
[DB] 資料庫分散式事務
資料庫分散式事務
分散式事務
分散式事務就是指事務的參與者、支援事務的伺服器、資源伺服器以及事務管理器分別位於不同的分散式系統的不同節點之上。以上是百度百科的解釋,簡單的說,就是一次大的操作由不同的小操作組成,這些小的操作分佈在不同的伺服器上,且屬於不同的應用,分散式事務需要保證這些小操作要麼全部成功,要麼全部失敗。本質上來說,分散式事務就是為了保證不同資料庫的資料一致性。
事務的ACID特性
- A
原子性: 在整個事務中的所有操作,要麼全部完成,要麼全部不做,沒有中間狀態。對於事務在執行中發生錯誤,所有的操作都會被回滾,整個事務就像從沒被執行過一樣。 - C
一致性:事務的執行必須保證系統的一致性,就拿轉賬為例,A有500元,B有300元,如果在一個事務裡A成功轉給B50元,那麼不管併發多少,不管發生什麼,只要事務執行成功了,那麼最後A賬戶一定是450元,B賬戶一定是350元。 - I
隔離性:所謂的隔離性就是說,事務與事務之間不會互相影響,一個事務的中間狀態不會被其他事務感知。 - D
永續性:所謂的永續性,就是說一單事務完成了,那麼事務對資料所做的變更就完全儲存在了資料庫中,即使發生停電,系統宕機也是如此。
分散式理論
當我們的單個數據庫的效能產生瓶頸的時候,我們可能會對資料庫進行分割槽,這裡所說的分割槽指的是物理分割槽,分割槽之後可能不同的庫就處於不同的伺服器上了,這個時候單個數據庫的ACID已經不能適應這種情況了,而在這種ACID的叢集環境下,再想保證叢集的ACID幾乎是很難達到,或者即使能達到那麼效率和效能會大幅下降,最為關鍵的是再很難擴充套件新的分割槽了,這個時候如果再追求叢集的ACID會導致我們的系統變得很差,這時我們就需要引入一個新的理論原則來適應這種叢集的情況,就是 CAP
CAP定理,那麼CAP定理指的是什麼呢?
CAP定理
CAP定理是由加州大學伯克利分校Eric Brewer教授提出來的,他指出WEB服務無法同時滿足一下3個屬性:
一致性(Consistency) : 客戶端知道一系列的操作都會同時發生(生效)
可用性(Availability) : 每個操作都必須以可預期的響應結束
分割槽容錯性(Partition tolerance) : 即使出現單個元件無法可用,操作依然可以完成
具體地講在分散式系統中,在任何資料庫設計中,一個Web應用至多隻能同時支援上面的兩個屬性。顯然,任何橫向擴充套件策略都要依賴於資料分割槽。因此,設計人員必須在一致性與可用性之間做出選擇。
這個定理在迄今為止的分散式系統中都是適用的! 為什麼這麼說呢?
這個時候有同學可能會把資料庫的2PC(兩階段提交)搬出來說話了。OK,我們就來看一下資料庫的兩階段提交。
對資料庫分散式事務有了解的同學一定知道資料庫支援的2PC,又叫做 XA Transactions。
MySQL從5.5版本開始支援,SQL Server 2005 開始支援,Oracle 7 開始支援。
其中,XA 是一個兩階段提交協議,該協議分為以下兩個階段:
第一階段:事務協調器要求每個涉及到事務的資料庫預提交(precommit)此操作,並反映是否可以提交.
