
RAID陣列與LVM邏輯卷組原理
Raid陣列和lvm邏輯卷組主要用於磁碟備份和擴充套件,其中Raid用於磁碟備份,lvm用於磁碟空間管理。
一.Raid工作原理
1.什麼是Raid
RAID(Redundant Array of Inexpensive Disks)稱為廉價磁碟冗餘陣列。RAID 的基本原理是把多個便宜的小磁碟組合到一起,成為一個磁碟組,使效能達到或超過一個容量巨大、價格昂貴的磁碟。
目前 RAID技術大致分為兩種:基於硬體的RAID技術和基於軟體的RAID技術。其中在 Linux下通過自帶的軟體就能實現RAID功能,這樣便可省去購買昂貴的硬體 RAID 控制器和附件就能極大地增強磁碟的 IO 效能和可靠性。由於是用軟體去實現的RAID功能,所以它配置靈活、管理方便。同時使用軟體RAID,還可以實現將幾個物理磁碟合併成一個更大的虛擬設 備,從而達到效能改進和資料冗餘的目的。當然基於硬體的RAID解決方案比基於軟體RAID技術在使用效能和服務效能上稍勝一籌,具體表現在檢測和修復多 位錯誤的能力、錯誤磁碟自動檢測和陣列重建等方面。
2.RAID級別介紹
一般常用的RAID階層,分別是RAID 0、RAID1、RAID 2、RAID 3、RAID 4以及RAID 5,再加上二合一型 RAID 0+1﹝或稱RAID 10﹞。我們先把這些RAID級別的優、缺點做個比較:
RAID級別 相對優點 相對缺點
RAID 0 存取速度最快 沒有容錯
RAID 1 完全容錯 成本高
RAID 2 帶海明碼校驗,資料冗餘多,速度慢
RAID 3 寫入效能最好 沒有多工功能
RAID 4 具備多工及容錯功能 Parity 磁碟驅動器造成效能瓶頸
RAID 5 具備多工及容錯功能 寫入時有overhead
RAID 0+1/RAID 10 速度快、完全容錯 成本高
- RAID 0 的特點、原理與應用
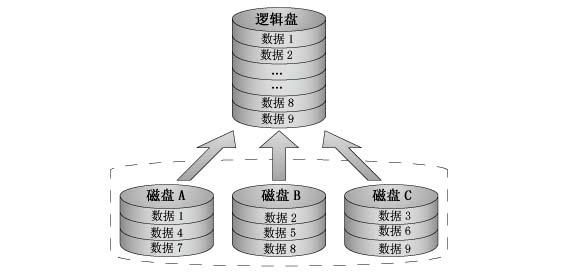
也稱為條帶模式(striped),即把連續的資料分散到多個磁碟上存取,如圖所示。當系統有資料請求就可以被多個磁碟並行的執行,每個磁碟執行屬於它自 己的那部分資料請求。這種資料上的並行操作可以充分利用匯流排的頻寬,顯著提高磁碟整體存取效能。因為讀取和寫入是在裝置上並行完成的,讀取和寫入效能將會 增加,這通常是執行 RAID 0 的主要原因。但RAID 0沒有資料冗餘,如果驅動器出現故障,那麼將無法恢復任何資料。
RAID 0:無差錯控制的帶區組
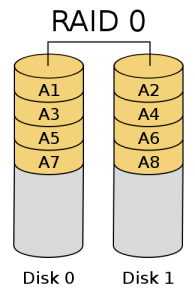
要實現RAID0必須要有兩個以上硬碟驅動器,RAID0實現了帶區組,資料並不是儲存在一個硬碟上,而是分成資料塊儲存在不同驅 動器上。因為將資料分佈在不同驅動器上,所以資料吞吐率大大提高,驅動器的負載也比較平衡。如果剛好所需要的資料在不同的驅動器上效率最好。它不需要計算 校驗碼,實現容易。它的缺點是它沒有資料差錯控制,如果一個驅動器中的資料發生錯誤,即使其它盤上的資料正確也無濟於事了。不應該將它用於對資料穩定性要 求高的場合。如果使用者進行圖象(包括動畫)編輯和其它要求傳輸比較大的場合使用RAID0比較合適。同時,RAID可以提高資料傳輸速率,比如所需讀取的 檔案分佈在兩個硬碟上,這兩個硬碟可以同時讀取。那麼原來讀取同樣檔案的時間被縮短為1/2。在所有的級別中,RAID 0的速度是最快的。但是RAID 0沒有冗餘功能的,如果一個磁碟(物理)損壞,則所有的資料都無法使用。
- RAID 1 的特點、原理與應用
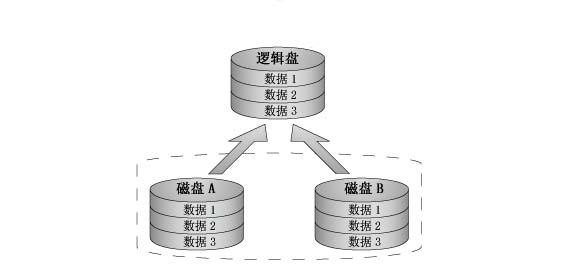
RAID 1 又稱為映象(Mirroring),一個具有全冗餘的模式,如圖所示。RAID 1可以用於兩個或2xN個磁碟,並使用0塊或更多的備用磁碟,每次寫資料時會同時寫入映象盤。這種陣列可靠性很高,但其有效容量減小到總容量的一半,同時 這些磁碟的大小應該相等,否則總容量只具有最小磁碟的大小。
