
歸併演算法及其優化
歸併排序演算法思想:分而治之
- 分解:把長度為n 的待排序列分解成 兩個長度為n/2 的序列
- 治理:對每個子序列分別呼叫歸併排序,進行遞迴操作。當子序列長度為1 時,序列本身有序,停止遞迴
- 合併:合併每個排序好的子序列
歸併排序採用分治法(Divide and Conquer)的一個應用,先使每個子序列有序,再使子序列段有序。需要一個輔助陣列,時間複雜度是O(nlogn)
1,原地歸併排序
因為需要一個輔助陣列,所以歸併排序的空間複雜度是O(n),對其 進行優化後可以進行原地排序,額外空間為O(1)。
原地歸併排序對Sort()函式進行優化,利用的核心思想是“反轉記憶體”的變體,即“交換兩段相鄰記憶體塊”
在瞭解原地歸併的思想之前,先回憶一下一般的歸併演算法,先是將有序子序列分別放入臨時陣列,然後設定兩個指標依次從兩個子序列的開始尋找最小元素放入歸併陣列中;那麼原地歸併的思想亦是如此,就是歸併時要保證指標之前的數字始終是兩個子序列中最小的那些元素。
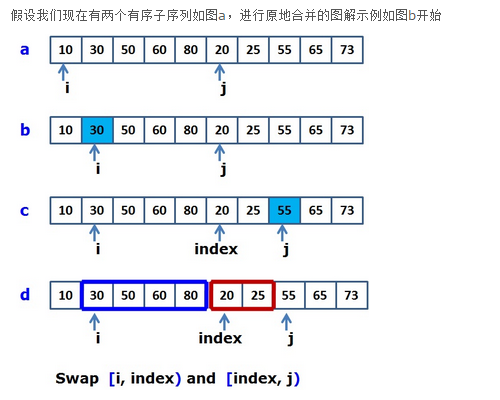
- 首先,圖b ,第一個子序列的值與第二個子序列的第一個值20比較,如果序列一的值小於20,則指標i向後移,直到找到比20大的值,即指標i移動到30;經過b,我們知道指標i之前的值一定是兩個子序列中最小的塊。
- 圖c,先用一個臨時指標記錄j的位置,然後用第二個子序列的值與序列一i所指的值30比較,如果序列二的值小於30,則j後移,直到找到比30大的值,即j移動到55的下標;
- 圖d,經過圖c的過程,我們知道陣列塊 [index, j) 中的值一定是全部都小於指標i所指的值30,即陣列塊 [index, j) 中的值全部小於陣列塊 [i, index) 中的值,為了滿足原地歸併的原則:始終保證指標i之前的元素為兩個序列中最小的那些元素,即i之前為已經歸併好的元素。
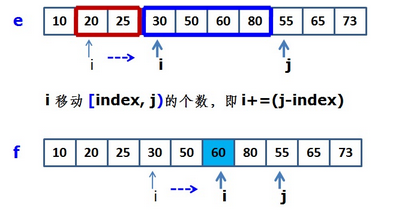
- 交換這兩塊陣列的記憶體塊,交換後i移動相應的步數,這個“步數”實際就是該步歸併好的數值個數,即陣列塊[index, j)的個數。
- 得到下圖:
2,插入歸併
歸併排序的時間複雜度為O(nlgn),一般來講,基於從單個記錄開始兩兩歸併的排序並不是特別提倡,一種比較常用的改進就是結合插入排序,即先利用插入排序獲得較長的有序子序列,然後再兩兩歸併
原因的:儘管插入排序的最壞情況是O(n^2),看起來大於歸併的最壞情況O(nlgn),但通常情況下,由於插入排序的常數因子使得它在n比較小的情況下能執行的更快一些,因此,歸併時,當子問題足夠小時,採用插入排序是比較合適的。
只需要在Merge 中判斷當子序列長度小於某個值的時候採用InsertSort,大於這個值正常採用Merge排序
只需要在Merge裡面進行修改:
public void Merge(int[] arr,int[] temp,int l,int r){
if(r-l<1) return;
if(r-l+1<INSERT_BOUND){
//這裡在下面的劃分遞迴中,只要滿足了條件,就會進入插入排序
insertSort(arr,l,r);
}else{
int mid = (l+r)/2;
internalMergeSort(arr,temp,l,mid);
internalMergeSort(arr,temp,mid+1,r);
Sort(arr,temp,l,mid,r);
}
}複雜度分析
下面分析下插入歸併排序最壞情況下的複雜度:假設整個序列長度為n,當子序列長度為k時,採取插入排序策略,這樣一共有n/k個子序列。
子序列完成排序複雜度:最壞情況下,n/k個子序列完成排序的時間複雜度為O(nk)。證明:每個子序列完成插入排序複雜度為O(k^2),一共n/k個子序列,故為O(nk)。
子序列完成合併複雜度:最壞情況下,合併兩個子序列的時間複雜度為O(n),一共有n/k個子序列,兩兩合併,共需要lg(n/k)步的合併,所以這些子序列完成合並的複雜度為O(nlg(n/k))。
