
storm如何高效地實現可靠性?
一個storm拓撲有一系列特殊的“acker”任務用來跟蹤 每一個spout傳送的所有tuple的dag(directed acyclic graph有向無環圖)。當一個acker看到一個dag完成以後,它會給創造spout touple的spout task傳送一個應答ack訊息。你可以設定一個拓撲的acker task的個數在Config.TOPOLOGY_ACKERS,預設情況下每個任務的每個worker有一個acker。
理解storm可靠性的最好方式是看tuple的生命週期和tuple dags。當一個拓撲中的一個tuple產生時,無論他是一個spout或者一個bolt,都會隨機給定一個64位的id,這些id用來讓ackers跟蹤dag中的每一個spout tuple。
每個tuple知道存在於他們的tuple 樹的spout tuple的ids(也就是這個tuple的源tuple的id(祖宗id)) ,問你在一個bolt中傳送一個新的tuple時,他的源spout tuple id會被複制給這個新的tuple。當一個tuple被ack,他傳送一個訊息到正確的acker task,資訊內容包括這個tuple tree是怎麼改變的。特別的,他會告訴acker“我是這個源spout tuple的tuple樹內部完成的,並且這些是從我產生的新的tuples”。(請繼續跟蹤他們)
例如,如果tuple“D"和”E“是基於tuple”C”產生的,那麼當C ack的時候,tuple 樹是這樣變化的:
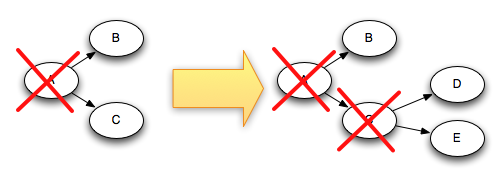
由於C從樹中被刪除的同時D和E同時被新增進樹,這個樹絕不會被永久性的完成。
還有一些細節,正如前文所提到,你可以在一個拓撲中有一個任意個數的acker tasks,那麼引出一個問題:當拓撲中的一個tuple被ack了,他怎麼知道給哪個ack task傳送這個ack訊息呢?
storm使用mod hashing來處理spout tuple和ack task之間的對映。由於每個tuple都會攜帶他所處的所有tuple tree的所有源spout tuple id,因此他們知道要跟哪個ack task交流。
另一個storm的細節是ack tasks如何跟蹤哪一個spout task負責的所有spout tuple。當一個spout task傳送一個新的tuple,他簡單地給正確的acker傳送一個訊息告訴他他要跟蹤的任務id,然後當一個acker看到一個樹被完成,他知道要給哪個task id傳送完成訊息。
ack task不顯式跟蹤tuples的tuple tree,對於那些有幾千個節點或者更多的節點的大型tuple樹,跟蹤所有tuple tree可能會用ackers壓倒性的佔用記憶體。替而代之的是,ackers 採取不同的策略,每個源spout id只需要一個固定空間(20bites)。這個跟蹤演算法就是storm工作的關鍵,也是他所取得的重大突破之一。
一個acker儲存了一個從spout tuple id到 一對數值的一個對映。這一對值中,第一個值是task id,就是創造了spout touple 的task id(spout task id)這個id用來接收完成訊息。第二個值是64位的“ack cal”。ack val是整個tuple 樹的狀態的表現形式,無論這個樹多大或者多小,他都是所有無論是acked或者created的tuple id異或的結果。
當一個acker task發現一個ack val變成了0,他就知道這個tuple tree已經完成了。由於tuple id是一個隨機的64位數,ack val突然變成0 的機率及其小,數學上,每秒鐘10K ack,需要花50000000年才會出現一個錯誤。即使是這樣,那個拓撲的tuple失效了也只會導致資料丟失。
現在,總結storm是如何避免資料丟失的:
由於一個task掛掉了而導致一個tuple不能acked:這種情況下這個失效的tuple所在的樹的源spout tuple id將會超時,然後會被重發
acker task 掛掉:這種情況下所有這個acker跟蹤的spout tuple id會超時並且重發
spout task掛掉:這個spout交流的source將會重發訊息,例如,佇列如Kestrel和RabbitMQ 當一個使用者失去連線以後將會替換佇列中所有掛起的訊息。
因此,storm的可靠性機制是完全分散式的、可拓展的、和可容錯的。
acker task是輕量級的,一個拓撲中不需要太多acker task,你可以從storm UI(component id“_acker”)中跟蹤他們的效能,如果吞吐量看著不太對,你可能需要增加更多的acker tasks。
如果可靠性不重要,你可以忍受發生故障情況下的資料丟失,你可以不跟蹤spout tuple,不跟蹤可以減少一半的訊息傳送量,(因為一般每個樹裡的沒個tuple都有一個ack message要傳輸)還能減少頻寬。
有三種方法可以去除可靠性,這裡不詳述了
相關推薦
storm如何高效地實現可靠性?
