
各種GAN原理總結及對比
最近試著玩了多種GAN,今天我們主要總結下常用的GAN包括DCGAN,WGAN,WGAN-GP,LSGAN-BEGAN,SRGAN的詳細原理介紹以及他們對GAN的主要改進,並推薦了一些Github程式碼復現連結。
本文旨在對GAN的變種做一些梳理工作,詳細請看下文。
1.原始GAN
1.GAN的原理:
GAN的主要靈感來源於博弈論中零和博弈的思想,應用到深度學習神經網路上來說,就是通過生成網路G(Generator)和判別網路D(Discriminator)不斷博弈,進而使G學習到資料的分佈,如果用到圖片生成上,則訓練完成後,G可以從一段隨機數中生成逼真的影象。G, D的主要功能是:
● G是一個生成式的網路,它接收一個隨機的噪聲z(隨機數),通過這個噪聲生成影象
● D是一個判別網路,判別一張圖片是不是“真實的”。它的輸入引數是x,x代表一張圖片,輸出D(x)代表x為真實圖片的概率,如果為1,就代表100%是真實的圖片,而輸出為0,就代表不可能是真實的圖片
訓練過程中,生成網路G的目標就是儘量生成真實的圖片去欺騙判別網路D。而D的目標就是儘量辨別出G生成的假影象和真實的影象。這樣,G和D構成了一個動態的“博弈過程”,最終的平衡點即納什均衡點.
2. GAN的特點:
● 相比較傳統的模型,他存在兩個不同的網路,而不是單一的網路,並且訓練方式採用的是對抗訓練方式
● GAN中G的梯度更新資訊來自判別器D,而不是來自資料樣本
3. GAN 的優點:
(以下部分摘自ian goodfellow 在Quora的問答)
● GAN是一種生成式模型,相比較其他生成模型(玻爾茲曼機和GSNs)只用到了反向傳播,而不需要複雜的馬爾科夫鏈
● 相比其他所有模型, GAN可以產生更加清晰,真實的樣本
● GAN採用的是一種無監督的學習方式訓練,可以被廣泛用在無監督學習和半監督學習領域
● 相比於變分自編碼器, GANs沒有引入任何決定性偏置( deterministic bias),變分方法引入決定性偏置,因為他們優化對數似然的下界,而不是似然度本身,這看起來導致了VAEs生成的例項比GANs更模糊
● 相比VAE, GANs沒有變分下界,如果鑑別器訓練良好,那麼生成器可以完美的學習到訓練樣本的分佈.換句話說,GANs是漸進一致的,但是VAE是有偏差的
● GAN應用到一些場景上,比如圖片風格遷移,超解析度,影象補全,去噪,避免了損失函式設計的困難,不管三七二十一,只要有一個的基準,直接上判別器,剩下的就交給對抗訓練了。
4. GAN的缺點:
● 訓練GAN需要達到納什均衡,有時候可以用梯度下降法做到,有時候做不到.我們還沒有找到很好的達到納什均衡的方法,所以訓練GAN相比VAE或者PixelRNN是不穩定的,但我認為在實踐中它還是比訓練玻爾茲曼機穩定的多
● GAN不適合處理離散形式的資料,比如文字
● GAN存在訓練不穩定、梯度消失、模式崩潰的問題(目前已解決)
模式崩潰(model collapse)原因
一般出現在GAN訓練不穩定的時候,具體表現為生成出來的結果非常差,但是即使加長訓練時間後也無法得到很好的改善。
具體原因可以解釋如下:GAN採用的是對抗訓練的方式,G的梯度更新來自D,所以G生成的好不好,得看D怎麼說。具體就是G生成一個樣本,交給D去評判,D會輸出生成的假樣本是真樣本的概率(0-1),相當於告訴G生成的樣本有多大的真實性,G就會根據這個反饋不斷改善自己,提高D輸出的概率值。但是如果某一次G生成的樣本可能並不是很真實,但是D給出了正確的評價,或者是G生成的結果中一些特徵得到了D的認可,這時候G就會認為我輸出的正確的,那麼接下來我就這樣輸出肯定D還會給出比較高的評價,實際上G生成的並不怎麼樣,但是他們兩個就這樣自我欺騙下去了,導致最終生成結果缺失一些資訊,特徵不全。