RAID 1:鏡象結構
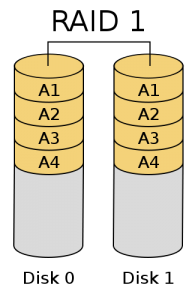
對於使用這種RAID1結構的裝置來說,RAID控制器必須能夠同時對兩個盤進行讀操作和對兩個鏡象盤進行寫操作。通過下面的結構 圖您也可以看到必須有兩個驅動器。因為是鏡象結構在一組盤出現問題時,可以使用鏡象,提高系統的容錯能力。它比較容易設計和實現。每讀一次盤只能讀出一塊 資料,也就是說資料塊傳送速率與單獨的盤的讀取速率相同。因為RAID1的校驗十分完備,因此對系統的處理能力有很大的影響,通常的RAID功能由軟體實 現,而這樣的實現方法在伺服器負載比較重的時候會大大影響伺服器效率。當您的系統需要極高的可靠性時,如進行資料統計,那麼使用RAID1比較合適。而且 RAID1技術支援“熱替換”,即不斷電的情況下對故障磁碟進行更換,更換完畢只要從映象盤上恢復資料即可。當主硬碟損壞時,映象硬碟就可以代替主硬碟工 作。映象硬碟相當於一個備份盤,可想而知,這種硬碟模式的安全性是非常高的,RAID 1的資料安全性在所有的RAID級別上來說是最好的。但是其磁碟的利用率卻只有50%,是所有RAID級別中最低的。
- RAID 2 的特點、原理與應用
RAID 2:帶海明碼校驗
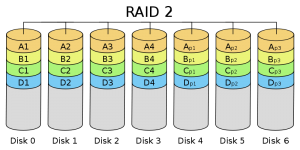
從概念上講,RAID 2 同RAID 3類似, 兩者都是將資料條塊化分佈於不同的硬碟上, 條塊單位為位或位元組。然而RAID 2 使用一定的編碼技術來提供錯誤檢查及恢復。這種編碼技術需要多個磁碟存放檢查及恢復資訊,使得RAID 2技術實施更復雜。因此,在商業環境中很少使用。下圖左邊的各個磁碟上是資料的各個位,由一個數據不同的位運算得到的海明校驗碼可以儲存另一組磁碟上,具 體情況請見下圖。由於海明碼的特點,它可以在資料發生錯誤的情況下將錯誤校正,以保證輸出的正確。它的資料傳送速率相當高,如果希望達到比較理想的速度, 那最好提高儲存校驗碼ECC碼的硬碟,對於控制器的設計來說,它又比RAID3,4或5要簡單。沒有免費的午餐,這裡也一樣,要利用海明碼,必須要付出數 據冗餘的代價。輸出資料的速率與驅動器組中速度最慢的相等。
- RAID 3 特點、原理與應用
RAID 3 是將資料先做XOR 運算,產生Parity Data後,在將資料和Parity Data 以並行存取模式寫入成員磁碟驅動器中,因此具備並行存取模式的優點和缺點。進一步來說,RAID 3每一筆資料傳輸,都更新整個Stripe﹝即每一個成員磁碟驅動器相對位置的資料都一起更新﹞,因此不會發生需要把部分磁碟驅動器現有的資料讀出來,與 新資料作XOR運算,再寫入的情況發生﹝這個情況在 RAID 4和RAID 5會發生,一般稱之為Read、Modify、Write Process,我們姑且譯為為讀、改、寫過程﹞。因此,在所有 RAID級別中,RAID 3的寫入效能是最好的。
RAID 3 的 Parity Data 一般都是存放在一個專屬的Parity Disk,但是由於每筆資料都更新整個Stripe,因此,RAID 3的 Parity Disk 並不會如RAID 4的 Parity Disk,會造成存取的瓶頸。
RAID 3 的並行存取模式,需要RAID 控制器特別功能的支援,才能達到磁碟驅動器同步控制,而且上述寫入效能的優點,以目前的Caching 技術,都可以將之取代,因此一般認為RAID 3的應用,將逐漸淡出市場。
RAID 3 以其優越的寫入效能,特別適合用在大型、連續性檔案寫入為主的應用,例如繪圖、影像、視訊編輯、多媒體、資料倉儲、高速資料擷取等等。
RAID3:帶奇偶校驗碼的並行傳送
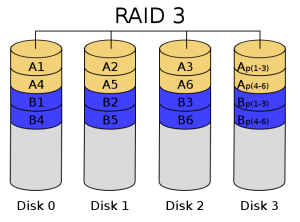