一個storm拓撲有一系列特殊的“acker”任務用來跟蹤 每一個spout傳送的所有tuple的dag(directed acyclic graph有向無環圖)。當一個acker看到一個dag完成以後,它會給創造spout touple的spout task傳送一個應答ac
如何高效地寫CSS--等以後有空多加總結一下
如何 span -- nbsp 項目 效率 自己 css引入 工程 CSS寫的並不多,如果從零開始的項目,自己一定想搬磚來得容易點。CSS編寫一定有其工程化的方法,來時編寫更加有效率。 考慮將CSS的預處理LESS、Sass或Stylus引入,或者將CSS的後處理Post
udp如何實現可靠性傳輸?
不能 處理 pad 實體 特性 name 們的 生成 tro 版權聲明:本文為博主原創文章,未經博主允許不得轉載。 目錄(?)[+] 1udp與tcp的區別 TCP(TransmissionControl Protocol 傳輸控制協議)
如何高效地分析Android_log中的問題?——查看Android源碼
work bug 發生 file roi 選擇 就會 技術分享 framework 在日常解bugs時,需要通過log日誌來分析問題,例如查看crash發生時的堆棧信息時,就會有Android的源碼的調用,這是就要去查看Android源碼。 1.進入Android源
如何高效地判斷數組中是否包含某特定值
算法 for 循環 false set ear 搜索算法 lis 復雜度 如何檢查一個未排序的數組中是否包含某個特定的值,這是在Java中非常實用並且頻繁使用的操作。另外,檢查數組中是否包含特定值可以用多種不同的方式實現,但是時間復雜度差別很大。下面,我將為大家展示各種方法
MQTT是IBM開發的一個即時通訊協議,構建於TCP/IP協議上,是物聯網IoT的訂閱協議,借助消息推送功能,可以更好地實現遠程控制
集合 cap 消息處理 簡易 遠程控制 mes ogr 設計思想 成本 最近一直做物聯網方面的開發,以下內容關於使用MQTT過程中遇到問題的記錄以及需要掌握的機制原理,主要講解理論。 背景 MQTT是IBM開發的一個即時通訊協議。MQTT構建於TCP/IP協議上
怎樣才能高效地使用JQuery
處理 www chrome 它的 this 而且 ont 另一個 對象 1. 使用最新版本的jQuery jQuery的版本更新很快,你應該總是使用最新的版本。因為新版本會改進性能,還有很多新功能。下面就來看看,不同版本的jQuery性能差異有多大。這裏是三條最常見的jQ
PHP的學習路線?如何系統且高效地學習
重點 web 教程 blog 入門 商業 運用 mysql 適合 作者:road‘cover鏈接:https://www.zhihu.com/question/29369715/answer/104456866來源:知乎著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉
如何更加安全、高效地選擇開源項目(內附詳解)
編譯 com 再次 即時聊天 能力 時代 核心 只需要 重新編譯 前言在平時的開發過程中,難免會遇到這樣那樣的難題,或者一些繁瑣且不想純手工完成的功能,對於這些問題,解決的姿勢有很多種,可以通過同事間的交流、上網查資料、去官網找文檔等,隨著開源的推動和完善,尋找合適的開
使用iMindMap高效地結束本周的3個步驟
快速 ads tle 都在 但是 nbsp 重要 href blog 讓周末結束,太容易了。你已經花了一周的時間努力勾劃出多項任務,現在,你的生產力有可能下降。但是,最後幾個小時仍有時間擠壓,為即將到來的一周成功。使用思維導圖和iMindMap進行這個3步儀式,確保星期五下
大神教你如果學習Python爬蟲 如何才能高效地爬取海量數據
