
【Python】【爬蟲】爬取京東商品使用者評論(分析+視覺化)
-----------------------------------------------------------------------------------------------------------------------------
1:在商品頁面f12或右鍵審查元素,點選network 輸入存使用者評論的json檔案productPageComments 重新整理
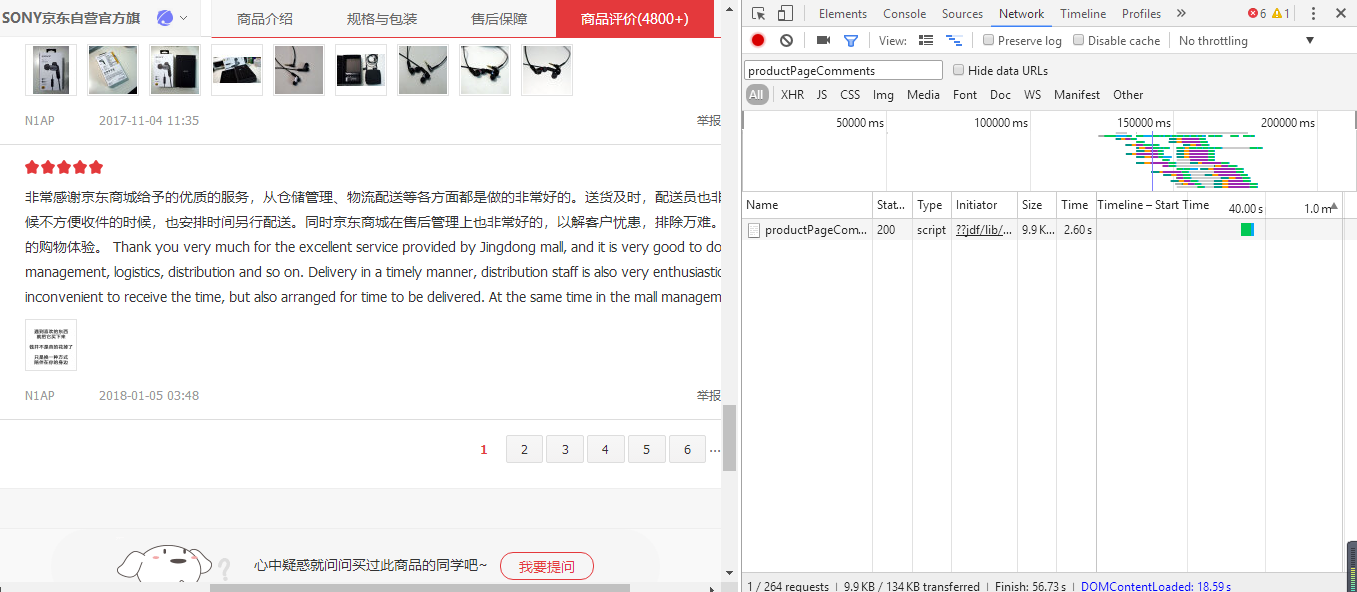
點選跳轉到第二頁評論的按鈕會在刷出一個json檔案
雙擊這個檔案開啟網頁複製網頁url到記事本以便找出規律
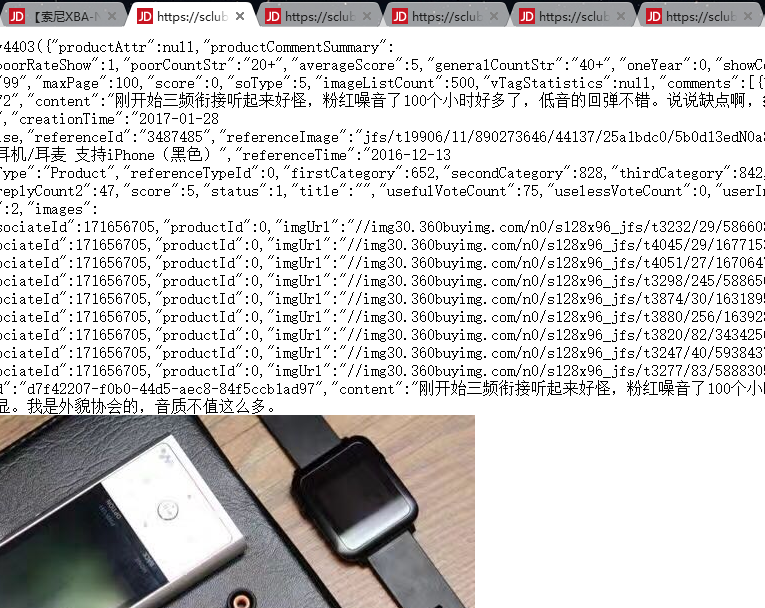
叮!規律識破!