關於梯度消失的問題可以參考鄭華濱的令人拍案叫絕的wassertein GAN,裡面給出了詳細的解釋,不過多重複。
區域性極小值點
原始GAN中判別器要最小化如下損失函式,儘可能把真實樣本分為正例,生成樣本分為負例:
(公式1 )
其中是真實樣本分佈,
是由生成器產生的樣本分佈。對於生成器,Goodfellow一開始提出來一個損失函式,後來又提出了一個改進的損失函式,分別是
(公式2)
(公式3)
為什麼GAN不適合處理文字資料
1. 文字資料相比較圖片資料來說是離散的,因為對於文字來說,通常需要將一個詞對映為一個高維的向量,最終預測的輸出是一個one-hot向量,假設softmax的輸出是(0.2, 0.3, 0.1,0.2,0.15,0.05)那麼變為onehot是(0,1,0,0,0,0),如果softmax輸出是(0.2, 0.25, 0.2, 0.1,0.15,0.1 ),one-hot仍然是(0, 1, 0, 0, 0, 0),所以對於生成器來說,G輸出了不同的結果但是D給出了同樣的判別結果,並不能將梯度更新資訊很好的傳遞到G中去,所以D最終輸出的判別沒有意義。
2. 另外就是GAN的損失函式是JS散度,JS散度不適合衡量不想交分佈之間的距離。
(WGAN雖然使用wassertein距離代替了JS散度,但是在生成文字上能力還是有限,GAN在生成文字上的應用有seq-GAN,和強化學習結合的產物)
訓練GAN的一些技巧
1. 輸入規範化到(-1,1)之間,最後一層的啟用函式使用tanh(BEGAN除外)
2. 使用wassertein GAN的損失函式,
3. 如果有標籤資料的話,儘量使用標籤,也有人提出使用反轉標籤效果很好,另外使用標籤平滑,單邊標籤平滑或者雙邊標籤平滑
4. 使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
5. 避免使用RELU和pooling層,減少稀疏梯度的可能性,可以使用leakrelu啟用函式
6. 優化器儘量選擇ADAM,學習率不要設定太大,初始1e-4可以參考,另外可以隨著訓練進行不斷縮小學習率,
7. 給D的網路層增加高斯噪聲,相當於是一種正則
2.DCGAN
【Paper】 :
http://arxiv.org/abs/1511.06434
【github】 :
https://github.com/Newmu/dcgan_code theano
https://github.com/carpedm20/DCGAN-tensorflow tensorflow
https://github.com/jacobgil/keras-dcgan keras
https://github.com/soumith/dcgan.torch torch
DCGAN是繼GAN之後比較好的改進,其主要的改進主要是在網路結構上,到目前為止,DCGAN的網路結構還是被廣泛的使用,DCGAN極大的提升了GAN訓練的穩定性以及生成結果質量。
論文的主要貢獻是:
◆ 為GAN的訓練提供了一個很好的網路拓撲結構。
◆ 表明生成的特徵具有向量的計算特性。
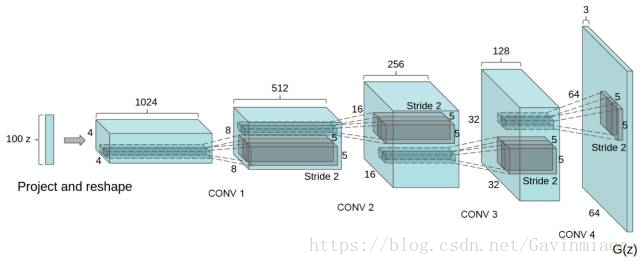
DCGAN的生成器網路結構如上圖所示,相較原始的GAN,DCGAN幾乎完全使用了卷積層代替全連結層,判別器幾乎是和生成器對稱的,從上圖中我們可以看到,整個網路沒有pooling層和上取樣層的存在,實際上是使用了帶步長(fractional-strided)的卷積代替了上取樣,以增加訓練的穩定性。