Python 爬蟲 分布式 大數據 編程 Python如何才能高效地爬取海量數據我們都知道在互聯網時代,數據才是最重要的,而且如果把數據用用得好的話,會創造很大的價值空間。但是沒有大量的數據,怎麽來創建價值呢?如果是自己的業務每天都能產生大量的數據,那麽數據量的來源問題就解決啦,但是沒有數
vue中點擊空白處隱藏彈框(用指令優雅地實現)
out component 效果 name eight 有變 空白 and 解綁 在寫vue的項目的時候,彈框經常性出現,並要求點擊彈框外面,關閉彈框,那麽如何實現呢?且聽我一一。。。不了,能實現效果就好 <template> <div&g
優雅地實現Android主流圖片加載框架封裝,可無侵入切換框架
ror 要去 out drawable 如果 jpg gre cached square 項目開發中,往往會隨著需求的改變而切換到其它圖片加載框架上去。如果最初代碼設計的耦合度太高,那麽恭喜你,成功入坑了。至今無法忘卻整個項目一行行去復制粘貼被支配的恐懼。:) 那麽是否存在
學會了這套方法論,你就能更高效地解決問題(3)
解決問題的基本步驟 曲凱是四十二章經創始人,他在剛畢業做諮詢師的時候就有個疑問,他的那些客戶都是大公司的大老闆,都有很豐富的行業資源和經驗,為什麼要找他一個剛畢業的人幫他們解決問題呢? 後來他發現,大老闆們跟管理諮詢師最大的區別是,面對問題,大老闆們用的是經驗,而諮詢師有一套思維
學會了這套方法論,你就能更高效地解決問題(2)
解決問題的基本步驟 曲凱是四十二章經創始人,他在剛畢業做諮詢師的時候就有個疑問,他的那些客戶都是大公司的大老闆,都有很豐富的行業資源和經驗,為什麼要找他一個剛畢業的人幫他們解決問題呢? 後來他發現,大老闆們跟管理諮詢師最大的區別是,面對問題,大老闆們用的是經驗,而諮詢師有一套思維
學會了這套方法論,你就能更高效地解決問題(1)
解決問題的基本步驟 曲凱是四十二章經創始人,他在剛畢業做諮詢師的時候就有個疑問,他的那些客戶都是大公司的大老闆,都有很豐富的行業資源和經驗,為什麼要找他一個剛畢業的人幫他們解決問題呢? 後來他發現,大老闆們跟管理諮詢師最大的區別是,面對問題,大老闆們用的是經驗,而諮詢師有一套思維
如何通過 Scrapyd + ScrapydWeb 簡單高效地部署和監控分散式爬蟲專案
需求分析 初級使用者: 只有一臺開發主機 能夠通過 Scrapyd-client 打包和部署 Scrapy 爬蟲專案,以及通過 Scrapyd JSON API 來控制爬蟲,感覺命令列操作太麻煩,希望能夠通過瀏覽器直接部署和執行專案 專業使用者:
如何簡單高效地部署和監控分散式爬蟲專案
需求分析 初級使用者: 只有一臺開發主機 能夠通過 Scrapyd-client 打包和部署 Scrapy 爬蟲專案,以及通過 Scrapyd JSON API 來控制爬蟲,感覺命令列操作太麻煩,希望能夠通過瀏覽器直接部署和執行專案 專業使用者: 有 N 臺雲主
如何高效地有意義的使用電腦?
自從大四開學以來,因為自己預設了考研的目標,所以不論是用電腦搜尋資料還是處理文件、檢視教程,總是搞得速度很快,一頓亂搞,給自己效率很高的假象,然後把剩餘擠出來的時間用於複習中。可是,越是這樣忙忙碌碌的亂搞,效率越低,到頭來,只是騙自己罷了。 一想到自己身處大四,還有不到六個月就要結束這短暫的大學生活
資料結構與演算法之美 課程筆記一 如何抓住重點,系統高效地學習資料結構與演算法?
什麼是資料結構?什麼是演算法? 從廣義上講,資料結構就是指一組資料的儲存結構。演算法就是操作資料的一種方法。 從狹義上講,是指某些著名的資料結構和演算法,比如佇列、棧、堆、二分查詢、動態規劃等。 那資料結構和演算法有什麼關係呢? 資料結構和演算法是相輔相成的。資料結構是為演算法服務的