這種校驗碼與RAID2不同,只能查錯不能糾錯。它訪問資料時一次處理一個帶區,這樣可以提高讀取和寫入速度,它像RAID 0一樣以並行的方式來存放資料,但速度沒有RAID 0快。校驗碼在寫入資料時產生並儲存在另一個磁碟上。需要實現時使用者必須要有三個以上的驅動器,寫入速率與讀出速率都很高,因為校驗位比較少,因此計算時 間相對而言比較少。用軟體實現RAID控制將是十分困難的,控制器的實現也不是很容易。它主要用於圖形(包括動畫)等要求吞吐率比較高的場合。不同於 RAID 2,RAID 3使用單塊磁碟存放奇偶校驗資訊。如果一塊磁碟失效,奇偶盤及其他資料盤可以重新產生資料。 如果奇偶盤失效,則不影響資料使用。RAID 3對於大量的連續資料可提供很好的傳輸率,但對於隨機資料,奇偶盤會成為寫操作的瓶頸。 利用單獨的校驗盤來保護資料雖然沒有映象的安全性高,但是硬碟利用率得到了很大的提高,為n-1。
- RAID 4 特點、原理與應用
建立RAID 4需要三塊或更多的磁碟,它在一個驅動器上儲存校驗資訊,並以RAID 0方式將資料寫入其它磁碟,如圖所示。因為一塊磁碟是為校驗資訊保留的,所以陣列的大小是(N-l)*S,其中S是陣列中最小驅動器的大小。就像在 RAID 1中那樣,磁碟的大小應該相等。
如果一個驅動器出現故障,那麼可以使用校驗資訊來重建所有資料。如果兩個驅動器出現故障,那麼所有資料都將丟失。不經常使用這個級別的原因是校驗資訊儲存 在一個驅動器上。每次寫入其它磁碟時,都必須更新這些資訊。因此,在大量寫入資料時很容易造成校驗磁碟的瓶頸,所以目前這個級別的RAID很少使用了。
RAID 4 是採取獨立存取模式,同時以單一專屬的Parity Disk 來存放Parity Data。RAID 4的每一筆傳輸﹝Strip﹞資料較長,而且可以執行Overlapped I/O,因此其讀取的效能很好。
但是由於使用單一專屬的Parity Disk 來存放Parity Data,因此在寫入時,就會造成很大的瓶頸。因此,RAID 4並沒有被廣泛地應用。
RAID4:帶奇偶校驗碼的獨立磁碟結構
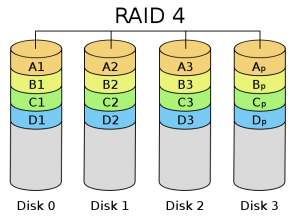
RAID4和RAID3很象,不同的是,它對資料的訪問是按資料塊進行的,也就是按磁碟進行的,每次是一個盤。在圖上可以這麼 看,RAID3是一次一橫條,而RAID4一次一豎條。它的特點的RAID3也挺象,不過在失敗恢復時,它的難度可要比RAID3大得多了,控制器的設計 難度也要大許多,而且訪問資料的效率不怎麼好。
- RAID 5特點、原理與應用
在希望結合大量物理磁碟並且仍然保留一些冗餘時,RAID 5 可能是最有用的 RAID 模式。RAID 5可以用在三塊或更多的磁碟上,並使用0塊或更多的備用磁碟。就像 RAID 4一樣,得到的 RAID5 裝置的大小是(N-1)*S。
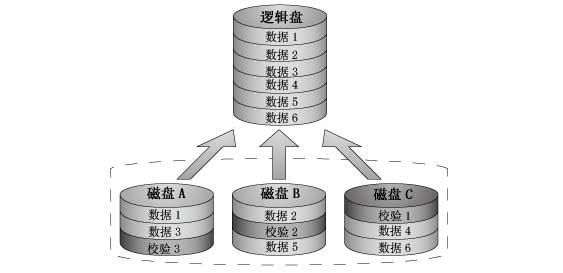
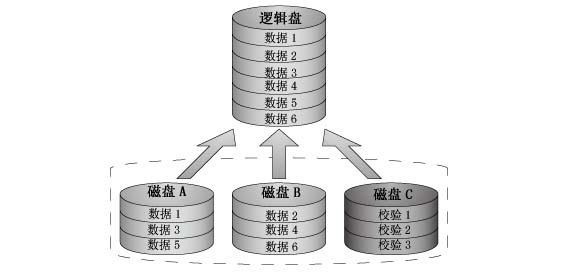
RAID5 與 RAID4 之間最大的區別就是校驗資訊均勻分佈在各個驅動器上,如圖4所示,這樣就避免了RAID 4中出現的瓶頸問題。如果其中一塊磁碟出現故障,那麼由於有校驗資訊,所以所有資料仍然可以保持不變。如果可以使用備用磁碟,那麼在裝置出現故障之後,將 立即開始同步資料。如果兩塊磁碟同時出現故障,那麼所有資料都會丟失。RAID5 可以經受一塊磁碟故障,但不能經受兩塊或多塊磁碟故障。
RAID 5也是採取獨立存取模式,但是其Parity Data 則是分散寫入到各個成員磁碟驅動器,因此,除了具備Overlapped I/O 多工效能之外,同時也脫離如RAID 4單一專屬Parity Disk的寫入瓶頸。但是,RAI?D 5在座資料寫入時,仍然稍微受到”讀、改、寫過程”的拖累。