改進後的插入歸併排序的最壞情況的複雜度為O(nk+nlg(n/k)),這裡k的最大取值不能超過lgn,顯然如果k大於lgn,複雜度就不是與歸併一個級別了,也就是說假設一個1000長度的陣列,採用插入策略排序子序列時,子序列的最大長度不能超過10。
相關推薦
歸併演算法及其優化
歸併排序演算法思想:分而治之 分解:把長度為n 的待排序列分解成 兩個長度為n/2 的序列 治理:對每個子序列分別呼叫歸併排序,進行遞迴操作。當子序列長度為1 時,序列本身有序,停止遞迴 合併:合併每個排序好的子序列 歸併排序採用分治法(Divide
O(n*logn)級別的演算法之一(歸併排序及其優化)
原理: 設兩個有序的子序列(相當於輸入序列)放在同一序列中相鄰的位置上:array[low..m],array[m + 1..high],先將它們合併到一個區域性的暫存序列 temp (相當於輸出序列)中,待合併完成後將 temp 複製回 array[low..high]中,從而完成排序。 在具體的合併過
菜鷄日記——KMP演算法及其優化與應用
一、什麼是KMP演算法 KMP演算法,全稱Knuth-Morris-Pratt演算法,由三位科學家的名字組合命名,是一種效能高效的字串匹配演算法。假設有主串S與模式串T,KMP演算法可以線上性的時間內匹配出S中的T,甚至還能處理由多個模式串組成的字典的匹配問題。 二、KMP演算法原理及實現
Bellman-Ford演算法及其優化
與Dijkstra演算法一樣,我們定義一幅加權有向圖的結構如下: //帶權有向圖 struct EdgeWeightedDigraph { size_t V; //頂點數 size_t E; //邊數 map<int, forward_list<tuple
Prim演算法及其優化
來源自我的部落格 #include <stdio.h> int main(){ int n, m; scanf("%d%d", &n, &m); int e[10][10]; // 任意兩點間直接距
氣泡排序演算法及其優化(Python)
#!/usr/bin/python3 # -*- coding: UTF-8 -*- import random ''' 氣泡排序演算法及其優化 氣泡排序的基本特徵是隻能交換相鄰的元素。 從下邊界開始,一趟掃描下來,可以把當前最大值頂到上邊界; 如果沒有發生交換操作,則表
氣泡排序演算法及其優化
對於上面的序列我們發現,含有10個元素的序列需要45次比較(第一趟9次,第二趟8次,第三趟7次,....... ,第九趟1次),那麼真的需要45次嗎?對於下面的這種序列{1,2,4,5,8,9,10,14,15,13},使用上面的演算法也是45次,但觀察發現該序列大部分是有序的,第一趟將15沉底放置最後,得
K-means演算法及其優化
本文摘選自:https://blog.csdn.net/google19890102/article/details/26149927https://blog.csdn.net/taoyanqi8932/article/details/53727841https://blog
Bellman-Ford 演算法及其優化以及SPFA
Bellman-Ford演算法與另一個非常著名的Dijkstra演算法一樣,用於求解單源點最短路徑問題。Bellman-ford演算法除了可求解邊權均非負的問題外,還可以解決存在負權邊的問題(意義是什麼,好好思考),而Dijkstra演算法只能處理邊權非負的問題,因此 B
【資料結構】各類排序演算法及其優化總結
本文對各類排序演算法的實現、優化、複雜度、穩定性、適用場景作以全面總結,為了突出演算法的簡潔、易懂,去除了一些冗餘操作,預設為升序進行模擬。 一、插入排序 插入排序基本思想:每一步將一個待排序的元素,按其排序碼的大小,插入到前面已經排好序的一組元素的合適位置
