
佇列的順序儲存與鏈式儲存
佇列就是我們日常生活中的排隊,佇列也是一種線性表,與堆疊相反,佇列的入列必須在隊尾,出列必須在隊頭。與一般的線性表不同,佇列的操作只能在兩端,一端插入一端刪除,先進先出。(堆疊只能在一端進行操作,所以先進後出)。
佇列的儲存方式這裡講兩種,首先第一種是用陣列的方式實現佇列的順序儲存。用一個一維陣列來儲存佇列的資料,對佇列執行操作時,插入和刪除分別是對陣列頭和陣列尾進行操作,所以還要有兩個變數來指示陣列的頭和尾。所以佇列的結構可以這樣定義:
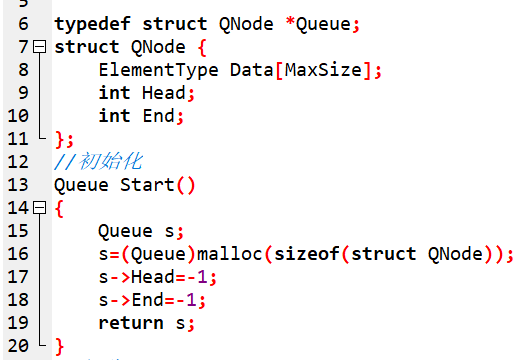
結構體裡定義一個一維陣列Data[ ]和兩個變數Head和End,Head和End分別表示陣列頭下標和陣列尾的下標。初始化佇列時,一開始陣列是空的,Head和End
佇列的順序儲存方式思路是這樣的:首先第一個資料讀進來後,End加1,再讀入資料就繼續往後加,End一直表示的是陣列中最後一個數據的下標。而當佇列中刪除一個元素時,Head就加1,Head指向的位置有點不同,一開始陣列中加入元素後,第一個資料的下標是0,但Head還是-1,所以其實往後操作時,Head指向的一直都是第一個資料的下標的前一位。
在佇列的不斷操作中(插入和刪除)後因為陣列的原因,我們會遇到下面這種情況,從而出現兩個問題:
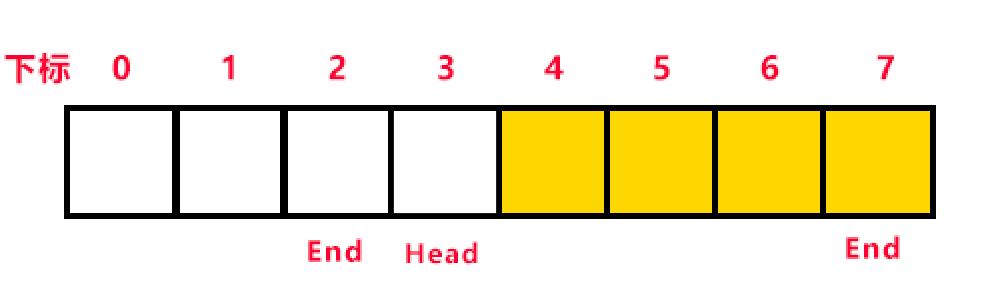
第一個問題:假設有一個能存放8個元素的陣列,陣列的最後一個位置被存放資料了,這時如果我們再要讀入資料,是可以的,因為陣列的前面有空位置可以存放,
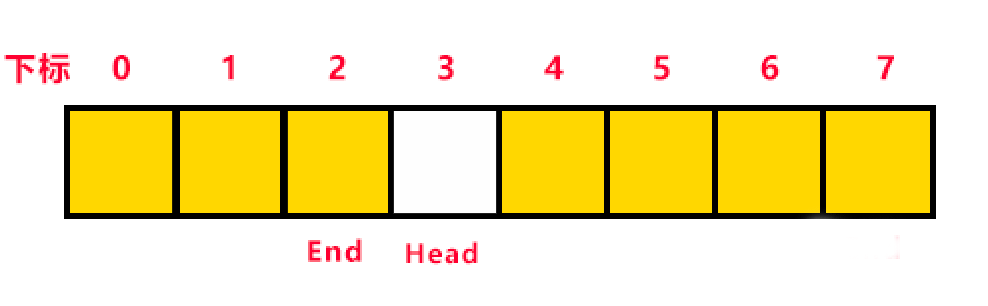
第二個問題:當陣列的所有位置都使用過一遍後,又從頭開始存放資料時(此時End在前了,Head反而在後),如果此時再存入一個數據,End就和Head相等了,這會出現什麼問題?一開始陣列初始化時,Head和End都是等於-1,Head和End相等時我們會把它當作是佇列為空的情況的條件。在陣列被使用完一輪後,從頭開始存放資料時,End陣列尾變成了陣列頭,追上了Head,再回去看一下上圖,當End再加1後,End與Head又相等了,但它們都不會等於-1。那麼當End和Head相等時,我們怎麼知道佇列是空的還是滿的?
