
基於spark的svm演算法實現
核函式
核函式在處理複雜資料時效果顯著,它的做法是將某一個維度的線性不可分資料採取核函式進行特徵空間的隱式對映到高維空間,從而在高維空間將資料轉化為線性可分,最後迴歸到原始維度空間實施分類的過程,常見的幾個核函式如下:
多項式核:
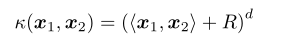
高斯核(徑向基函式):
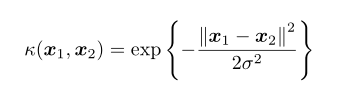
線性核:
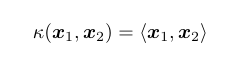
即是兩個矩陣空間的內積。
SMO演算法流程
SMO的主要兩個步驟就是:
1、選擇需要更新的一對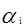
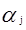
2、將目標函式對
以上是兩個基本步驟,實現具體推到公式如下:
所需要收到的約束條件為:
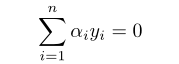
同時更新
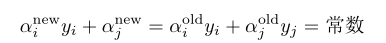
消去
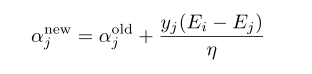
其中
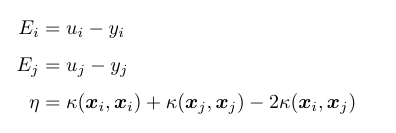
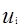
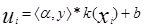
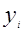
之後考慮約束條件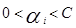

約束條件的線性表示
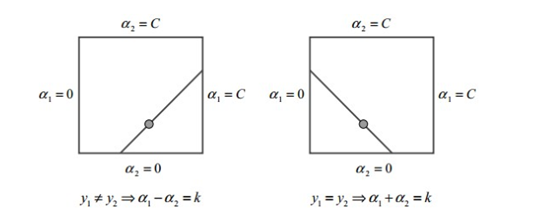
依據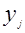
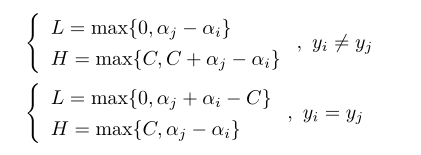
對於
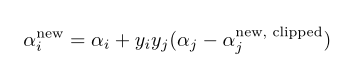
對於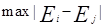
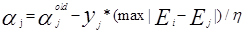
而b的更新為

其中
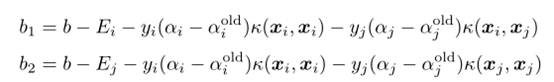
每次更新完和都需要重新計算b以及對應的和
有了以上的公式,程式碼實現就比較簡單了。演算法實現
完整的Platt-smo演算法實現入口
public SvmResult plattSmo(final SvmResult svmResult) { double b = svmResult.getB(); double[] alphas = svmResult.getAlphas(); for(int i=0;i<featuresArray.length;i++){ double ei = this.calcEk(i, alphas, b); if (((lablesArray[i] * ei < -tolerFactor) && (alphas[i] < penaltyFactor)) || ((lablesArray[i] * ei > tolerFactor) && (alphas[i] > 0))) { double[] jSelected = this.selectJ(i, ei, alphas, b); //啟發式實現j的選擇 int j = (int) jSelected[0]; double ej = jSelected[1]; double alphaIold = alphas[i]; double alphaJold = alphas[j]; double L = 0; double H = 0; //邊界計算 if (lablesArray[i] != lablesArray[j]) { L = Math.max(0, alphas[j] - alphas[i]); H = Math.min(penaltyFactor, penaltyFactor + alphas[j] - alphas[i]); } else { L = Math.max(0, alphas[j] + alphas[i] - penaltyFactor); H = Math.min(penaltyFactor, alphas[j] + alphas[i]); } if (L == H) { logger.info("L==H"); } else { double eta = (2.0 * this.kernelArray[i][j] - this.kernelArray[i][i] - this.kernelArray[j][j]); if (eta >= 0) { logger.info("eta>=0"); } else { //雙向調整alphas[j]遞減 alphas[j] -= lablesArray[j] * (ei - ej) / eta; if (alphas[j] > H) { alphas[j] = H; } if (L > alphas[j]) { alphas[j] = L; } //更新ej this.updateEk(j, alphas, b); if (Math.abs(alphas[j] - alphaJold) < 0.00001) { logger.info("j not moving enough"); } else { //雙向調整alphas[i]遞減 alphas[i] += lablesArray[j] * lablesArray[i] * (alphaJold - alphas[j]); //更新ei this.updateEk(i, alphas, b); //計算b double b1 = b - ei- lablesArray[i]*(alphas[i]-alphaIold)*this.kernelArray[i][i] - lablesArray[j]*(alphas[j]-alphaJold)*this.kernelArray[i][j]; double b2 = b - ej- lablesArray[i]*(alphas[i]-alphaIold)*this.kernelArray[i][j] - lablesArray[j]*(alphas[j]-alphaJold)*this.kernelArray[j][j]; if ((0 < alphas[i]) && (penaltyFactor > alphas[i])){ b = b1; }else if ((0 < alphas[j]) && (penaltyFactor > alphas[j])){ b = b2; }else{ b = (b1 + b2)/2.0; } } } } } } return new SvmResult(b, alphas); }
在以上演算法裡面重點關注是j的選擇,
J的選擇
private double[] selectJ(int i,double ei,double[] alphas,double b){ int maxK = -1; double maxDeltaE = 0; double ej = 0; int j = -1; double[] eiArray= new double[2]; eiArray[0] = 1d; eiArray[1] = ei; this.eCache[i] = eiArray; boolean hasValidEcacheList = false; for(int k=0;k<this.eCache.length;k++){ if(this.eCache[k][0] > 0){ if(k == i){ continue; } hasValidEcacheList = true; if(k == this.m){ k = m-1; } double ek = this.calcEk(k, alphas, b); double deltaE = Math.abs(ei - ek); if (deltaE > maxDeltaE){ maxK = k; maxDeltaE = deltaE; ej = ek; } } } j = maxK; if(!hasValidEcacheList || j == -1){ j = this.selectJRandom(i); ej = this.calcEk(j, alphas, b); } if(j == this.m){ j = m-1; } return new double[]{j,ej}; }