第二階段:事務協調器要求每個資料庫提交資料。
其中,如果有任何一個數據庫否決此次提交,那麼所有資料庫都會被要求回滾它們在此事務中的那部分資訊。這樣做的缺陷是什麼呢? 咋看之下我們可以在資料庫分割槽之間獲得一致性。
如果CAP 定理是對的,那麼它一定會影響到可用性。
如果說系統的可用性代表的是執行某項操作相關所有元件的可用性的和。那麼在兩階段提交的過程中,可用性就代表了涉及到的每一個數據庫中可用性的和。我們假設兩階段提交的過程中每一個數據庫都具有99.9%的可用性,那麼如果兩階段提交涉及到兩個資料庫,這個結果就是99.8%。根據系統可用性計算公式,假設每個月43200分鐘,99.9%的可用性就是43157分鐘, 99.8%的可用性就是43114分鐘,相當於每個月的宕機時間增加了43分鐘。
以上,可以驗證出來,CAP定理從理論上來講是正確的,CAP我們先看到這裡,等會再接著說。
BASE理論
在分散式系統中,我們往往追求的是可用性,它的重要程式比一致性要高,那麼如何實現高可用性呢? 前人已經給我們提出來了另外一個理論,就是BASE理論,它是用來對CAP定理進行進一步擴充的。BASE理論指的是:
Basically Available(基本可用)
Soft state(軟狀態)
Eventually consistent(最終一致性)
BASE理論是對CAP中的一致性和可用性進行一個權衡的結果,理論的核心思想就是:我們無法做到強一致,但每個應用都可以根據自身的業務特點,採用適當的方式來使系統達到最終一致性(Eventual consistency)。
有了以上理論之後,我們來看一下分散式事務的問題。
分散式事務的產生的原因
資料庫分庫分表
當資料庫單表一年產生的資料超過1000W,那麼就要考慮分庫分表,具體分庫分表的原理在此不做解釋,以後有空詳細說,簡單的說就是原來的一個數據庫變成了多個數據庫。這時候,如果一個操作既訪問01庫,又訪問02庫,而且要保證資料的一致性,那麼就要用到分散式事務。
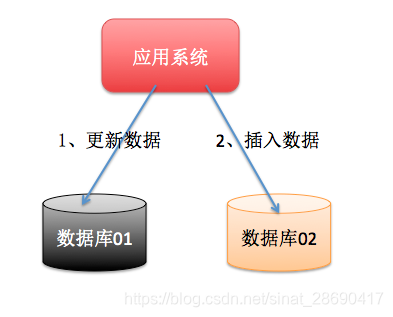
應用SOA化
所謂的SOA化,就是業務的服務化。比如原來單機支撐了整個電商網站,現在對整個網站進行拆解,分離出了訂單中心、使用者中心、庫存中心。對於訂單中心,有專門的資料庫儲存訂單資訊,使用者中心也有專門的資料庫儲存使用者資訊,庫存中心也會有專門的資料庫儲存庫存資訊。這時候如果要同時對訂單和庫存進行操作,那麼就會涉及到訂單資料庫和庫存資料庫,為了保證資料一致性,就需要用到分散式事務。
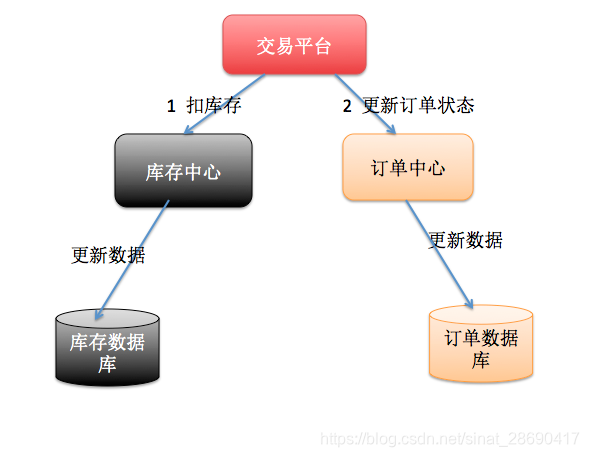
以上兩種情況表象不同,但是本質相同,都是因為要操作的資料庫變多了!
