
hive 3.x 特性更改
Apache Hive 3.x 架構介紹
hive 的更新操作一直是大資料倉庫頭痛的問題,在3.x之前也支援update,但是速度太慢,還需要進行分桶,現在hive 支援全新ACID,並且底層採用TEZ 和記憶體進行查詢,效能是hive2的50倍。生產建議升級到hive3.1.1版本。
瞭解Apache Hive 3主要的設計更改,例如預設的ACID事務處理和僅支援瘦配置客戶端,可以幫助您使用新功能來滿足企業資料倉庫系統不斷增長的需求。
1.執行引擎更改
Apache Tez將MapReduce替換為預設的Hive執行引擎。不再支援MapReduce
Hive編譯查詢。
Tez執行查詢。
YARN為群集中的應用程式分配資源,併為YARN佇列中的Hive作業啟用授權。
Hive根據表型別更新HDFS或Hive倉庫中的資料。
Hive通過JDBC連線返回查詢結果。該過程的簡化檢視如下圖所示: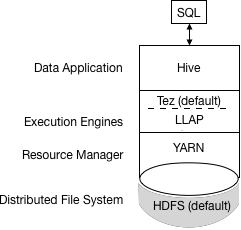
如果舊指令碼或應用程式指定MapReduce執行,則會發生異常。您可以設定一個選項以靜默忽略MapReduce設定。
大多數使用者定義的函式(UDF)不需要在Tez而不是MapReduce上執行更改
2.設計影響安全性的更改
以下Hive 3體系結構更改提供了更高的安全性:
2.1緊密控制的檔案系統和計算機記憶體資源,取代靈活的邊界:確定的邊界提高了可預測性。更強大的檔案系統控制可提高安
共享檔案和YARN容器中的優化工作負載
2.2預設情況下,HDP 3.0 Ambari安裝添加了Apache Ranger安全服務。Hive的主要授權模型是Ranger。此模型僅允許Hive訪問HDFS。Hive強制執行Ranger中指定的訪問控制。此模型提供比其他安全方案更強的安全性以及更靈活的策略管理。
如果您未啟用Ranger安全服務或其他安全性,則預設情況下Hive使用基於使用者模擬的基於儲存的授權(SBA)。
3.HDFS許可權更改
在HDP 3.0中,SBA在很大程度上依賴於HDFS訪問控制列表(ACL)。ACL是HDFS中許可權系統的擴充套件。HDP 3.0預設開啟HDFS中的ACL,為您提供以下優勢:
在為多個組和使用者提供特定許可權時,可以提高靈活性
方便地將許可權應用於目錄樹而不是單個檔案
4.交易處理變更
您可以通過利用事務處理中的以下改進來部署新的Hive應用程式型別:
4.1成熟版本的ACID事務處理和LLAP:
ACID表是HDP 3.0中的預設表型別。
預設情況下啟用ACID不會導致效能或操作過載。
4.2簡化的應用程式開發,具有更強事務保證的操作,以及更簡單的SQL命令語義
您不需要在HDP 3.0中儲存ACID表,因此維護更容易。
5.其他特性修改
物化檢視重寫
自動查詢快取
6.高階優化
6.1Hive客戶端更改
Hive 3僅支援瘦客戶端Beeline,用於從命令列執行查詢和Hive管理命令。Beeline使用與HiveServer的JDBC連線來執行所有命令。在HiveServer中進行解析,編譯和執行操作。Beeline支援與Hive CLI相同的命令列選項,但有一個例外:Hive Metastore配置更改。
您可以通過使用hive 關鍵字,命令選項和命令呼叫Beeline來輸入支援的Hive CLI命令。例如,hive -e set。使用Beeline而不是不再支援的胖客戶端Hive CLI有幾個優點,包括:
您現在只維護JDBC客戶端,而不是維護整個Hive程式碼庫。
使用Beeline可以降低啟動開銷,因為不涉及整個Hive程式碼庫。
瘦客戶端體系結構有助於以這些方式保護資料:
會話狀態,內部資料結構,密碼等駐留在客戶端而不是伺服器上。
執行查詢所需的少量守護程序簡化了監視和除錯。
HiveServer強制執行您可以使用SET命令更改的白名單和黑名單設定。使用黑名單,您可以限制記憶體配置以防止HiveServer不穩定。您可以使用不同的白名單和黑名單配置多個HiveServer例項,以建立不同級別的穩定性。
6.2Hive客戶端的更改要求您使用grunt命令列來使用Apache Pig。
6.3pache Hive Metastore發生了變化
HiveServer現在使用遠端而不是嵌入式Metastore; 因此,Ambari不再使用hive.metastore.uris=' '.您不再key=value在命令列上設定 命令來配置Hive Metastore來啟動Metastore。您可以在hive-site.xml中配置屬性。Hive目錄位於Hive Metastore中,它與早期版本中的RDBMS一樣。使用此體系結構,Hive可以利用雲部署中的RDBMS資源。
7.Spark目錄更改
Spark和Hive現在使用獨立的目錄來訪問相同或不同平臺上的SparkSQL或Hive表。Spark建立的表駐留在Spark目錄中。Hive建立的表位於Hive目錄中。雖然是獨立的,但這些表互操作。
您可以使用HiveWarehouseConnector從Spark訪問ACID和外部表。
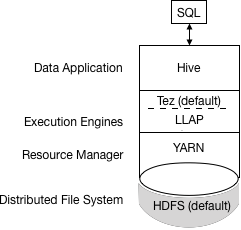
查詢批處理和互動式工作負載的執行
下圖顯示了批處理和互動式工作負載的HDP 3.0查詢執行體系結構:
您可以使用JDBC命令列工具(如Beeline)或使用帶有BI工具(如Tableau)的JDBC / ODBC驅動程式連線到Hive。客戶端與同一HiveServer版本的例項進行通訊。您可以為每個例項配置設定檔案,以執行批處理或互動式處理。
原文連結:https://smileyboy2009.iteye.com/blog/2433512
官方網站:http://hive.apache.org/downloads.html
hive文件:https://cwiki.apache.org/confluence/display/Hive/Home#Home-GeneralInformationaboutHive
spark官網:http://spark.apache.org/