由於RAID 5 可以執行Overlapped I/O 多工,因此當RAID 5的成員磁碟驅動器數目越多,其效能也就越高,因為一個磁碟驅動器再一個時間只能執行一個 Thread,所以磁碟驅動器越多,可以Overlapped 的Thread 就越多,當然效能就越高。但是反過來說,磁碟驅動器越多,陣列中可能有磁碟驅動器故障的機率就越高,整個陣列的可靠度,或MTDL (Mean Time to Data Loss) 就會降低。
由於RAID 5將Parity Data 分散存在各個磁碟驅動器,因此很符合XOR技術的特性。例如,當同時有好幾個寫入要求發生時,這些要寫入的資料以及Parity Data 可能都分散在不同的成員磁碟驅動器,因此RAID 控制器可以充分利用Overlapped I/O,同時讓好幾個磁碟驅動器分別作存取工作,如此,陣列的整體效能就會提高很多。
基本上來說,多人多工的環境,存取頻繁,資料量不是很大的應用,都適合選用RAID 5 架構,
例如企業檔案伺服器、WEB 伺服器、線上交易系統、電子商務等應用,都是資料量小,存取頻繁的應用。
RAID5:分散式奇偶校驗的獨立磁碟結構
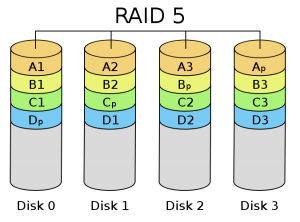
從它的示意圖上可以看到,它的奇偶校驗碼存在於所有磁碟上,其中的p0代表第0帶區的奇偶校驗值,其它的意思也相同。RAID5的 讀出效率很高,寫入效率一般,塊式的集體訪問效率不錯。因為奇偶校驗碼在不同的磁碟上,所以提高了可靠性,允許單個磁碟出錯。RAID 5也是以資料的校驗位來保證資料的安全,但它不是以單獨硬碟來存放資料的校驗位,而是將資料段的校驗位互動存放於各個硬碟上。這樣,任何一個硬碟損壞,都 可以根據其它硬碟上的校驗位來重建損壞的資料。硬碟的利用率為n-1。 但是它對資料傳輸的並行性解決不好,而且控制器的設計也相當困難。RAID 3 與RAID 5相比,重要的區別在於RAID 3每進行一次資料傳輸,需涉及到所有的陣列盤。而對於RAID 5來說,大部分資料傳輸只對一塊磁碟操作,可進行並行操作。在RAID 5中有“寫損失”,即每一次寫操作,將產生四個實際的讀/寫操作,其中兩次讀舊的資料及奇偶資訊,兩次寫新的資料及奇偶資訊。 RAID-5的話,優點是提供了冗餘性(支援一塊盤掉線後仍然正常執行),磁碟空間利用率較高(N-1/N),讀寫速度較快(N-1倍)。RAID5最大 的好處是在一塊盤掉線的情況下,RAID照常工作,相對於RAID0必須每一塊盤都正常才可以正常工作的狀況容錯效能好多了。因此RAID5是RAID級 別中最常見的一個型別。RAID5校驗位即P位是通過其它條帶資料做異或(xor)求得的。計算公式為P=D0xorD1xorD2…xorDn,其中p 代表校驗塊,Dn代表相應的資料塊,xor是數學運算子號異或。 RAID5校驗位演算法詳解 P=D1 xor D2 xor D3 … xor Dn (D1,D2,D3 … Dn為資料塊,P為校驗,xor為異或運算) XOR(Exclusive OR)的校驗原理如下表:
A值 B值 Xor結果
0 0 0
1 0 1
0 1 1
1 1 0
這裡的A與B值就代表了兩個位,從中可以發現,A與B一樣時,XOR(非或又稱”非異或”)結果為0,A與B不一樣時,XOR結 果就是1,如果知道XOR結果,A和B中的任何兩個數值,就可以反推出剩下的一個數值。比如A為1,XOR結果為1,那麼B肯定為0,如果XOR結果為 0,那麼B肯定為1。這就是XOR編碼與校驗的基本原理。
- RAID 0+1﹝RAID 10﹞的特點、原理與應用
RAID 0+1/RAID 10,綜合了RAID 0 和 RAID 1的優點,適合用在速度需求高,又要完全容錯,當然經費也很多的應用。 RAID 0和RAID 1的原理很簡單,合起來之後還是很簡單,我們不打算詳細介紹,倒是要談談,RAID 0+1到底應該是 RAID 0 over RAID 1,還是RAID 1 over RAID 0,也就是說,是把多個RAID 1 做成RAID 0,還是把多個 RAID 0 做成RAID 1?