分散式事務解決方案
- 基於XA協議的兩階段提交
XA是一個分散式事務協議,由Tuxedo提出。XA中大致分為兩部分:事務管理器和本地資源管理器。其中本地資源管理器往往由資料庫實現,比如Oracle、DB2這些商業資料庫都實現了XA介面,而事務管理器作為全域性的排程者,負責各個本地資源的提交和回滾。XA實現分散式事務的原理如下:
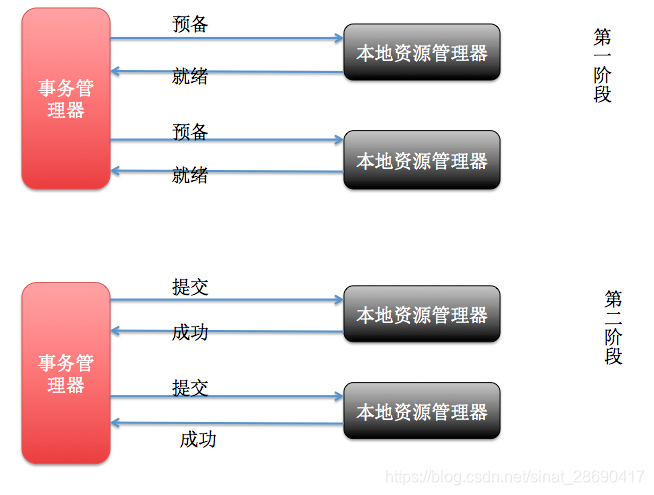
總的來說,XA協議比較簡單,而且一旦商業資料庫實現了XA協議,使用分散式事務的成本也比較低。但是,XA也有致命的缺點,那就是效能不理想,特別是在交易下單鏈路,往往併發量很高,XA無法滿足高併發場景。XA目前在商業資料庫支援的比較理想,在mysql資料庫中支援的不太理想,mysql的XA實現,沒有記錄prepare階段日誌,主備切換回導致主庫與備庫資料不一致。許多nosql也沒有支援XA,這讓XA的應用場景變得非常狹隘。
優缺點
優點: 儘量保證了資料的強一致,適合對資料強一致要求很高的關鍵領域。(其實也不能100%保證強一致)
缺點: 實現複雜,犧牲了可用性,對效能影響較大,不適合高併發高效能場景。
- 訊息事務+最終一致性
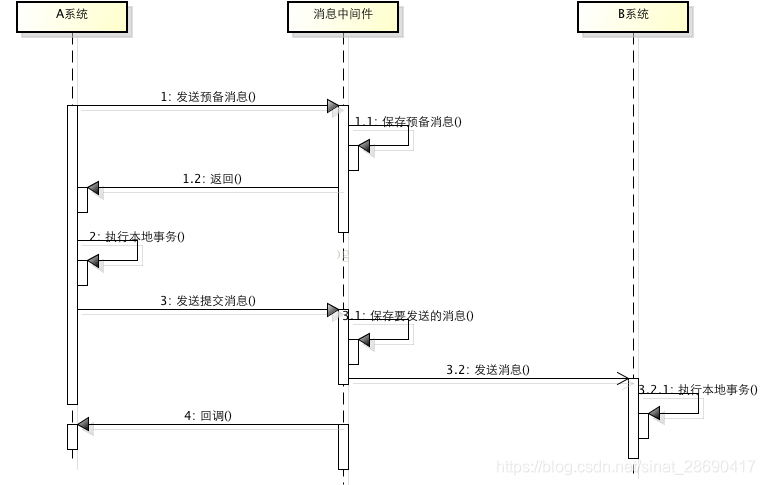
所謂的訊息事務就是基於訊息中介軟體的兩階段提交,本質上是對訊息中介軟體的一種特殊利用,它是將本地事務和發訊息放在了一個分散式事務裡,保證要麼本地操作成功成功並且對外發訊息成功,要麼兩者都失敗,開源的RocketMQ就支援這一特性,具體原理如下:
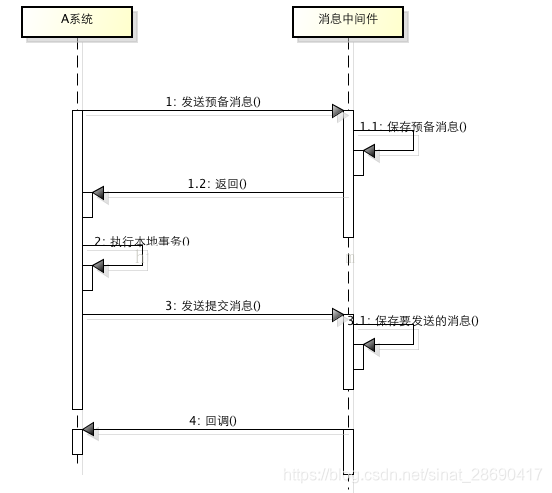
1、A系統向訊息中介軟體傳送一條預備訊息
2、訊息中介軟體儲存預備訊息並返回成功
3、A執行本地事務
4、A傳送提交訊息給訊息中介軟體
通過以上4步完成了一個訊息事務。對於以上的4個步驟,每個步驟都可能產生錯誤,下面一一分析:
- 步驟一出錯,則整個事務失敗,不會執行A的本地操作
- 步驟二出錯,則整個事務失敗,不會執行A的本地操作
- 步驟三出錯,這時候需要回滾預備訊息,怎麼回滾?答案是A系統實現一個訊息中介軟體的回撥介面,訊息中介軟體會去不斷執行回撥介面,檢查A事務執行是否執行成功,如果失敗則回滾預備訊息
- 步驟四出錯,這時候A的本地事務是成功的,那麼訊息中介軟體要回滾A嗎?答案是不需要,其實通過回撥介面,訊息中介軟體能夠檢查到A執行成功了,這時候其實不需要A發提交訊息了,訊息中介軟體可以自己對訊息進行提交,從而完成整個訊息事務
基於訊息中介軟體的兩階段提交往往用在高併發場景下,將一個分散式事務拆成一個訊息事務(A系統的本地操作+發訊息)+B系統的本地操作,其中B系統的操作由訊息驅動,只要訊息事務成功,那麼A操作一定成功,訊息也一定發出來了,這時候B會收到訊息去執行本地操作,如果本地操作失敗,訊息會重投,直到B操作成功,這樣就變相地實現了A與B的分散式事務。原理如下:
雖然上面的方案能夠完成A和B的操作,但是A和B並不是嚴格一致的,而是最終一致的,我們在這裡犧牲了一致性,換來了效能的大幅度提升。當然,這種玩法也是有風險的,如果B一直執行不成功,那麼一致性會被破壞,具體要不要玩,還是得看業務能夠承擔多少風險。
本地訊息表(非同步確保)
本地訊息表這種實現方式應該是業界使用最多的,其核心思想是將分散式事務拆分成本地事務進行處理,這種思路是來源於ebay。我們可以從下面的流程圖中看出其中的一些細節:
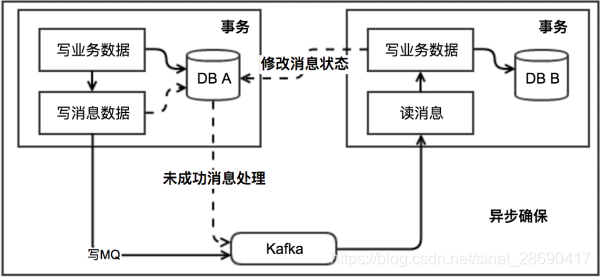
基本思路就是:
訊息生產方,需要額外建一個訊息表,並記錄訊息傳送狀態。訊息表和業務資料要在一個事務裡提交,也就是說他們要在一個數據庫裡面。然後訊息會經過MQ傳送到訊息的消費方。如果訊息傳送失敗,會進行重試傳送。
訊息消費方,需要處理這個訊息,並完成自己的業務邏輯。此時如果本地事務處理成功,表明已經處理成功了,如果處理失敗,那麼就會重試執行。如果是業務上面的失敗,可以給生產方傳送一個業務補償訊息,通知生產方進行回滾等操作。
生產方和消費方定時掃描本地訊息表,把還沒處理完成的訊息或者失敗的訊息再發送一遍。如果有靠譜的自動對賬補賬邏輯,這種方案還是非常實用的。
這種方案遵循BASE理論,採用的是最終一致性,筆者認為是這幾種方案裡面比較適合實際業務場景的,即不會出現像2PC那樣複雜的實現(當呼叫鏈很長的時候,2PC的可用性是非常低的),也不會像TCC那樣可能出現確認或者回滾不了的情況。
優點: 一種非常經典的實現,避免了分散式事務,實現了最終一致性。
缺點: 訊息表會耦合到業務系統中,如果沒有封裝好的解決方案,會有很多雜活需要處理。
MQ 事務訊息
有一些第三方的MQ是支援事務訊息的,比如RocketMQ,他們支援事務訊息的方式也是類似於採用的二階段提交,但是市面上一些主流的MQ都是不支援事務訊息的,比如 RabbitMQ 和 Kafka 都不支援。
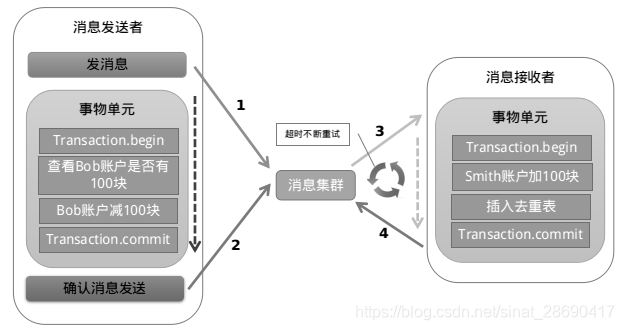
以阿里的 RocketMQ 中介軟體為例,其思路大致為:
第一階段Prepared訊息,會拿到訊息的地址。
第二階段執行本地事務,第三階段通過第一階段拿到的地址去訪問訊息,並修改狀態。
也就是說在業務方法內要想訊息佇列提交兩次請求,一次傳送訊息和一次確認訊息。如果確認訊息傳送失敗了RocketMQ會定期掃描訊息叢集中的事務訊息,這時候發現了Prepared訊息,它會向訊息傳送者確認,所以生產方需要實現一個check介面,RocketMQ會根據傳送端設定的策略來決定是回滾還是繼續傳送確認訊息。這樣就保證了訊息傳送與本地事務同時成功或同時失敗。