DCGAN能改進GAN訓練穩定的原因主要有:
◆ 使用步長卷積代替上取樣層,卷積在提取影象特徵上具有很好的作用,並且使用卷積代替全連線層。
◆ 生成器G和判別器D中幾乎每一層都使用batchnorm層,將特徵層的輸出歸一化到一起,加速了訓練,提升了訓練的穩定性。(生成器的最後一層和判別器的第一層不加batchnorm)
◆ 在判別器中使用leakrelu啟用函式,而不是RELU,防止梯度稀疏,生成器中仍然採用relu,但是輸出層採用tanh
◆ 使用adam優化器訓練,並且學習率最好是0.0002,(我也試過其他學習率,不得不說0.0002是表現最好的了)
主要改進總結:
1.將pooling層用convolutions替代。(對於判別模型,允許網路學習自己的空間下采樣;対於生成模型,允許它學習自己的空間上取樣)
2.在generator和discriminator上都使用batchnorm:
解決初始化差的問題
幫助梯度傳播到每一層
防止generator把所有的樣本都收斂到同一個點
3.在CNN中移除全連線層
4.在generator的除了輸出層外的所有層使用ReLU,輸出層採用tanh
5.在discriminator的所有層上使用LeakyReLU.
問題:
DCGAN雖然有很好的架構,但是對GAN訓練穩定性來說是治標不治本,沒有從根本上解決問題,而且訓練的時候仍需要小心的平衡G,D的訓練程序,往往是訓練一個多次,訓練另一個一次。
3.WGAN
【paper】:
https://arxiv.org/abs/1701.07875
【GitHub】:
https://github.com/hwalsuklee/tensorflow-generative-model-collections
https://github.com/Zardinality/WGAN-tensorflow
與DCGAN不同,WGAN主要從損失函式的角度對GAN做了改進,損失函式改進之後的WGAN即使在全連結層上也能得到很好的表現結果,WGAN對GAN的改進主要有:
◆ 判別器最後一層去掉sigmoid
◆ 生成器和判別器的loss不取log
◆ 對更新後的權重強制截斷到一定範圍內,比如[-0.01,0.01],以滿足論文中提到的lipschitz連續性條件。
◆ 論文中也推薦使用SGD, RMSprop等優化器,不要基於使用動量的優化演算法,比如adam,但是就我目前來說,訓練GAN時,我還是adam用的多一些。
從上面看來,WGAN好像在程式碼上很好實現,基本上在原始GAN的程式碼上不用更改什麼,但是它的作用是巨大的
◆ WGAN理論上給出了GAN訓練不穩定的原因,即交叉熵(JS散度)不適合衡量具有不相交部分的分佈之間的距離,轉而使用wassertein距離去衡量生成資料分佈和真實資料分佈之間的距離,理論上解決了訓練不穩定的問題。
◆ 解決了模式崩潰的(collapse mode)問題,生成結果多樣性更豐富。
◆ 對GAN的訓練提供了一個指標,此指標數值越小,表示GAN訓練的越差,反之越好。可以說之前訓練GAN完全就和買彩票一樣,訓練好了算你中獎,沒中獎也不要氣餒,多買幾注吧。
有關GAN和WGAN的解釋,可以參考連結:https://zhuanlan.zhihu.com/p/25071913