RAID 0 over RAID 1
假設我們有四臺磁碟驅動器,每兩臺磁碟驅動器先做成RAID 1,再把兩個RAID 1做成RAID 0,這就是RAID 0 over RAID 1:
(RAID 1) A = Drive A1 + Drive A2 (Mirrored)
(RAID 1) B = Drive B1 + Drive B2 (Mirrored)
RAID 0 = (RAID 1) A + (RAID 1) B (Striped)
RAID 1 over RAID 0
假設我們有四臺磁碟驅動器,每兩臺磁碟驅動器先做成RAID 0,再把兩個RAID 0做成RAID 1,這就是RAID 1 over RAID 0:
(RAID 0) A = Drive A1 + Drive A2 (Striped)
(RAID 0) B = Drive B1 + Drive B2 (Striped)
RAID 1 = (RAID 1) A + (RAID 1) B (Mirrored)
在這種架構之下,如果 (RAID 0) A有一臺磁碟驅動器故障,(RAID 0) A就算毀了,當然RAID 1仍然可以正常工作;如果這時 (RAID 0) B也有一臺磁碟驅動器故障,(RAID 0) B也就算毀了,此時RAID 1的兩磁碟驅動器都算故障,整個RAID 1資料就毀了。
因此,RAID 0 OVER RAID 1應該比RAID 1 OVER RAID 0具備比較高的可靠度。所以我們建議,當採用RAID 0+1/RAID 10架構時,要先作RAID 1,再把數個RAID 1做成RAID 0。
3. 怎樣選擇Raid級別;
RAID 012345 到底哪一種適合你,不只是成本問題,容錯功能和傳輸效能的考慮以及未來之可擴充性都應該符合應用的需求。
RAID 在市場上的的應用,已經不是新鮮的事兒了,很多人都大略瞭解RAID的基本觀念,以及各個不同RAID LEVEL 的區分。但是在實際應用 面,我們發現,有很多使用者對於選擇一個合適的RAID LEVEL,仍然無法很確切的掌握,尤其是對於RAID 0+1 (10),RAID 3, RAID 5之間的選擇取捨,更是舉棋不定。
- RAID條切“striped”的存取模式
在使用資料條切﹝Data Stripping﹞ 的RAID 系統之中,對成員磁碟驅動器的存取方式,可分為兩種:
並行存取﹝Paralleled Access﹞
獨立存取﹝Independent Access﹞
RAID 2和RAID 3 是採取並行存取模式。
RAID 0、RAID 4、RAID 5及RAID 6則是採用獨立存取模式。
- 平行存取模式
並行存取模式支援裡,是把所有磁碟驅動器的主軸馬達作精密的控制,使每個磁碟的位置都彼此同步,然後對每一個磁碟驅動器作一個很短的I/O資料傳送,如此一來,從主機來的每一個I/O 指令,都平均分佈到每一個磁碟驅動器。
為了達到並行存取的功能,RAID 中的每一個磁碟驅動器,都必須具備幾乎完全相同的規格:轉速必須一樣;磁頭搜尋速度﹝Access Time﹞必須相同;Buffer 或Cache的容量和存取速度要一致;CPU處理指令的速度要相同;I/O Channel 的速度也要一樣。總而言之,要利用並行存取模式,RAID 中所有的成員磁碟驅動器,應該使用同一廠牌,相同型號的磁碟驅動器。
並行存取的基本工作原理
假設RAID中共有四部相同規格的磁碟驅動器,分別為磁碟驅動器A、B、C和D,我們在把時間軸略分為T0、T1、T2、T3和T4:
T0: RAID控制器將第一筆資料傳送到A的Buffer,磁碟驅動器B、C和D的Buffer都是空的,在等待中
T1: RAID控制器將第二筆資料傳送到B的Buffer,A開始把Buffer中的資料寫入扇區,磁碟驅動器C和D的Buffer都是空的,在等待中
T2: RAID控制器將第三筆資料傳送到C的Buffer,B開始把Buffer中的資料寫入扇區,A已經完成寫入動作,磁碟驅動器D和A的Buffer都是空的,在等待中