優點: 實現了最終一致性,不需要依賴本地資料庫事務。
缺點: 實現難度大,主流MQ不支援,沒有.NET客戶端,RocketMQ事務訊息部分程式碼也未開源。
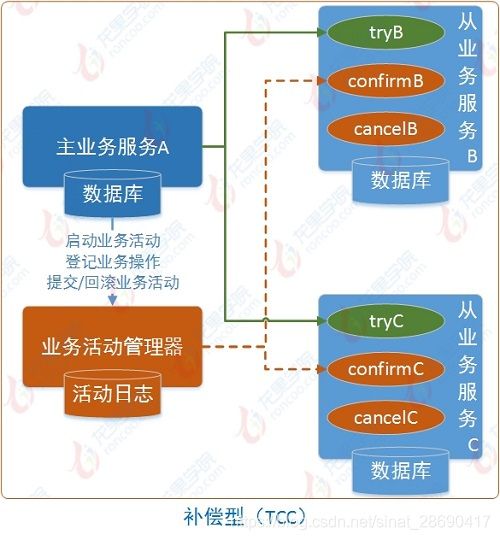
- TCC程式設計模式
所謂的TCC程式設計模式,也是兩階段提交的一個變種。TCC提供了一個程式設計框架,將整個業務邏輯分為三塊:Try、Confirm和Cancel三個操作。以線上下單為例,Try階段會去扣庫存,Confirm階段則是去更新訂單狀態,如果更新訂單失敗,則進入Cancel階段,會去恢復庫存。總之,TCC就是通過程式碼人為實現了兩階段提交,不同的業務場景所寫的程式碼都不一樣,複雜度也不一樣,因此,這種模式並不能很好地被複用。
TCC 採用的補償機制,其核心思想是:針對每個操作,都要註冊一個與其對應的確認和補償(撤銷)操作。它分為三個階段:
-
Try 階段主要是對業務系統做檢測及資源預留
-
Confirm 階段主要是對業務系統做確認提交,Try階段執行成功並開始執行 Confirm階段時,預設 Confirm階段是不會出錯的。即:只要Try成功,Confirm一定成功。
-
Cancel 階段主要是在業務執行錯誤,需要回滾的狀態下執行的業務取消,預留資源釋放。
舉個例子,假入 Bob 要向 Smith 轉賬,思路大概是:
我們有一個本地方法,裡面依次呼叫
1、首先在 Try 階段,要先呼叫遠端介面把 Smith 和 Bob 的錢給凍結起來。
2、在 Confirm 階段,執行遠端呼叫的轉賬的操作,轉賬成功進行解凍。
3、如果第2步執行成功,那麼轉賬成功,如果第二步執行失敗,則呼叫遠端凍結介面對應的解凍方法 (Cancel)。
優缺點
優點: 跟2PC比起來,實現以及流程相對簡單了一些,但資料的一致性比2PC也要差一些
缺點: 缺點還是比較明顯的,在2,3步中都有可能失敗。TCC屬於應用層的一種補償方式,所以需要程式設計師在實現的時候多寫很多補償的程式碼,在一些場景中,一些業務流程可能用TCC不太好定義及處理。
總結
分散式事務,本質上是對多個數據庫的事務進行統一控制,按照控制力度可以分為:不控制、部分控制和完全控制。不控制就是不引入分散式事務,部分控制就是各種變種的兩階段提交,包括上面提到的訊息事務+最終一致性、TCC模式,而完全控制就是完全實現兩階段提交。部分控制的好處是併發量和效能很好,缺點是資料一致性減弱了,完全控制則是犧牲了效能,保障了一致性,具體用哪種方式,最終還是取決於業務場景。作為技術人員,一定不能忘了技術是為業務服務的,不要為了技術而技術,針對不同業務進行技術選型也是一種很重要的能力!
