
利用mySql處理資料——把資料按照指定時間間隔匯出
任務:將近10天的溫度資料,9個溫度測點,取樣間隔為1分鐘,共計12萬行資料,需要匯出每小時的溫度資料。
0. 資料格式和資料庫設計
資料格式如下:有3列,分別是日期,時間,溫度。檔名是測點編號。
資料庫設計為如下:
create database sensorDB;
use sensorDB;
create table sensor
(
ID smallint ,
dt Date,
tm Time,
temp float,
primary key (ID,dt,tm)
);並且建立一個檢視把dt和tm兩個欄位合併
create view temperature as select ID, cast(CONCAT(dt,' ',tm) as datetime) '時間' , temp from sensor ;
1.Txt格式檔案匯入資料庫
用C語言寫了一個小工具,可以把txt轉成sql語句【見後面的原始碼】
執行後,輸入txt的檔名,要插入的表名,和感測器的編號即可。
程式執行完畢之後,自動生成sql語句如下:
然後直接執行sql語句,資料就匯入到資料庫中了。
2.按指定間隔查詢資料
利用了timestampdiff()來計算時間間隔 ,並利用%來逐個判斷
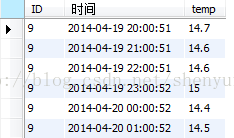
</pre><p></p></blockquote><blockquote style="margin:0 0 0 40px; border:none; padding:0px"><p><span style="font-size:24px"></span></p><pre code_snippet_id="531991" snippet_file_name="blog_20141125_4_1936774" name="code" class="sql">select * from temperature where ID = 9 and timestampdiff(MINUTE,時間,'2014-04-19 15:00:00')%60 =0;如下便是間隔1小時的溫度資料
附件:txt轉sql原始碼 C
#include<stdlib.h> #include<stdio.h> #include<string.h> #define BUFFER_LEN 2048 const char sp[] = { ' ', '\t', ';','\r','\n' }; void error(char *msg) { printf("ERROR:%s",msg); fflush(stdin); getchar(); exit(1); } int isSeperator(char ch) { for (int i = 0; i < sizeof(sp) / sizeof(char); i++) { if ( ch == sp[i]) { return 1; } } return 0; } int main() { printf("=============================\n"); printf(" txt2sql\n"); printf("=============================\n"); printf("data fielname: "); fflush(stdin); char filename_in[256], filename_out[256]; scanf("%s",filename_in); strcpy(filename_out, filename_in); strcat(filename_out, "_sql.txt"); strcat(filename_in, ".txt"); printf("table name: "); fflush(stdin); char table_name[256]; scanf("%s", table_name); printf("sensor ID: "); fflush(stdin); char sensor_ID[256]; scanf("%s", sensor_ID); FILE *fin = fopen(filename_in, "r"); FILE *fout = fopen(filename_out, "w"); if (fin == NULL || fout == NULL) { error("cannot open file"); } char buffer[BUFFER_LEN]; while (fgets(buffer, BUFFER_LEN, fin) != 0) { //除去多餘的分隔符 char elem[BUFFER_LEN]; int k = 0; memset(elem, 0, sizeof(elem)); for (int i = 0; i < strlen(buffer); i++) { if (buffer[i] == '\n' || buffer[i] == '\r' || buffer[i]=='\0') buffer[i] = ' '; } for (int i = 0; i < strlen(buffer); i++) { if (!isSeperator(buffer[i])) { elem[k++] = buffer[i]; } else { //如果最後一個是分隔符則跳過 if (i == strlen(buffer) && isSeperator(buffer[i])) continue; //如果下一個還是分隔符,則跳過。 