T3: RAID控制器將第四筆資料傳送到D的Buffer,C開始把Buffer中的資料寫入扇區,B已經完成寫入動作,磁碟驅動器A和B的Buffer都是空的,在等待中
T4: RAID控制器將第五筆資料傳送到A的Buffer,D開始把Buffer中的資料寫入扇區,C已經完成寫入動作,磁碟驅動器B和C的Buffer都是空的,在等待中
如此一直迴圈,一直到把從主機來的這個I/O 指令處理完畢,RAID控制器才會受處理下一個I/O 指令。重點是在任何一個磁碟驅動器準備好把資料寫入扇區時,該目的扇區必須剛剛好轉到磁頭下。同時RAID控制器每依次傳給一個磁碟驅動器的資料長度,也 必須剛剛好,配合磁碟驅動器的轉速,否則一旦發生 miss,RAID 效能就大打折扣。
並行存取RAID的最佳應用
並行存取RAID之架構,以其精細的馬達控制和分佈之資料傳輸,將陣列中每一個磁碟驅動器的效能發揮到最大,同時充分利用Storage Bus的頻寬,因此特別適合應用在大型、資料連續的檔案存取應用,例如:
影像、視訊檔案伺服器
資料倉儲系統
多媒體資料庫
電子圖書館
印前或底片輸出檔案伺服器
其它大型且連續性檔案伺服器
由於並行存取RAID架構之特性,RAID 控制器一次只能處理一個I/O要求,無法執行Overlapping 的多工,因此非常不適合應用在 I/O次數頻繁、資料隨機存取、每筆資料傳輸量小的環境。同時,因為並行存取無法執行Overlapping 的多工,因此沒有辦法”隱藏”磁碟驅動器搜尋﹝seek﹞的時間,而且在每一個I/O的第一筆資料傳輸,都要等待第一個磁碟驅動器旋轉延遲 ﹝rotational latency﹞,平均為旋轉半圈的時間,如果使用一萬轉的磁碟驅動器,平均就需要等待50 usec。所以機械延遲時間,是並行存取架構的最大問題。
- 獨立存取模式
相對於並行存取模式,獨立存取模式並不對成員磁碟驅動器作同步轉動控制,其對每個磁碟驅動器的存取,都是獨立且沒有順序和時間間格的限制,同時每筆傳輸的 資料量都比較大。因此,獨立存取模式可以儘量地利用overlapping 多工、Tagged Command Queuing等等高階功能,來” 隱藏”上述磁碟驅動器的機械時間延遲﹝Seek 和Rotational Latency﹞。
由於獨立存取模式可以做overlapping 多工,而且可以同時處理來自多個主機不同的I/O Requests,在多主機環境﹝如Clustering﹞,更可發揮最大的效能。
獨立存取RAID的最佳應用
由於獨立存取模式可以同時接受多個I/O Requests,因此特別適合應用在資料存取頻繁、每筆資料量較小的系統。例如:
線上交易系統或電子商務應用
多使用者資料庫
ERM及MRP 系統
小檔案之檔案伺服器
二.LVM
1.LVM簡介
是邏輯卷管理(LogicalVolumeManager)的簡稱,它是Linux環境下對磁碟分割槽進行管理的一種機制,LVM是建立在硬碟和分割槽之上的一個邏輯層,來提高磁碟分割槽管理的靈活性。通過LVM系統管理員可以輕鬆管理磁碟分割槽,如:將若干個磁碟分割槽連線為一個整塊的卷組 (volumegroup),形成一個儲存池。管理員可以在卷組上隨意建立邏輯卷組(logicalvolumes),並進一步在邏輯卷組上建立檔案系統。管理員通過LVM可以方便的調整儲存卷組的大小,並且可以對磁碟儲存按照組的方式進行命名、管理和分配,例如按照使用用途進行定義: “development”和“sales”,而不是使用物理磁碟名“sda”和“sdb”。而且當系統添加了新的磁碟,通過LVM管理員就不必將磁碟的檔案移動到新的磁碟上以充分利用新的儲存空間,而是直接擴充套件檔案系統跨越磁碟即可。
2.LVM原理
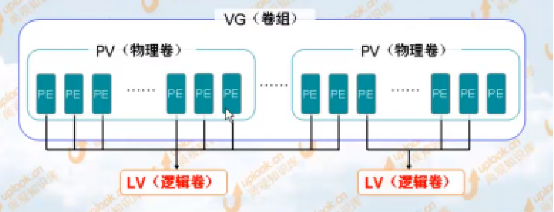
PV(Physical Volume,物理卷)
整個硬碟,或使用fdisk等工具建立的普通分割槽
包括許多預設4M大小的PE(Physical Extent,基本單元)
VG(Volume Group,卷組)
一個或多個物理卷組合而成的整體