2:定個小目標先爬它個15頁
先存到本地一波.
import requests import urllib3 import json import urllib import urllib.request from bs4 import BeautifulSoup for i in range(1, 15): url1 = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4403&productId=3487485&score=3&sortType=5&page=' url2 = str(i) uel3 = '&pageSize=10&isShadowSku=0&rid=0&fold=1' finalurl = url1+url2+uel3 xba = requests.get(finalurl) for i in range(1, 15): u1 = "E:\\pachong1\\" u2 = str(i) u3 = ".json" finalu = u1+u2+u3 file = open(finalu, "w") file.write(xba.text[26:-2]) file.close() st = xba.text print('finished')
3再定箇中等目標,爬取150頁使用者具體評論內容,並存入本地.
import requests import urllib3 import json import urllib import urllib.request from bs4 import BeautifulSoup for i in range(1, 150): url1 = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4403&productId=3487485&score=3&sortType=5&page=' url2 = str(i) uel3 = '&pageSize=10&isShadowSku=0&rid=0&fold=1' finalurl = url1+url2+uel3 xba = requests.get(finalurl) data=json.loads(xba.text[26:-2]) for i in data['comments']: content = i['content'] print("評論內容".format(content)) file=open("E:\\pachong1\\comm.txt", 'a') file.writelines(format(content)) print("finished")
以下為該商品前150頁使用者評論內容

4終極目標:清洗資料,統計每個詞的出現次數,並用詞雲進行展示
這裡需要stopwords檔案和simhei.ttf都可以在網上下的得到,但stopwords檔案需要下載券,這裡我下載之後放到了百度雲上
stopwords: https://pan.baidu.com/s/1K-fbpcbHJzM67Jq1O4YLZQ
import re import jieba import pandas as p import numpy from wordcloud import WordCloud import matplotlib.pyplot as plt import matplotlib #讀檔案 file1 = open("E:\\pachong1\\comm.txt", 'r') xt = file1.read() pattern = re.compile(r'[\u4e00-\u9fa5]+') filedata = re.findall(pattern, xt) xx = ''.join(filedata) file1.close() # 清洗資料 clear = jieba.lcut(xx) cleared = p.DataFrame({'clear': clear}) #print(clear) stopwords = p.read_csv("chineseStopWords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'], encoding='GBK') cleared = cleared[~cleared.clear.isin(stopwords.stopword)] #print(std) count_words=cleared.groupby(by=['clear'])['clear'].agg({"num": numpy.size}) count_words=count_words.reset_index().sort_values(by=["num"], ascending=False) #print(count_words) # 詞雲展示 wordcloud=WordCloud(font_path="simhei.ttf",background_color="white",max_font_size=250,width=1300,height=800) #指定字型型別、字型大小和字型顏色 word_frequence = {x[0]:x[1] for x in count_words.head(200).values} wordcloud=wordcloud.fit_words(word_frequence) plt.imshow(wordcloud) plt.axis("off") plt.colorbar() #顏色條 plt.show() #wctext = open('E:\\pachong1\\comm1.txt', 'r') print("finish")