if (i != strlen(buffer) - 1 && isSeperator(buffer[i + 1])) continue; if (i != strlen(buffer) - 1 && !isSeperator(buffer[i + 1])) elem[k++] = buffer[i]; } } /*printf("\"%s\"",elem);*/ //經過處理的elem只有包含一個分隔符在一起的情況,最後沒有空元素 fprintf(fout, "INSERT INTO %s VALUES ('%s',", table_name,sensor_ID); int left = 0; for (int i = 0; i < strlen(elem); i++) { if (isSeperator(elem[i])) { fprintf(fout, "\'"); for (int j = left; j < i; j++) { fprintf(fout, "%c", elem[j]); } fprintf(fout, "\',"); left = i + 1; } } //the last one fprintf(fout, "\'"); for (int j = left; j < strlen(elem); j++) { fprintf(fout, "%c", elem[j]); } fprintf(fout, "\');\n"); } fclose(fin); fclose(fout); printf("Done!"); fflush(stdin); getchar(); exit(0); }
相關推薦
利用mySql處理資料——把資料按照指定時間間隔匯出
任務:將近10天的溫度資料,9個溫度測點,取樣間隔為1分鐘,共計12萬行資料,需要匯出每小時的溫度資料。 0. 資料格式和資料庫設計 資料格式如下:有3列,分別是日期,時間,溫度。檔名是測點編號。 資料庫設計為如下: create database sensorDB;
利用linux處理網路流量資料
2009-01-15 # 周海漢/文 2009.1.15 ablozhou #gmail.com 網路壓力測試,需要處理原始資料,將原始的Byte/s 處理為Mbps,並通過直觀曲線圖表展示出來。 1.統計網絡卡流量
[MySQL] 利用 MySql日誌檔案 恢復資料
2. 要想通過日誌恢復資料庫,在你的my.cnf檔案裡應該有如下的定義,log-bin=mysql-bin,這個是必須的.binlog-do-db=db_test,這個是指定哪些資料庫需要日誌,如果有多個數據庫就每行一個,如果不指定的話預設就是所有資料庫. [mysqld] log-bin=mysql
利用柵格處理list集合資料,使每行顯示兩條或者多資料時候
這個是微信小程式的框架,TouchUI,做頁面查詢資料是list的物件,但是要用柵格每行顯示兩條資料 <ui-row wx:for="{{resumeCoverImg}}" wx:key="unique" class="resumeCoverImg">
批處理怎把資料夾內檔案移到上一層?
批處理把資料夾內的xml檔案移到上一層 for /f "tokens=* delims=" %%i in ('dir /b /a-d /s "*.xml"') do (move "%%i" "%%~dpi./../") pause
mysql處理百萬級資料
1、應儘量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 2、對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 3、應儘量避免在 where 子句中對欄位進行 null
利用MySQL WorkBench匯入csv資料
1、開啟MySQL WorkBench,新建一個Schema,如圖所示 2、在上圖中的Tables上右鍵,點選Table Data Import Wizard選項,進入如下所示對話方塊 3、選擇要匯入
mysql處理高併發資料,防止資料超讀