首選採取啟發式選擇j,通過計算deltaE的最大值來逼近j的選擇,如果選擇不到就隨機選擇一個j值,在j選擇裡面有一個Ek的計算方式
private double calcEk(int k,double[] alphas,double b){
Matrix alphasMatrix = new Matrix(alphas);
Matrix lablesMatrix = new Matrix(lablesArray);
Matrix kMatrix = new Matrix(this.kernelArray[k]);
double fXk = alphasMatrix.multiply(lablesMatrix).dotMultiply(kMatrix.transpose()).dotValue() + b;
double ek = fXk - (float)this.lablesArray[k];
return ek;
}
下面再介紹一下核函式計算方式,本文主要採取徑向基函式(RBF)實現,如下
public double[] kernelTrans(double[][] featuresArray,double[] featuresIArray){
int mCount = featuresArray.length;
double[] kernelTransI = new double[mCount];
Matrix featuresMatrix = new Matrix(featuresArray);
Matrix featuresIMatrix = new Matrix(featuresIArray);
if(trainFactorMap.get("KT").equals("lin")){
Matrix result = featuresMatrix.dotMultiply(featuresIMatrix.transpose());
kernelTransI = result.transpose().values()[0];
}else if(trainFactorMap.get("KT").equals("rbf")){
double rbfDelta = (double)trainFactorMap.get("rbfDelta");
for(int j=0;j<mCount;j++){
Matrix xj = new Matrix(featuresArray[j]);
Matrix delta = xj.reduce(featuresIMatrix);
double deltaValue = delta.dotMultiply(delta.transpose()).dotValue();
kernelTransI[j] = Math.exp((-1.0*deltaValue)/(2*Math.pow(rbfDelta, 2)));
}
}
return kernelTransI;
}
最後看下測試程式碼實現
double[][] datasvs = new double[m][d[0].length];
double[] labelsvs = new double[m];
double[] alphassvs = new double[m];
int n = 0;
for(int i=0;i<alphas.length;i++){
if(alphas[i] != 0){
datasvs[n] = d[i];
labelsvs[n] = l[i];
alphassvs[n] = alphas[i];
n++;
}
}
//model test
int errorCount = 0;
for(int i=0;i<d.length;i++){
double[] kernelTransI = learner.kernelTrans(datasvs, d[i]);
Matrix kernelTransIM = new Matrix(kernelTransI);