總的來說,GAN中交叉熵(JS散度)不適合衡量生成資料分佈和真實資料分佈的距離,如果通過優化JS散度訓練GAN會導致找不到正確的優化目標,所以,WGAN提出使用wassertein距離作為優化方式訓練GAN,但是數學上和真正程式碼實現上還是有區別的,使用Wasserteion距離需要滿足很強的連續性條件—lipschitz連續性,為了滿足這個條件,作者使用了將權重限制到一個範圍的方式強制滿足lipschitz連續性,但是這也造成了隱患,接下來會詳細說。另外說實話,雖然理論證明很漂亮,但是實際上訓練起來,以及生成結果並沒有期待的那麼好。
注:Lipschitz限制是在樣本空間中,要求判別器函式D(x)梯度值不大於一個有限的常數K,通過權重值限制的方式保證了權重引數的有界性,間接限制了其梯度資訊。
4.WGAN-GP (improved wgan)
【paper】:
https://arxiv.org/abs/1704.00028
【GitHub】:
https://link.zhihu.com/?target=https%3A//github.com/igul222/improved_wgan_training
https://github.com/caogang/wgan-gp
WGAN-GP是WGAN之後的改進版,主要還是改進了連續性限制的條件,因為,作者也發現將權重剪下到一定範圍之後,比如剪下到[-0.01,+0.01]後,發生了這樣的情況,如下圖左邊表示。

發現大多數的權重都在-0.01 和0.01上,這就意味了網路的大部分權重只有兩個可能數,對於深度神經網路來說不能充分發揮深度神經網路的擬合能力,簡直是極大的浪費。並且,也發現強制剪下權重容易導致梯度消失或者梯度爆炸,梯度消失很好理解,就是權重得不到更新資訊,梯度爆炸就是更新過猛了,權重每次更新都變化很大,很容易導致訓練不穩定。梯度消失與梯度爆炸原因均在於剪下範圍的選擇,選擇過小的話會導致梯度消失,如果設得稍微大了一點,每經過一層網路,梯度變大一點點,多層之後就會發生梯度爆炸 。為了解決這個問題,並且找一個合適的方式滿足lipschitz連續性條件,作者提出了使用梯度懲罰(gradient penalty)的方式以滿足此連續性條件,其結果如上圖右邊所示。
梯度懲罰就是既然Lipschitz限制是要求判別器的梯度不超過K,那麼可以通過建立一個損失函式來滿足這個要求,即先求出判別器的梯度d(D(x)),然後建立與K之間的二範數就可以實現一個簡單的損失函式設計。但是注意到D的梯度的數值空間是整個樣本空間,對於圖片(既包含了真實資料集也包含了生成出的圖片集)這樣的資料集來說,維度及其高,顯然是及其不適合的計算的。作者提出沒必要對整個資料集(真的和生成的)做取樣,只要從每一批次的樣本中取樣就可以了,比如可以產生一個隨機數,在生成資料和真實資料上做一個插值

於是就算解決了在整個樣本空間上取樣的麻煩。
所以WGAN-GP的貢獻是:
◆ 提出了一種新的lipschitz連續性限制手法—梯度懲罰,解決了訓練梯度消失梯度爆炸的問題。
◆ 比標準WGAN擁有更快的收斂速度,並能生成更高質量的樣本
◆ 提供穩定的GAN訓練方式,幾乎不需要怎麼調參,成功訓練多種針對圖片生成和語言模型的GAN架構
但是論文提出,由於是對每個batch中的每一個樣本都做了梯度懲罰(隨機數的維度是(batchsize,1)),因此判別器中不能使用batch norm,但是可以使用其他的normalization方法,比如Layer Normalization、Weight Normalization和Instance Normalization,論文中使用了Layer Normalization,weight normalization效果也是可以的。為了比較,還是給出了下面這張圖,可以發現WGAN-GP完爆其他GAN:

5.LSGAN
最小二乘GAN
全稱是Least Squares Generative Adversarial Networks
【paper】
https://arxiv.org/abs/1611.04076
【github】
https://github.com/hwalsuklee/tensorflow-generative-model-collections
https://github.com/guojunq/lsgan
LSGAN原理:
其實原理部分可以一句話概括,即使用了最小二乘損失函式代替了GAN的損失函式。
但是就這樣的改變,緩解了GAN訓練不穩定和生成影象質量差多樣性不足的問題。
事實上,作者認為使用JS散度並不能拉近真實分佈和生成分佈之間的距離,使用最小二乘可以將影象的分佈儘可能的接近決策邊界,其損失函式定義如下:
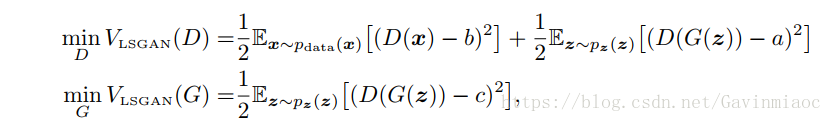
其中作者設定a=c=1,b=0
論文裡還是給了一些數學推導與證明,感興趣的可以去看看
生成結果展示:

6.BEGAN:
BEGAN全稱是Boundary Equilibrium GANs
【paper】:
https://arxiv.org/abs/1703.10717
【GitHub】:
https://github.com/carpedm20/BEGAN-tensorflow
https://github.com/Heumi/BEGAN-tensorflow
https://github.com/carpedm20/BEGAN-pytorch
BEGAN的主要貢獻:
◆ 提出了一種新的簡單強大GAN,使用標準的訓練方式,不加訓練trick也能很快且穩定的收斂
◆ 對於GAN中G,D的能力的平衡提出了一種均衡的概念(GAN的理論基礎就是goodfellow理論上證明了GAN均衡點的存在,但是一直沒有一個準確的衡量指標說明GAN的均衡程度)
◆ 提出了一種收斂程度的估計,這個機制只在WGAN中出現過。作者在論文中也提到,他們的靈感來自於WGAN,在此之前只有wgan做到了
◆提供了一個超引數,這個超引數可以在影象的多樣性和生成質量之間做均衡(熟悉GAN的小夥伴就知道這又多難得)
先說說BEGAN的主要原理,BEGAN和其他GAN不一樣,這裡的D使用的是auto-encoder結構,就是下面這種,D的輸入是圖片,輸出是經過編碼解碼後的圖片,
為了估計分佈的誤差,作者使用了auto-encoder作為D,D的輸入是影象V,維度為RNx,輸出的也是維度為RNx的圖片,本文中n=1,自編碼器的模型如下 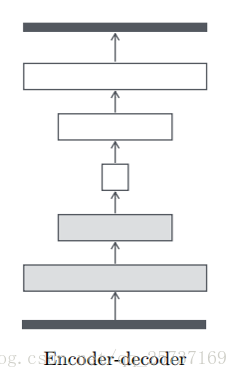
之前的GAN以及其變種都是希望生成器生成的資料分佈儘可能的接近真實資料的分佈,當生成資料分佈等同於真實資料分佈時,我們就確定生成器G經過訓練可以生成和真實資料分佈相同的樣本,即獲得了生成足以以假亂真資料的能力,所以從這一點出發,研究者們設計了各種損失函式去令G的生成資料分佈儘可能接近真實資料分佈。BEGAN代替了這種估計概率分佈方法,它不直接去估計生成分佈Pg與真實分佈Px的差距,進而設計合理的損失函式拉近他們之間的距離,而是估計分佈的誤差之間的距離,作者認為只要分佈的的誤差分佈相近的話,也可以認為這些分佈是相近的。即如果我們認為兩個人非常相似,又發現這兩人中的第二個人和第三個人很相似,那麼我們就完全可以說第一個人和第三個人長的很像。