總結下解決方案:
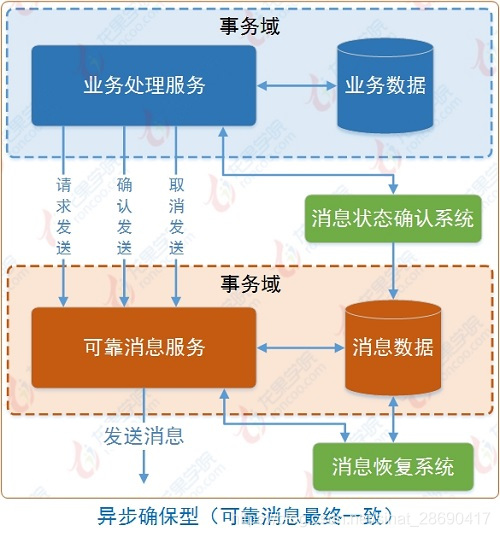
一、結合MQ訊息中介軟體實現的可靠訊息最終一致性
二、TCC補償性事務解決方案
三、最大努力通知型方案
第一種方案:可靠訊息最終一致性,需要業務系統結合MQ訊息中介軟體實現,在實現過程中需要保證訊息的成功傳送及成功消費。即需要通過業務系統控制MQ的訊息狀態
-
第二種方案:TCC事務補償型,分為三個階段TRYING-CONFIRMING-CANCELING。每個階段做不同的處理。- TRYING 階段主要是對業務系統進行檢測及資源預留
- CONFIRMING 階段是做業務提交,通過TRYING階段執行成功後,再執行該階段。預設如果TRYING階段執行成功,CONFIRMING就一定能成功。
- CANCELING 階段是回對業務做回滾,在TRYING階段中,如果存在分支事務TRYING失敗,則需要呼叫CANCELING將已預留的資源進行釋放。
以上所有的操作需要滿足冪等性,冪等性的實現方式可以是:
1、通過唯一鍵值做處理,即每次呼叫的時候傳入唯一鍵值,通過唯一鍵值判斷業務是否被操作,如果已被操作,則不再重複操作
2、通過狀態機處理,給業務資料設定狀態,通過業務狀態判斷是否需要重複執行
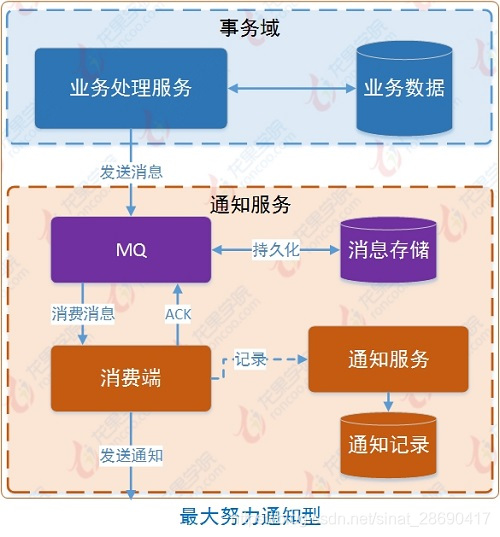
第三種方案:最大努力通知型(按規律進行通知,不保證資料一定能通知成功,但會提供可查詢操作介面進行核對)這種方案主要用在與第三方系統通訊時,比如:呼叫微信或支付寶支付後的支付結果通知。這種方案也是結合MQ進行實現,例如:通過MQ傳送http請求,設定最大通知次數。達到通知次數後即不再通知。
REFRENCES
- 深入理解分散式事務
- 分散式事務解決方案的效果演示(結合支付系統真實應用場景
- 微服務架構的分散式事務解決方案
- 分散式事務的一種實現方式–狀態流轉
- 微服務架構的分散式事務解決方案(Dubbo分散式事務處理)
- 聊聊分散式事務,再說說解決方案
更多

掃碼關注或搜尋架構探險之道獲取最新文章,不積跬步無以至千里,堅持每週一更,堅持技術分享^_^ !