第一個問題先留著(記住!!),先看看第二個問題如何解決?其實解決方法有很多,比如:
1、定義一個變數count來記錄當前資料的個數,存入資料時,count就加一,刪除資料時,count就減一,然後根據count的值如果為0就表示佇列空,如果等於陣列的大小減一就表示佇列滿。(當Head和End相等時,你就去檢視這個count,根據count的大小來判斷佇列的空還是滿。)
2、定義一個變數tag,一開始初始化為0。當存入一個數據時,tag的值變為1;當刪除一個數據時,tag的值變為0;最後根據tag是1還是0來判斷佇列是空還是滿。(當Head和End相等時,就去檢視tag,因為只有插入操作時tag才會等於1,如果做到Head等於End這一步時是插入操作,那麼佇列就是滿了。相反同理,如果Head等於End這一步是刪除操作後得到的,那麼佇列就是空了。)
3、第三個方法比較推薦,就是對於大小為n的陣列,我們不把它使用滿,而是使用n-1就夠了。這種方法Head和End相等就只會出現在一開始佇列空的時候了。
下面來展開第三種方法的實現,就是佇列只使用n-1的陣列空間。佇列的結構體和初始化還是一樣的,我們先來看下入佇列的操作:

第24行的註釋裡說明了為什麼第25行要用取餘的方式,為了解決上面提到的第一個問題,“陣列的位置被使用完一輪後,如何讓End從陣列尾過渡回到陣列頭?”,我們再看一下這副圖
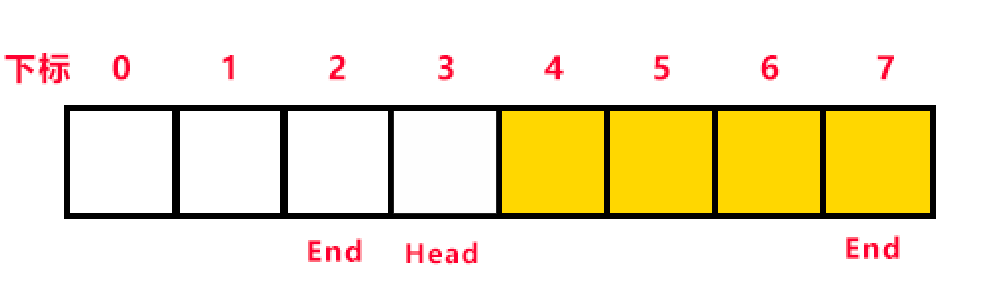
陣列的大小MaxSize等於8,End指向了最後一個數據的下標等於7,當(End+1)%MaxSize後,End就等於0了。這樣就可以讓End從陣列尾過渡到陣列頭了,同時也可以作為判斷佇列是否滿的條件。(因為使用陣列的n-1個空間,End與Head在佇列滿時會相差1,所以當(End+1)%MaxSize等於Head時,就說明佇列滿了。)。判斷完特殊情況後,就開始插入資料,如果陣列沒滿,我們就把End加一(第29行),然後把資料插入相應的陣列位置裡。
接著到出佇列,很簡單就和入佇列差不多,只不過是對Head操作:
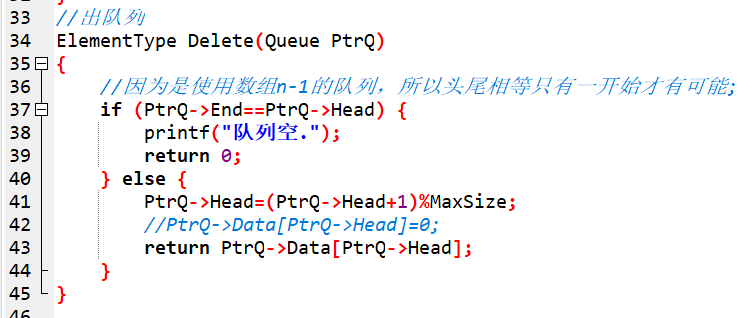
第37行一開始還是特殊情況的判斷,判斷佇列是否為空,這時判斷Head和End是否相等就可以了。如果佇列不為空,就讓Head加一,然後返回相應的陣列位置的元素。
上面講完第一種方式用一維陣列來順序儲存佇列,接下來看第二種:佇列的鏈式儲存,就是用線性表的方式了。
先來看下每個資料的資料結構:
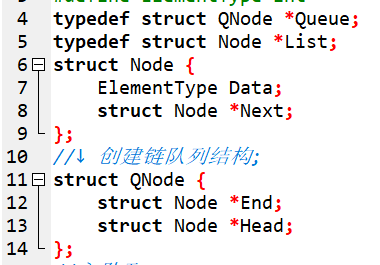