畫出詞雲,當然還可以自定義處各種效果

精簡完整版-不進行中間儲存
ps:你需要將stopwords檔案與背景圖片放入當前目錄下,或者在程式中指定響應檔案路徑。
import requests
import json
import re
import jieba
import pandas as pd
import numpy
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from os import path
import numpy as np
from PIL import Image
# 資料爬取模組
def get_comments():
all_comments = ""
for i in range(1, 90):
url2 = str(i)
url1c = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv2&productId=7652137&score=0&sortType=5&page='
url3c = '&pageSize=10&isShadowSku=0&rid=0&fold=1'
finalurlc = url1c+url2+url3c
xba = requests.get(finalurlc)
data=json.loads(xba.text[23:-2])
for j in data['comments']:
content = j['content']
all_comments = all_comments+content
print(i)
print("finished")
return all_comments
# 資料清洗處理模組
def data_clear():
xt = get_comments()
pattern = re.compile(r'[\u4e00-\u9fa5]+')
filedata = re.findall(pattern, xt)
xx = ''.join(filedata)
clear = jieba.lcut(xx) # 切分詞
cleared = pd.DataFrame({'clear': clear})
stopwords = pd.read_csv("chineseStopWords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'], encoding='GBK')
cleared = cleared[~cleared.clear.isin(stopwords.stopword)]
count_words = cleared.groupby(by=['clear'])['clear'].agg({"num": numpy.size})
count_words = count_words.reset_index().sort_values(by=["num"], ascending=False)
return count_words
#詞雲展示模組
def make_wordclound():
d = path.dirname(__file__)
msk = np.array(Image.open(path.join(d, "me.jpg")))
wordcloud = WordCloud(font_path="simhei.ttf",mask=msk,background_color="#EEEEEE",max_font_size=250,width=1300,height=800) #指定字型型別、字型大小和字型顏色
word_frequence = {x[0]:x[1] for x in data_clear().head(200).values}
wordcloud = wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
if __name__=="__main__":
make_wordclound()
print("finish")
相關推薦
【Python】【爬蟲】爬取京東商品使用者評論(分析+視覺化)
----------------------------------------------------------------------------------------------------------------------------- 1:在商品頁面f1
[python爬蟲] selenium爬取區域性動態重新整理網站(URL始終固定)
在爬取網站過程中,通常會遇到區域性動態重新整理情況,當你點選“下一頁”或某一頁時,它的資料就進行重新整理,但其頂部的URL始終不變。這種區域性動態重新整理的網站,怎麼爬取資料呢?某網站資料顯示如下圖所示,當點選“第五頁”之時,其URL始終不變,傳統的網站爬取方法是無法拼接這類
【Python資料分析】簡單爬蟲,爬取知乎神回覆
歡迎加入Python學習交流QQ群:535993938 禁止閒聊 ! 名額有限 ! 非喜勿進 ! 看知乎的時候發現了一個 “如何正確地吐槽” 收藏夾,
【python 淘寶爬蟲】淘寶信譽分抓取
一、需求分析 輸入旺旺號,獲取淘寶賣家的信用分 二、思路 淘寶需要模擬登陸,我們這裡抓不到,因此為了繞過登陸,發現了淘一兔,我們可以通過這裡,得到淘寶賣家的信用分,結果是一樣的。 http:
python制作爬蟲爬取京東商品評論教程
