
redis、memcache實際應用中的快取作用
有人說網際網路使用者是用腳投票的,這句話其實也從側面說明了,使用者體驗是多麼的重要;這就要求在軟體架構設計時,不但要注重可靠性、安全性、可擴充套件性以及可維護性等等的一些指標,更要注重使用者的體驗,使用者體驗分很多方面,但是有一點非常重要就是對使用者操作的響應一定要快;怎樣提高使用者訪問的響應速度,這就是擺在架構設計中必須要解決的問題;說道提高服務的響應速度就不得不說快取了;
從系統的層面說,CPU的速度遠遠高於磁碟IO的速度;所以要想提高響應速度,必須減少磁碟IO的操作,但是有很多資訊又是存在資料庫當中的,每次查詢資料庫就是一次IO操作;比如查詢使用者資訊的例子,通常如下圖:
請求響應時間等於網路響應時間和伺服器響應時間;網路我們控制不了,伺服器響應時間包括CPU計算時間和磁碟IO時間,其中CPU計算時間這個有硬體資源決定的,我們儘量減少演算法的複雜度來減少它,磁碟IO時間,這個時間是非常慢的,應該儘量減少;
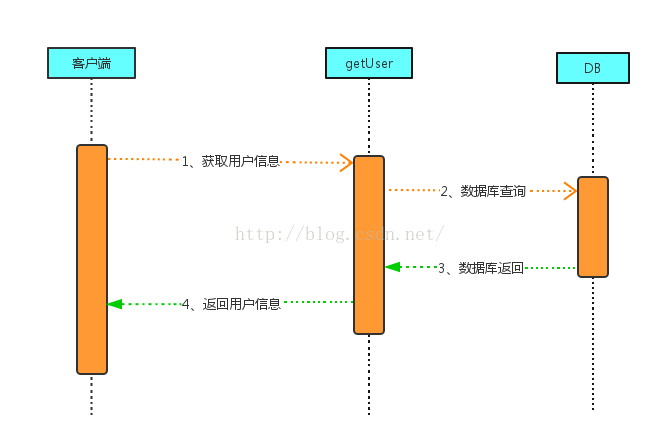
當客戶端呼叫getUser介面的查詢使用者資訊的時候,執行順序1、2、3、4;由於使用者資訊存放在DB中,所以2、3就有一次磁碟IO;這個看似非常簡單業務邏輯,但是當你做架構設計的時候往往要考慮最壞的場景,或者當成千上萬的使用者頻繁的呼叫這個介面應該怎麼處理?如果按照上圖這樣的架構處理,這個看似簡單業務的介面會使整個系統變慢,這樣使用者的請求就會長時間得不到響應;這樣的問題怎麼解決那,這時候就該快取登場了;
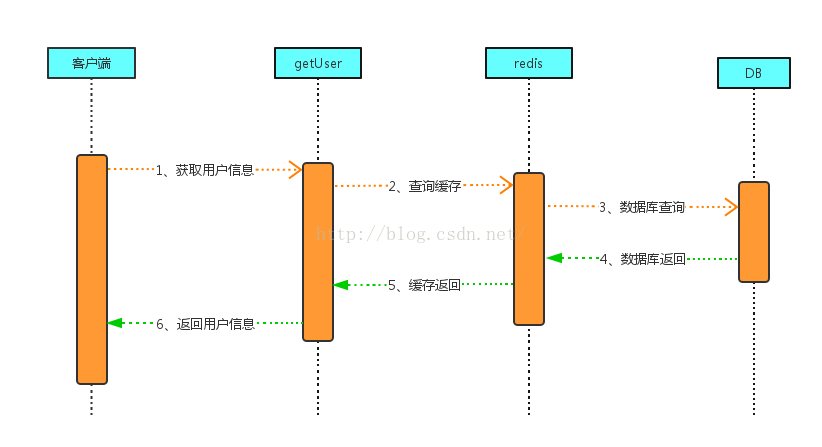
談到快取有幾種形式,其中最簡單的是在每個程序中開闢一塊記憶體,存放快取的資訊,每次先從記憶體查… … 但是在一個分散式或者叢集的環境中,getUser的介面可能會部署多套,每個程序的的記憶體是不能共享、相互獨立的,這就悲劇了;還有一種使用一個第三方的快取也叫公共快取(比如redis、memcache等);不論部署多少個包含getUser介面的服務,都去訪問同一套快取,那結果就不一樣了,看一下下面這幅圖:
當用客戶端呼叫getUser介面查詢使用者資訊的時候,getUser介面直接去redis中查詢,如果redis中有該使用者資訊,直接返回,避免查詢DB,從而避免了磁碟IO操作;如果redis中沒有該使用者資訊,則從DB查詢,並且把該使用者資訊存放到redis中;這樣在服務介面(getUser)和DB中間,增加了一個快取層;看似邏輯增加了,其實當面對高併發的時候,比如上邊提到的頻繁查詢使用者資訊的情況,只有第一次查詢有磁碟IO操作,以後只要redis中存在就沒必要再查詢資料庫了;由於沒有了磁碟IO操作,並且redis所有資料都在記憶體操作,所以速度回大大提升;
我們上面用到的快取是redis,其實常用的還有memcache等,它們都提供了叢集模式,並且都是直接記憶體操作,所以速度特別快,也是目前業內使用的比較熱門的技術;redis相對於memcache提供了更豐富的資料型別,根據不同的業務場景可以選在不同的資料型別;redis本身也提供了主從模式、叢集模式;也有第三方的比如codis提供了redis叢集解決方案;這次咱們主要聊快取在架構設計中的作用,等有機會詳細介紹redis的使用;
總之一句話,要想提高系統的效能,儘量減少IO的操作,特別是磁碟IO的操作;使用快取可以有效的避免這種情況;所以在架構設計過程中,社交到查詢資料庫的時候,應該考慮一下是不是考慮使用快取技術來提高系統的效能,並且降低資料庫的負載。
轉載於:http://blog.csdn.net/weis_2007/article/details/50678281