在BEGAN中,第一個人相當於訓練的資料x,第二個人相當於D對x編碼解碼後的影象D(x),第三個人相當於D以G的生成為輸入的結果D(g(z)),所以,如果||D(x)-x|| - || D(x)- D(g(z)) || 不斷趨近於0,那麼隨著訓練,D(x)會不斷接近x,那麼D(g(z)) 接近於D(x),豈不是就意味著 g(z) 的資料分佈和x分佈幾乎一樣了,那麼就說明G學到了生成資料的能力。於是乎,假設圖片足夠大,畫素很多。但是問題來了,如果||D(x)-x|| - || D(x)- D(g(z)) ||剛好等於0,這時候,D(x)和x可能還差的很遠呢,那不就什麼也學不到了D(x)-x是一個圖片,假設圖片上的每一個畫素都滿足獨立同分布條件,根據中心極限定理,畫素的誤差近似滿足正太分佈,假設期望是m1,方差是μ1,同理D(x)- D(g(z)),還有m2, μ2這時候如果我們再用wassertein距離衡量m1與m2的距離,
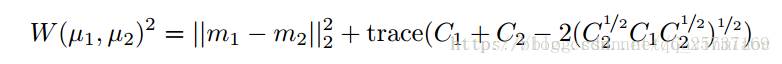
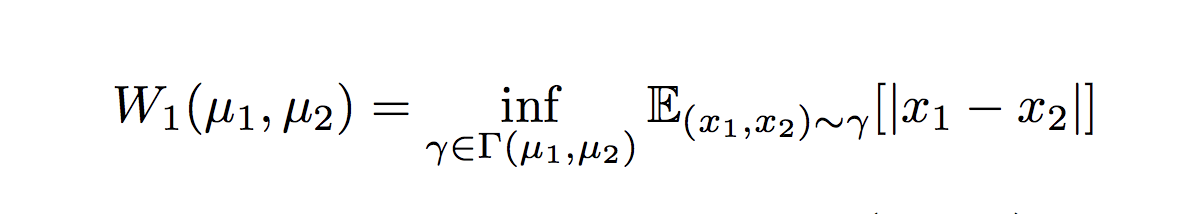
trace是求跡操作。
再滿足下面這個條件下,

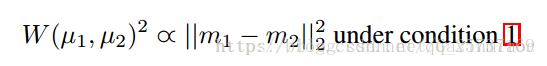
即他們成正比,這時候連lipschitz連續性條件也不需要了,
令D不斷的最大化m2,最小化m1,而G則不斷最小化m2,當m2 接近m1的時候我們就認為GAN完成了訓練。
分析到這裡我們得出結論,我們可以去估計誤差的分佈而不是直接估計分佈去擬合GAN,但是損失函式究竟是怎麼樣的呢?
有一個問題,當m1和m2很接近是,條件1是趨於無窮的,不可能再忽略,於是,boundary(限制)就來了,
設定一個位於[0~1]之間的數λ,強制將m1和m2劃分開界限,具體的損失函式如下:
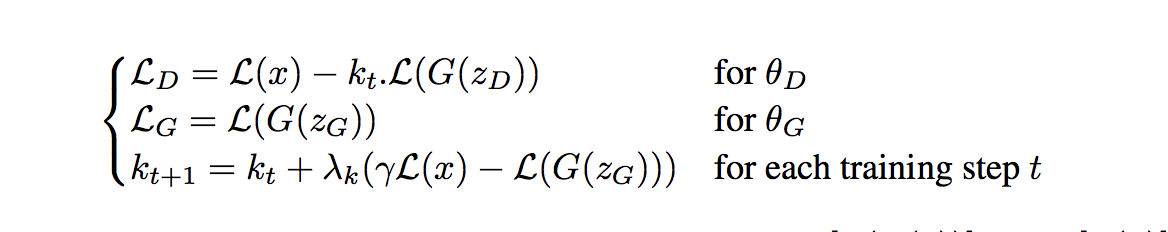
BEGAN的訓練結果:不同的γ可以在圖片的質量和生成多樣性之間做選擇。

7.SRGAN
SRGAN (Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, arxiv, 21 Nov, 2016)將生成式對抗網路(GAN)用於SR問題。其出發點是傳統的方法一般處理的是較小的放大倍數,當影象的放大倍數在4以上時,很容易使得到的結果顯得過於平滑,而缺少一些細節上的真實感。因此SRGAN使用GAN來生成影象中的細節。
傳統的方法使用的代價函式一般是最小均方差(MSE),即
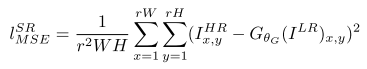
該代價函式使重建結果有較高的信噪比,但是缺少了高頻資訊,出現過度平滑的紋理。SRGAN認為,應當使重建的高解析度影象與真實的高解析度影象無論是低層次的畫素值上,還是高層次的抽象特徵上,和整體概念和風格上,都應當接近。整體概念和風格如何來評估呢?可以使用一個判別器,判斷一副高解析度影象是由演算法生成的還是真實的。如果一個判別器無法區分出來,那麼由演算法生成的影象就達到了以假亂真的效果。
因此,該文章將代價函式改進為
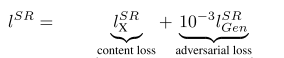 第一部分是基於內容的代價函式,第二部分是基於對抗學習的代價函式。基於內容的代價函式除了上述畫素空間的最小均方差以外,又包含了一個基於特徵空間的最小均方差,該特徵是利用VGG網路提取的影象高層次特徵:
第一部分是基於內容的代價函式,第二部分是基於對抗學習的代價函式。基於內容的代價函式除了上述畫素空間的最小均方差以外,又包含了一個基於特徵空間的最小均方差,該特徵是利用VGG網路提取的影象高層次特徵: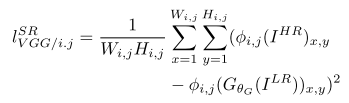 對抗學習的代價函式是基於判別器輸出的概率:
對抗學習的代價函式是基於判別器輸出的概率: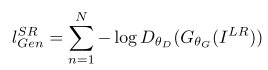
相關推薦
各種GAN原理總結及對比
最近試著玩了多種GAN,今天我們主要總結下常用的GAN包括DCGAN,WGAN,WGAN-GP,LSGAN-BEGAN,SRGAN的詳細原理介紹以及他們對GAN的主要改進,並推薦了一些Github程式碼復現連結。 本文旨在對GAN的變種做一些梳理工作,詳細請看下文。1.原始G
DCGAN、WGAN、WGAN-GP、LSGAN、BEGAN原理總結及對比
GAN系列學習(2)——前生今世 本文已投稿至微信公眾號--機器學習演算法工程師,歡迎關注 本文是GAN系列學習–前世今生第二篇,在第一篇中主要介紹了
Https原理總結及抓取Https的工作原理
Https原理: a.Https == Http + SSL(TSL),SSL是網景公司的命名,TSL為OSI組織接手名的命名 b.要解決的問題:傳統HTTP協議可能有三大風險: b.1 被截獲並獲取內容(因為是明文傳輸) &n
檔案包含漏洞的原理總結及例題
什麼是檔案包含漏洞: PHP檔案包含漏洞的產生原因: 在通過PHP的函式引入檔案時,由於傳入的檔名沒有經過合理的校驗,從而操作了預想之外的檔案,就可能導致意外的檔案洩露甚至惡意的程式碼注入。最常見的就屬於本地檔案包含(Local File Inclusion)漏洞了。
Java 多執行緒加鎖的方式總結及對比
一.Java多執行緒可以通過: 1. synchronized關鍵字 2. Java.util.concurrent包中的lock介面和ReentrantLock實現類 這兩種方式實現加鎖。 二.synchronized關鍵字加鎖的缺陷: 如
微服務總結及對比
一、微服務技術棧總結 微服務條目 落地技術 服務開發 SpringCloud、Spring、SpringMVC 服務配置與管理 Netfix公司的Archaius、阿里的Diamond
GAN原理總結
基礎GAN:原理 GAN(Generative Adversarial Nets,生成對抗網路)由J.GoodFellow在2014年的文章中正式提出,在其後大熱,在兩三年內被提出多種實用的改進方法,且仍在快速發展.在影象創作,超解析度重建等方面已
【超詳細】計算機組成原理總結及思維導圖
計算機組成 第一章 計算機系統概論 馮諾依曼型計算機特點 1.計算機由運算器,控制器,儲存器,輸入和輸出裝置5部分組成 2.採用儲存程式的方式,程式和資料放在同一個儲存器中,並以二進位制表示。 3.指
各種排序演算法總結及C#程式碼實現
排序是計算機內經常進行的一種操作,其目的是將一組“無序”的記錄序列調整為“有序”的記錄序列。分內部排序和外部排序。若整個排序過程不需要訪問外存便能完成,則稱此類排序問題為內部排序。反之,若參加排序的記錄數量很大,整個序列的排序過程不可能在記憶體中完成,則稱此類排序問
【神經網路】GAN原理總結,CatGAN
定義及原理: 生成器 (G)generator:接收一個隨機的噪聲z(隨機數),通過這個噪聲生成影象。G的目標就是儘量生成真實的圖片去欺騙判別網路D。 判別器(D) discriminator:對接收的圖片進行真假判別。它的輸入引數是x
Java常用消息隊列原理介紹及性能對比