Matrix labelsvsM = new Matrix(labelsvs);
Matrix alphassvsM = new Matrix(alphassvs);
double predict = kernelTransIM.dotMultiply(labelsvsM.multiply(alphassvsM).transpose()).dotValue() + b;
System.out.println(i+"\t"+predict+"\t"+l[i]);
if(AdaBoost.sigmoid(predict) != l[i]){
errorCount++;
}
}
測試程式碼是首先找出所有的支援向量,並提取支援向量下的特徵向量和標籤向量,採取核函式進行隱式對映,最後計算預測值。
訓練結果
本文采取100個二維平面無法線性可分的資料集合,如下
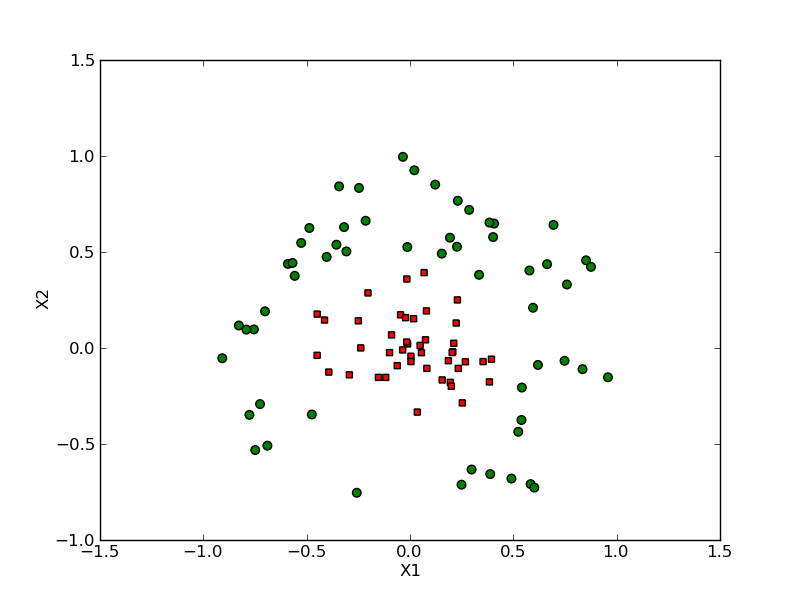
通過徑向基函式對映後採取支援向量預測計算得到的可分平面如下
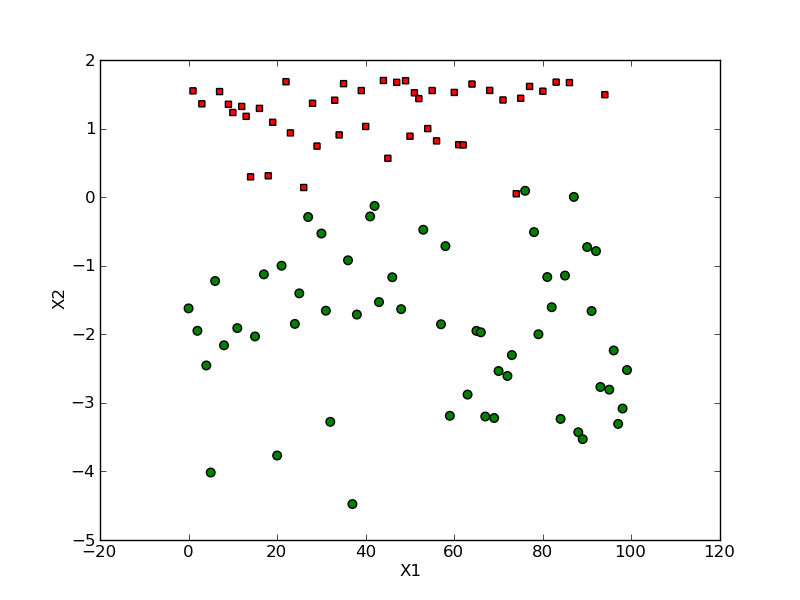
本演算法100個數據訓練準確率可達98%。
注:本文演算法均來自Peter Harrington的《Machine Learning in action》
相關推薦
Python基於Kmeans演算法實現文字聚類的簡單練習
接觸機器學習時間不長,也一直有興趣研究這方面的演算法。最近在學習Kmeans演算法,但由於工作的原因無法接觸到相關的專案實戰。為了理清思路、熟悉程式碼,在參照了幾篇機器學習大神的博文後,做了一個簡單的Kmeans演算法的簡單練習。作為一枚機器學習的門外漢,對於文中的一些錯誤和
基於KNN演算法實現的單個圖片數字識別
Test.csv中第1434行,圖片數字值為”0“,最終歸類為0,正確。 Test.csv中第14686行,圖片數字值為”8“,最終歸類為8,正確。 4原始碼 最後附上本次基於KNN思想實現單個數字圖片識別的全部原始碼。 /** * @Title: DigitClassification.java
R語言基於KNN演算法實現蘑菇毒性識別
R語言:基於KNN演算法實現蘑菇毒性識別 平臺:Ubuntu16.04LTS RStudio 資料集介紹: trainData.txt 訓練資料集。包含4339個樣本(行),每個樣本共6個特徵(列),其中前5列為蘑菇樣本的特徵值,第6列為蘑菇的毒性屬性,0表示無毒,1
基於snowflake演算法實現發號器
(2)snowflake的結構如下(每部分用-分開): 0 - 0000000000 0000000000 0000000000 0000000000 000 - 000 - 00000 - 000000000000 一共加起來剛好64位,為一個Long型。(轉換成字串長度為18) snowflak
Hadoop偽分佈安裝詳解+MapReduce執行原理+基於MapReduce的KNN演算法實現
本篇部落格將圍繞Hadoop偽分佈安裝+MapReduce執行原理+基於MapReduce的KNN演算法實現這三個方面進行敘述。 (一)Hadoop偽分佈安裝 1、簡述Hadoop的安裝模式中–偽分佈模式與叢集模式的區別與聯絡. Hadoop的安裝方式有三種:本地模式,偽分佈模式
基於使用者的協同過濾演算法實現的商品推薦系統
基於使用者的協同過濾演算法實現的商品推薦系統 專案介紹 商品推薦是針對使用者面對海量的商品資訊而不知從何下手的一種解決方案,它可以根據使用者的喜好,年齡,點選量,購買量以及各種購買行為來為使用者推薦合適的商品。在本專案中採用的是基於使用者的協同過濾的推薦演算法來實現
DL之RNN:人工智慧為你寫歌詞(林夕寫給陳奕迅)——基於TF利用RNN演算法實現【機器為你作詞】、訓練&測試過程全記錄
DL之RNN:人工智慧為你寫歌詞(林夕寫給陳奕迅)——基於TF利用RNN演算法實現【機器為你作詞】、訓練&測試過程全記錄 輸出結果 1、test01 你的揹包 一個人過我 誰不屬了 不甘心 不能回頭 我的揹包載管這個 誰讓我們是要不可 但求跟你過一生 你把我灌醉 即使嘴角
DL之RNN:人工智慧為你寫周董歌詞——基於TF利用RNN演算法實現【機器為你作詞】、訓練&測試過程全記錄