頭文件 天津 ref back 文字 eai 目的 格式 open 作者:藍鯨 類型:轉載 本文是繼前2篇Python爬蟲系列文章的後續篇,給大家介紹的是如何使用Python爬取京東商品評論信息的方法,並根據數據繪制成各種統計圖表,非常的細致,有需要的小夥伴可以參考下
Python網絡爬蟲:爬取古詩文中的某個制定詩句來實現搜索
它的 參考文獻 lis 實現 word self 適合 odi 級別 python編譯練習,為了將自己學習過的知識用上,自己找了很多資料。所以想做一個簡單的爬蟲,代碼不會超過60行。主要用於爬取的古詩文網站沒有什麽限制而且網頁排布很規律,沒有什麽特別的東西,適合入門級別的
利用Python爬蟲爬取京東商品的簡要資訊
一、前言 本文適合有一定Python基礎的同學學習Python爬蟲,無基礎請點選:慕課網——Python入門 申明:例項的主體框架來自於慕課網——Python開發簡單爬蟲 語言:Python2 IDE:VScode二、何為爬蟲 傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的UR
Python資料爬蟲學習筆記(21)爬取京東商品JSON資訊並解析
一、需求:有一個通過抓包得到的京東商品的JSON連結,解析該JSON內容,並提取出特定id的商品價格p,json內容如下: jQuery923933([{"op":"7599.00","m":"9999.00","id":"J_5089253","p":"7099.00"}
網路爬蟲:Python+requests+bs4+xlwt 爬取京東商品存入Excel表
學了網路爬蟲兩週了,還是比較喜歡用網頁級庫requests,很靈活方便,scrapy網站級面向物件庫,還不熟悉,可能是原來c++學習面向物件就沒學好,對面向物件程式設計還沒理解好吧...兩週中爬了淘寶,京東,天貓(爬取失敗,反爬蟲把我這種新手難倒了,登入驗證就卡死),爬取搜狗
Python 爬蟲 爬取京東 商品評論 資料,並存入CSV檔案
利用閒暇時間寫了一個抓取京東商品評論資料的爬蟲。之前寫了抓取拉勾網資料的爬蟲,請 參考1,參考2。 我的開發環境是Windows + Anaconda3(Python 3.6),家用電腦沒安裝Linux(Linux下也是可以的)。 京東的評論資料是通過介面提供的,所以先找
python 3.3 爬蟲之爬取圖片
今天沒事用BeautifulSoup寫了一個爬取淘寶頁面的部分圖片的程式碼,之前用正則也寫了一個,感覺用BeautifulSoup 更簡單了 import urllib import urllib.request as request from bs4 import Bea
python爬蟲實踐----爬取京東圖片
爬蟲思路: 1.分析url: http://list.jd.com/list.html?cat=9987,653,655&page=1 # url只有page變化,而page代表了頁數
python網絡爬蟲《爬取get請求的頁面數據》
可用 enc 搜索 爬蟲程序 pre www __main__ object python網絡 一、urllib庫 urllib是python自帶的一個用於爬蟲的庫,其主要作用就是可以通過代碼模擬瀏覽器發送請求。其常被用到的子模塊在python3中的為urllib.r
python 爬蟲實戰專案--爬取京東商品資訊(價格、優惠、排名、好評率等)
利用splash爬取京東商品資訊一、環境window7python3.5pycharmscrapyscrapy-splashMySQL二、簡介 為了體驗scrapy-spla
Python使用Scrapy爬蟲框架爬取天涯社群小說“大宗師”全文
大宗師是著名網路小說作家蛇從革的系列作品“宜昌鬼事”之一,在天涯論壇具有超級高的訪問量。這個長篇小說於2015年3月17日開篇,並於2016年12月29日大結局,期間每天有7萬多讀者閱讀。如果在天涯社群直接閱讀的話,會被很多讀者留言干擾,如圖 於是,我寫了下面的程式碼,從
Python爬蟲實戰(2):爬取京東商品列表
1,引言在上一篇》,爬取了一個用Drupal做的論壇,是靜態頁面,抓取比較容易,即使直接解析html原始檔都可以抓取到需要的內容。相反,JavaScript實現的動態網頁內容,無法從html原始碼抓取
Python爬取京東商品列表
+= 圖片 info sta HR earch tex new html 爬取代碼: import requests from bs4 import BeautifulSoup def page_url(url): for i in range(1, 3):
Java爬蟲爬取京東商品信息
1.2 image 商品 void code 更改 size pri name 以下內容轉載於《https://www.cnblogs.com/zhuangbiing/p/9194994.html》,在此僅供學習借鑒只用。 Maven地址 <dependency>
爬蟲之爬取豆瓣圖書的評論
pen 數據 app bs4 lis 爬取 fix replace sub from urllib import request from bs4 import BeautifulSoup as bs #爬取豆瓣最受關註圖書榜 resp = request.urlope
Scrapy框架基於crawl爬取京東商品資訊爬蟲
Items.py檔案 # -*- coding: utf-8 -*- # Define here the models for your scraped items # See documentation in: # https://doc.scrapy.org/en/latest/topics