創新 序列化 knowledge rom sage 特定 了解 代碼 lang 消息隊列使用場景為什麽會需要消息隊列(MQ)?解耦 在項目啟動之初來預測將來項目會碰到什麽需求,是極其困難的。消息系統在處理過程中間插入了一個隱含的、基於數據的接口層,兩邊的處理過程都要實現
HTML5總結及原理剖析
html5中新增的特性 1.語義化標籤,比如:<header> <footer> <article>等,可以使我們建立更友好的頁面結構,便於搜尋引擎抓取; div是division的縮寫,你在網頁中寫了大量的div,就算你寫了class
Java常用訊息佇列原理介紹及效能對比
訊息佇列使用場景 為什麼會需要訊息佇列(MQ)? 解耦 在專案啟動之初來預測將來專案會碰到什麼需求,是極其困難的。訊息系統在處理過程中間插入了一個隱含的、基於資料的介面層,兩邊的處理過程都要實現這一介面。這允許你獨立的擴充套件或修改兩邊的處理
最後階段基礎知識點及Oracle各種知識點重點總結
yi:Oracle中字串連線的實現方法 1.和其他資料庫系統類似,Oracle字串連線使用“||”進行字串拼接,其使用方式和MSSQLServer中的加號“+”一樣。 例如: SELECT '工號為'||FNumber||'的員工姓名為'||FName FROM T
手機充電原理分析及問題總結
(1)充電流程介紹:當充電器插入時,亦即為PMIC充電模組提供了Vcharge電壓,這時會產生一個充電中斷訊號到CPU,通知CPU現在已經進入充電狀態。CPU開始啟動如下模組: 1,ADC取樣,主要是採集Vchrg,Vbat及從MOSFET漏極輸出的電壓,可以算出充電電壓和
機器學習常見演算法及原理總結(乾貨)
樸素貝葉斯 參考[1] 事件A和B同時發生的概率為在A發生的情況下發生B或者在B發生的情況下發生A P(A∩B)=P(A)∗P(B|A)=P(B)∗P(A|B) 所以有: P(A|B)=P(B|A)∗P(A)P(B) 對於給出的待分類項,求解在此項出現的條件下各個目標類別出
python學習番外篇之print輸出函式用法及原理總結
print輸出函式用法及原理總結: 在python2.x中,print作為關鍵字使用,輸出用print語句輸出,例如,x=5 ; print x ,但在python3.x中,print則成為了一個函式,輸出用print()函式輸出,例如:x=5 ; print(
Android編譯過程總結及android中各種img檔案的作用以及系統啟動過程
編譯環境:ubuntu 10.04(或者更高)(windows平臺目前不被支援) 本文以編譯android2.3為例,64位作業系統 1、編譯環境的準備 (1)確保安裝有ubuntu系統或者虛擬機器 (2)安裝JDK1.6(對於Android2.3以上程式碼) $ sud
android lambda的使用總結及執行原理
為了支援函數語言程式設計,Java 8引入了Lambda表示式,Android N已經開始支援Java 8 了。Java 8中的新特性,是開發者們的一大福音,從此我們可以happy的在程式碼中使用Lambda了,呼叫Stream等。本篇文章主要介紹Lambda的
HashMap原始碼分析及原理總結
從上面的例子中可以看出:當它們和15-1(1110)“與”的時候,產生了相同的結果,也就是說它們會定位到陣列中的同一個位置上去,這就產生了碰撞,8和9會被放到陣列中的同一個位置上形成連結串列,那麼查詢的時候就需要遍歷這個鏈 表,得到8或者9,這樣就降低了查詢的效率。同時,我們也可以發現,當陣列長度為15的時候