LV(Logical Volume,邏輯卷)
從卷組中分割出的一塊空間,用於建立檔案系統
3.建立LVM邏輯卷的一般步驟
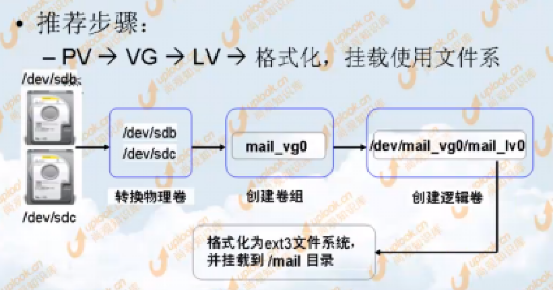
三.RAID和LVM共存時建立步驟
同時使用RAID和LVM既能保證資料的安全,又可以方便的管理儲存空間,這時應該先建立RAID,再建立LVM,因為一個是物理層面上的,一個是邏輯層面上的:
新新增n塊硬碟—->完成硬體檢測及分割槽—>建立RAID5—>在建立的RAID5上建立邏輯卷—>基於該邏輯卷建立EXT3檔案系統—>將新建的檔案系統掛載到指定目錄
PS:這裡只講了RAID和LVM的原理,具體如何建立會在下一篇文章講述Linux下RAID和LVM的建立
相關推薦
RAID陣列與LVM邏輯卷組原理
Raid陣列和lvm邏輯卷組主要用於磁碟備份和擴充套件,其中Raid用於磁碟備份,lvm用於磁碟空間管理。 一.Raid工作原理 1.什麼是Raid RAID(Redundant Array of Inexpensive Disks)稱為廉價磁碟冗餘陣
LVM邏輯卷管理--在線擴容、邏輯卷與卷組容量縮減、邏輯卷快照
劃分 分區信息 包括 管理 troy 系統 避免 理解 req LVM邏輯卷管理公司生產環境中使用了LVM邏輯卷管理,所以今天花時間整理一下。通過LVM技術整合所有的磁盤資源進行分區,然後創建PV物理卷形成一個資源池,再劃分卷組,最後在卷組上創建不同的邏輯卷,繼而初始化邏輯
LINUX的 LVM邏輯卷與管理交換空間
linux LVM邏輯卷 1.管理分散的空間。 2.邏輯卷動態的擴大與縮減。 首先將眾多的物理卷(pv)組成卷組(vg), 再從卷組中劃分出邏輯卷(lv)。 命令:crea
lvm邏輯卷的創建、擴展與刪除
vgdisplay 系統 play 邏輯卷的創建 bce png image 格式 技術分享 本機環境: 創建:a. 創建物理卷: pvcreate /dev/sdb{1,2,5} b. 創建卷組: vgcreate my_vg /dev/sdb1 /dev/sdb
Linux 磁盤管理 管理LVM邏輯卷 以及 RAID卷組成
陣列 wap 虛擬 中文 所在 進行 文件系統 安裝 添加 Linux 磁盤管理 管理LVM邏輯卷 以及 RAID卷組成 管理磁盤及分區 在Linux服務器中,當現有硬盤的分區規劃不能滿足要求(例如,根分區的剩余空間過少,無法繼續安裝新的系統程序)時,就需要對硬盤中的分區進
磁盤空間的擴展與減少------邏輯卷管理器 LVM
-a 硬盤 物理 roc ima centos linux tle bottom 一、基本理論知識 LVM是 Logical Volume Manager(邏輯卷管理)的簡寫,是Linux環境下對磁盤分區進行管理的一種機制。邏輯卷管理通過將底層物理硬盤抽象封裝起來,以
LVM邏輯卷建立與管理
lvm分割槽方式分為三部分組成 物理卷(PV) 建立物理卷 pvcreate +(已有的空白分割槽) [[email protected] dev]# pvs(顯示已經建立的物理卷) PV VG Fmt Attr PSize PFree /dev/sda2 centos lvm
LVM 邏輯卷建立與管理
LVM ( Logical Volume Manager ) 是基於核心的一種邏輯卷管理器,允許使用者動態調整檔案系統大小,可以利用快照功能備份資料。 LVM分為:物理卷 卷組 邏輯卷 物理卷:(PV)是LVM最底層概念,和磁碟份區是對應的關係(一個分割槽對應一
LVM邏輯卷、卷組的新建及調整
LVM邏輯卷 練習:關閉虛擬機器,新增一場80G 的硬碟,劃分3個主分割槽,1個擴充套件分割槽,3個邏輯分割槽,每個分割槽10G 傳統分割槽的侷限性:1)分割槽容量調整不方便 2)單個分割槽的總大小有限 LVM邏輯卷(Logica
linux系統中lvm(邏輯卷組)的管理