DL之RNN:人工智慧為你寫周董歌詞——基於TF利用RNN演算法實現~機器為你作詞~、訓練&測試過程全記錄 輸出結果 1、test01 夕海 而我在等待之光 在月前被畫面 而我心碎 你的個世紀 你的時間 我在趕過去 我的不是你不會感覺媽媽 我說不要不要說 我會愛你 我不要你不
【機器學習演算法實現】主成分分析 PCA ——基於python+numpy
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
基於System Generator的CORDIC演算法實現
基於System Generator的CORDIC演算法實現 文章目錄 基於System Generator的CORDIC演算法實現 一、CORDIC演算法實現 1、簡介 2、CORDIC演算法模式 2、搭建CORDIC模組系統
【機器學習演算法實現】logistic迴歸 基於Python和Numpy函式庫
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
【機器學習演算法實現】kNN演算法 手寫識別——基於Python和NumPy函式庫
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Python基於K-均值、RLS演算法實現RBF神經網路(神經網路與機器學習 第五章 計算機實驗)
1、生成資料集 class moon_data_class(object): def __init__(self,N,d,r,w): self.N=N self.w=w self.d=d self.r=r
基於sciket-learn實現線性迴歸演算法
線性迴歸演算法主要用來解決迴歸問題,是許多強大的非線性模型的基礎,無論是簡單線性迴歸,還是多元線性迴歸,思想都是一樣的,假設我們找到了最佳擬合方程(對於簡單線性迴歸,多元線性迴歸對應多個特徵作為一組向量)y=ax+b,則對於每一個樣本點xi,根據我們的直線方程,預測值為y^i = axi + b,真
基於scikit-learn實現k近鄰演算法(kNN)與超引數的除錯
前一篇關於kNN的部落格介紹了演算法的底層實現,這片部落格讓我們一起看一看基於scikit-learn如何快速的實現kNN演算法。 scikit-learn內建了很多資料集,就不用我們自己編造假資料了,下面我們分別選用鳶尾花和手寫數字識別的資料集。 首先匯入需要的庫 from sklea
TF之NN:基於TF利用NN演算法實現根據三個自變數預測一個因變數的迴歸問題
TF之NN:基於TF利用NN演算法實現根據三個自變數預測一個因變數的迴歸問題 實驗資料 說明:利用前四年的資料建立迴歸模型,並對第五年進行預測。 輸出結果 loss is: 913.6623 loss is: 781206160000.0
[文件和原始碼分享]C++實現的基於α-β剪枝演算法的井字棋遊戲
“井字棋”遊戲(又叫“三子棋”),是一款十分經典的益智小遊戲,操作簡單,娛樂性強。兩個玩家,一個打圈(O),一個打叉(X),輪流在3乘3的格上打自己的符號,最先以橫、直、斜連成一線則為勝。 如果雙方都下得正確無誤,將得和局。這種遊戲實際上是由第一位玩家所控制,第一位玩家是攻,第二位玩家是守。 這種遊戲的變
常見排序演算法記錄(基於java語言實現)
桶排序 public class TongPaiXu1 { public static void main(String[] args) { // 桶排序 int[] m = {1, 3, 6, 3, 4,
非對稱加密過程詳解(基於RSA非對稱加密演算法實現)
1、非對稱加密過程: 假如現實世界中存在A和B進行通訊,為了實現在非安全的通訊通道上實現資訊的保密性、完整性、可用性(即資訊保安的三個性質),A和B約定使用非對稱加密通道進行通訊,具體過程如下: 說明: 國內目前使用雙證書體系,即
基於LVD、貝葉斯模型演算法實現的電商行業商品評論與情感分析案例
一、 專案需求 現在大家進行網購,在購物之前呢,肯定會看下相關商品的評論,看下好評和差評,然後再綜合衡量,最後才會決定是否購買相關的商品。對一個指定商品,生產商,賣家,買家認同該商品的哪些優點/不認同