結點的每個區塊都有一個Data資料,和一個Next指標來和其他區塊串聯起來。接著再定義一個結構,裡面兩個Node型的指標,Head和End分別指向線性表的頭結點和尾結點。
接下來看入佇列的操作:
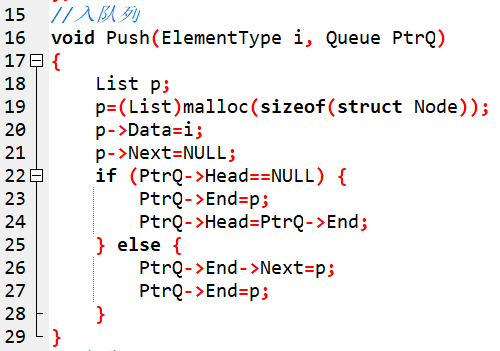
第22行,佇列一開始是空的,所以Head等於NULL,讓PtrQ->End指向第一個資料區塊,然後讓Head指向End,連結起來。第一次資料儲存完後,下一次就直接操作End就可以了,就跟普通連結串列儲存資料一樣的操作。
接著到出佇列:
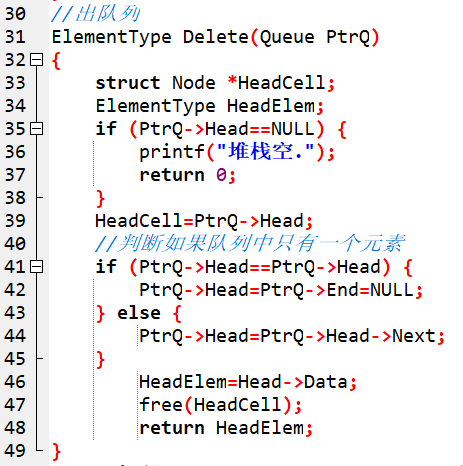
因為出列就是要把那個資料區塊free掉,所以先定義一個指標HeadCell,指向要刪除的那個Head(第39行)。接著再做一個特殊情況的判斷:(第41行)如果佇列中只有一個數據,當你free掉之後,也就是刪除掉資料之後,佇列應該要為空了,但此時End仍然指向那個資料塊,所以其實並沒有刪除掉。當佇列只有一個數據塊時,我們要把Head和End都指向NULL,最後再free掉HeadCell。如果佇列中不止一個元素,那麼就讓PtrQ->Head=PtrQ->Head->Next,然後把Head->的資料Data儲存起來做return,最後free掉HeadCell就可以了。
相關推薦
佇列的順序儲存與鏈式儲存
佇列就是我們日常生活中的排隊,佇列也是一種線性表,與堆疊相反,佇列的入列必須在隊尾,出列必須在隊頭。與一般的線性表不同,佇列的操作只能在兩端,一端插入一端刪除,先進先出。(堆疊只能在一端進行操作,所以先進後出)。佇列的儲存方式這裡講兩種,首先第一種是用陣列的方式實現佇列的順序
順序儲存與鏈式儲存的集合-HashMap、HashTable
HashMap,日常最常用的資料結構之一。它是基於雜湊表的 Map 介面的實現,以key-value的形式存在。在HashMap中,key-value總是會當做一個整體來處理,系統會根據hash演算法
順序儲存結構與鏈式儲存結構的比較(也可以說的順序表與連結串列的比較)
1、鏈式儲存結構的儲存空間在邏輯上是連續的,但是在物理上是離散的;而順序儲存結構的儲存空間在邏輯上是連續的,在物理上也是連續的。 2、鏈式儲存儲存密度小,但空間利用率較高;順序儲存儲存密度大,但空間利用率較低。 3、順序結構優點是可以隨機讀取元素,缺點是插入和刪除元素要移動大量元素,
資料結構與演算法(二)-線性表之單鏈表順序儲存和鏈式儲存
前言:前面已經介紹過資料結構和演算法的基本概念,下面就開始總結一下資料結構中邏輯結構下的分支——線性結構線性表 一、簡介 1、線性表定義 線性表(List):由零個或多個數據元素組成的有限序列; 這裡有需要注意的幾個關鍵地方: 1.首先他是一個序列,也就是說元素之間是有個先來後到的。