先來就庫存超賣的問題作描述:一般電子商務網站都會遇到如團購、秒殺、特價之類的活動,而這樣的活動有一個共同的特點就是訪問量激增、上千甚至上萬人搶購一個商品。然而,作為活動商品,庫存肯定是很有限的,如何控制庫存不讓出現超買,以防止造成不必要的損失是眾多電子商務網站程式設計師
如何優化Mysql千萬級快速分頁,limit優化快速分頁,MySQL處理千萬級資料查詢的優化方案!(zz)
MySQL資料庫優化處理實現千萬級快速分頁分析,來看下吧。 資料表 collect ( id, title ,info ,vtype) 就這4個欄位,其中 title 用定長,info 用text, id 是逐漸,vtype是tinyint,vtype是索引。這是一個基本的新聞系統的簡單模型。現在往裡面填
spring定時器按照指定時間進行執行
一般我們使用spring定時器的時候都是配置的固定時間在spring配置檔案中,如果我們有一個時間設定頁面,通過這個頁面設定定時器的執行時間,就可以達到動態執行的效果。 上程式碼: package com.test.action; import java.text.Par
C#使用Timer.Interval指定時間間隔與指定時間執行事件
https://www.cnblogs.com/wusir/p/3636149.html C#中,Timer是一個定時器,它可以按照指定的時間間隔或者指定的時間執行一個事件。 指定時間間隔是指按特定的時間間隔,如每1分鐘、每10分鐘、每1個小時等執行指定事件; 指定時間是指每小時的第30分、每天10:3
python 刪除指定時間間隔之前的檔案
遍歷指定資料夾下的檔案,根據檔案字尾名,獲取指定型別的檔案列表;根據檔案列表裡的檔案路徑,逐個獲取檔案屬性裡的“修改時間”,如果“修改時間”與“系統當前時間”差值大於某個值,則刪除該檔案。 #!/
利用Navicate把SQLServer轉MYSQL的方法(連資料)
本次轉換需要依賴使用工具Navicat Premium。 首先,將資料庫移至本地SQLServer,我試過直接在區域網上其他SQLServer伺服器上想轉到本地Mysql好像有問題,想將遠端資料庫備份恢復到本地。 1、開啟Navicat Premium,新建一個同名的資料庫,然後在表上點選“匯
如何利用mysql+pyecharts儲存資料並可視化
目標 爬取紅嶺創投(https://www.my089.com/)日投資發標記錄,儲存在mysql資料庫中, 並將資料視覺化以便分析. 行動 爬取資料 通過selenium+FIrefox的無頭模式將需要的資料爬取出來,程式碼實現不在贅述,詳細步驟可檢視我的上一篇圖文(如何
Mysql到Redis的資料協議(可以按照寫redis的協議,自測已經成功,key值可以自己變化,不一定非要是id)
redis-cli命令列工具有一個批量插入模式,是專門為批量執行命令設計的。這第一步就是把Mysql查詢的內容格式化成redis-cli可用的資料格式。 原理是把要插入到Redis的資料直接轉成Redis協議資料流,通過pipe mode 匯入到Redis. Redis協議: *<
用python批量獲取某路徑資料夾及子資料夾下的指定型別檔案,並按原資料夾結構批量儲存處理後的檔案
因為是把自己成功執行的整個程式碼按幾部分截取出來的,所以每一小節程式碼不一定能單獨執行,特此說明。 1.獲取某路徑資料夾及子資料夾下的指定pcm型別檔案的全部路徑 import os def eachfile(filepath): pathdi
[Pandas]利用Pandas處理excel資料
Python 處理excel的第三包有很多,比如XlsxWriter、xlrd&xlwt、OpenPyXL、Microsoft Excel API等,最後綜合考慮選用了Pandas。 Pandas 是基於NumPy 的一種工具,該工具是為了解決資料分析任務而建立的。Pandas 納入了大量
Python利用pandas處理Excel資料的應用
Python利用pandas處理Excel資料的應用 最近迷上了高效處理資料的pandas,其實這個是用來做資料分析的,如果你是做大資料分析和測試的,那麼這個是非常的有用的!!但是其實我們平時在做自動化測試的時候,如
吳裕雄 29-MySQL 處理重複資料
MySQL 處理重複資料有些 MySQL 資料表中可能存在重複的記錄,有些情況我們允許重複資料的存在,但有時候我們也需要刪除這些重複的資料。本章節我們將為大家介紹如何防止資料表出現重複資料及如何刪除資料表中的重複資料。 你可以在MySQL資料表中設定指定的欄位為 PRIMARY KEY(主鍵)或者 UNIQ
利用pandas的to_sql將資料插入MySQL資料庫和所踩過的坑
前言 最近做一個Django web的專案要把爬取的一些資料存入MySQL中,資料儲存為csv格式,想到pandas中有to_sql這個方法,就採用它了 準備:連線MySQL資料庫所需的第三方包pymysql、sqlalchemy(pip安裝即可) 實現 from sql