氣泡排序演算法及其優化(BubbleSort)
氣泡排序算是排序演算法裡面的一種較為簡單的演算法,也是我接觸的第一種排序演算法,有升序與降序之分,如果面試的時候面試官問道這個題目,一定要問清楚是升序還是降序,這樣會給你加分。 下面,我以升序來講一下它的運作。 1、比較相鄰的元素。如果第一個比第二個大,就交換他們
排序演算法之——歸併排序(兩種方法及其優化)
1 public class MergeX implements Comparable<Merge> {// 歸併排序(優化後) 2 private static Comparable[] aux; 3 4 private static boolean less(C
歸併排序演算法詳解及其優化
歸併排序演算法: 思想:分治法 每個遞迴過程涉及三個步驟 第一, 分解: 把待排序的 n 個元素的序列分解成兩個子序列, 每個子序列包括 n/2 個元素. 第二, 治理: 對每個子序列分別呼叫歸併排序__MergeSort, 進行遞迴操作 第三
8皇后以及N皇后演算法探究,回溯演算法的JAVA實現,非遞迴,迴圈控制及其優化
研究了遞迴方法實現回溯,解決N皇后問題,下面我們來探討一下非遞迴方案 實驗結果令人還是有些失望,原來非遞迴方案的效能並不比遞迴方案效能高 程式碼如下: package com.newflypig.eightqueen; import java.util.Date; /**
經典的同態濾波演算法的優化及其應用引數配置。
% 同態濾波器 % ImageIn - 需要進行濾波的灰度影象 % High - 高頻增益,需要大於1 % Low - 低頻增益,取值在0和1之間 % C - 銳化係數 % Sigma - 截止頻率,越大影象越亮 % 輸出為進行
排序演算法6——圖解歸併排序及其遞迴與非遞迴實現
排序演算法1——圖解氣泡排序及其實現(三種方法,基於模板及函式指標) 排序演算法2——圖解簡單選擇排序及其實現 排序演算法3——圖解直接插入排序以及折半(二分)插入排序及其實現 排序演算法4——圖解希爾排序及其實現 排序演算法5——圖解堆排序及其實現 排序演算法6——圖解歸併排序及其遞迴與非
歸併排序演算法及其C語言具體實現
本節介紹一種不同於插入排序和選擇排序的排序方法——歸併排序,其排序的實現思想是先將所有的記錄完全分開,然後兩兩合併,在合併的過程中將其排好序,最終能夠得到一個完整的有序表。 例如對於含有 n 個記錄的無序表,首先預設表中每個記錄各為一個有序表(只不過表的長度都為 1),然後進行兩兩合併,使 n 個有序表變為
SSE影象演算法優化系列二十五:二值影象的Euclidean distance map(EDM)特徵圖計算及其優化。 SSE影象演算法優化系列九:靈活運用SIMD指令16倍提升Sobel邊緣檢測的速度(4000*3000的24點陣圖像時間由480ms降低到30ms)
Euclidean distance map(EDM)這個概念可能聽過的人也很少,其主要是用在二值影象中,作為一個很有效的中間處理手段存在。一般的處理都是將灰度圖處理成二值圖或者一個二值圖處理成另外一個二值圖,而EDM演算法確是由一幅二值圖生成一幅灰度圖。其核心定義如下: The definitio
GeoHash演算法及其實現優化
前言 上篇部落格中提到了空間索引的用途和多種資料庫對空間索引的支援情況,那麼在應用層以下,好學的小夥伴應該會考慮空間索引的實現原理了。 目前空間索引的實現有 R樹和其變種GIST樹、四叉樹、網格索引等。 網格索引不再多提,使用普通的hash表儲存地點和風格之間的對映來實現。今天要介紹的GeoH
排序演算法之 歸併排序 及其時間複雜度和空間複雜度
在排序演算法中快速排序的效率是非常高的,但是還有種排序演算法的效率可以與之媲美,那就是歸併排序;歸併排序和快速排序有那麼點異曲同工之妙,快速排序:是先把陣列粗略的排序成兩個子陣列,然後遞迴再粗略分兩個子陣列,直到子數組裡面只有一個元素,那麼就自然排好序了,可