佇列的順序儲存和鏈式儲存
佇列的基本概念 1.定義:佇列是隻允許在一端進行插入操作,而在另一端進行刪除操作的線性表。 2.佇列是一種先進先出的線性表,簡稱FIFO。允許插入的一端稱為隊尾,允許刪除的一端稱為隊頭。front指標指向對頭元素,rear指標指向隊尾的下一個位置。當fron
線性表、棧、佇列的的順序儲存和鏈式儲存
先概括一下線性表順序儲存和鏈式儲存。 線性表的順序儲存是用一組地址連續的儲存單元依次儲存線性表的資料元素。 線性表的鏈式儲存是用指標將儲存線性表中的資料元素的那些單元依次串聯在一起。 接下來圖片說明。
資料結構與演算法(C語言) | 線性表(順序儲存、鏈式儲存)
線性表是最常用最簡單的線性結構 線性結構具有以下基本特徵: 線性結構是一個數據元素的有序(次序)集(處理元素有限)。若該集合非空,則 1)必存在唯一的一個“第一元素”; 2)必存在唯一的一個“最後元素”; 3)除第一元素之外,其餘每個元素均有唯一的前
線性表的順序儲存和鏈式儲存差異
線性表的順序儲存和鏈式儲存方式在存讀資料以及插入刪除資料時,時間複雜度不同。順序儲存的典型例子為陣列,鏈式儲存的典型例子為單鏈表。眾所周知,當讀取資料較為頻繁時,我們選擇順序儲存方式,當插入和刪除操作較為頻繁時,我們選擇鏈式儲存方式。接下來,我們將分析這樣做的原因:1.順序儲
【資料結構】二叉樹(順序儲存、鏈式儲存)的JAVA程式碼實現
二叉樹是一種非線性的資料結構。它是由n個有限元素的集合,該集合或者為空、或者由一個稱為根(root)的元素及兩顆不相交的、被分別稱為左子樹、右子樹的二叉樹組成。當集合為空時,稱該二叉樹為空二叉樹。在二叉樹中,一個元素也可以稱做一個結點。二叉樹是有序的,即若將其左右兩個子樹顛倒
資料結構 線性表中,順序儲存和鏈式儲存的優缺點
簡單對順序儲存和鏈式儲存結構做對比: 儲存分配方式; 順序儲存用一段連續的儲存單元一次儲存線性表的資料元素。 鏈式儲存採用鏈式儲存結構,用一組任意的儲存單元存放線性表的元素。時間複雜度衡量;
(轉載)列式儲存與行式儲存
1 為什麼要按列儲存 列式儲存(Columnar or column-based)是相對於傳統關係型資料庫的行式儲存(Row-basedstorage)來說的。簡單來說兩者的區別就是如何組織表(翻譯不好,直接抄原文了): Ø Row-based storage stor
順序棧與鏈式棧型別的定義
