scale 作者:Deep mind三位大神
《Macro-Micro Adversarial Network for Human Parsing》論文閱讀筆記
邊界 分享圖片 strong 避免 也有 ima 1.4 以及 potential 《Macro-Micro Adversarial Network for Human Parsing》 摘要:在人體語義分割中,像素級別的分類損失在其低級局部不一致性和高級語義不一致性方面存
論文閱讀筆記《The Contextual Loss for Image Transformation with Non-Aligned Data》(ECCV2018 oral)
github 區域 偏移 org nbsp 修改 transfer style 但是 目錄: 相關鏈接 方法亮點 相關工作 方法細節 實驗結果 總結與收獲 相關鏈接 論文:https://arxiv.org/abs/1803.02077 代碼:https://
論文閱讀筆記(一)LeNet--Gradient-Based Learning Applied to Document Recognition
輸入 共享 rbf map 內部 field dex title 手動 作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner這篇論文內容較多,這裏只對部分內容進行記錄:以下是對論文原文的翻譯:在傳統的模式識
論文閱讀筆記(十一)Network In Network
hole orm 後來 entropy function ppr master 3層 上進 該論文提出了一種新穎的深度網絡結構,稱為“Network In Network”(NIN),以增強模型對感受野內local patches的辨別能力。與傳統的CNNs相比,NIN主要
論文閱讀筆記(六)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
采樣 分享 最終 產生 pre 運算 減少 att 我們 作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian SunSPPnet、Fast R-CNN等目標檢測算法已經大幅降低了目標檢測網絡的運行時間。可是盡管如此,仍然
論文閱讀筆記 DeepLabv1:SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
bar pro 依賴性 後處理 主題 處理 分配 位置 平滑 論文鏈接:https://arxiv.org/abs/1412.7062 摘要 該文將DCNN與概率模型結合進行語義分割,並指出DCNN的最後一層feature map不足以進行準確的語義分割
論文閱讀筆記(九)YOLOv3: An Incremental Improvement
專案地址 Abstract 該技術報告主要介紹了作者對 YOLOv1 的一系列改進措施(注意:不是對YOLOv2,但是借鑑了YOLOv2中的部分改進措施)。雖然改進後的網路較YOLOv1大一些,但是檢測結果更精確,執行速度依然很快。在輸入影象解析度
DensePose:Dense Human Pose Estimation In The Wild 論文閱讀筆記
一、本文主要是Facebook AI 和INRIA 聯合出品,基於RCNN架構,以及Mask RCNN的多工結構,開源http://densepose.org 二、主要工作分為三點 1:標註了一個新的資料集,基於coco資料集,增加了u
《Self-Protection of Android Systems from Inter-component Communication Attacks》論文閱讀筆記
前言 本篇部落格是用來記錄自己在閱讀《Self-Protection of Android Systems from Inter-component Communication Attacks》這篇論文期間的閱讀筆記,方便自己日後翻閱檢視,如果對於這篇論文的閱讀有什麼不正確的地方,歡迎大家批評指
《System Service Call-oriented Symbolic Execution of Android Framework with Applications to...》論文閱讀筆記
System Service Call-oriented Symbolic Execution of Android Framework with Applications to Vulnerability Discovery and Exploit Generation 用於Andro
《AppIntent - Analyzing Sensitive Data Transmission in Android for Privacy Leakage Detection》論文閱讀筆記
AppIntent: Analyzing Sensitive Data Transmission in Android for Privacy Leakage Detection APPIntent:分析敏感資料傳播在Android裝置中隱私洩露的檢測 文獻引
【論文閱讀筆記3】序列模型入門之LSTM和GRU
本文只是吳恩達視訊課程關於序列模型一節的筆記。 參考資料: 吳恩達深度學習工程師微專業之序列模型 博文——理解LSTM 吳恩達本來就是根據這篇博文的內容來講的,所以 個人認為 認真學習過吳恩達講的那個課程後可以不用再看那篇博文了,能獲得的新的知識不多,另外網上的博文基本也都是根據那篇
ECCV 2018 論文閱讀筆記——Acquisition of Localization Confidence for Accurate Object Detection
目標檢測涉及到目標分類和目標定位,但很多基於 CNN 的目標檢測方法都存在分類置信度和定位置信度不匹配的問題。針對這一問題,一種稱之為 IoU-Net 的目標檢測新方法被提出,在基準方法的基礎上實現了顯著的提升。該論文已被將於當地時間 9 月 8
【論文閱讀筆記】Deep Learning based Recommender System: A Survey and New Perspectives
【論文閱讀筆記】Deep Learning based Recommender System: A Survey and New Perspectives 2017年12月04日 17:44:15 cskywit 閱讀數:1116更多 個人分類: 機器學習
論文閱讀筆記:《Contextual String Embeddings for Sequence Labeling》
文章引起我關注的主要原因是在CoNLL03 NER的F1值超過BERT達到了93.09左右,名副其實的state-of-art。考慮到BERT訓練的資料量和引數量都極大,而該文方法只用一個GPU訓了一週,就達到了state-of-art效果,值得花時間看看。 一句話總結:使用BiLSTM模型,用動態embe
06 ResNeXt論文閱讀筆記
1. 提出背景 2. 核心思想 3. 論文核心 4. 組卷積 5. 核心程式碼 論文: Aggregated Residual Transformations for Deep Neural Networks 論文地址: https://arxiv.org/a
論文閱讀筆記十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
每一個 內核 基於 proc vgg 包含 rep 重要 偏差 論文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet 摘要