一.限額的介紹與設定 限額表示對數額的限定,在linux系統中我們可以設定擷取磁碟大小的額度。 限額是針對於裝置的,而不是針對使用者的(我們可以舉例:螞蟻花唄的額度是針對軟體本身的,而不是針對每個使用者的)1.設定配額 (1)mount -o u
Linux LVM-刪除卷組邏輯卷物理卷
檢視卷組相關資訊 [[email protected] /]# vgscan Reading all physical volumes. This may take a while... Found volume group "VolGr
LVM邏輯卷管理
文件系統管理 物理卷 動態分區 邏輯卷擴展 楊書凡 LVM概述LVM是邏輯盤卷管理(Logical Volume Manager)的簡稱,它是Linux環境下對磁盤分區進行管理的一種機制,LVM是建立在硬盤和分區之上的一個邏輯層,來提高磁盤分區管理的靈活性。LVM的工作原理其實很簡單,它就
LVM邏輯卷
linux 邏輯卷 lvm 邏輯卷LVM小實驗LVM全名是 Logical Volume Manager,中文翻譯作逡輯滾動條管理員,我還是喜歡叫邏輯卷。簡單好記QWQ邏輯卷裏面有幾個名詞需要介紹一下!1.PhysicalVolume,實體滾動條,簡稱PV。2.Physical Extend,實體
LVM邏輯卷-創建、擴容、縮減、遷移、快照
網絡 linux LVM邏輯卷邏輯卷管理工具,允許在多個物理設備之間重新組織文件系統,包括重新設定文件系統的大小PE 物理盤區,類似於磁盤中的block邏輯卷的基本存儲單位就是PEdm:device mapper將一個或多個底層塊設備組織成一個邏輯設備的模塊設備名:/dev/dm-# //系統自動
Linux常用命令(八)LVM邏輯卷管理
侯良金 linux lvm 邏輯卷 動態擴容 Linux常用命令(八)LVM邏輯卷管理一、LVM概述 LVM是Linux系統中對磁盤分區進行管理的一種邏輯機制,它是建立在硬盤和分區之上,文件系統之下的一個邏輯層,在建立文件系統時屏蔽了下層的磁盤分區布局,能夠在保持現有數據不變
Linux LVM 邏輯卷的使用,擴容,刪除 -- 將多塊硬盤組合一起使用
linux lvm 邏輯卷的使用 擴容 刪除 -- 將多塊硬盤組合一起使用 1,創建邏輯卷 查看物理磁盤: [root@localhost ~]# parted -l | grep ‘Disk /dev/s‘ #如果分區表是GPT [root@localhost ~]# fdisk -l | gr
Linux運維之道之admin1.5(分區規劃及使用,lvm邏輯卷,交換空間)
linux 達內 雲計算 admin1.5分區規劃及使用:硬盤分區管理:使用fdisk分區工具:查看分區列表:--fdisk -l /dev/sda修改硬盤的分區表:--fdisk /dev/vdb常用交互命令:-m:列出指令幫助;-p:查看現有分區表;-n:新建分區;-d:刪除分區;-q:放
No.26 LVM邏輯卷管理
linux 運維 lvm 邏輯卷整合小容量磁盤和實現分區的動態伸縮。boot用來存放引導文件,不要基於LVM創建,開機的過程中不識別邏輯卷。PV(Physical Volume,物理卷):物理分區,或整個物理磁盤,由PE(Physical Extent,基本單元)組成。VG(Volume Group,卷組):
lvm邏輯卷的基本應用,擴展及縮減、快照功能實現方法
mapper tcl 磁盤擴容 align fsck 縮減 mark 替換 1.5 lvm:邏輯卷管理 作用:將多個物理磁盤組合成一個邏輯磁盤,使其擁有更大的磁盤空間邏輯磁盤結構如下:一、下面一Centos6 為例來創建 lvm,首先在虛擬機上添加3塊硬盤,大小自定。1、f
Linux-LVM邏輯卷
vgdisplay 表現 大小 空間 pvdisplay creat vgcreate vdi 調整 LVM邏輯卷管理通過將底層物理硬盤抽象封裝起來,以邏輯卷的形式表現給上層系統,邏輯卷的大小可以動態調整,而且不會丟失數據。新加入的硬盤也不會改變現有上層的邏輯卷。 PE:物