順序棧:#define StackSize 100/*假定預分配的棧的空間為100個元素*/typedef char DataType;/*假定棧元素的資料型別為字元*/typedef struct{ dataType data[StackSize];//定義棧陣列
棧與佇列-順序棧與鏈棧類模板的實現(資料結構基礎 第3周)
這是用C++編寫的棧的類模板的實現,包括順序棧和鏈棧,並進行了簡單的測試。 程式碼中srrStack類和lnkStack類均繼承於Stack類, Stack類可以看成是棧的邏輯結構(ADT抽象資料型別,Abstract Data Type)。注意這裡實現是棧與
順序棧與鏈式棧的實現
棧的概念: 棧(stack)又名堆疊,它是一種運算受限的線性表。其限制是僅允許在表的一端進行插入和刪除運算。這一端被稱為棧頂,相對地,把另一端稱為棧底。向一個棧插入新元素又稱作進棧、入棧或壓棧,它是把新元素放到棧頂元素的上面,使之成為新的棧頂元素;從一個棧刪除
順序棧與鏈式棧的圖解與實現
# 順序棧與鏈式棧的圖解與實現 - 棧是一種特殊的線性表,它與線性表的區別體現在增刪操作上 - 棧的特點是先進後出,後
佇列的鏈式儲存與順序儲存
佇列是一種先進先出的線性表,佇列也有兩種結構:順序儲存和鏈式儲存 一:佇列的鏈式儲存結構 為了實現鏈式儲存,就要設定結點資訊——元素和指向下一個結點的指標。為了實現佇列的先進先出(FIFO)的功能,就要有兩個指標指向開始和結尾,才能方便的進行插入和刪除。但是如何表示佇列
棧與佇列鏈式儲存結構一貨物上架問題
#include <iostream> #include<string.h> static int n; //用於輸入
資料結構棧和佇列(五)棧的順序儲存結構和鏈式儲存結構的實現
一、 實驗目的1. 熟悉棧的特點(先進後出)及棧的抽象類定義;2. 掌握棧的順序儲存結構和鏈式儲存結構的實現;3. 熟悉佇列的特點(先進先出)及佇列的抽象類定義;4. 掌握棧的順序儲存結構和鏈式儲存結構的實現;二、實驗要求1. 複習課本中有關棧和佇列的知識;2. 用C++語言
佇列的順序儲存結構和鏈式儲存結構
佇列(queue)是隻允許在一端進行插入操作,而在另一端進行刪除操作的線性表(在隊尾進行插入操作,在對頭進行刪除操作)。 與棧相反,佇列是一種先進先出(First In First Out, FIFO
《大話資料結構5》—— 佇列的鏈式儲存結構 —— C++程式碼實現
目錄 鏈佇列 迴圈佇列和鏈式佇列的比較 鏈佇列 ● 實現佇列的最好的方式就是使用單鏈表來實現,佇列的鏈式儲存結構,其實就是線性表的單鏈表,只不過它只能尾進頭出而已——稱為鏈佇列。 ● 那為了操作方便,頭指標指向頭結點,隊尾指標指向終端節點,即最後一個結點元